
Eu Regulations for AI integration and BIM analysis through NLP
I think most of us get traumatized every time we search for a specific regulation, right?

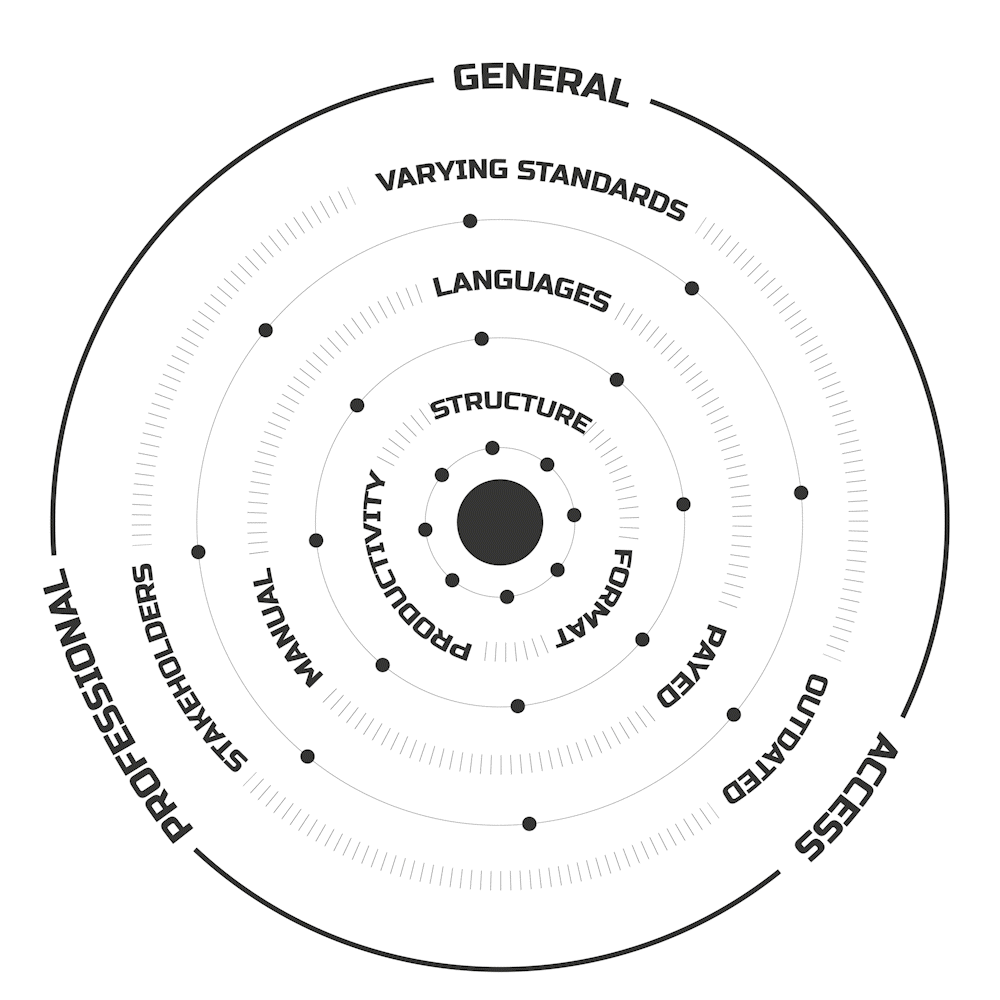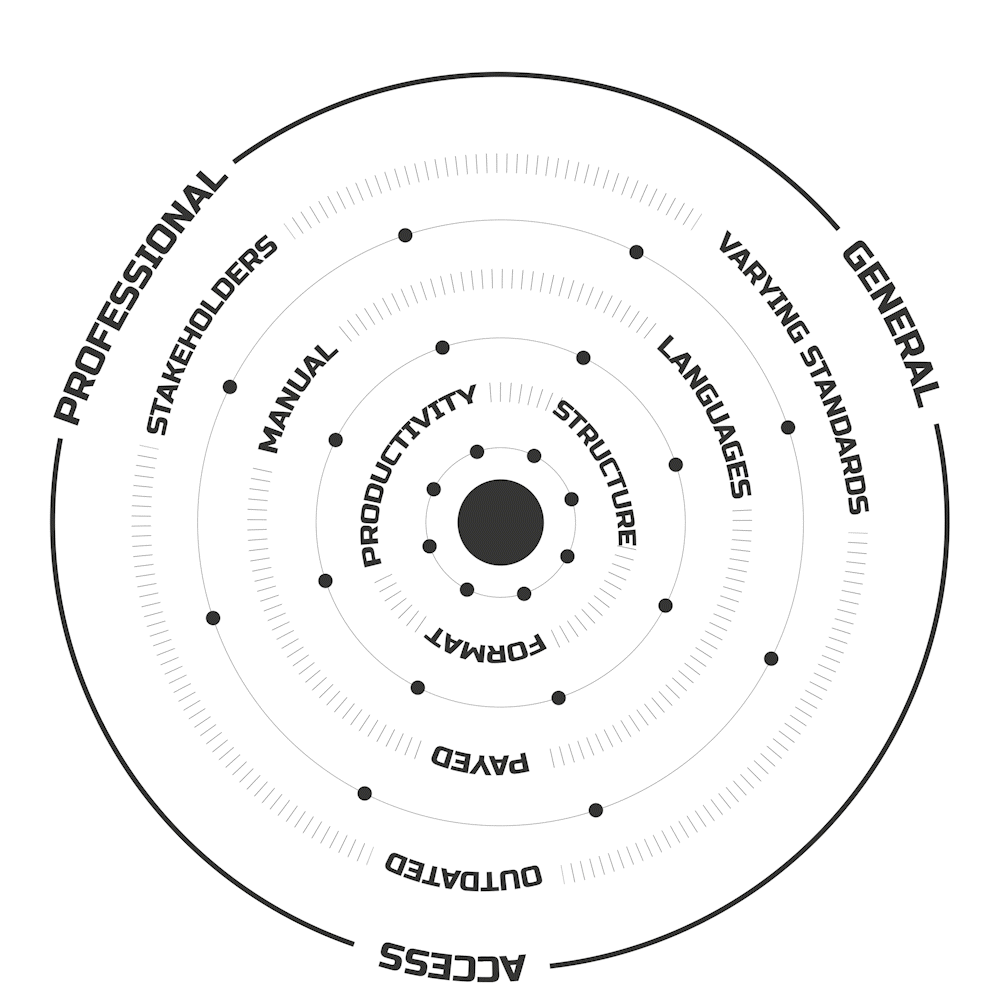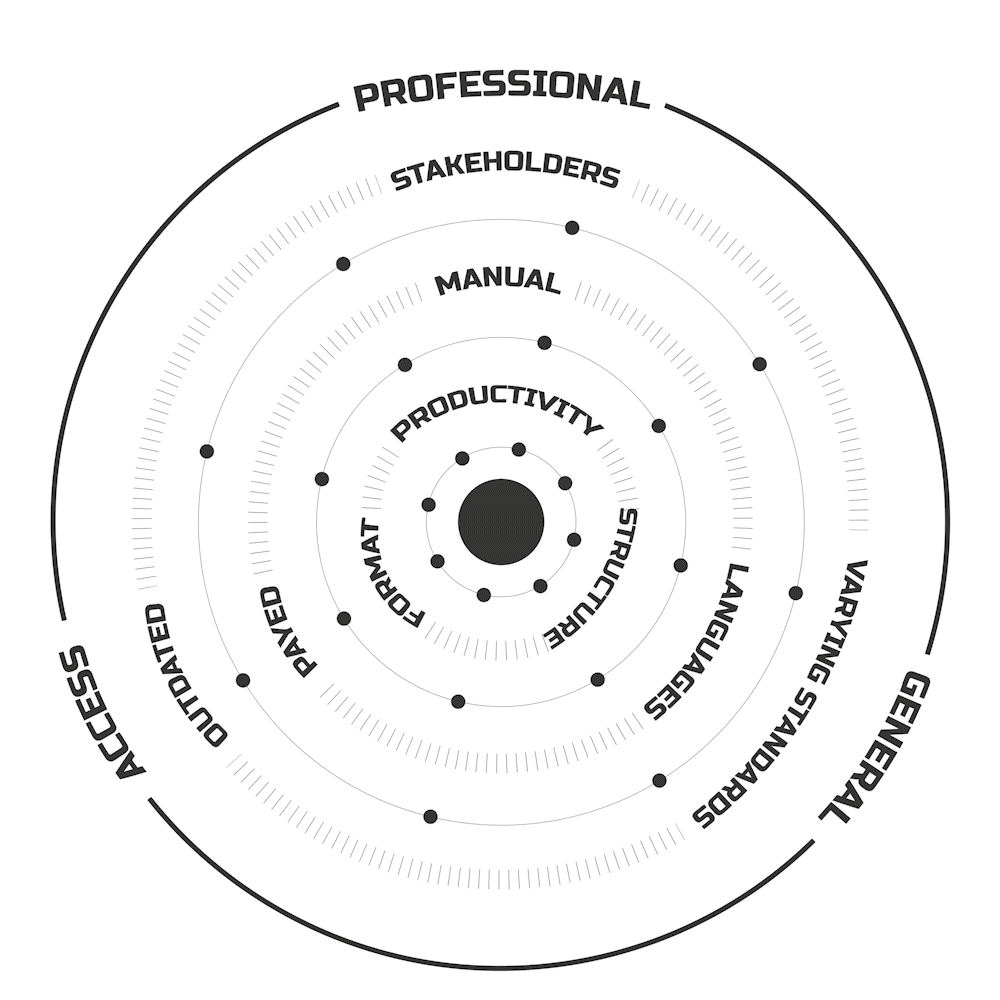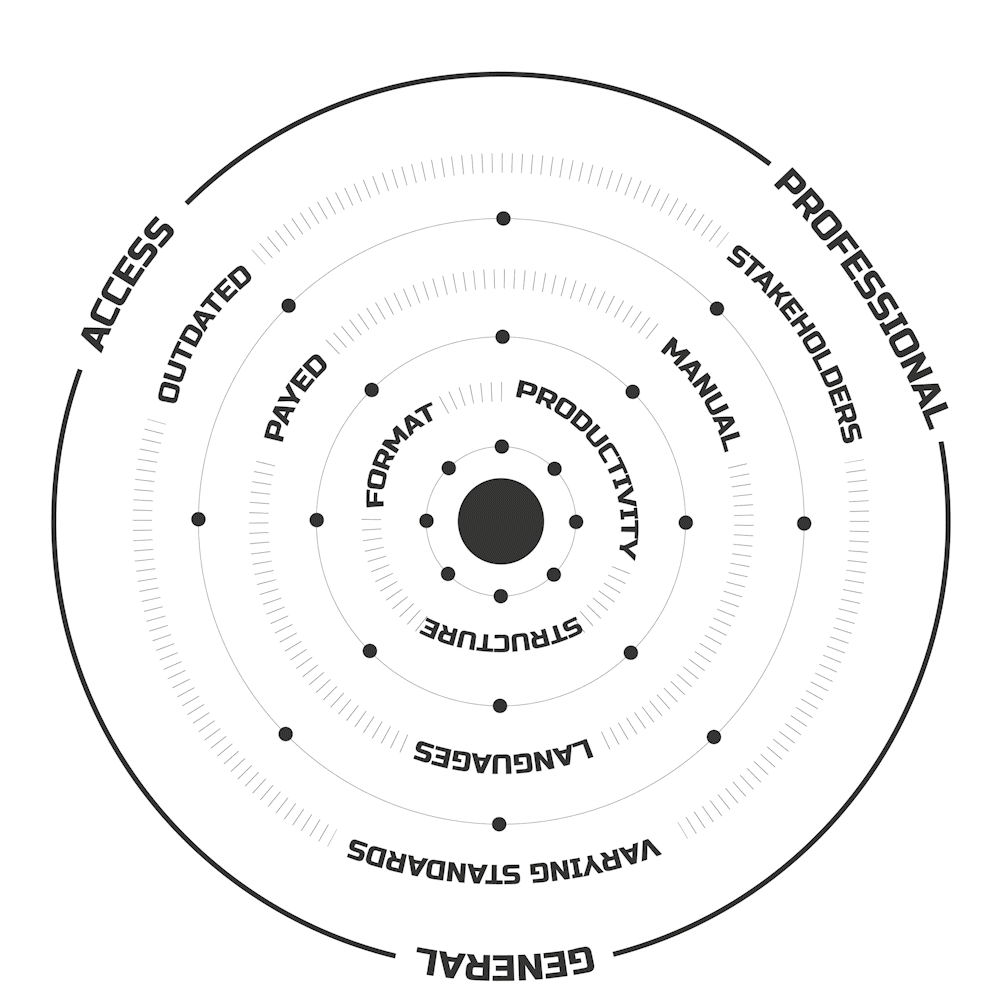
Every time it’s a nightmare that feels like a descent into madness. Especially when working in different countries, that have their own land divisions with different approaches to regulatory structures.
And of course, each country’s native language makes it even worse.
One minute you’re a designer; the next, you’re an amateur linguist.
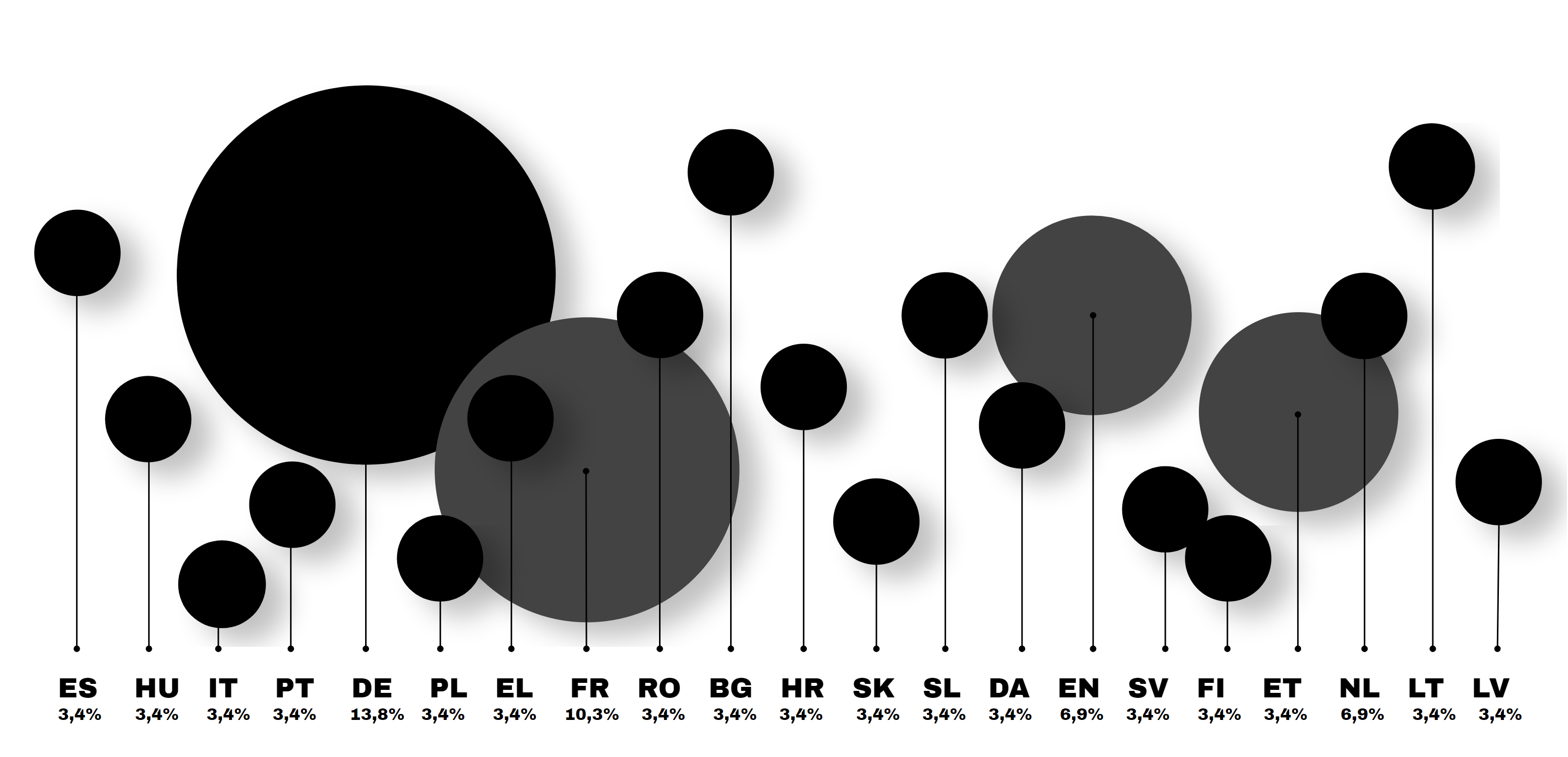
Just when you think you’ve cracked the code, you discover the document you need has a price tag, adding insult to injury. Even when you manage to find what you need, there’s always a colleague who’s going through the same document-dungeon quest. Hiring experts, spending money, wasting time — just to get to the right answers.

