

My name is Aleksandra, and I hate working with documents.
I hate it so much that I dedicated my thesis to this, specifically to building codes in the European Union.
Dear colleagues, I think you can relate to this. Do you remember yourself working with building codes? Nightmare, right?

Nightmare that makes us slow. Dealing with international documents, like European building codes is tricky, cause first, you get lost in geography.

Then of course in translation.

In the structure of the laws, their names.

And when you finally find the relevant document, they ask you to pay for it, log in, or it’s out of date.
PROBLEM
“The lack of an efficient system for navigating complex building regulations affects productivity across various industries, underscoring the necessity for a specialized tool to provide guidance”
SOLUTION
“Develop a user-friendly tool designed to simplify the process of understanding building regulations for both professionals and general users.”
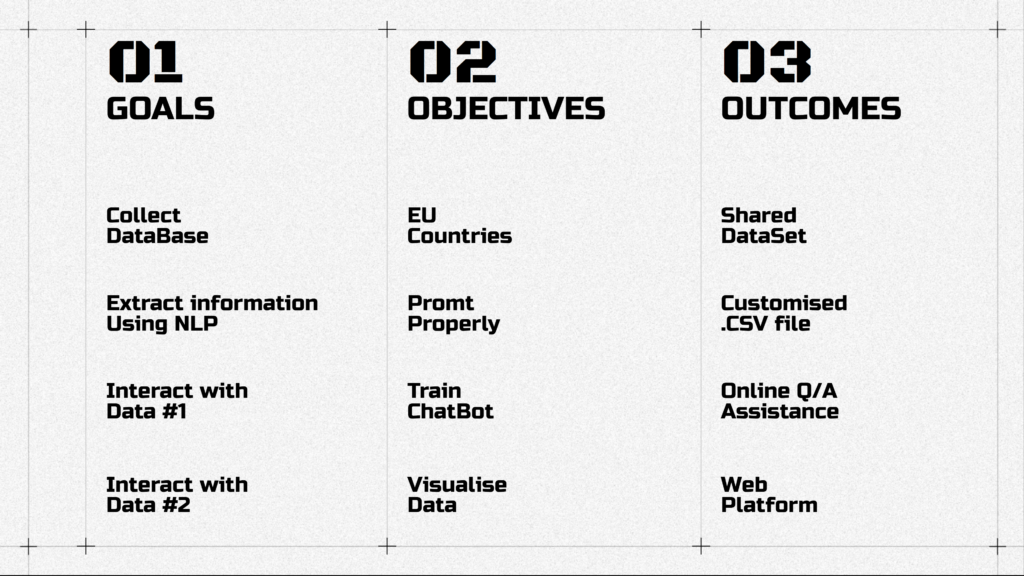
FIve steps plan of how to stop drawing in the documents and start to design.
- First – I gather all codes in one dataset
- Second – Extract information from this dataset using some magical coding
- Next – Train chatbot with the data i collected and cleaned
- And Last – Create a web platform where users can interact with this data

