
Multidimensional Regression-Based Model for Early-Stage Architectural Feedback
traditional daylight simulations, while accurate are extremely time-consuming, often taking hours per design option. This slows down the creative process and limits how many alternatives we can test, which ultimately impacts design quality and performance. By narrowing the scope to room-scale inputs and structured presets, we ensured our model training remained clean, con
The Problem
Definitions

Metrics:
- DA(300 lx): % of occupied hours a point ≥ 300 lx
- sDA(300/50): % of floor area ≥300 lx for ≥50% of hours
- UDI(100–2000 lx): % of hours in useful range
- ASE(1000/250): % of area >1000 lx for >250 h/yr
The problem:
- Each metric requires separate runs and waiting.
- Waiting breaks design flow and hides trade-offs.
- fewer options explored; inconsistent decisions across metrics.
To understand the challenge better, let’s look at the four key daylight metrics : DA, sDA, UDI, and ASE
Each capturing a different aspect of daylight quality. The issue is that each metric requires simulation, which means more time, more waiting, and fewer chances to explore trade-offs.
Research Question

what if we could predict all of these metrics instantly, using just the design inputs? Can a supervised machine learning regression model accurately predict daylight autonomy using geometric, climatic, and shading features — without running a single simulation?
Evaluating Existing AI Approaches
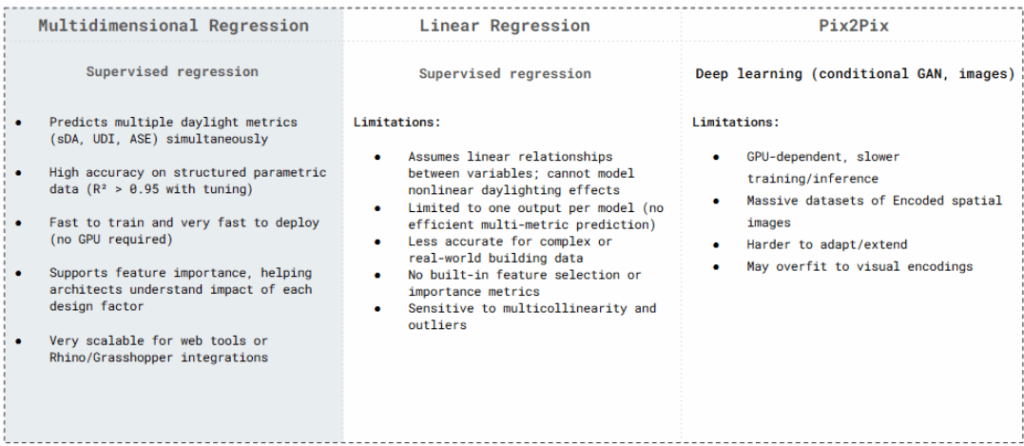
Before developing our own model, we explored existing AI techniques that have been applied to daylighting. Multidimensional regression stood out — it predicts multiple metrics with high accuracy and is lightweight enough to run without a GPU. In contrast, linear regression is too limited for our problem — it can’t handle nonlinear effects or provide multi-output results. And while deep learning methods like Pix2Pix are powerful, they require massive datasets, are GPU-dependent, and are hard to scale for early-stage design.
The Research Gap

What we found is that most existing approaches are single-objective, they either predict one metric at a time or lack the speed and interpretability needed for real-time feedback. So our direction was clear: we needed a multi-objective surrogate model — one that could predict DA, sDA, UDI, and ASE all at once, offering fast, consistent feedback and showing designers exactly which features drive change.” “This parametric control gave us diverse, yet structured, design cases for robust model training.