I think this is a problem. The manual verification of building design compliance with international regulations, complicated by language differences and varying standards, is inefficient and outdated, reducing productivity
So, what if there was a way to have a tool with integrated 3D model analysis and a chatbot pre-trained on building regulations? If possible, it would bridge a huge gap, making it easier to understand and verify regulations during the early design stages
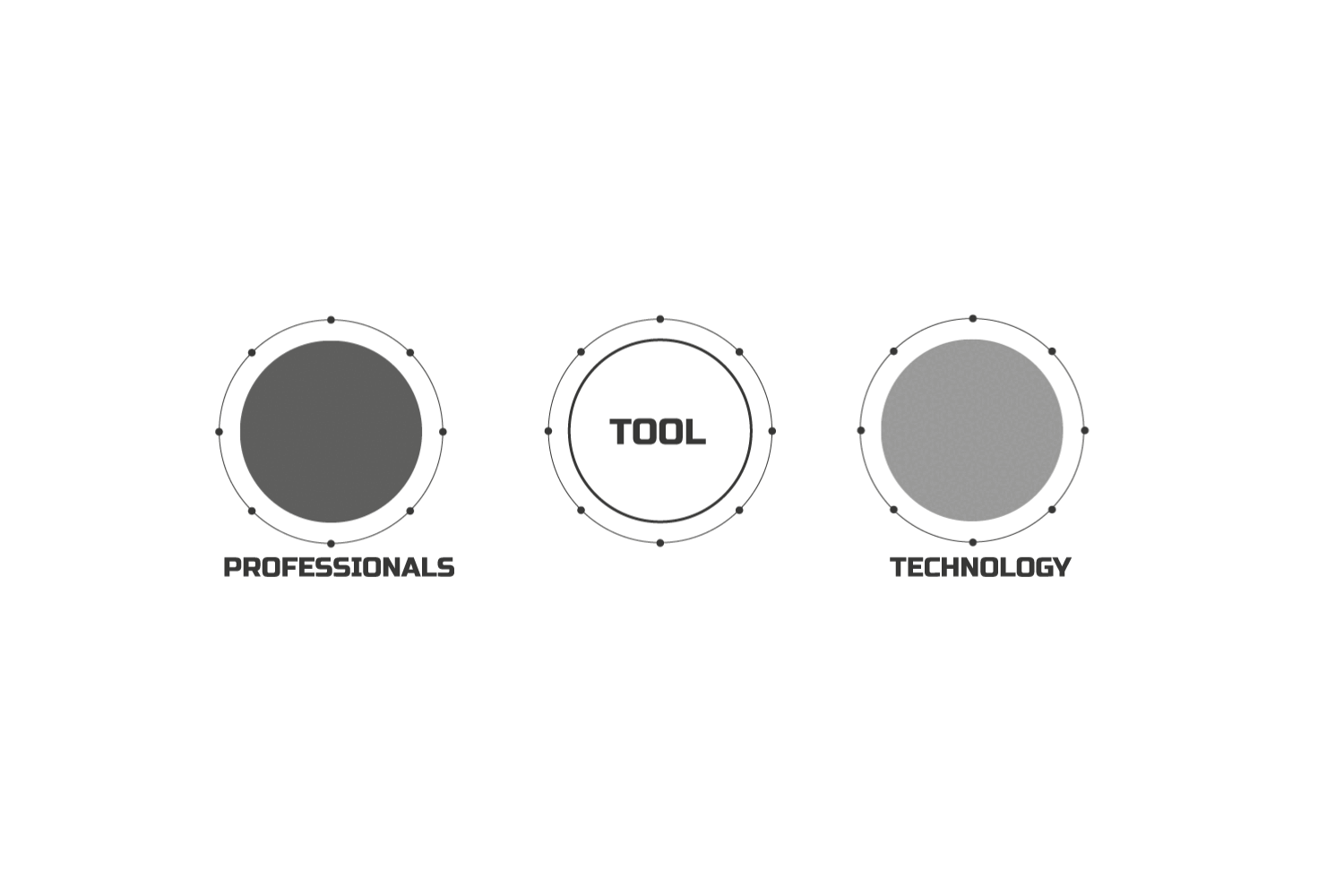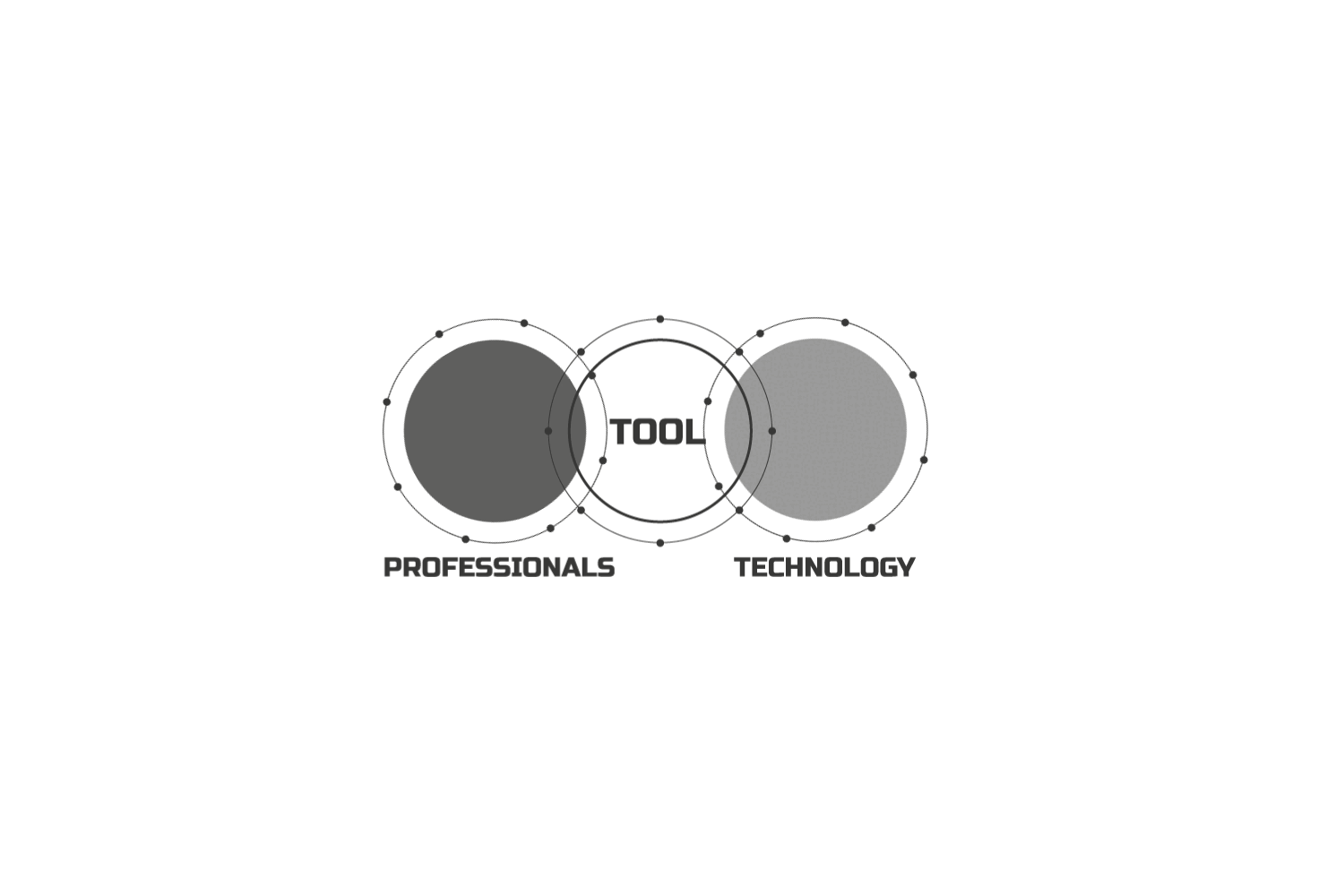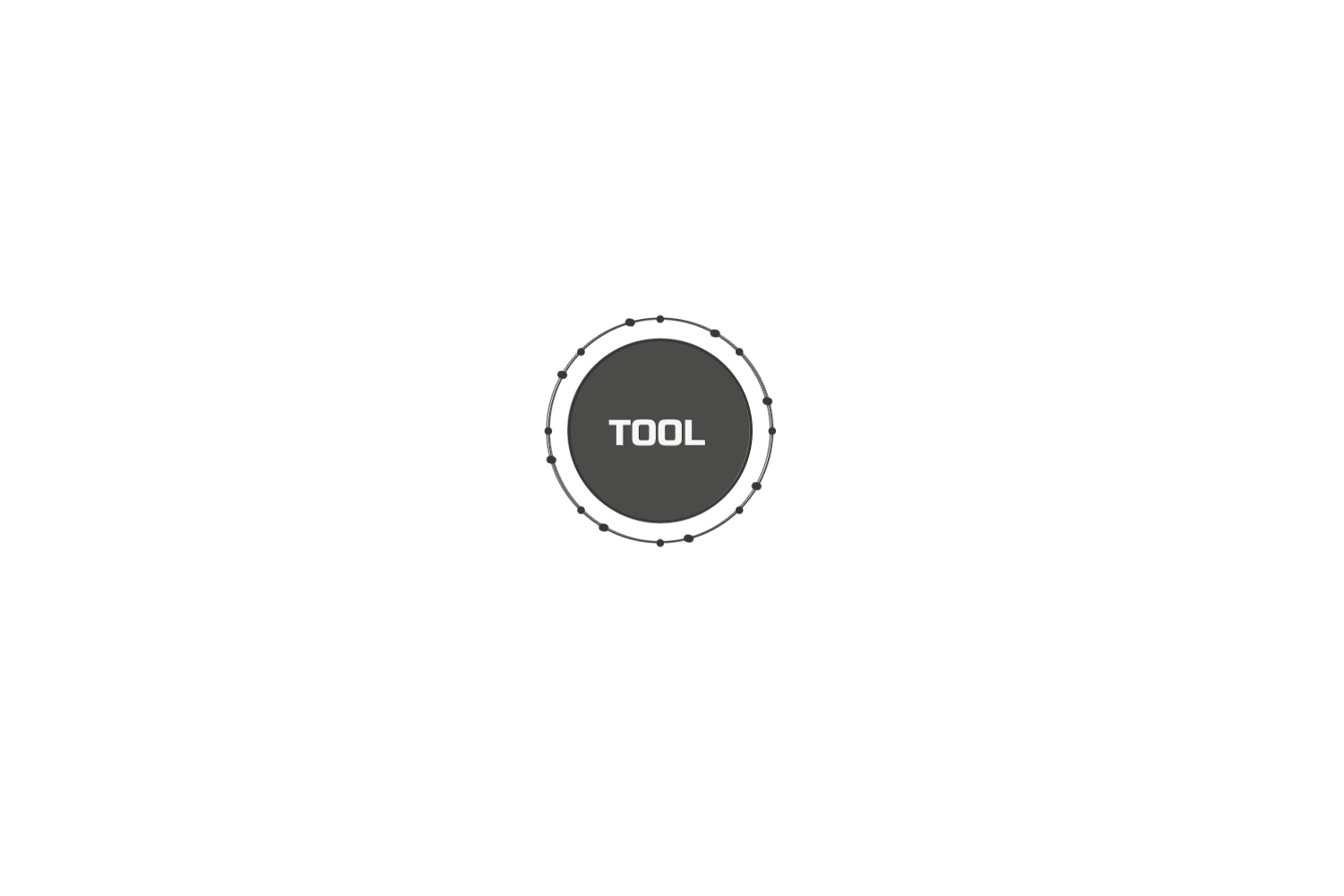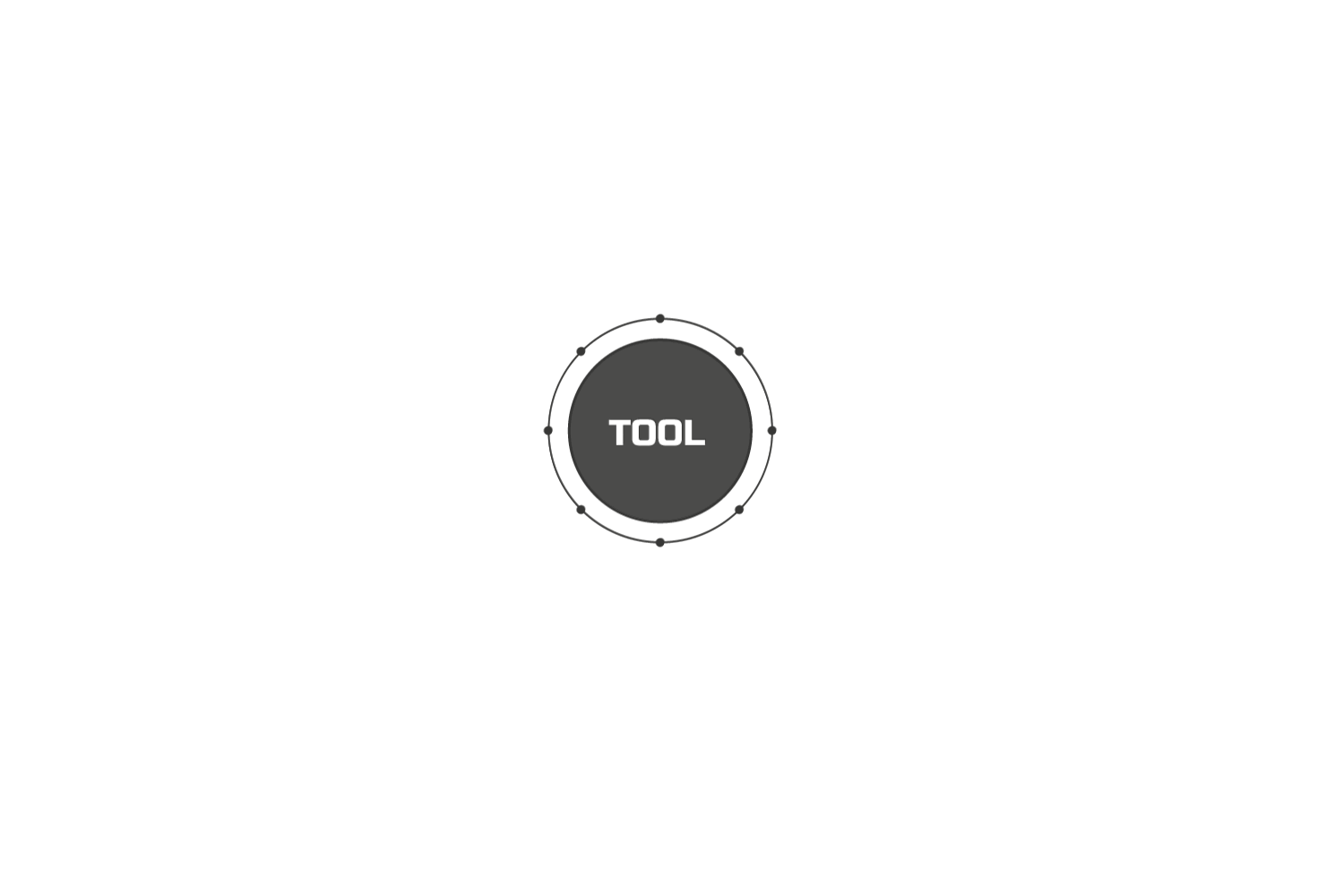

The dream for me is a web platform that helps us navigate building regulations via a smart chatbot and checks our 3D models for compliance across the EU.