So we have three main characters right: the user, the app, the dataset. The user can explore building codes, download them or extract information in a table format. The user also gets the support from the chatbot trained on the dataset. The user can even upload the ifc model and check the compliance with relevant regulations. On top of that, the user can see the documents labeled with the coordinates and spreaded across the European Union map.
FINAL PRODUCT
“WEB platform which helps users to navigate through European building regulations by interacting with DataSet”
WHY IMPORTANT
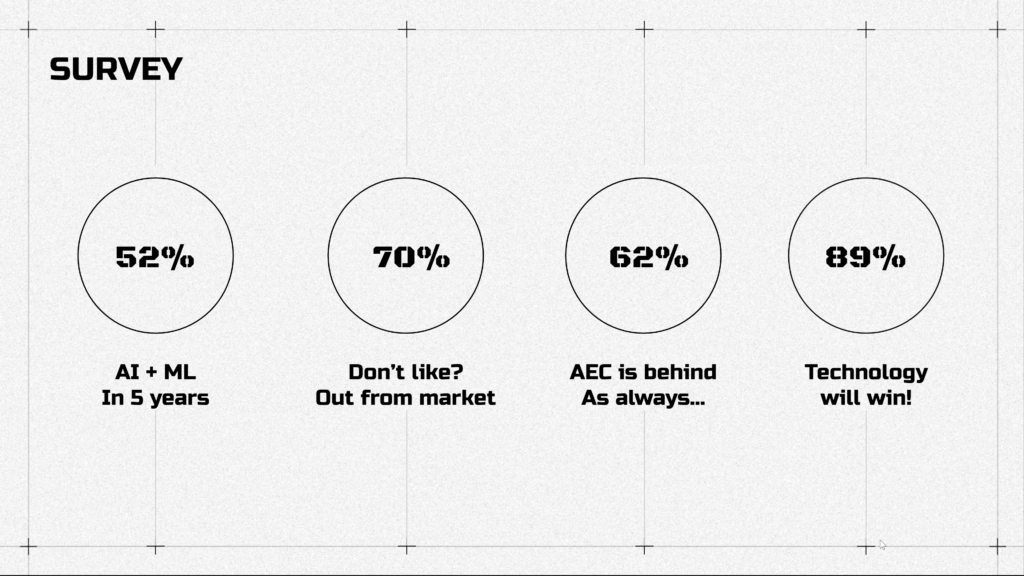
Through surveys, we can see that most AEC specialists think that new technologies and automation are required nowadays to keep pace with the rest of the world. It’s important to integrate new tools.
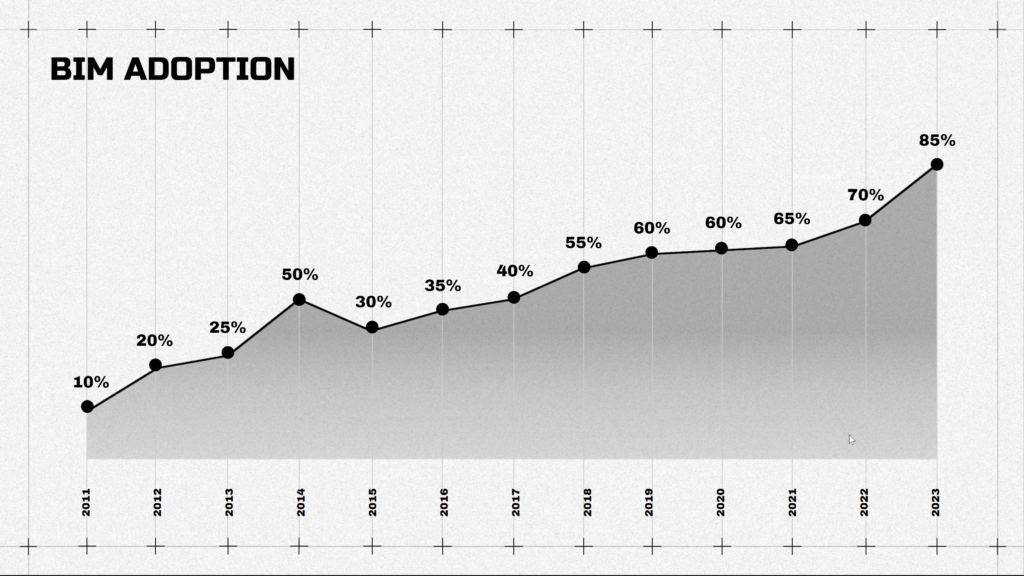
Companies keep integrating new technologies like BIM to make the workflow more efficient.
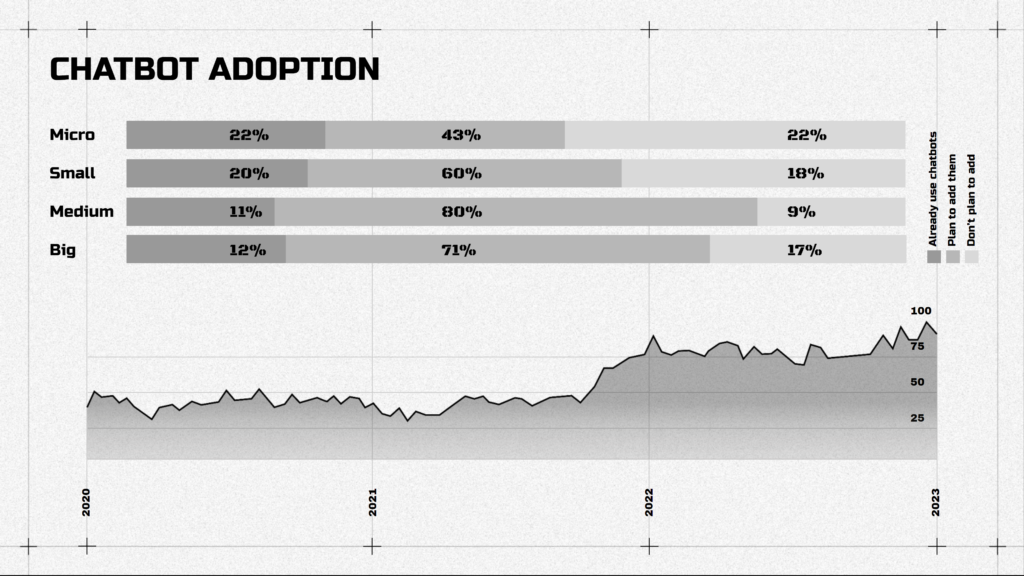
Chatbots have become an integral part of companies of different scales.