Our Proposal
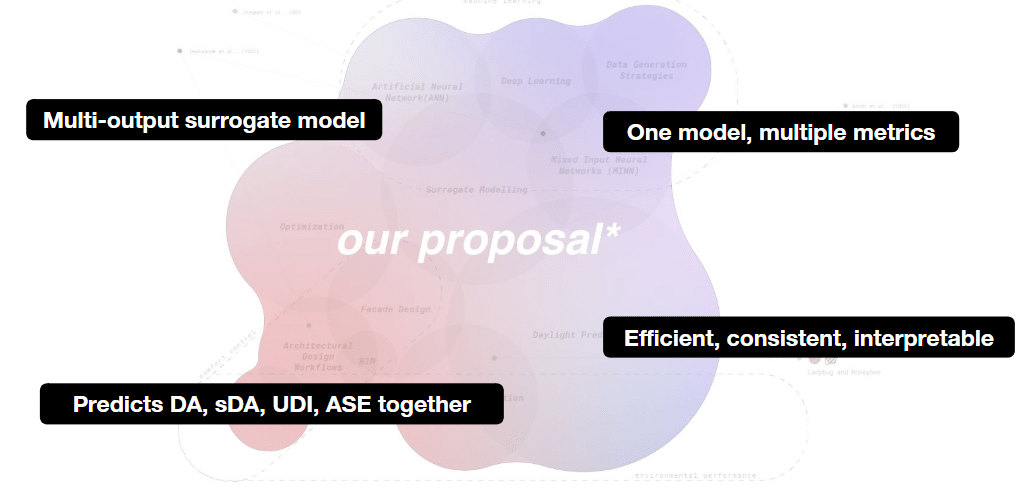
Our approach is a single, multi-output surrogate model that predicts all four daylight metrics :
DA Daylight Autonomy, sDA Spatial Daylight Autonomy, UDI Useful Daylight Illuminance, and ASE Annual Sunlight Exposure at once. It’s designed to be efficient, interpretable, and scalable for early design feedback.
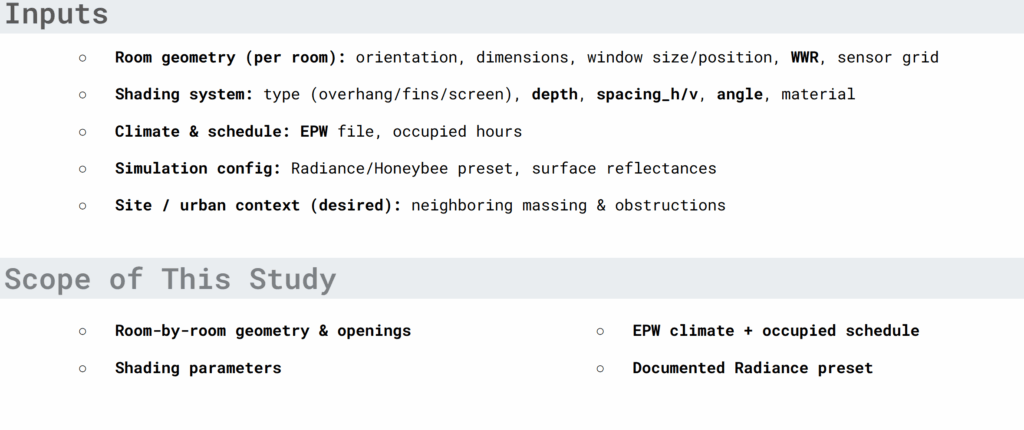
Inputs
Hypothesis

We hypothesize that one surrogate model can deliver fast, consistent, and interpretable daylight predictions using only core design inputs. To isolate model performance, we intentionally exclude site context and test across four key aspects: accuracy, efficiency, consistency, and interpretability. So we set out to unify fragmented tools into one predictive, interpretable model
Dataset Generation Workflow
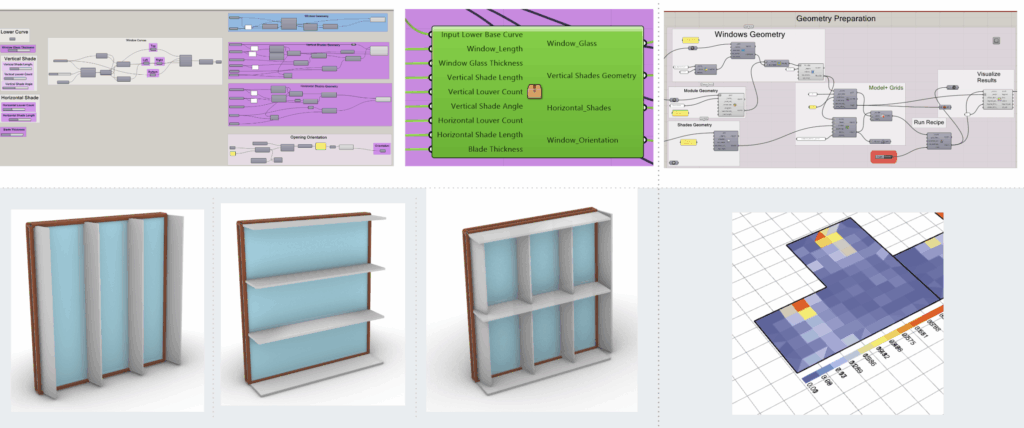
We generated a parametric dataset using Grasshopper, varying room types and shading geometries to simulate thousands of daylight scenarios. This structured pipeline allowed us to control inputs and extract reliable daylight metrics for training the model.