CONCEPT
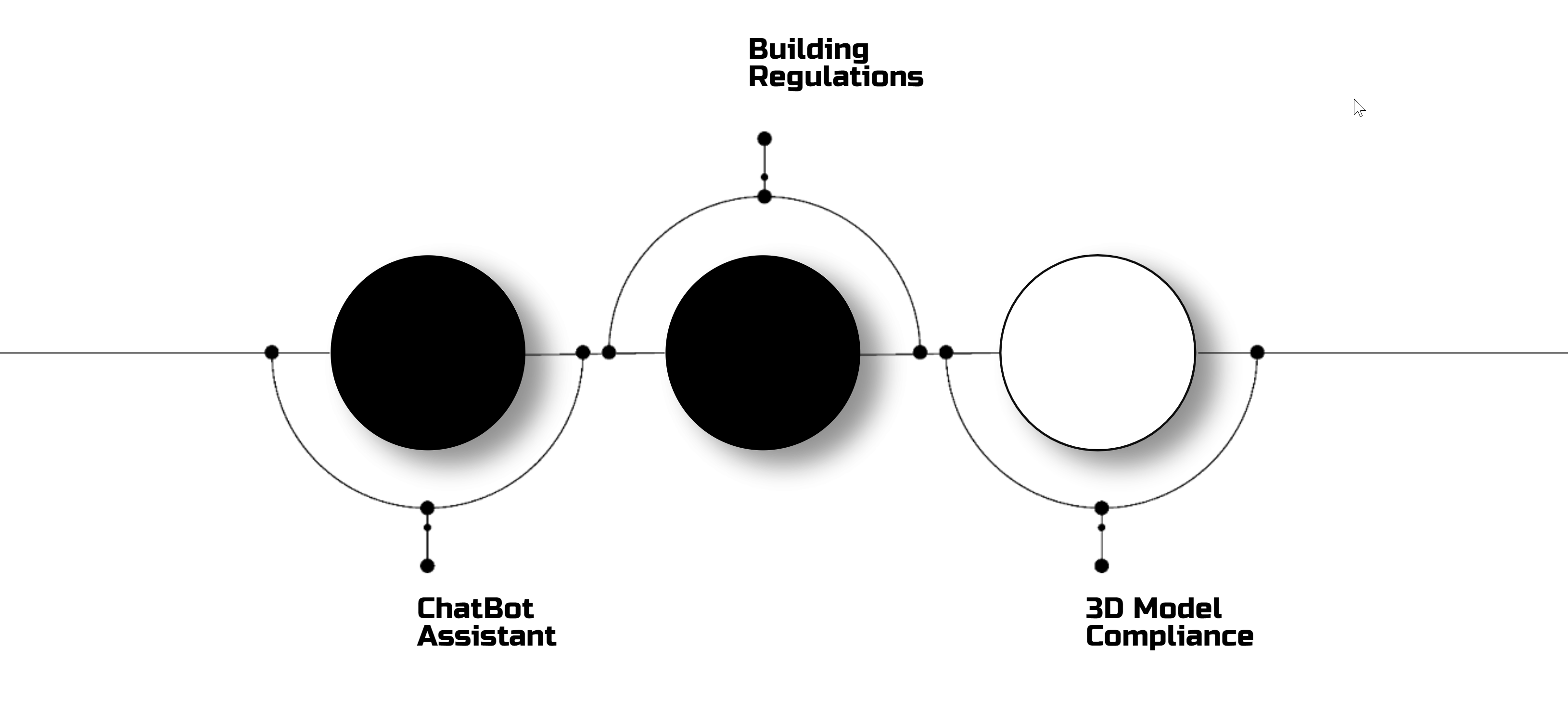
But why again do we need this kind of tool, and who will it benefit?

Firstly, as I mentioned, the legal structure across Europe is a maze. Some countries have layers upon layers of regulations—Central, Regional, Local—while others just use their own building acts or the Eurocodes.
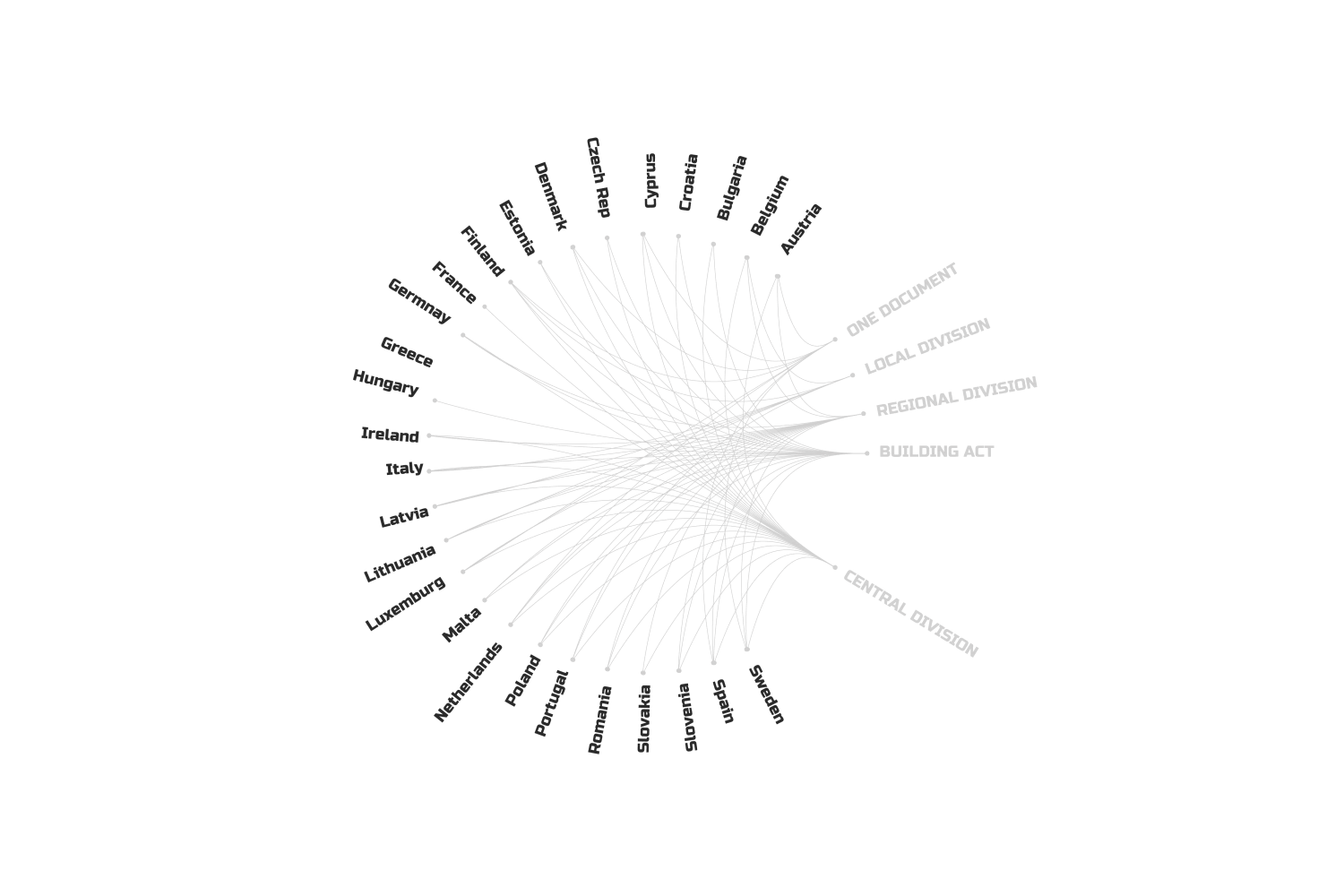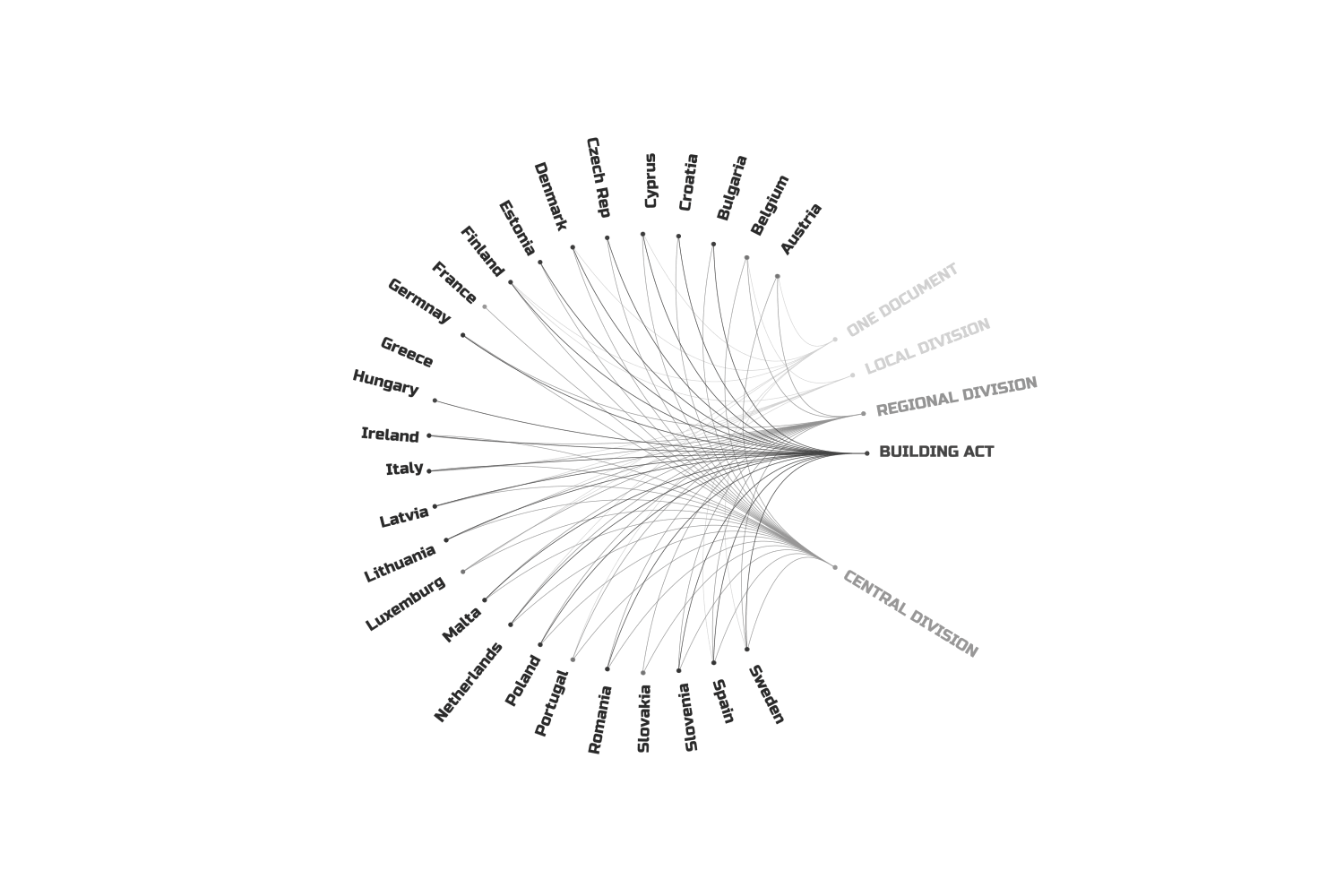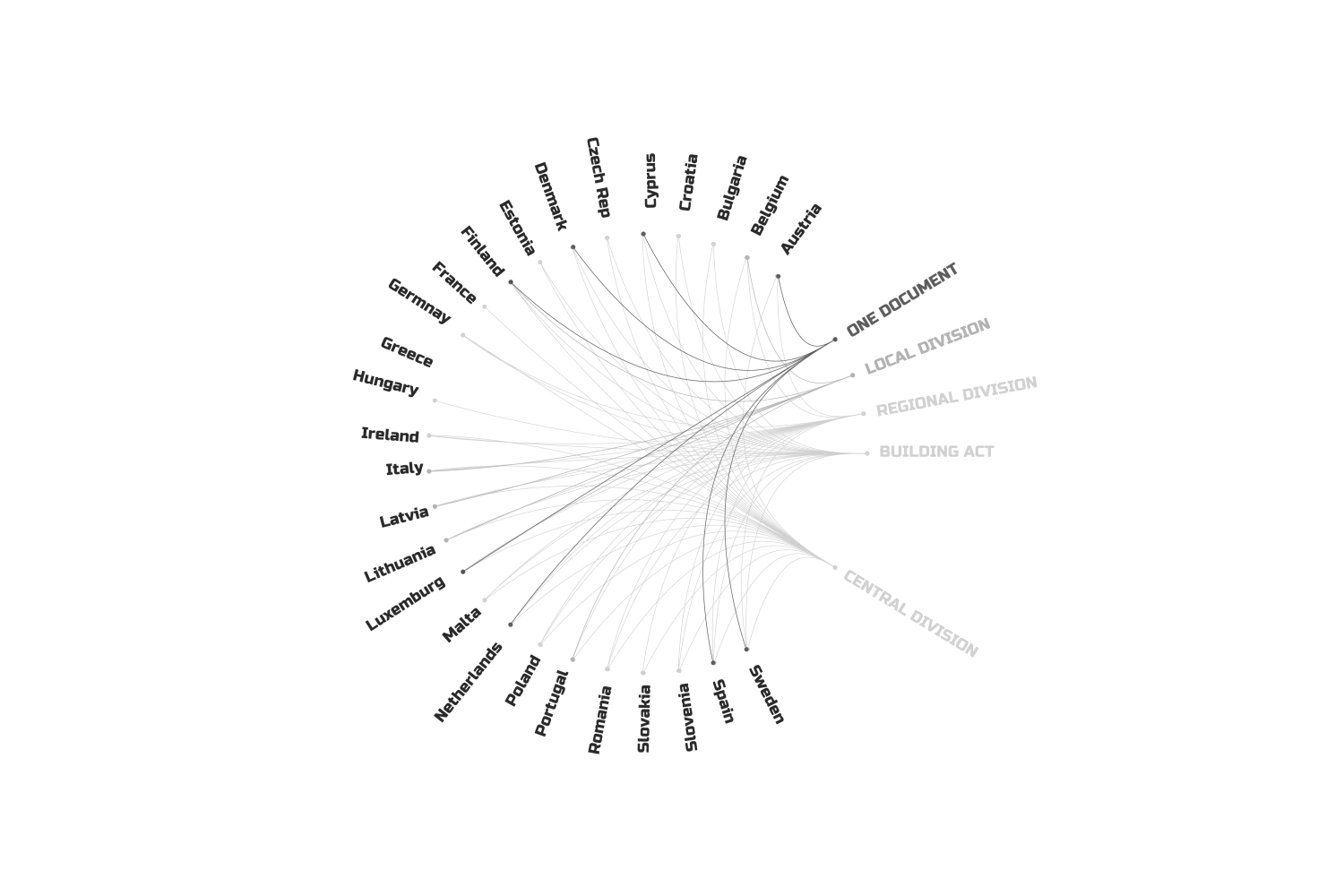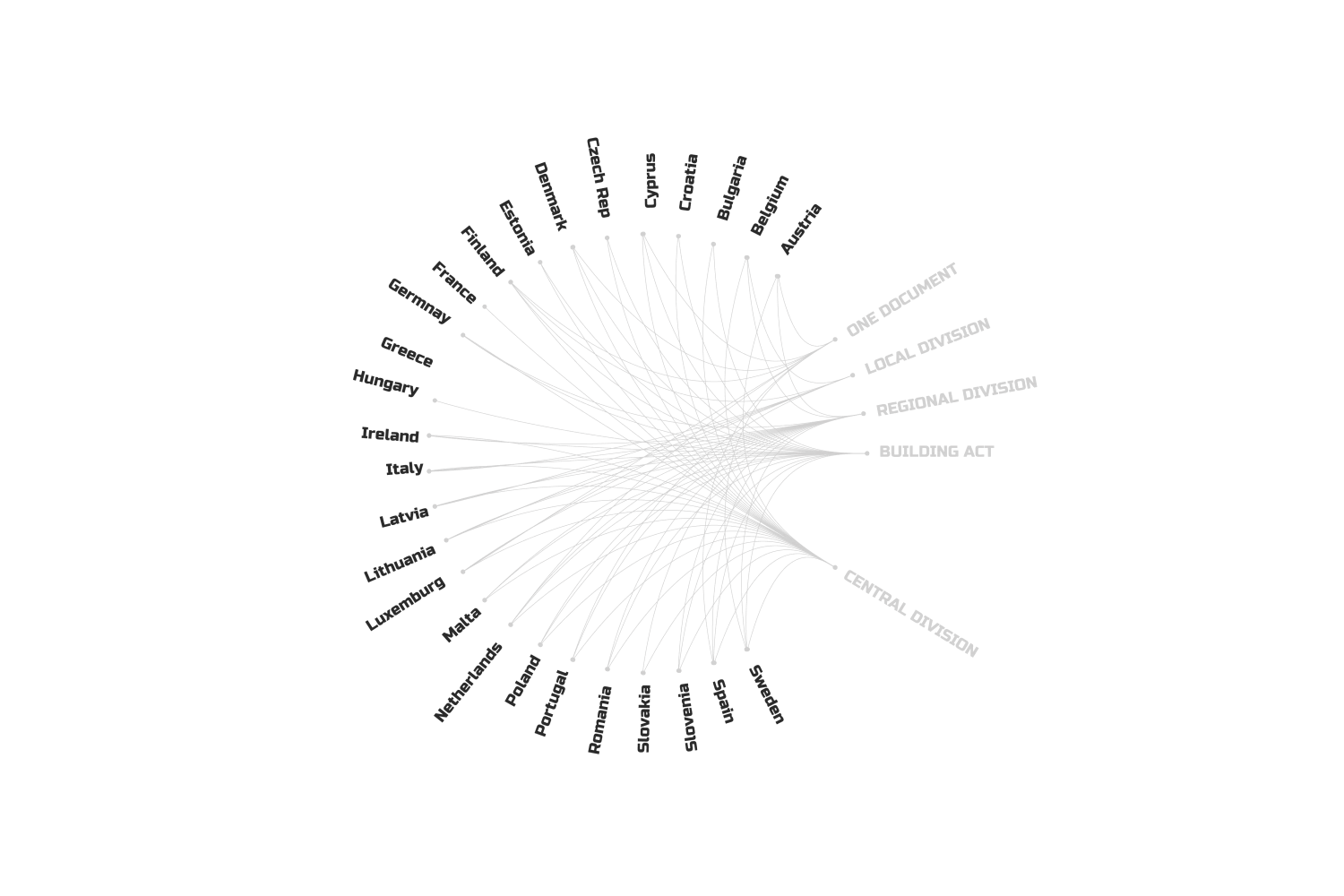
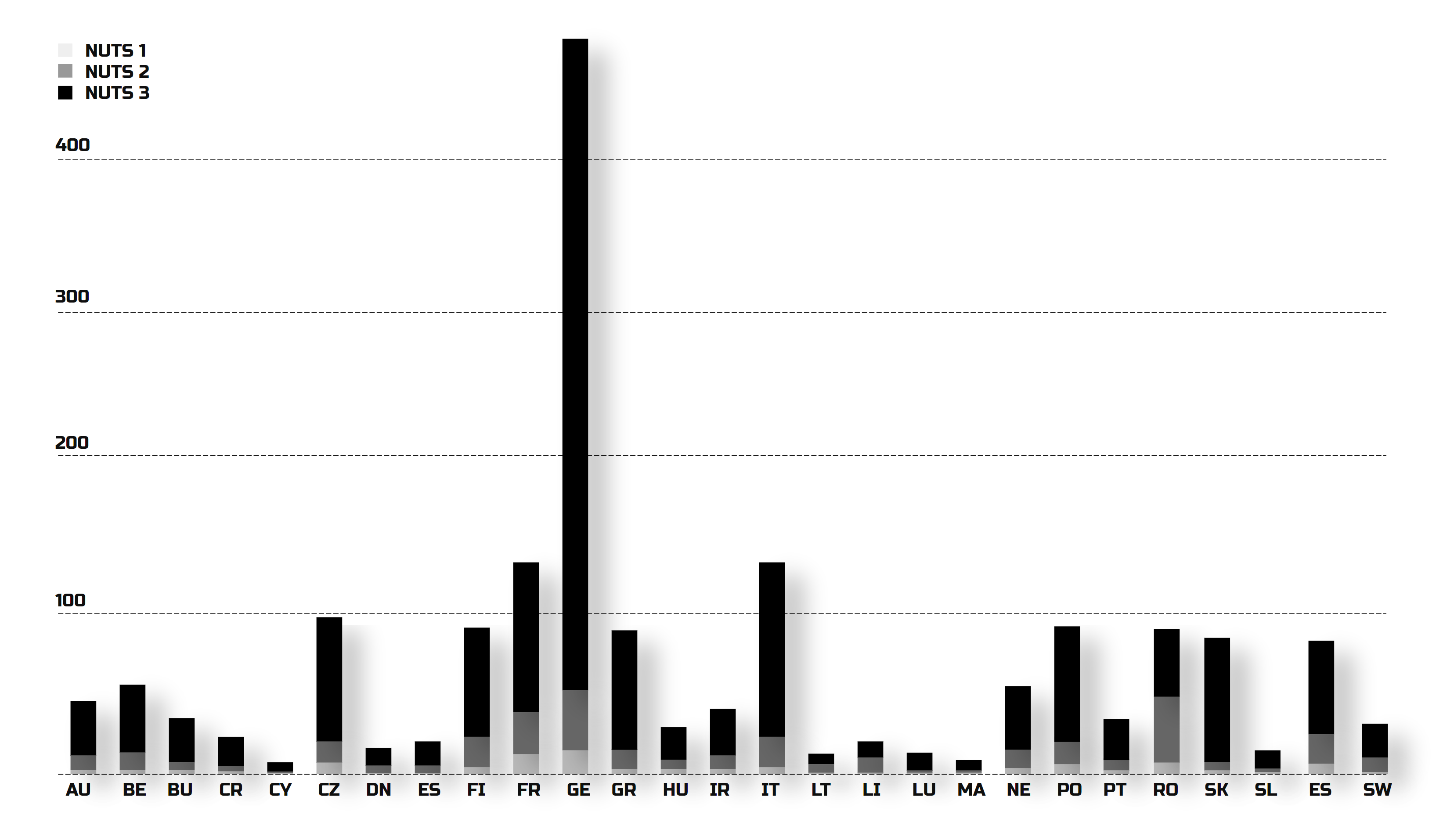
We have two main types of documents: country-specific ones and Eurocodes. To use the first, you need a treasure map—find the country, the region, the district, the municipality, the city, and so on
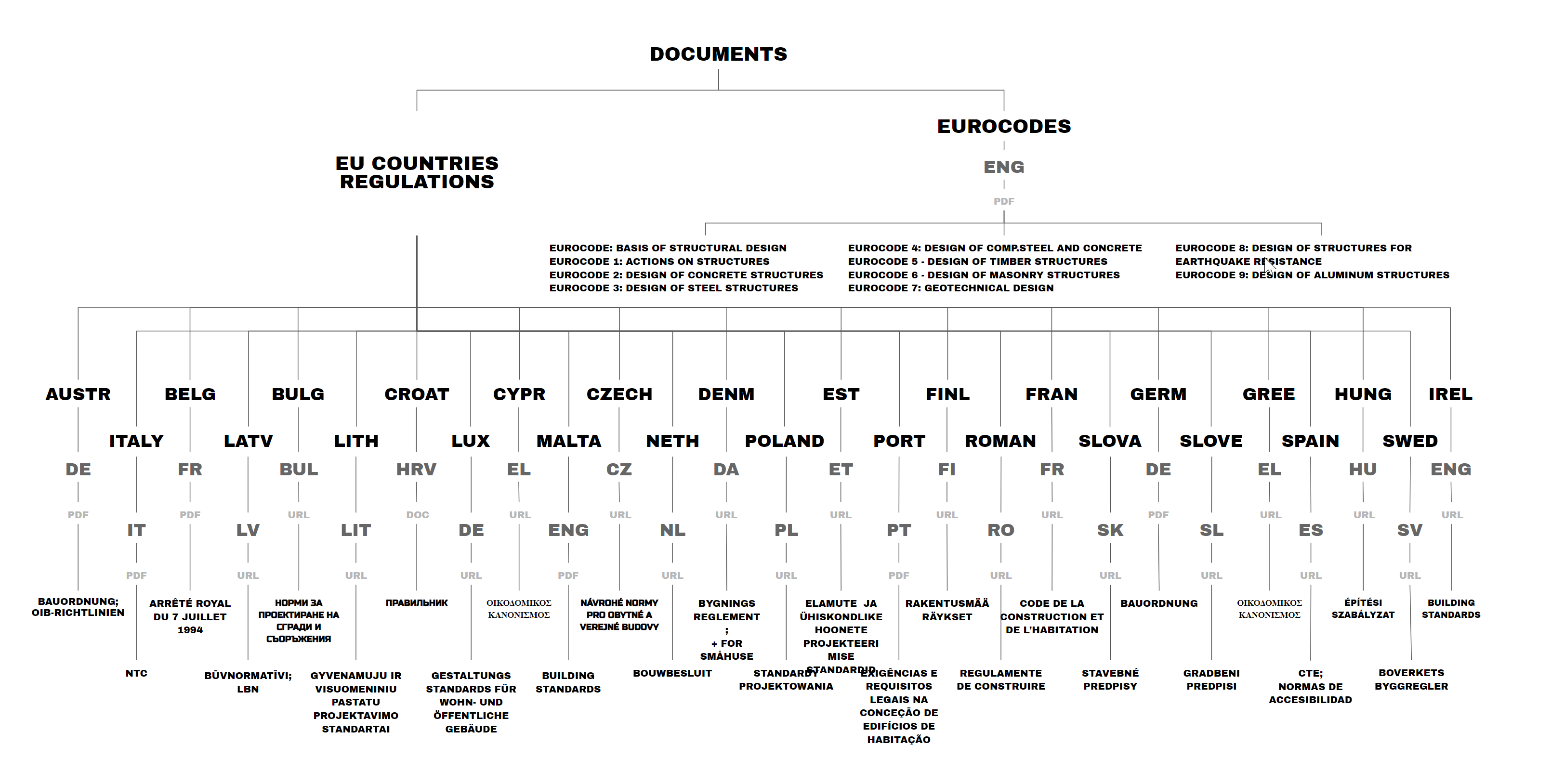