Obviously, the structure of the documents is not the same all over Europe. All of the countries have their own level of division and grouping. So, it’s the problem, the problem which could be solved.
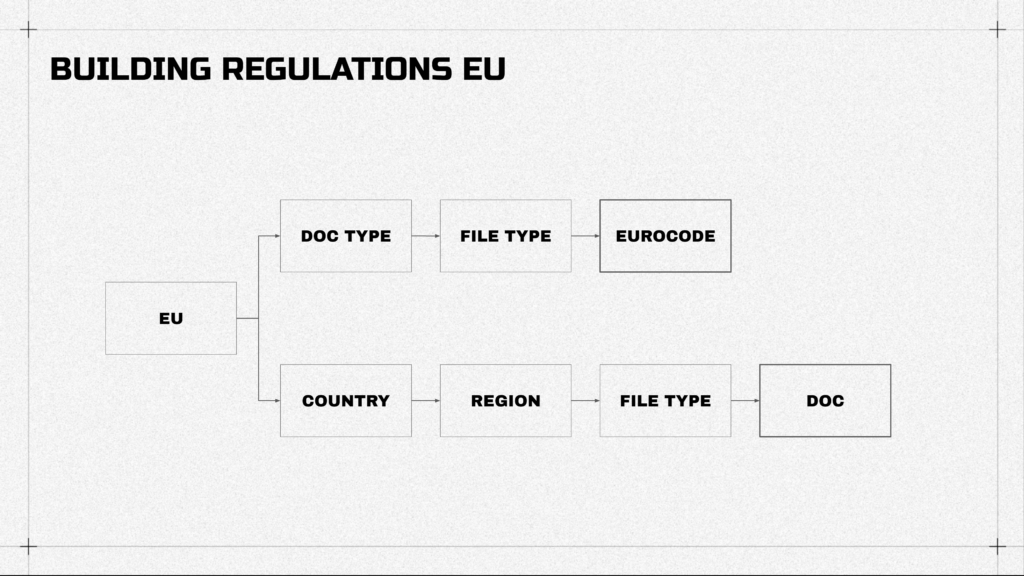
The main two divisions are Eurocodes and documents by country, and in the second, you first need to define the country, the region, the district, the municipality, city, and many more details. And again, with enough time this problem could be solved. All the data could be structured in an easy-access way.
HOW TO
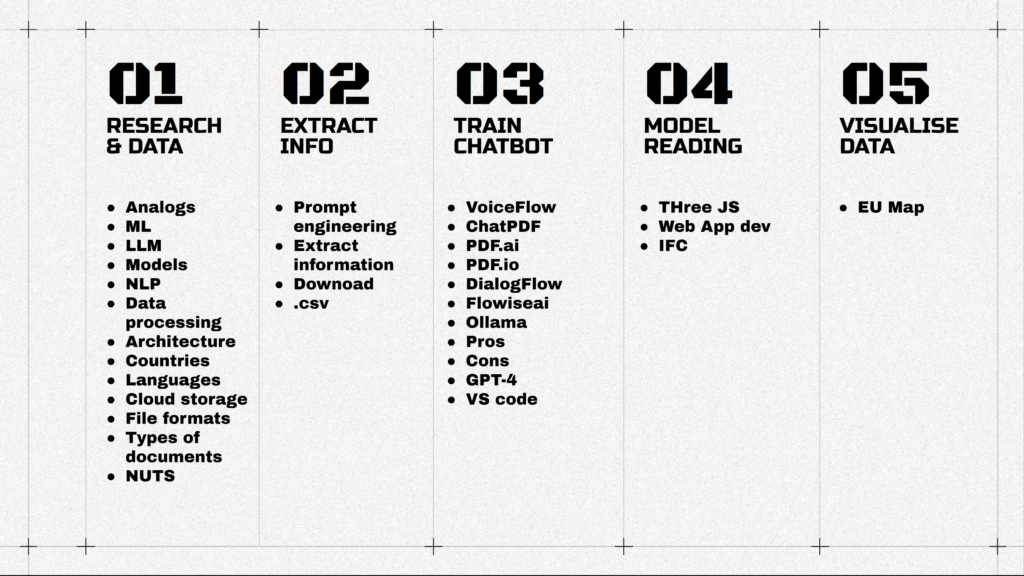
Upgraded 5 steps from previous slides:
- First – research and data collection with some keywords to check
- Than – extraction of information from it
- After – training a chatbot with it
- and later on dealing with the model reading aspect and labeling coordinates with documents.
01 RESEARCH AND DATA