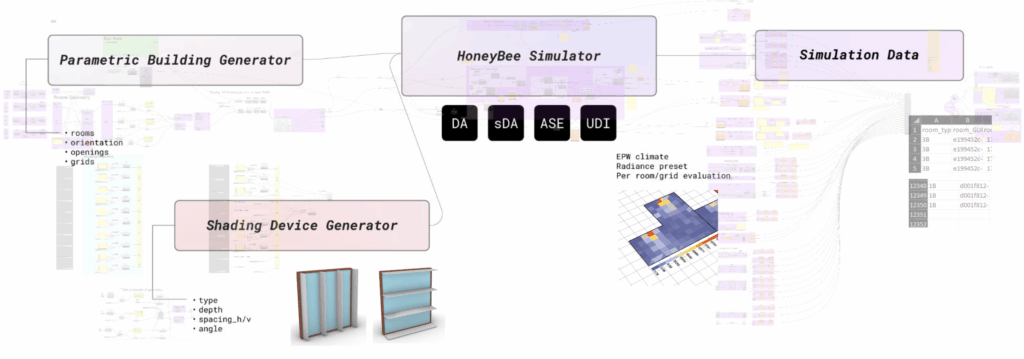
We created a fully automated pipeline combining parametric room and shading generation with Honeybee simulations. This setup allowed us to generate a large, structured dataset of daylight metrics under consistent conditions.” “This means architects can test more ideas, iterate quicker, and stay in the creative flow.
Feature Engineering for ML Training
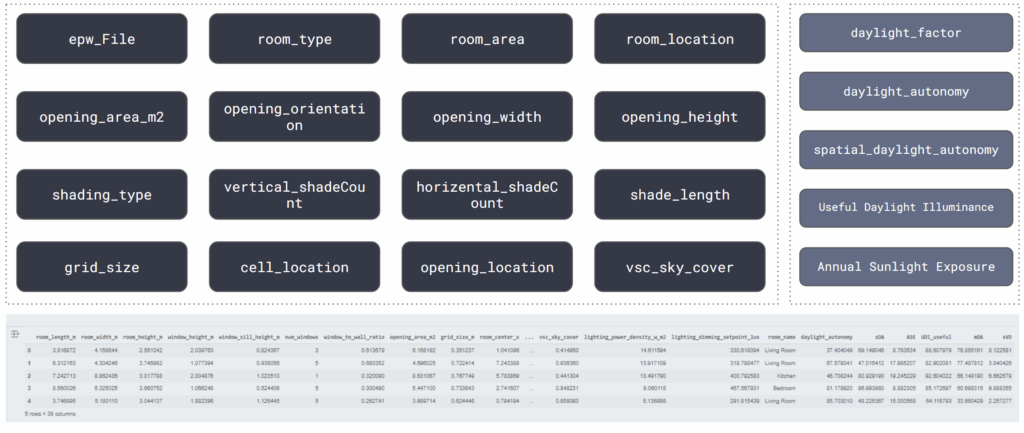
We structured the dataset into well-defined input features , like geometry, shading type, and climate , and daylight metric outputs. This clean format made it easy to train and evaluate different machine learning models. This automation ensured consistency and scale — we could generate thousands of variants without manual intervention.