From my survey among professionals, aside from the pure chaos of finding regulations, there are key questions everyone struggles with.
Fire Safety, Seismic Design, Permit Requirements, Land Use, and Wiring are the usual suspects.
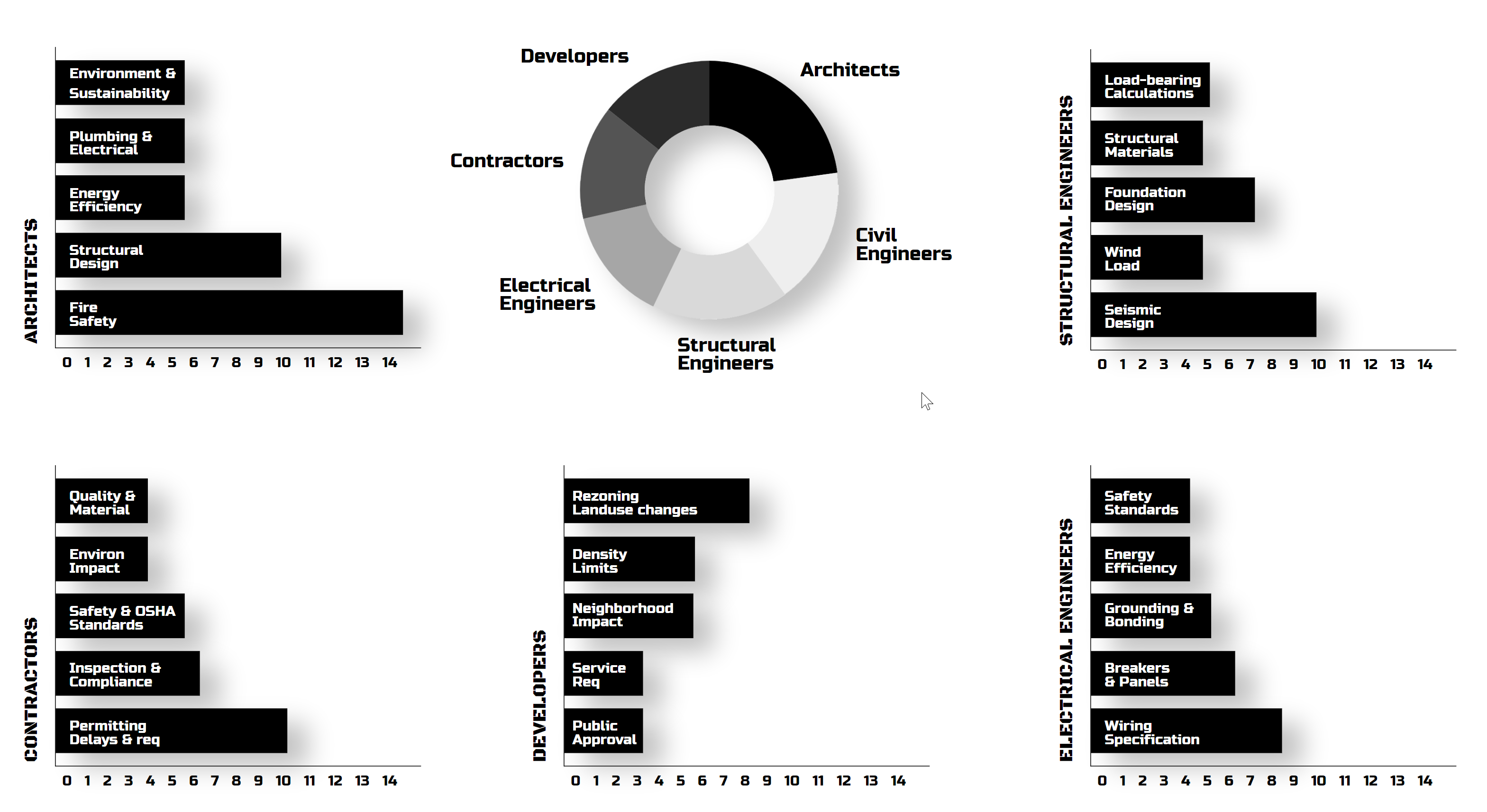
These topics still require us to manually check, which is bizarre and unproductive

So, how do we bridge this gap and create an assistant that helps us navigate the regulatory nightmare and checks our models?
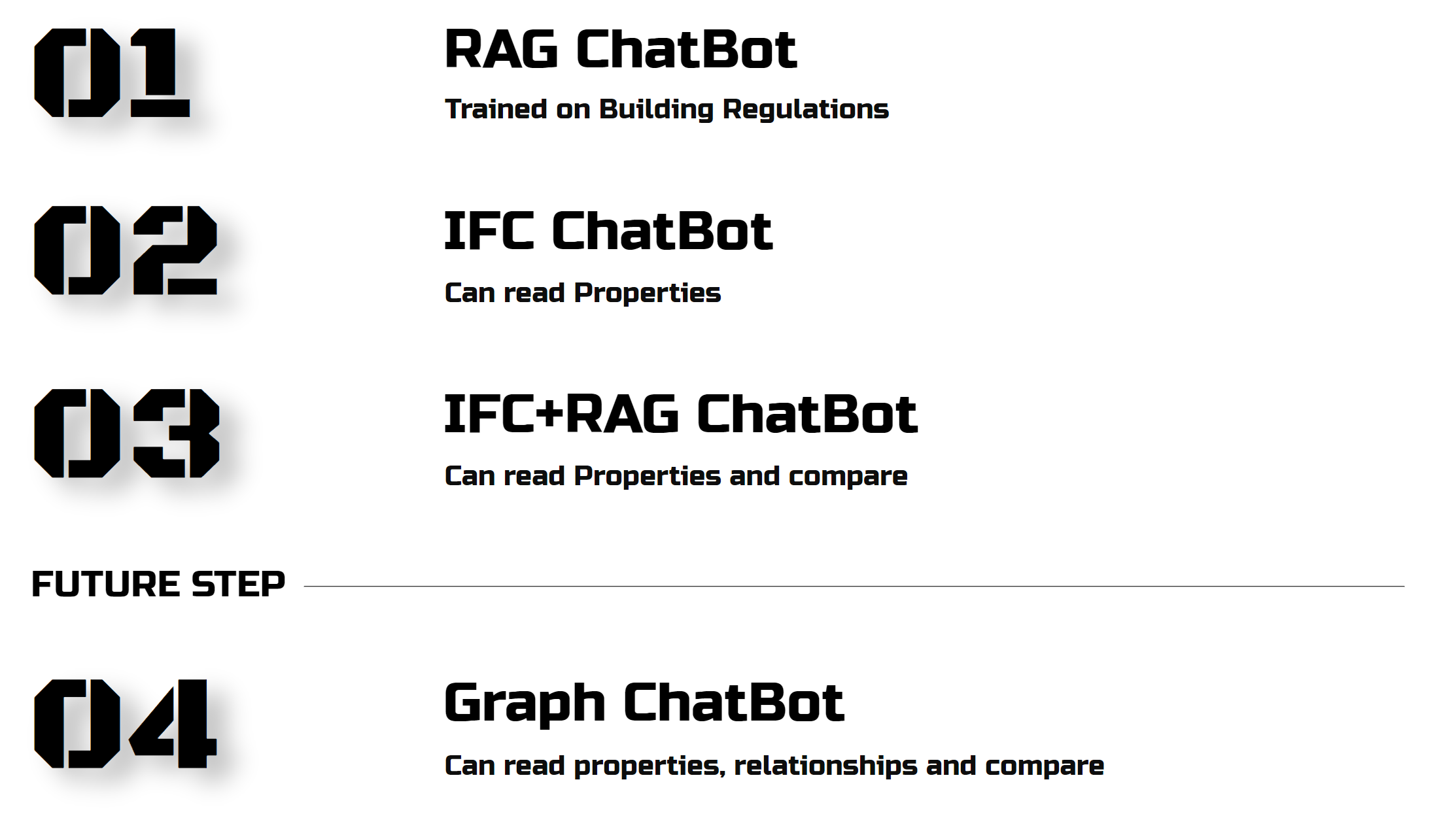
The research steps were clear: first, understand how chatbots and BIM work, explore IFC files. Next, gather the documents, conduct a survey, train a chatbot on the findings, and probe its capabilities. Finally, delve into IFC files to see what properties we can extract and how to get the chatbot talking about them.