As for the references
I found some interesting research from law specialists related to differences in building regulations in EU countries. Plenty of examples of chatbots trained on specific data. And there are some apps with similar datasets, but mostly for the USA.

After that when I first asked ChatGPT about ChatGPT, and how to build it a brother or sister I received plenty of unknown words.

Let’s quickly go through the main ones, I think you heard about them.
- So, thanks to Natural Processing language, computers can talk to us like a human.
- Machine Learning helps us to find patterns and with Deep learning machines can learn by human example.
- Large Language Models are super smart and are trained on big datasets and can respond to you as a real person.
- Probably some of you asked what is happening inside ChatGPT?
- Inside chatGPT tokenization is happening, it’s when big text is divided into small chunks, so the machine can read it easier.
- Embedding is basically the point when normal human words are translated into weird machine symbols, so the computer can finally read it.
- Vector Database serves as a storage for embedded text.
- And semantic search is when the machine compares the question you ask the So chatbot to the information stored in the vector base to find the best matches
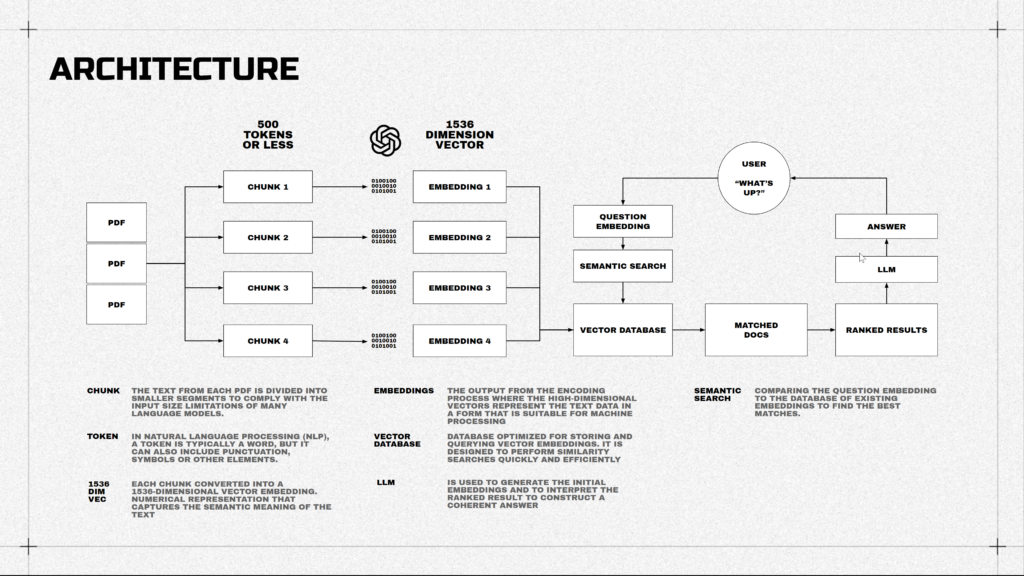
I hope you are still with me. Let’s see the architecture. Unfortunatelly there will be no beautiful examples of Peter Zumthor’s works, we will talk about a bit different architecture. How the ChatGPT and other guys work.
So, we upload our PDFs, they get divided into smaller chunks or tokens, then the text is translated into weird symbols that the machine understands and stored in the database. So when you ask a question, the machine translates it again to weird numbers, searches for the similar ones in the database, checks the matched ones, and finally starts to talk like a human with the help of one of the LLM models and NLP.

All countries in Europe divide their lands into 3 parts: States, Regions, and Districts or Communes. So I collected the data of the land division for each country, these 3 NUTS layers, to later merge it with the list of building codes. It turned out that apart from 27 countries, there are 92 States, 238 Regions, and 1217 Districts in Europe. So you can imagine the scale of the database for the building regulations.
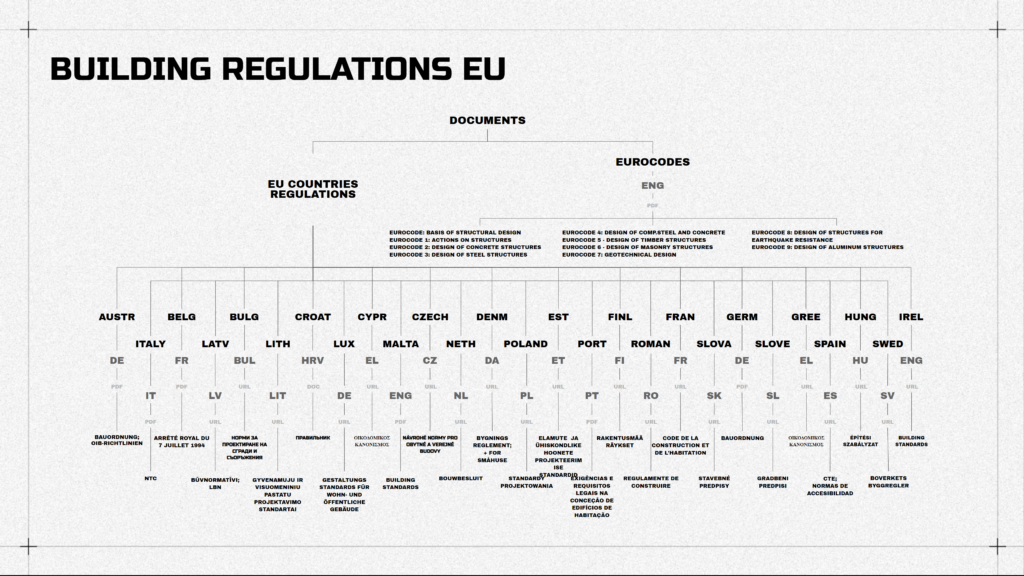