How the Model Transforms the Workflow
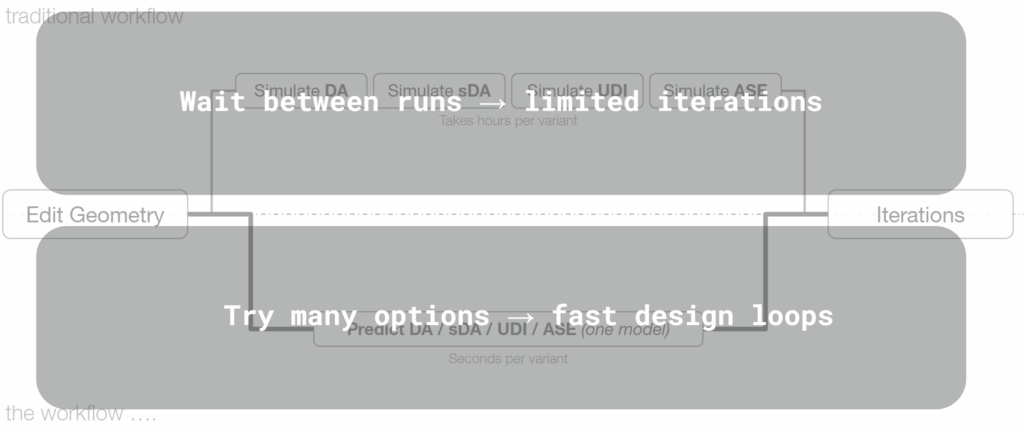
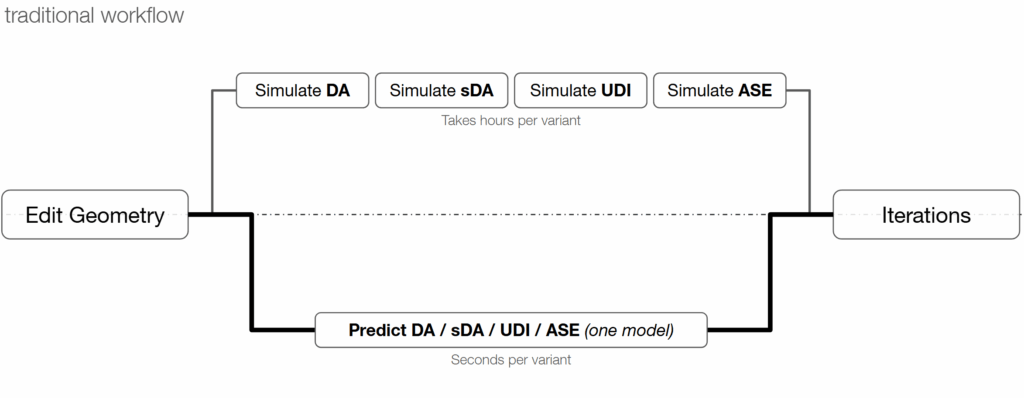
Traditionally, each daylight metric requires a separate simulation, which adds up to hours per design change. With our model, a single prediction replaces all four — reducing iteration time from hours to seconds. Its balance of performance and clarity made it the most suitable for real-time architectural use.
ML Results
Feature Importance & Model Accuracy
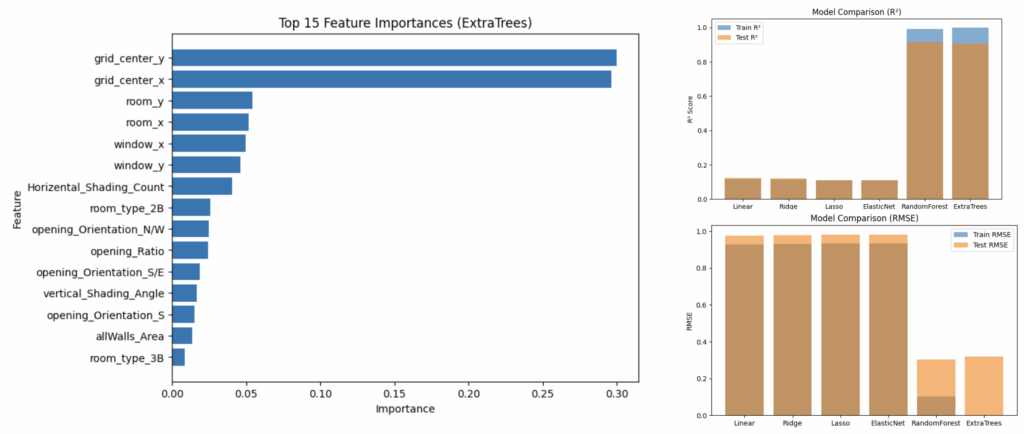
We tested several models and found that tree-based regressors — especially ExtraTrees — performed best in both R² and RMSE. The top features influencing daylight performance were grid location, room position, and shading parameters.