CHATBOTS

There are some chatbots out there that handle building regs, but they’re trained on U.S. documents and don’t support 3D.
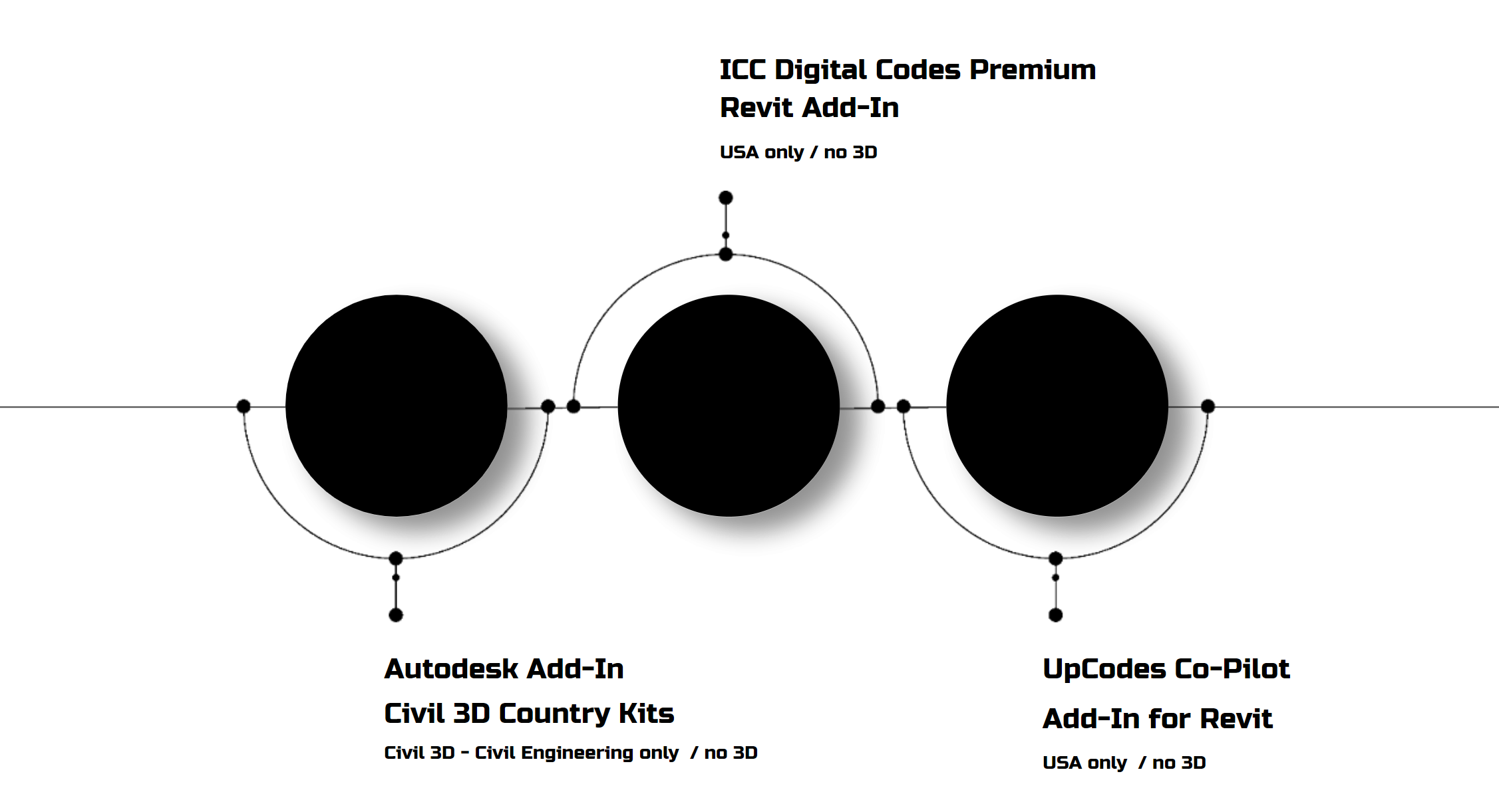
Before we dive into the experiments, let’s see what’s happening inside of chatbots. You’ve probably heard the terms before, but let’s recap.

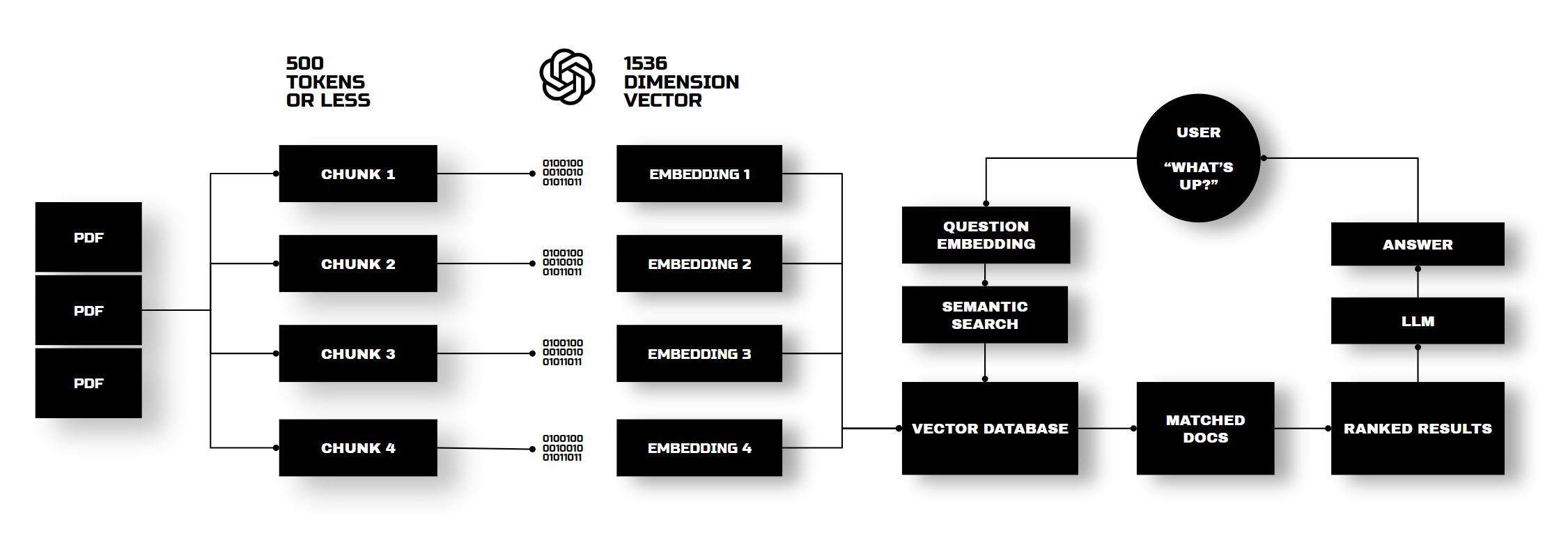
Let’s look at the architecture, a slightly different architecture. Here’s how ChatGPT and similar systems work. We upload PDFs, break them into chunks, convert them into numeric vectors, and store them in a database. When you ask ChatGPT a question, it translates your query into vectors, searches for matches, and then responds like a human using one of the LLM models.
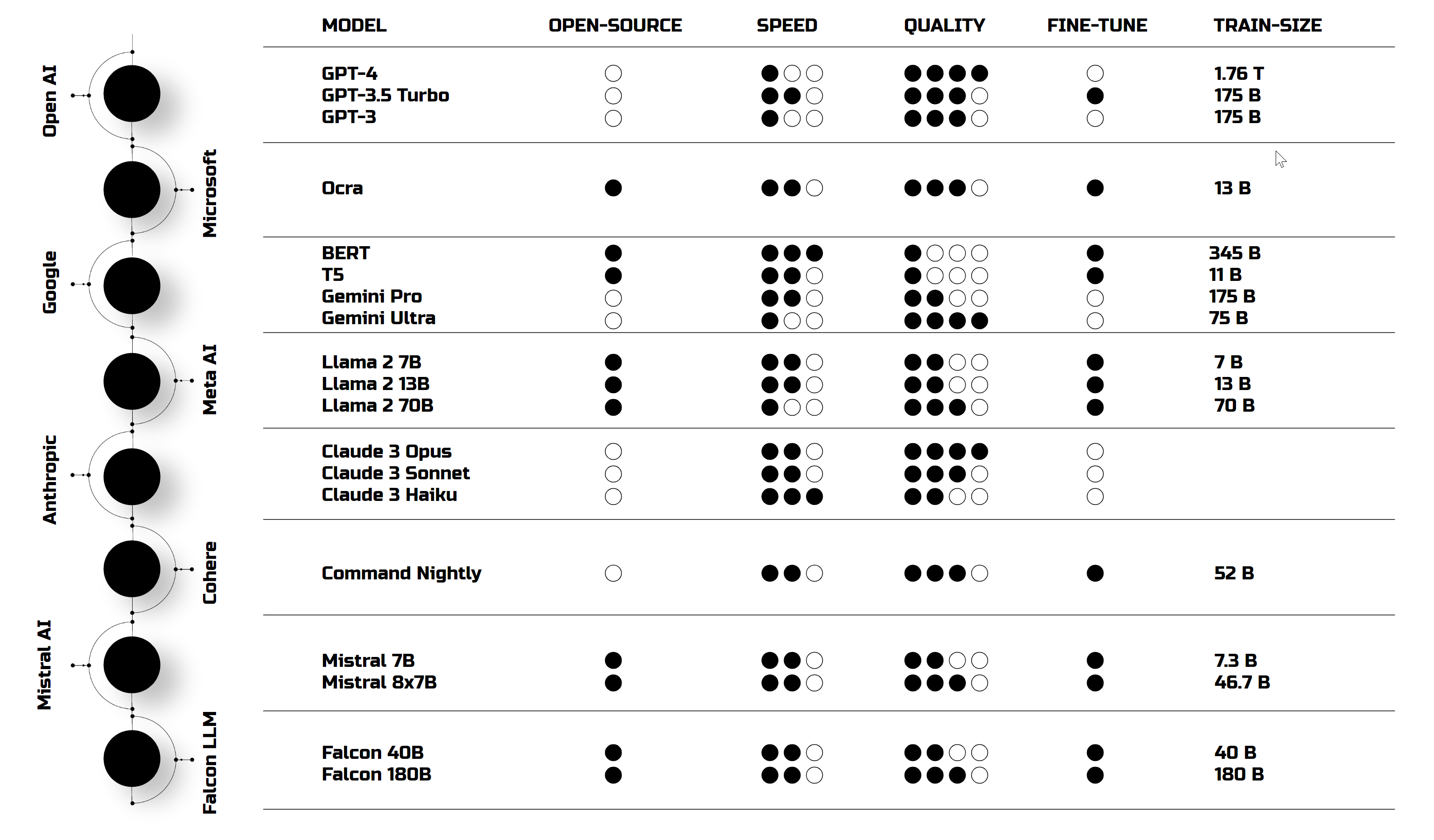
There are plenty of models out there, each with its own flavor. some open-source, some slow, with varying answer quality. OpenAI models were my choice for its superior language understanding, enhanced retrieval capabilities, and its effectiveness in managing long queries.
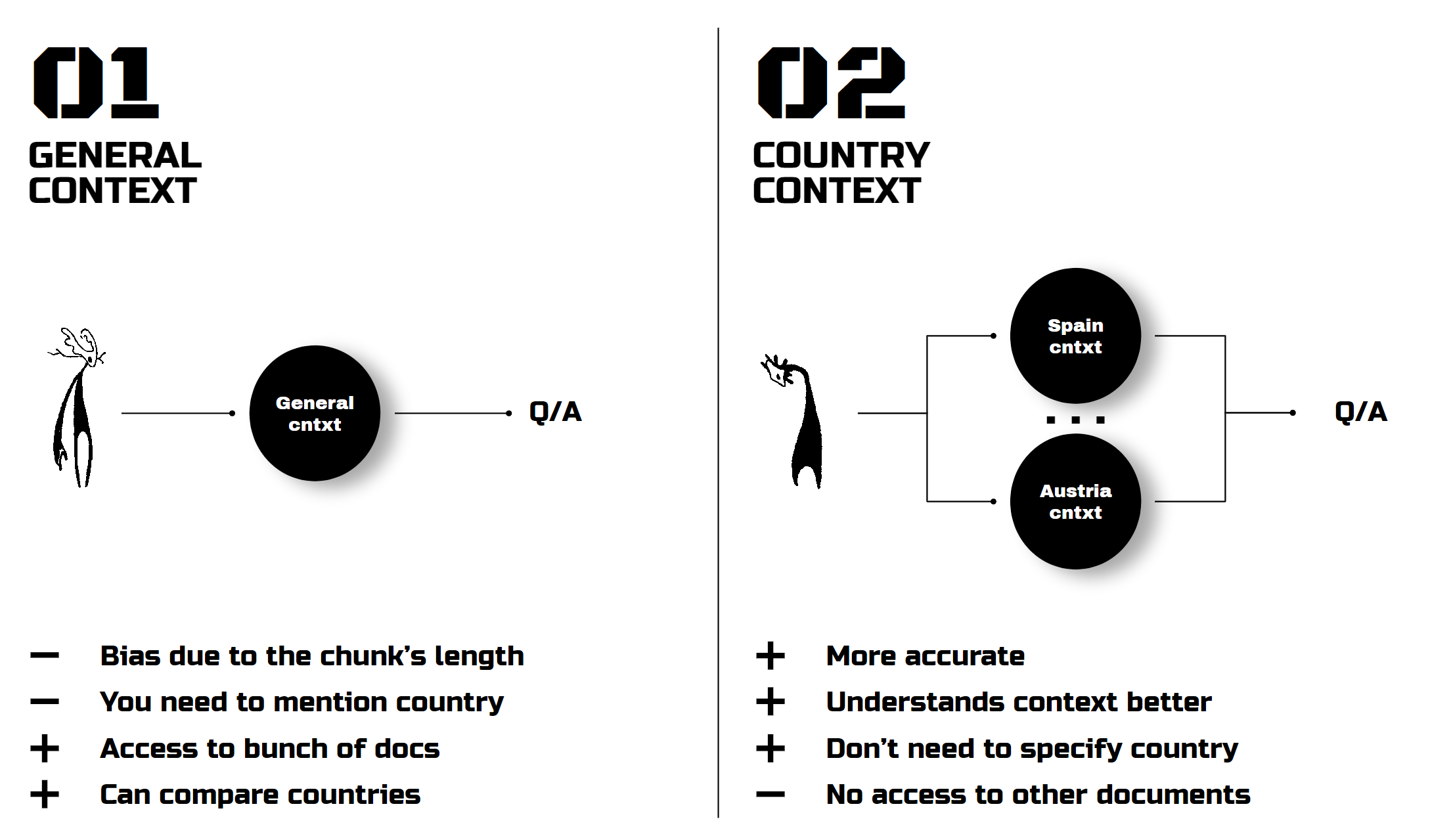
After choosing the model, it was interesting to compare two data structure strategies: a general context model versus a country-specific one. The general context model, despite its broad access, was often biased and required specifying the country in each question. The country-specific model was more accurate.