They are divided into two categories, as we talked before. Eurocodes and regulations by country. And these are only the main regulations for each country.
02 EXTRACT INFO
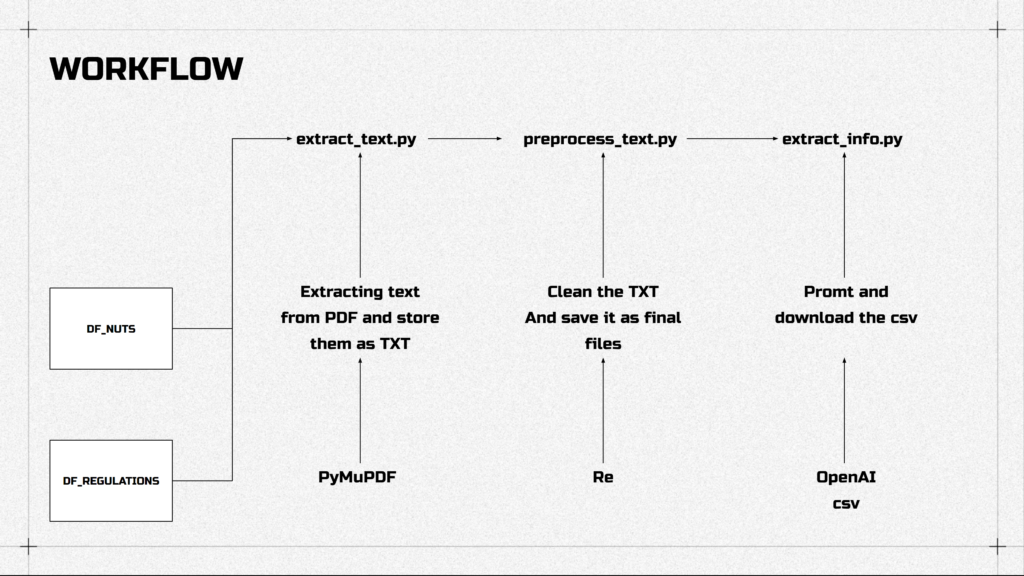
We have two datasets, one for EU units and another for document names. Of course, no one will merge it manually. From both of them, the text gets extracted from PDFs, preprocessed and by prompting only required information is extracted.
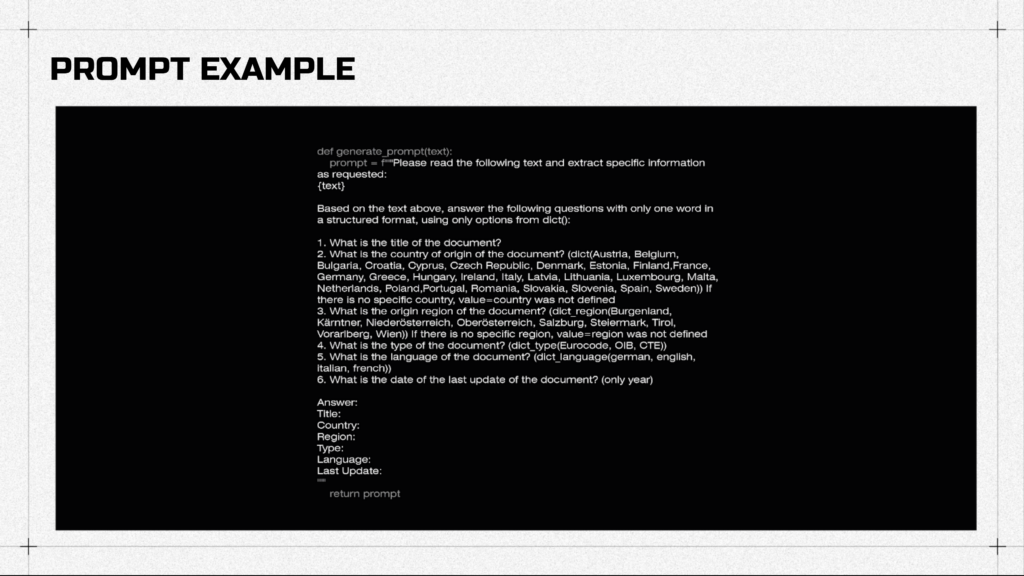
So for example, you can ask IT to give you a clean .csv file with documents name, its country, region, ets.
Just like that

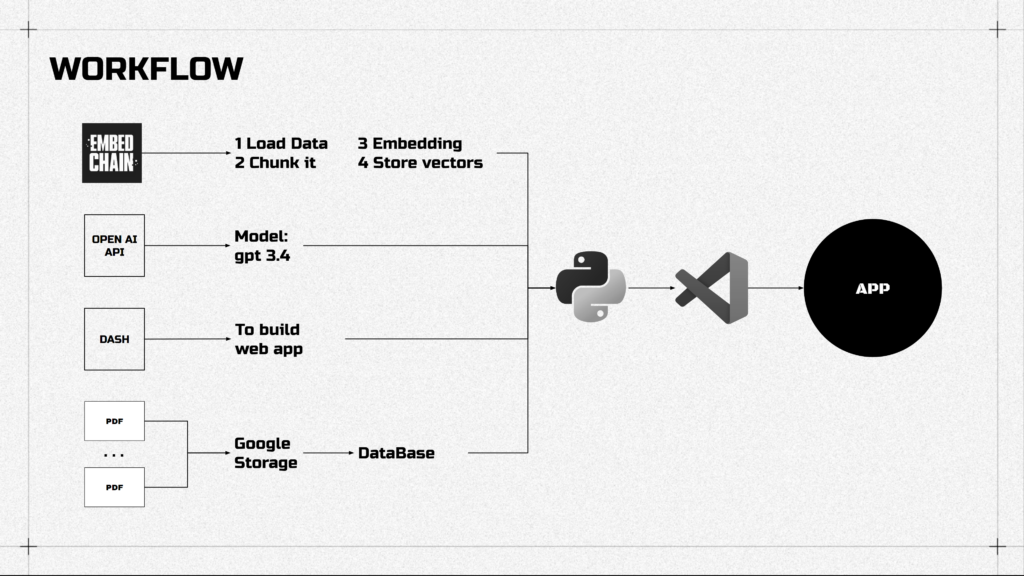
Now, people usually don’t build their own LLMs, they use APIs of existing models like gpt, bert, ets. So the workflow of building the chatbot is that we store PDFs, use an embed chain which is built on langchain, the thing for splitting the data and translating it to machine language. Then we use OpenAI API to get access to the LLM model we need.
Dash, another tool, serves as a builder for our web app.
All of this mixes together, and again by some magic coding it turns into an app.
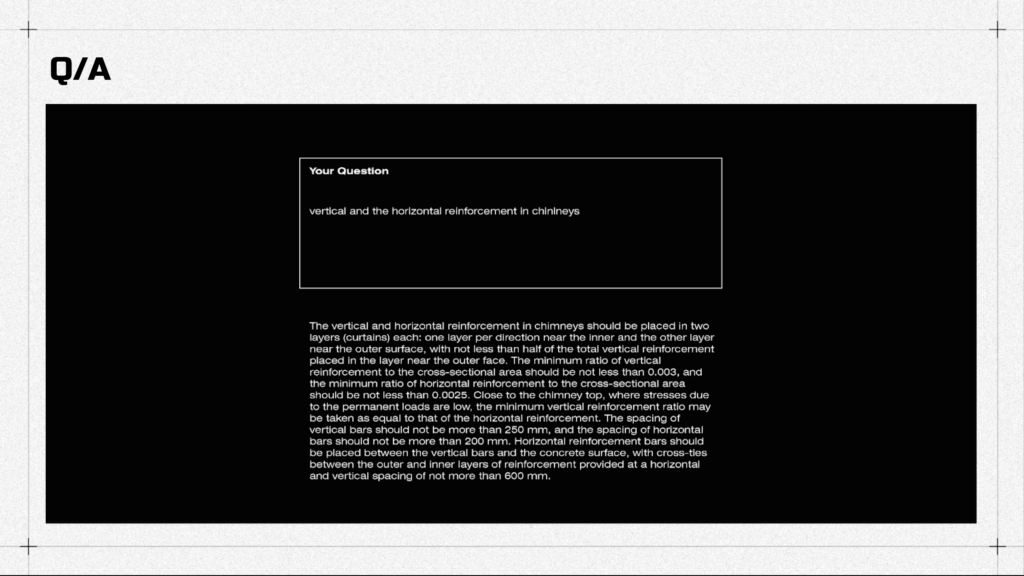
These are the responses from the demo. So it can search for the name of the documents. Or for some more specific information.

And the language problem it’s not a problem at all.
PERSPECTIVE
04 MODEL READING
Imagine being able to check the regulations for your specific project? I think it would be amazing.

So, you will upload the IFC file, which contains the objects’ definition, relationship between them. Then words like door, window, fence, roof, etc. will be extracted and the element from the IFC file will be recognized by the app. And you will be able to talk to chatbot if this exact element, from this exact model, designed in this exact country meets the regulations.
05 DATA VISUALISAION

Mapping regulations to latitude-longitude, to have a dataset that will be super useful for future use, when you start a new project or reconstruct one.
CONCLUSION

In conclusion, the platform proposed consists of a pre-trained chatbot, a way to extract information from the dataset, interaction with your model, and data visualization.