ExtraTrees gave the best results, with R² close to 0.9, making it our main reference model. Its predictions do more than just copy the simulation results; they also show which design factors matter most — like how the building is oriented, how deep the shading is, and the ratio of windows to walls.
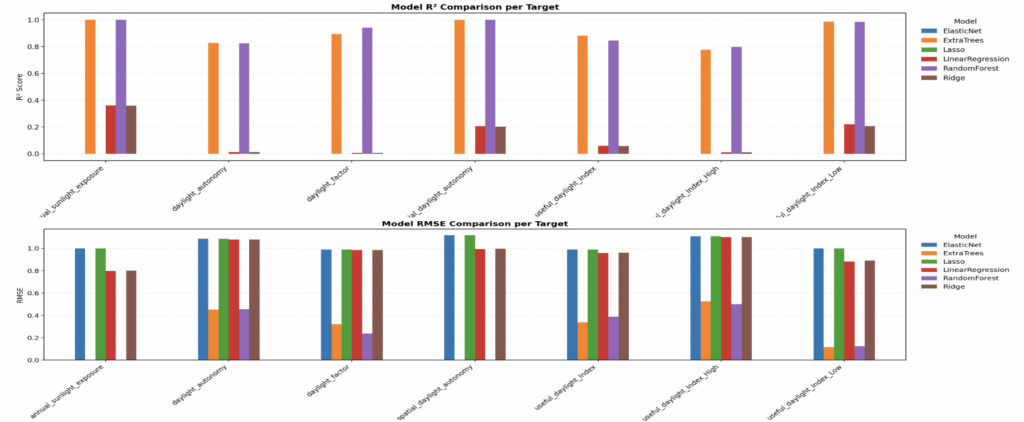
We compared multiple models across all daylight metrics to ensure robustness beyond just DA.
– ExtraTrees consistently outperformed others in both accuracy and error, confirming its generalization across targets.
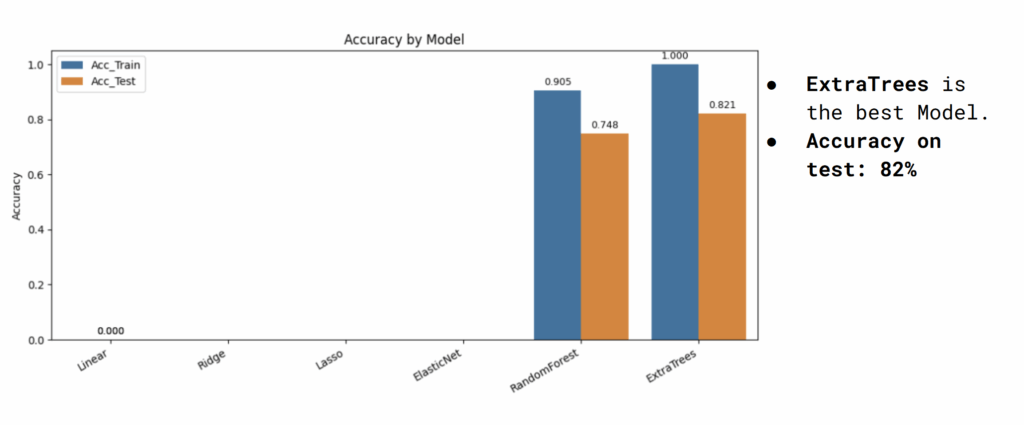
Out of all tested models, ExtraTrees gave the highest accuracy — scoring 82% on the test set. Its balance between generalization and precision makes it the best for deployment.