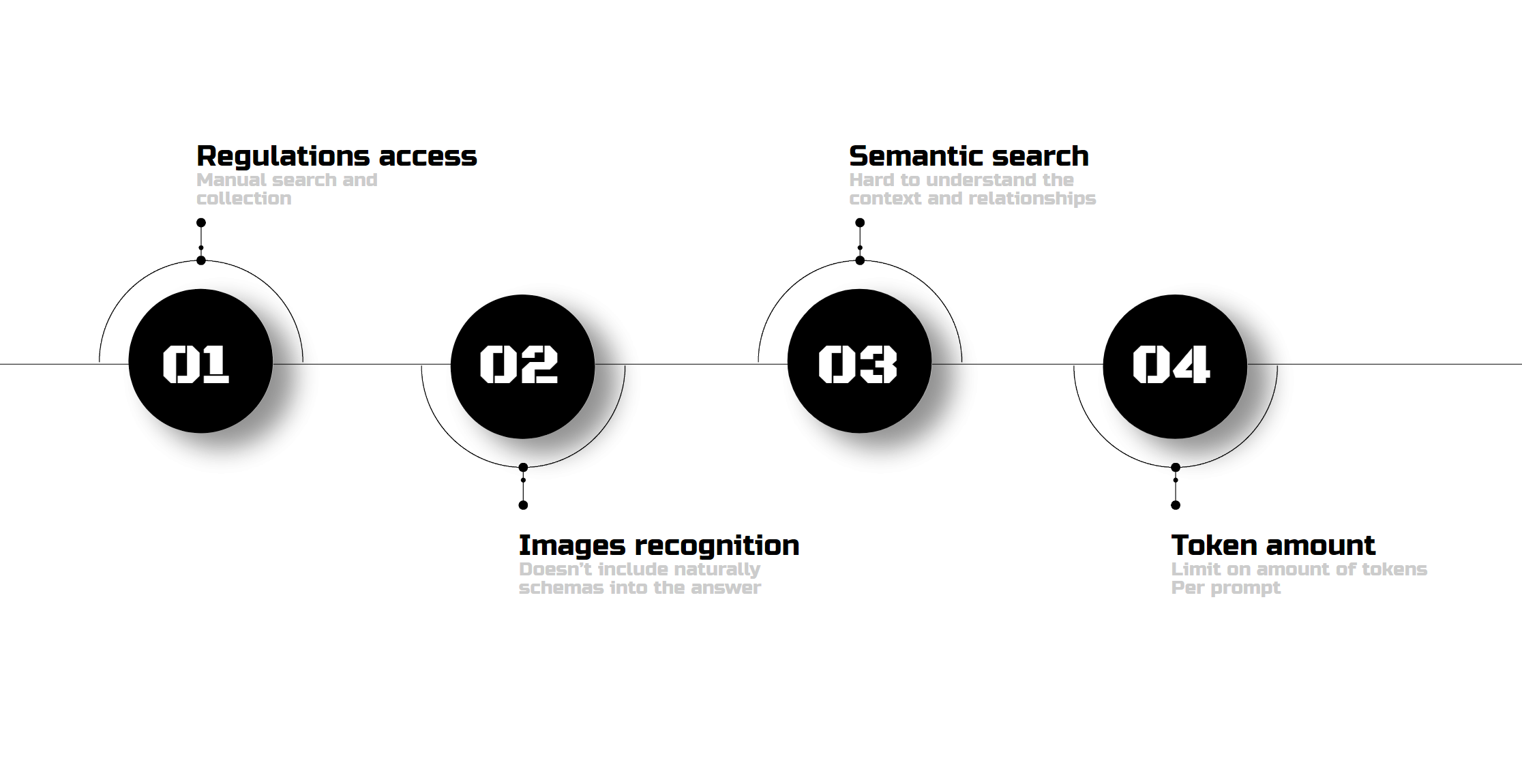
Limitations
But there are limitations. We still need to search for documents manually. The chatbot can describe images if asked about a specific one, but it doesn’t link image to the questions. Plus, there’s always bias in semantic searches due to the data volume, and LLMs have token limits.
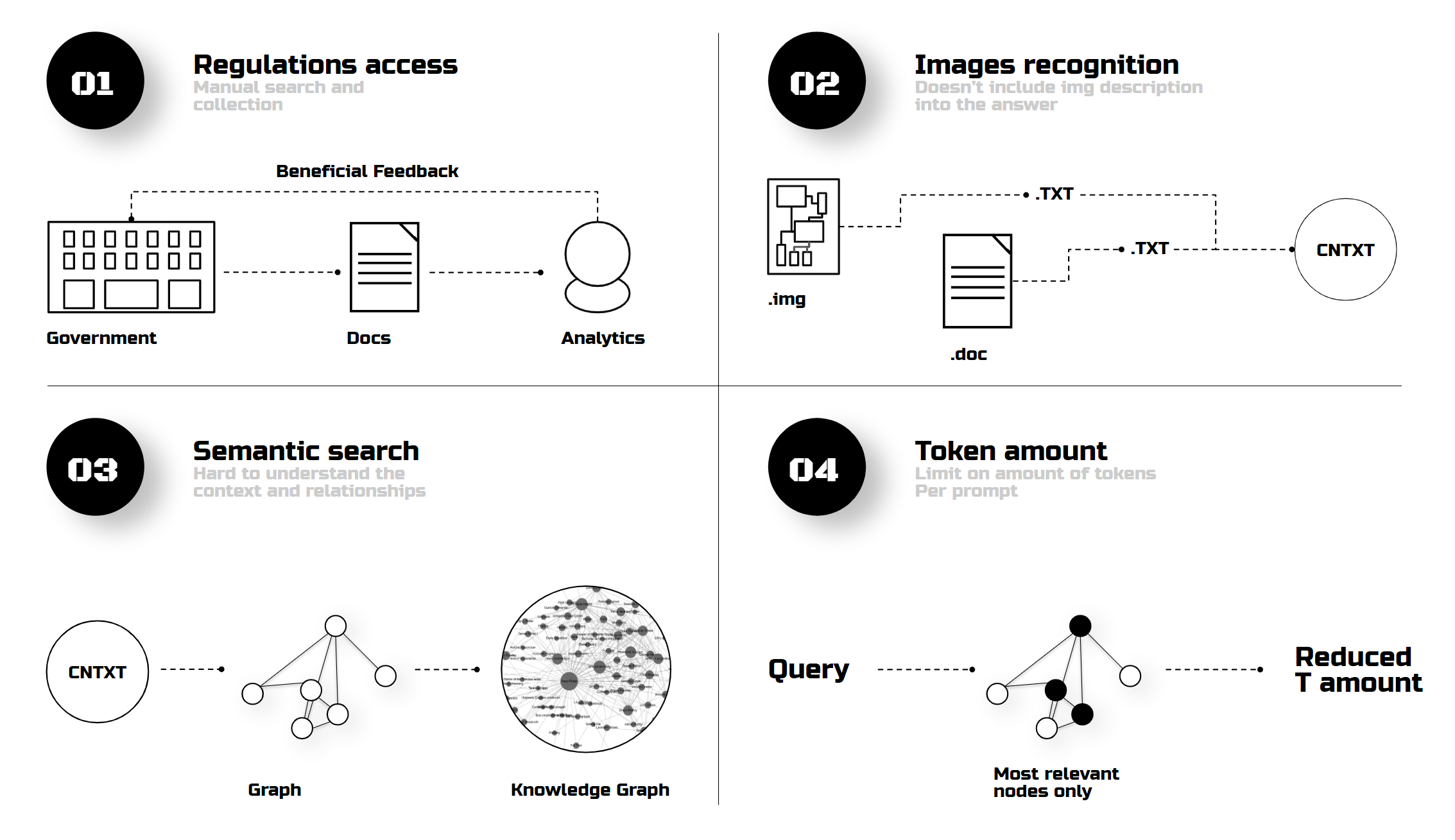
Solutions
Future solutions could involve collaborating with governments for regulation access, using image-to-text conversion for better context, and implementing knowledge graphs to streamline semantic searches by focusing only on relevant data points.
For now, the chatbot context includes all documents, a pre-written prompt like “Hey chatbot, stick to answering questions about documents based on the chosen country,” and, of course, the user’s query. But what if we add a 3D model into the mix?

This brings us to the second part of my thesis: How can we read a 3D model using NLP?
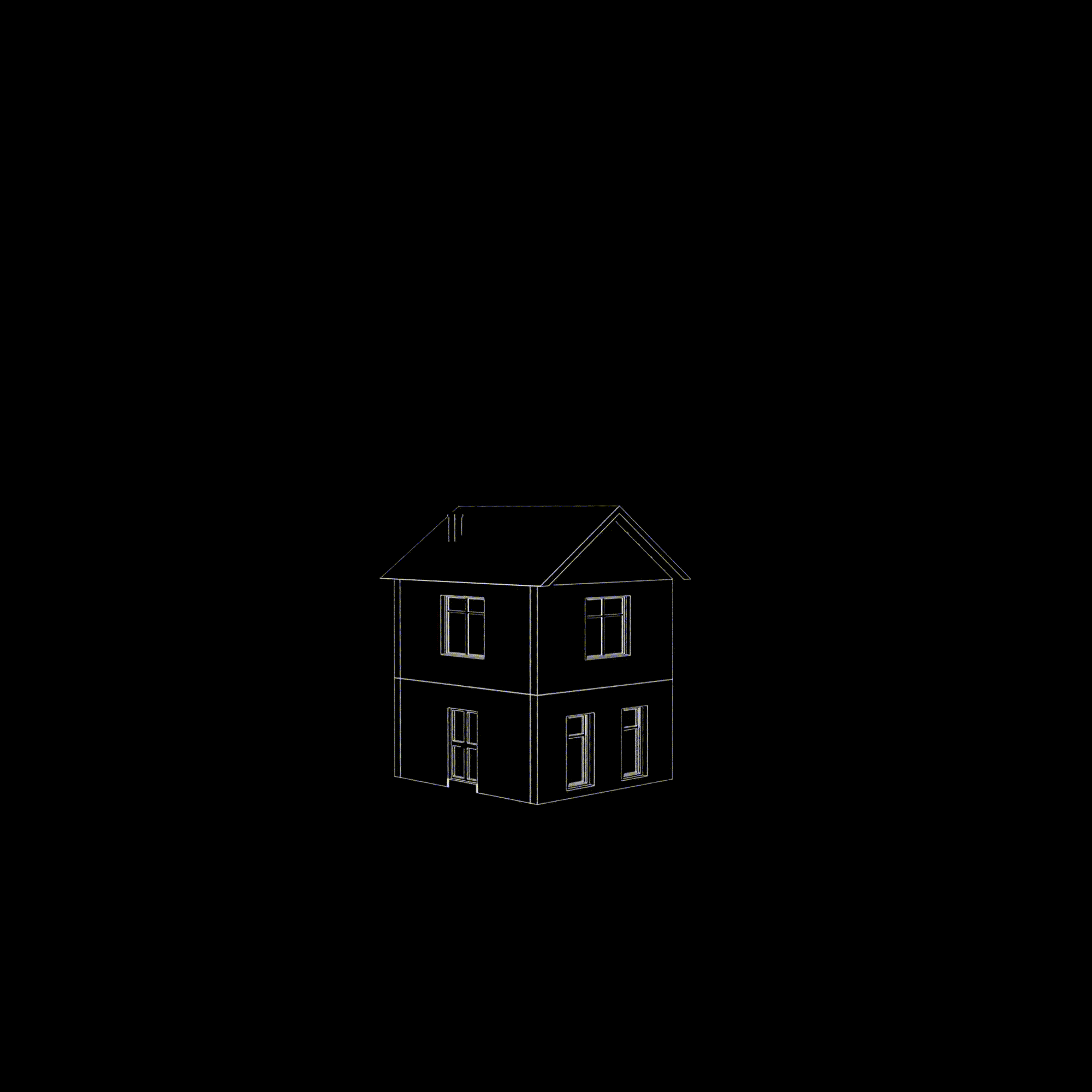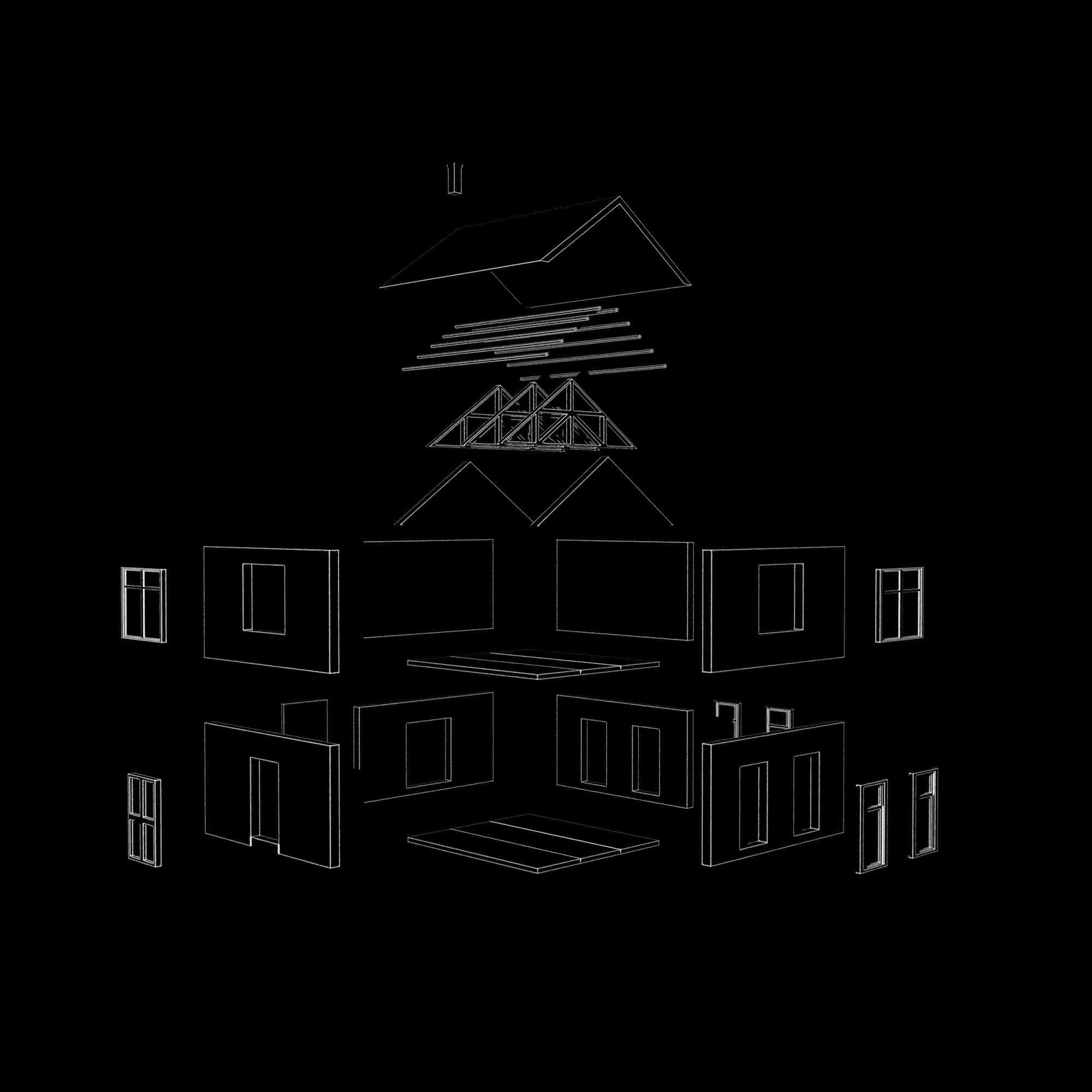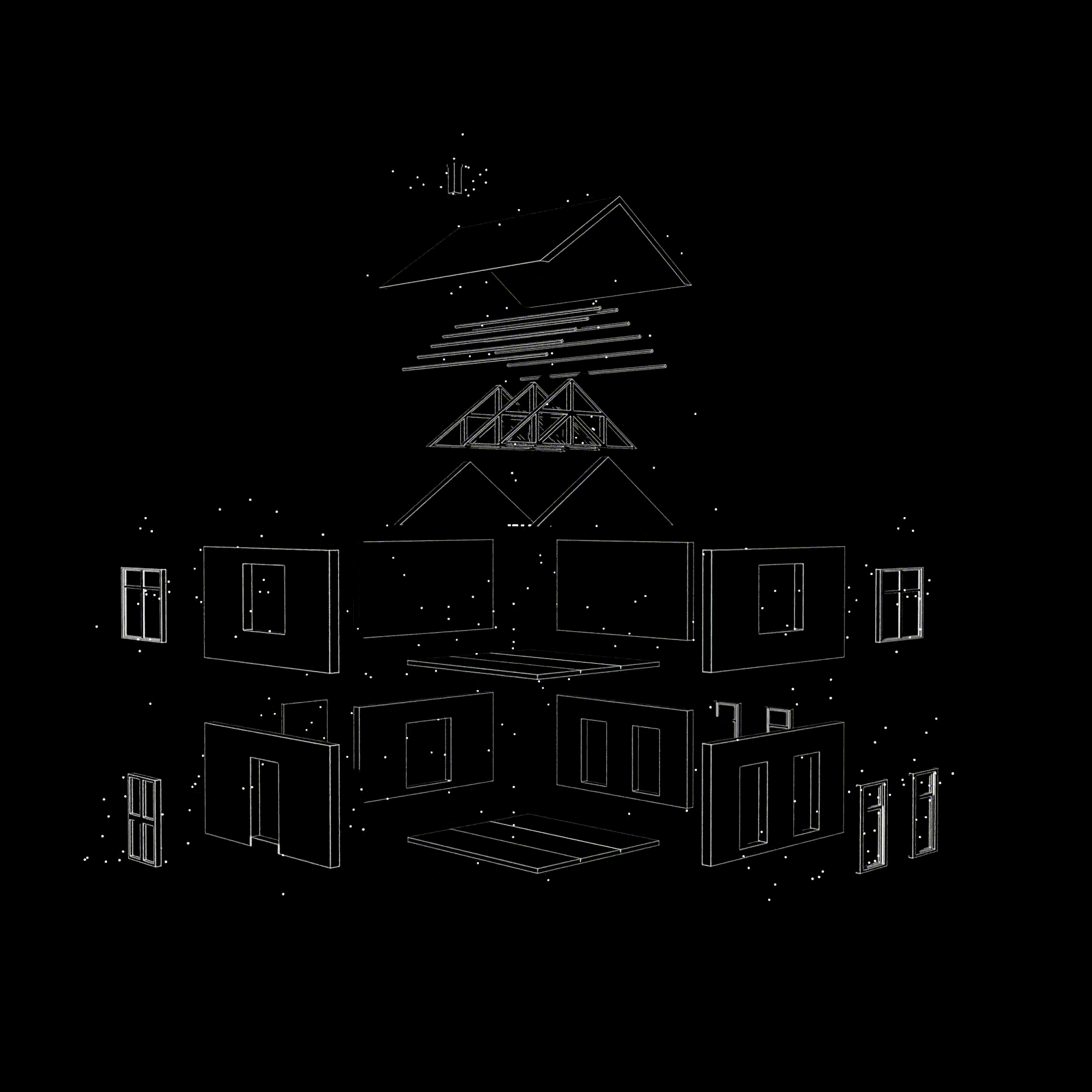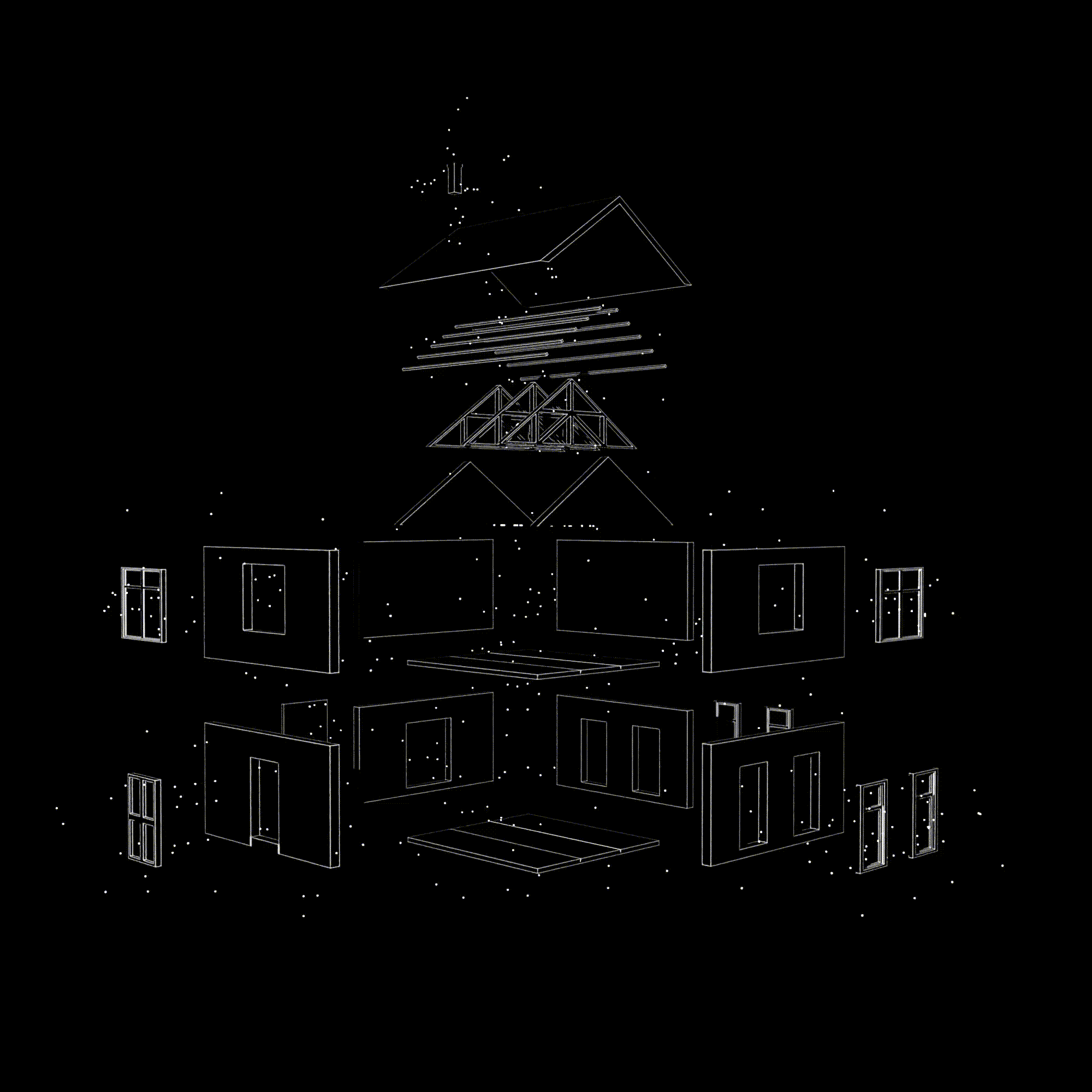
We’ve already explored the basics. The next step is to see if the chatbot can read IFC files, compare them with regulations, and maybe, just maybe, use graphs to understand relationships better.
IFC files are fascinating. They’re text files that work across software platforms, great for analysis and simulations.
Let’s take a door as an example
An IFC file might look like a mess of all-caps words and hashtags like:
ISO-10303-21;
HEADER;
FILE_DESCRIPTION((‘ViewDefinition [CoordinationView, QuantityTakeOffAddOnView]’,’RevitIdentifiers [VersionGUID: be9406ae-1255-4fa0-a527-78681dfc7380, NumberOfSaves: 3]’,’CoordinateReference [CoordinateBase: \X2\041E0431044904380435\X0\ \X2\043A043E043E044004340438043D04300442044B\X0\]’),’2;1′);
FILE_NAME(‘\X2\041D043E043C04350440\X0\ \X2\043F0440043E0435043A04420430\X0\’,’2024-06-13T21:42:28+01:00′,(”),(”),’ODA SDAI 22.12′,’23.1.10.4 – Exporter 23.2.2.0 – \X2\0410043B044C044204350440043D0430044204380432043D044B0439\X0\ \X2\0438043D0442043504400444043504390441\X0\ 23.2.2.0′,”);
FILE_SCHEMA((‘IFC2X3’));
ENDSEC;
DATA;
#1=IFCORGANIZATION($,’Autodesk Revit 2023 (RUS)’,$,$,$);
#2=IFCAPPLICATION(#1,’2023′,’Autodesk Revit 2023 (RUS)’,’Revit’);
#3=IFCCARTESIANPOINT((0.,0.,0.));
#4=IFCCARTESIANPOINT((0.,0.));
#5=IFCDIRECTION((1.,0.,0.));
#6=IFCDIRECTION((-1.,0.,0.));
…
#1204=IFCDOORLININGPROPERTIES(‘0uj_lNU1D3xhVmgpn2QnOB’,#18,’\X2\041E04340438043D043E0447043D044B0435\X0\-\X2\042904380442043E0432044B0435\X0\:0915 x 2134 \X2\043C043C\X0\:276007′,$,$,$,$,$,$,$,$,$,$,$,$);
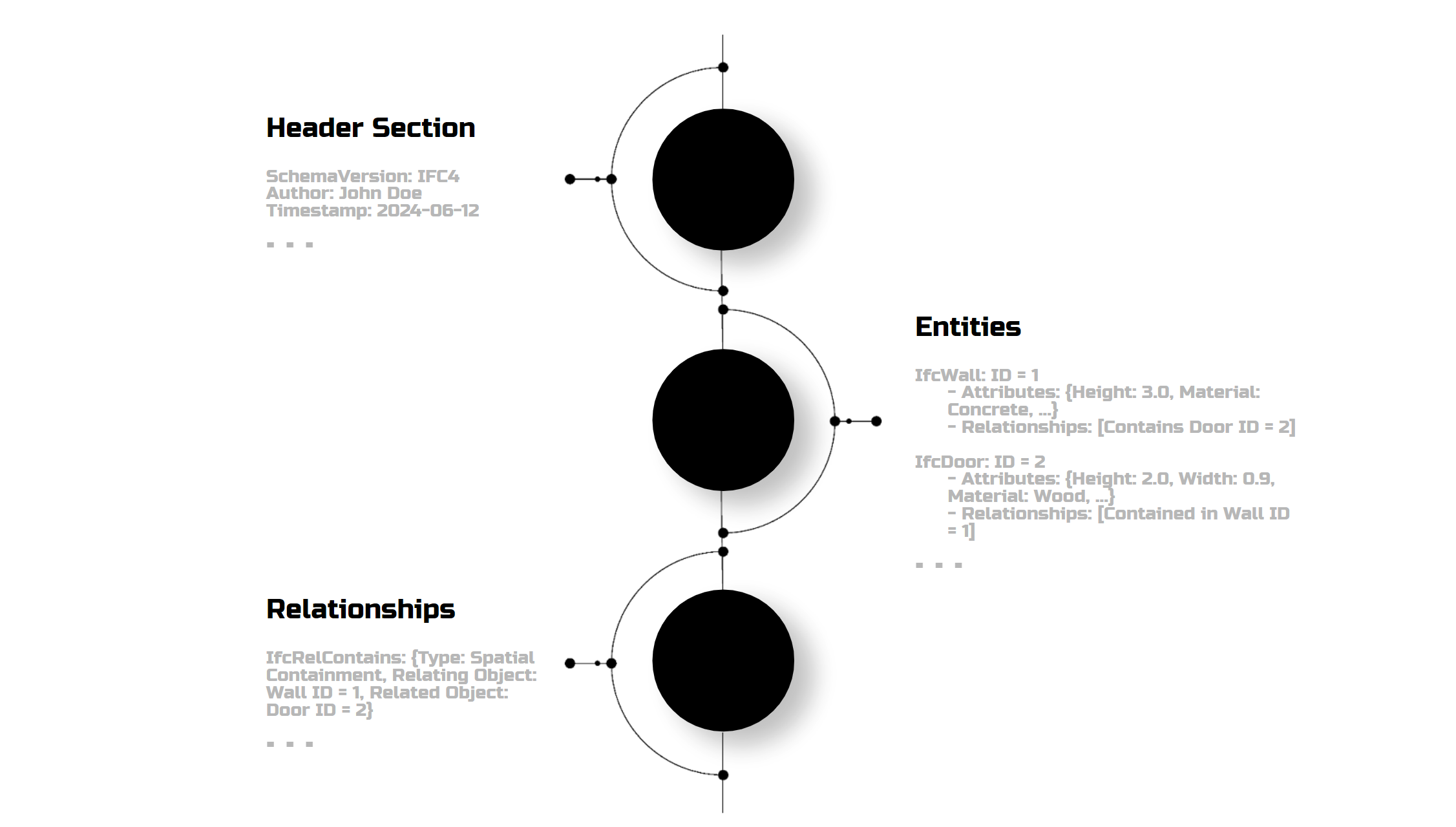
But if we structure it into a table, it reveals Global ID, Name, Description, Object type, dimensions, and more—all in text. And we need text, so it starts to make sense, right?
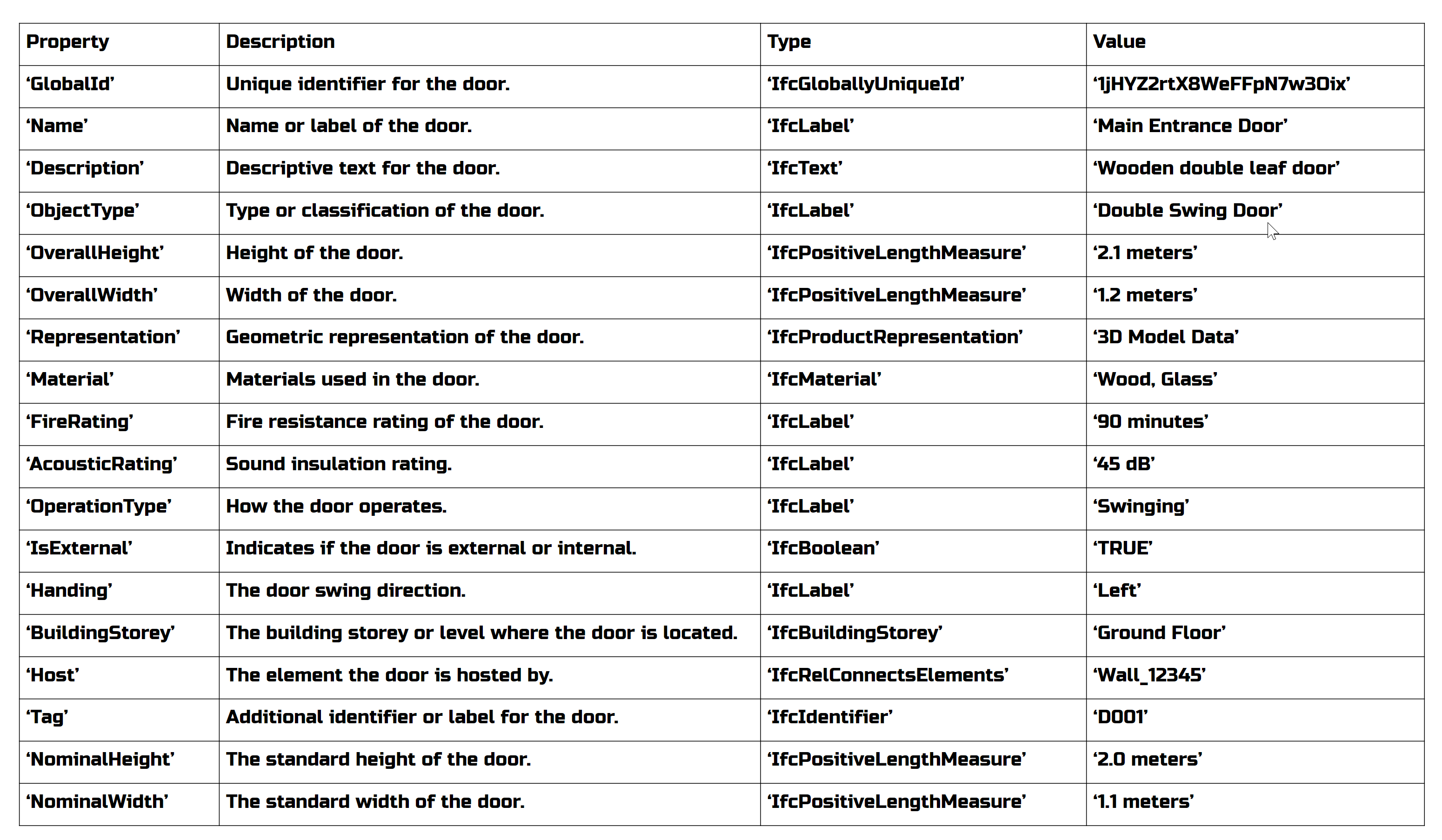
The file structure includes a header, entities (elements with properties), and their relationships. With proper BIM management, we can extract a wealth of information
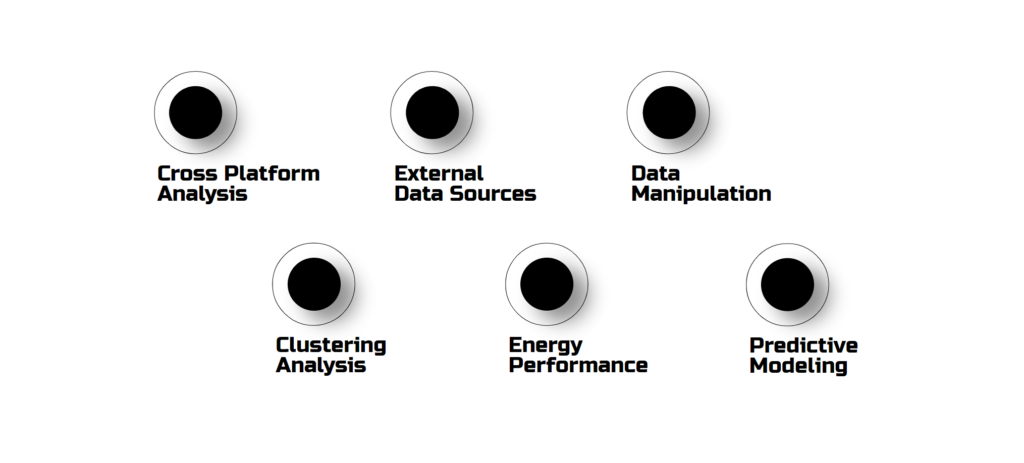
Beyond Revit, IFC allows for cross-platform analysis, data manipulation, clustering, energy performance analysis, and even machine learning predictions.