Speed Comparison: Simulation vs Prediction
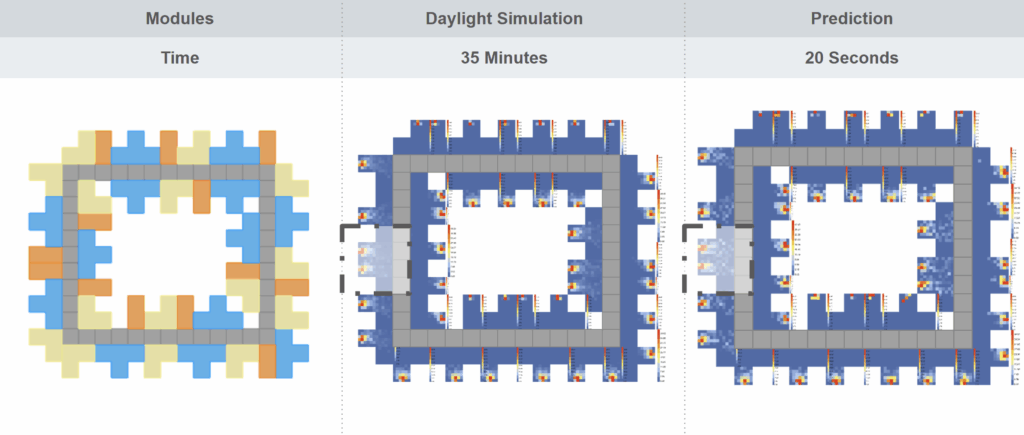
This example shows how the model reduces runtime from 35 minutes for a full daylight simulation… to just 20 seconds for prediction. Despite the speed gain, the predicted daylight distribution closely matches the simulation results.” “This structured format makes the dataset reusable — for retraining, fine-tuning, or even expanding to new metrics.
Prediction vs Simulation
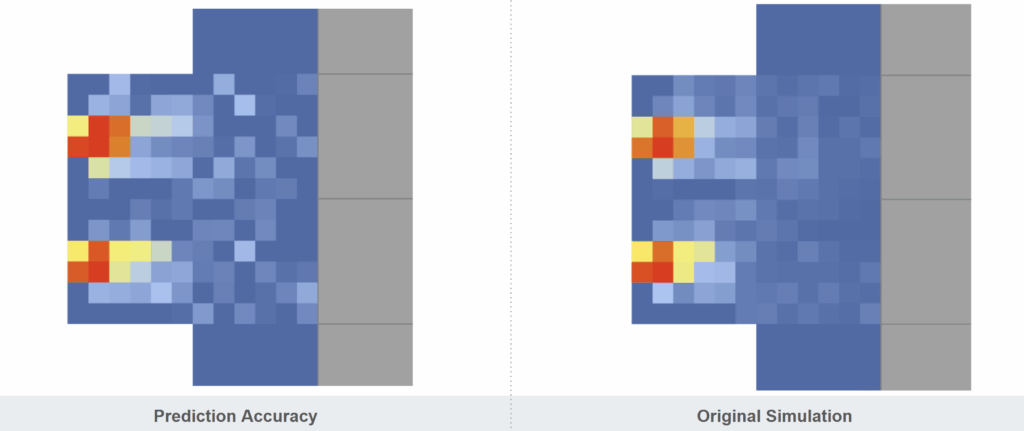
Here’s a side-by-side comparison of the model’s prediction and the original daylight simulation.
Even at 82% accuracy, it captures the high-intensity zones remarkably well — and does so in seconds.
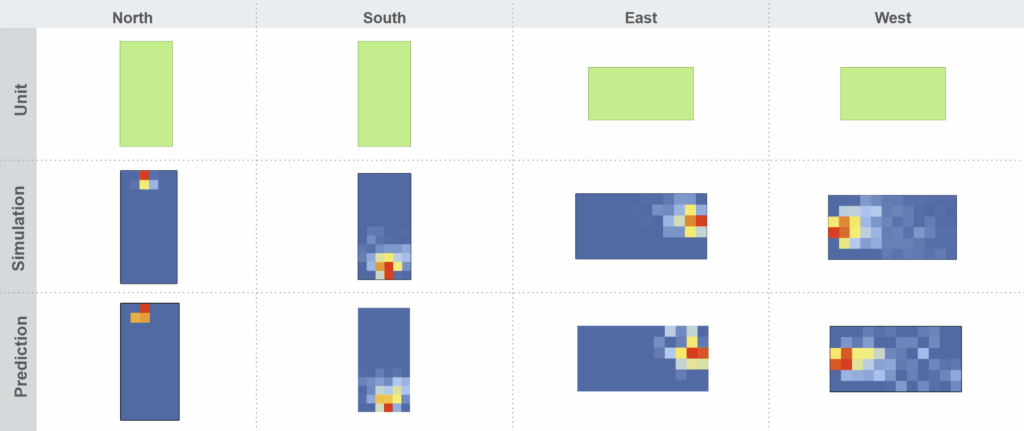
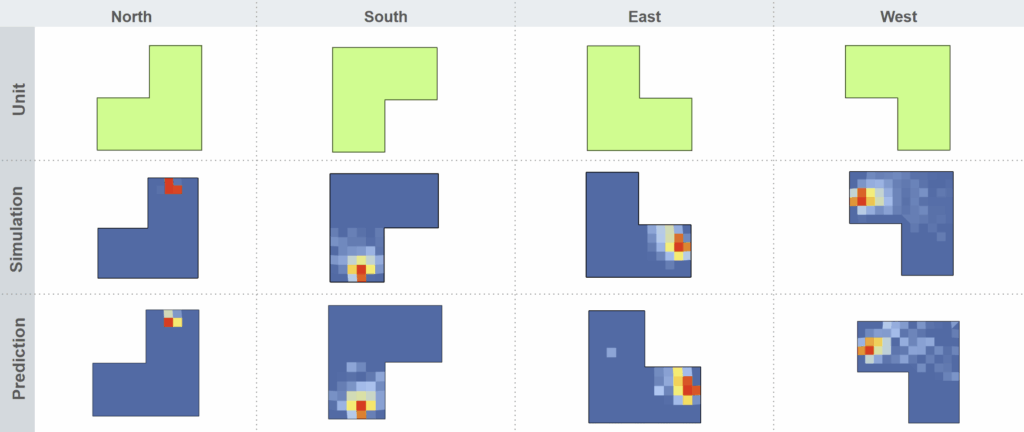
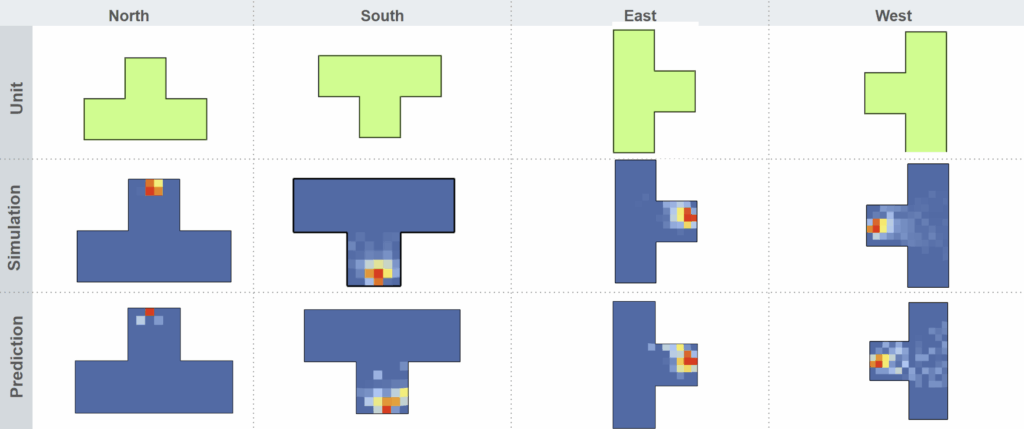
To sum up: we built one model that predicts all daylight metrics in under 20 seconds, with strong interpretability and early design support.
Next, we’ll expand our dataset and refine the multi-output architecture to improve generalization even further.