Many projects implement it for different purposes—model viewing, data management, property changes, and querying the model and its properties.
I ran a few tests to see how IFC querying works. First, I explored different formats and properties, then passed them through IFC_Reader code, and asked the chatbot to read them and answer my questions. It could count elements and give dimensions, but not always accurately. Why? Because my manual algorithms of defining what to extract from a file weren’t cutting it.
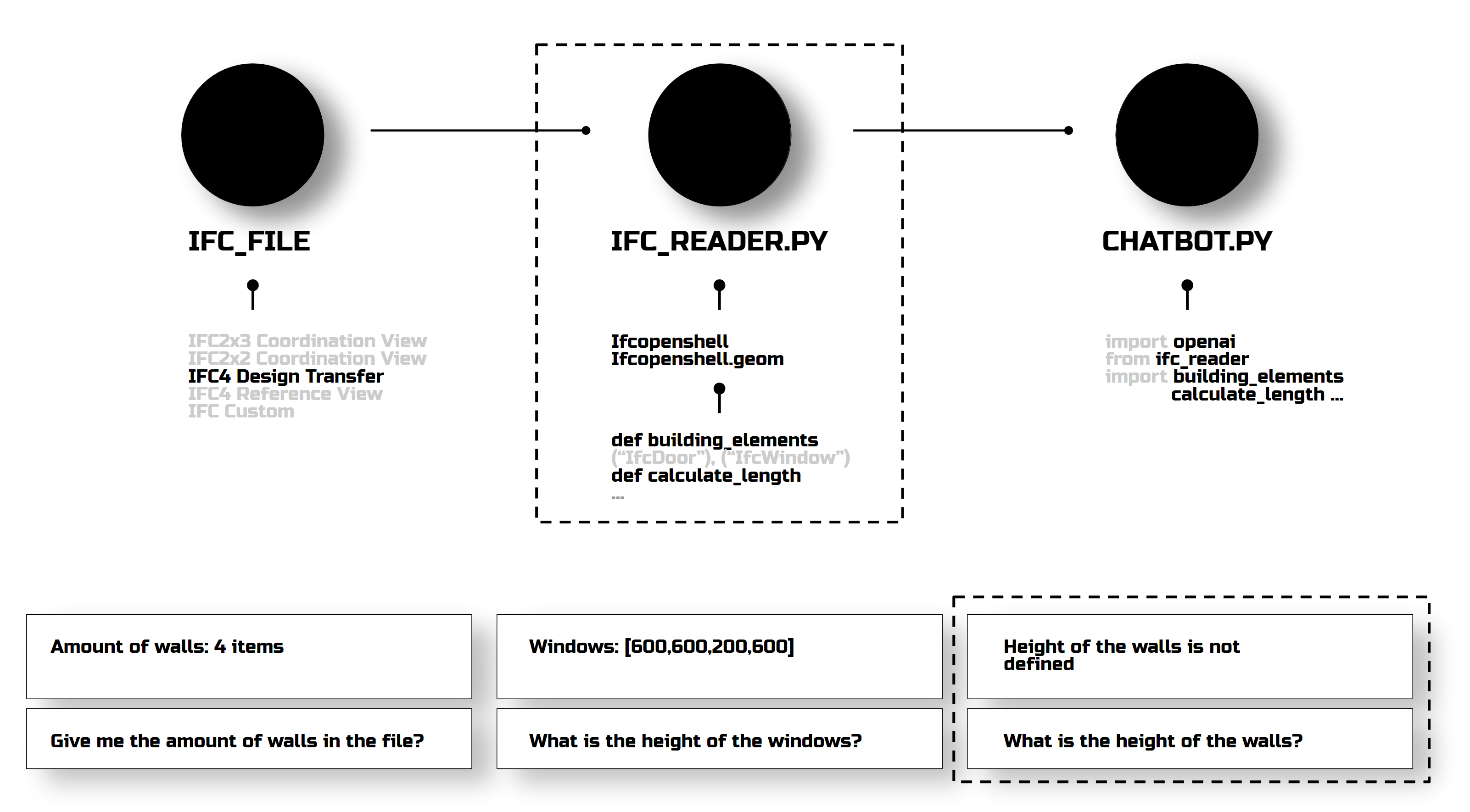
In another experiment, I improved the chatbot prompts instead of manually specifying all IFC elements. But we hit token limits, so I tried summarizing documents, which led to biased responses. For example, it doubled the window count in a project. So, that test was a bit of a disappointment.
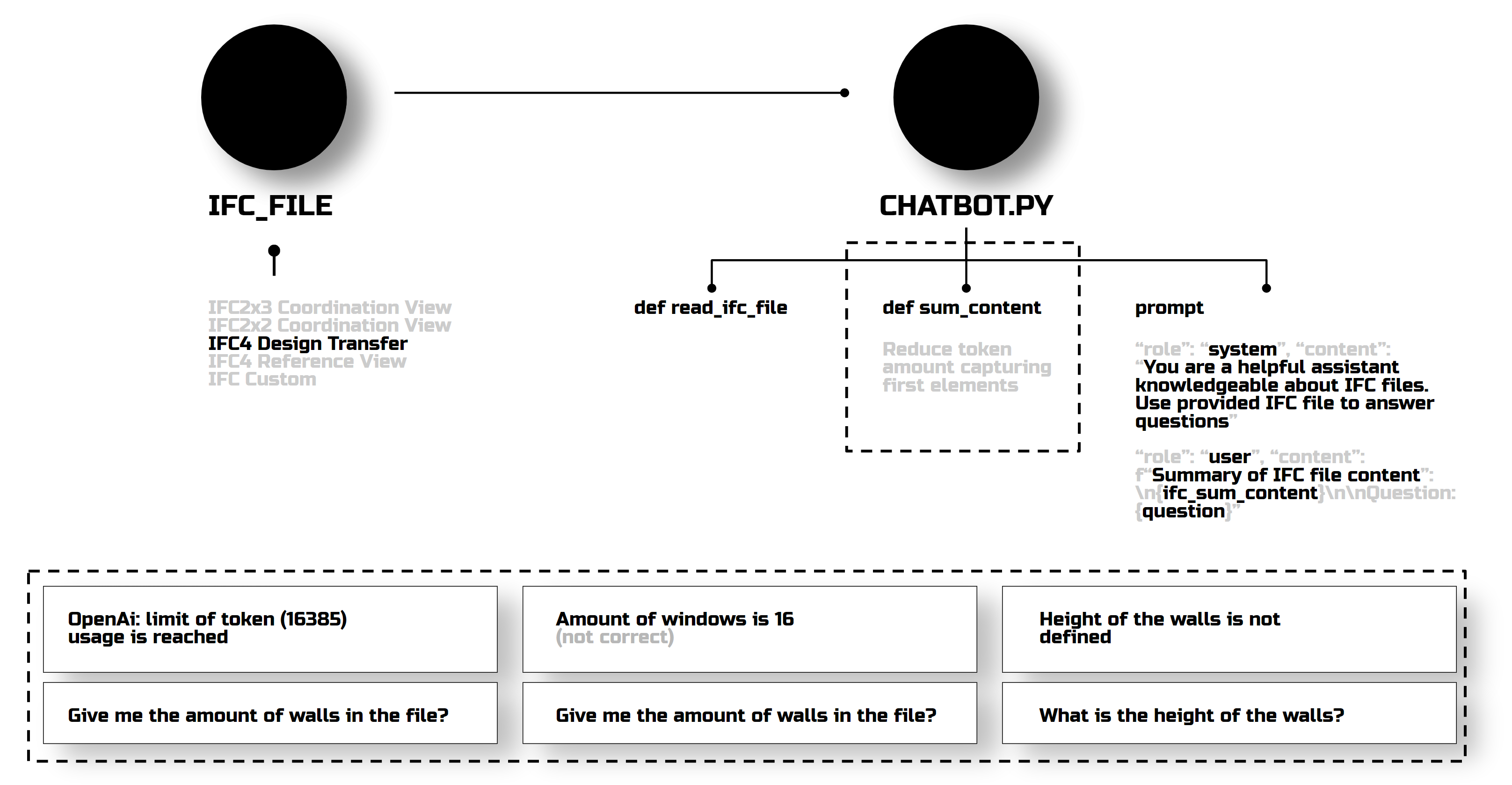
I decided to keep the summarization part to avoid exceeding the token limit. I added a step to convert the file to CSV format, as we saw in the door example earlier. First, this didn’t give any bias in counting elements; it started to understand dimensions, but still didn’t read the floor height. This was frustrating, but I decided to leave it for later and try comparing the IFC with the PDF.
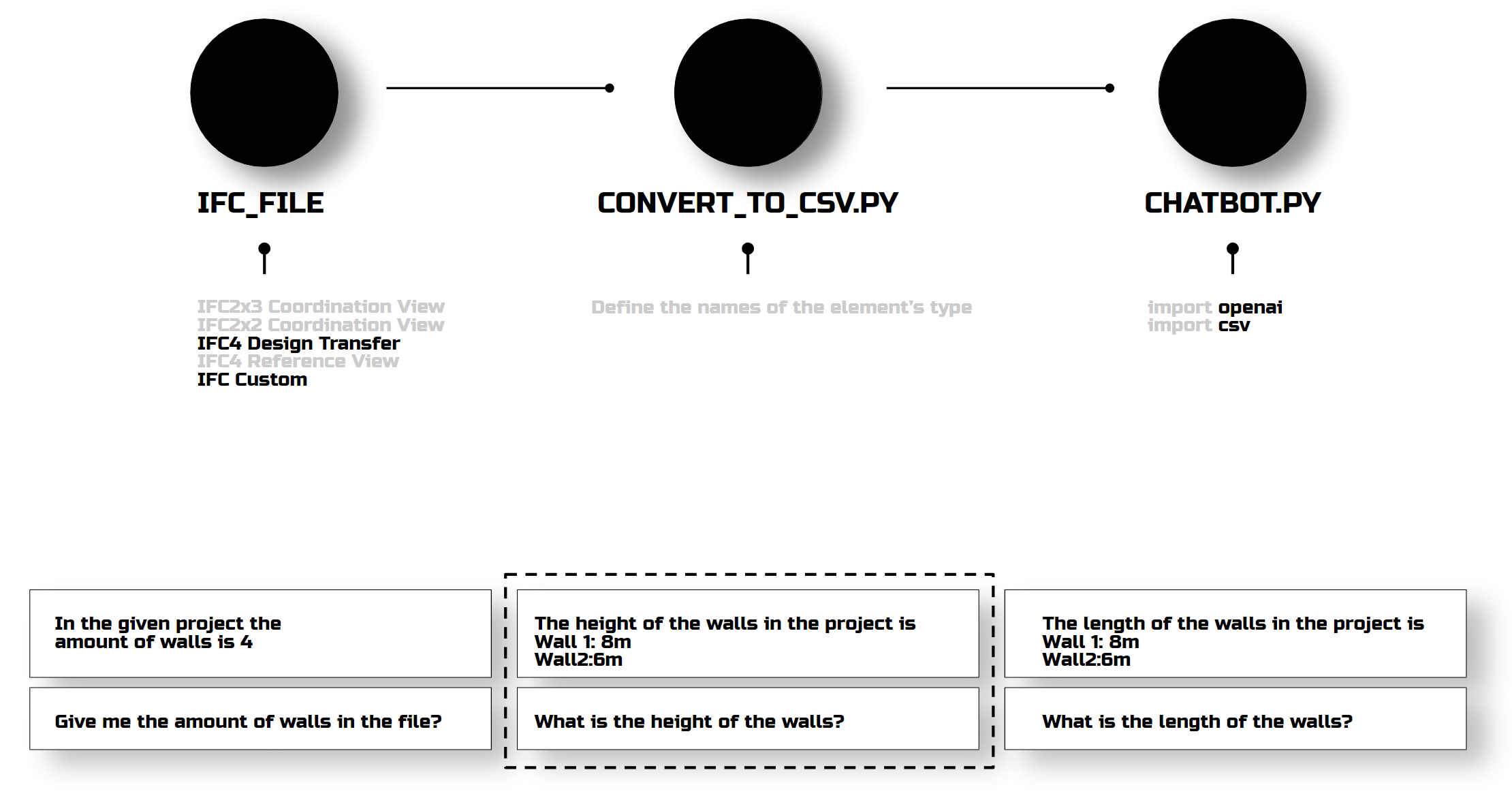
I created a small-scale PDF with my own regulations to see if the strategy works on a small scale. Spoiler alert: it worked.
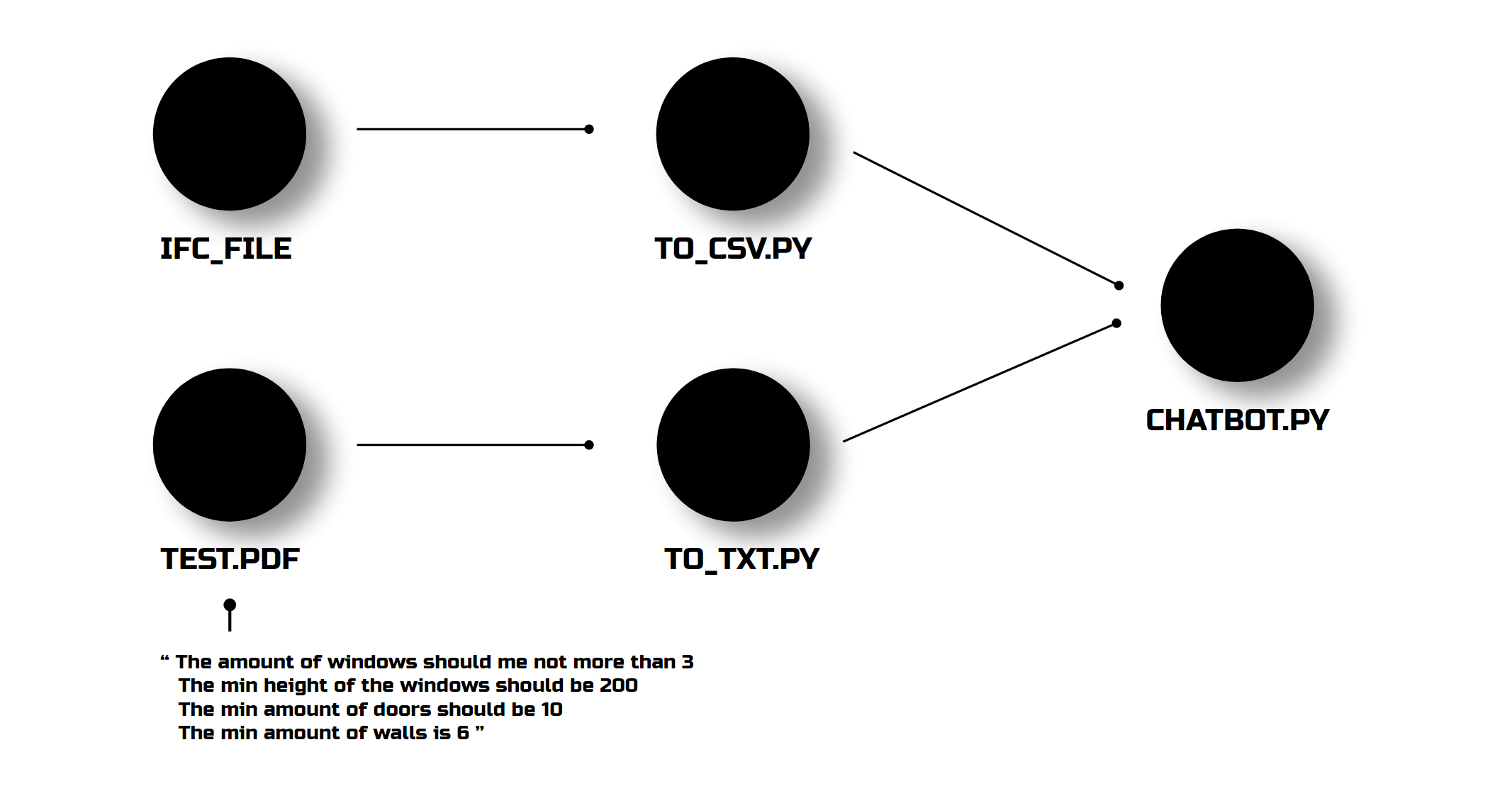
It started comparing and providing correct answers about regulation compliance. But, yes, the floor height issue was still there.

Limitations:
The limitations of these experiments were clear: the chatbot couldn’t calculate paths without a prewritten algorithm, didn’t understand spatial relationships, couldn’t perform accessibility analysis, and struggled with complex data or detailed models.

CONCLUSION:

