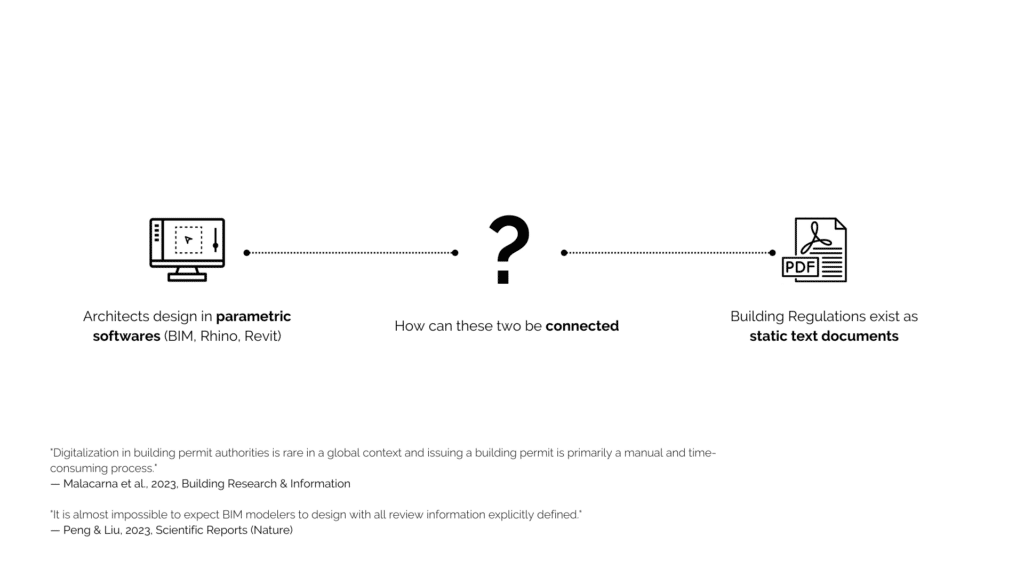
Which brings us to the disconnect. On one side, architects design in parametric software like Rhino, Grasshopper, Revit, BIM tools. On the other side, building regulations sit in static PDF documents. And between them, There’s no live connection. One is dynamic, the other is static text.
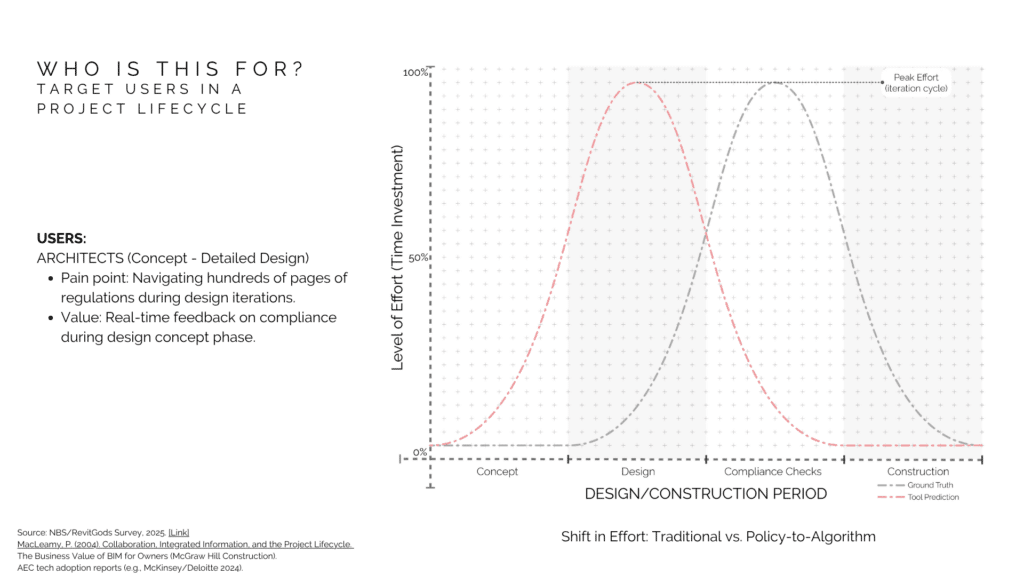
Who actually needs this? Architects. Specifically during the concept and design phase when you’re iterating fast playing with massing. Right now, compliance check happens later in the process. So the idea with Policy-to-Algorithm is to shift that effort early and get feedback while you’re still designing, to push the viability of that design during official checks.
So the starting point was asking How can building regulatory compliance be verified continuously during the design process rather than as a separate post-design activity?
Before building anything, I needed to understand what already exists out there.
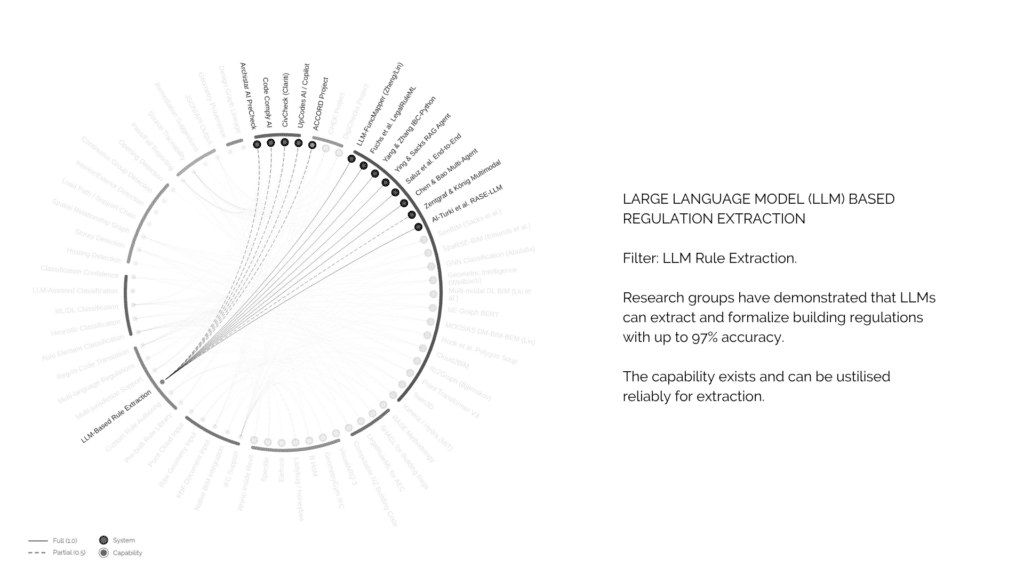
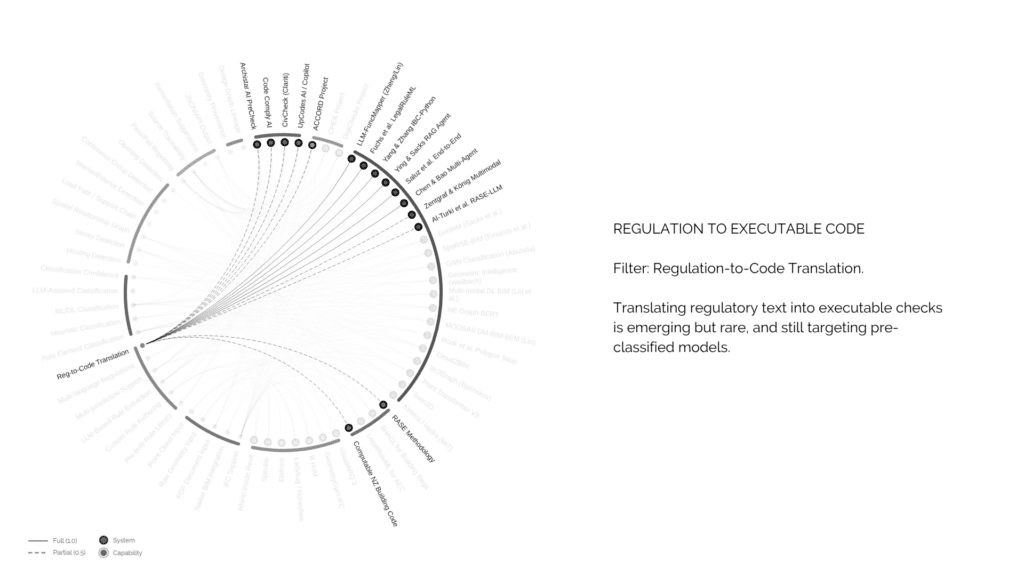
So I mapped the entire landscape. 39 systems evaluated against 29 capabilities. This is the full picture. But the key insight isn’t in the web of connections, it’s in the gaps.
looking at Large language model based rule extraction. Several research groups have shown that, these Language models can extract and formalize building regulations with up to 97% accuracy. the capability is proven. the models CAN read a regulation PDF and turn it into structured rules. This part of the puzzle exists.
translating those extracted regulations into actual executable code that can run against a checker model. This is something only a handful of systems are attempting, and most target pre-classified models, meaning you already need a fully labeled building model before they work.
In response to that Nearly 64% of the systems in this landscape require a pre-classified IFC model as input. IFC gives you geometry AND semantic labels like this is a wall, this is a window, its on the 2nd floor etc. The building has to be labeled before any compliance checking can begin.
OK so compliance needs IFC. Let’s look at what is IFC and how to use it.
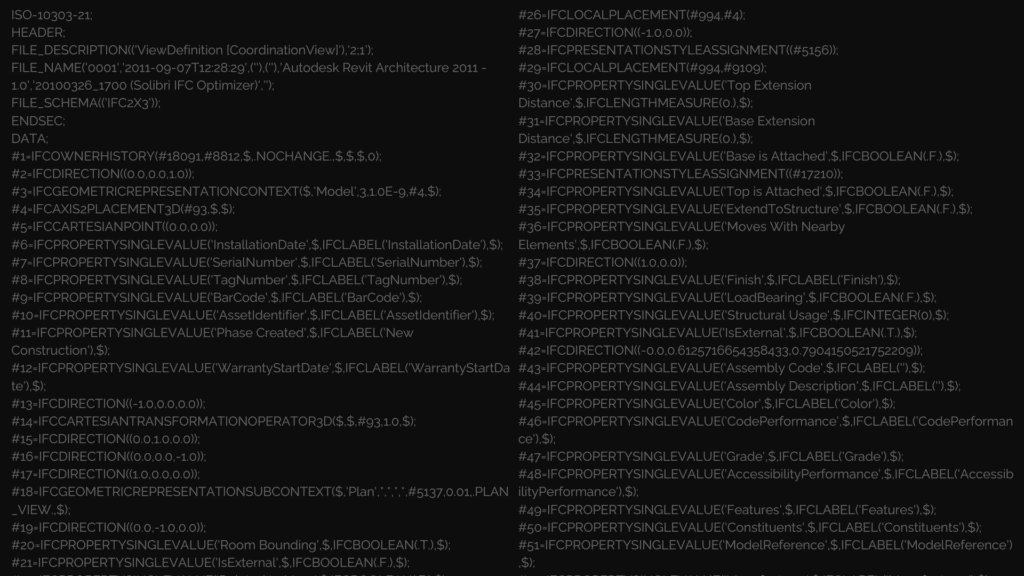
This is what an IFC file looks like. Lines and lines of text. It’s essentially a database of every property of every element in the building. It contains incredible information. But it’s not exactly friendly.
To actually USE any of this, you have to parse it. Decode it. Map properties to elements, Libraries like IfcOpenShell do this.
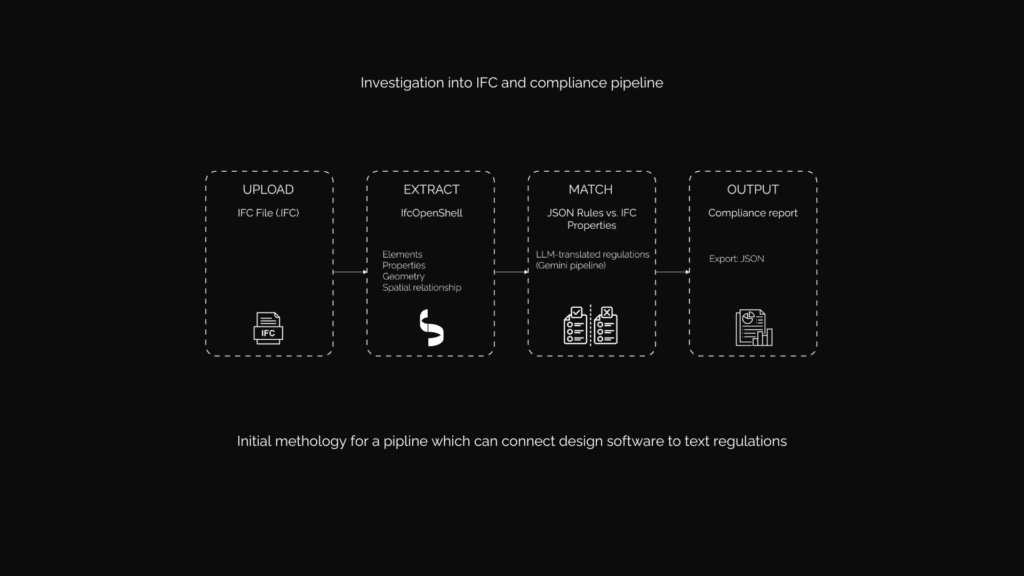
So my first investigative attempt was exactly this. Upload IFC, extract with IfcOpenShell, match LLM-extracted regulations against the IFC which output a compliance report.
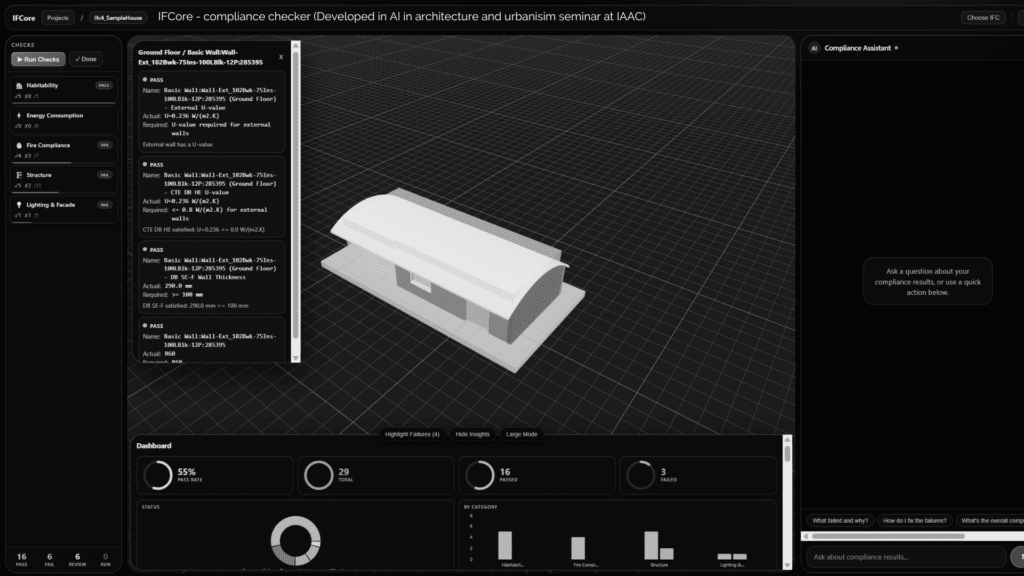
This is IFCore. the compliance checker we developed in the AI in Architecture and urbanism seminar here at IAAC. It works. You can click on elements, see pass/fail, ask the AI assistant questions. It’s a real functional tool. But then I hit a wall. a fundamental workflow problem.
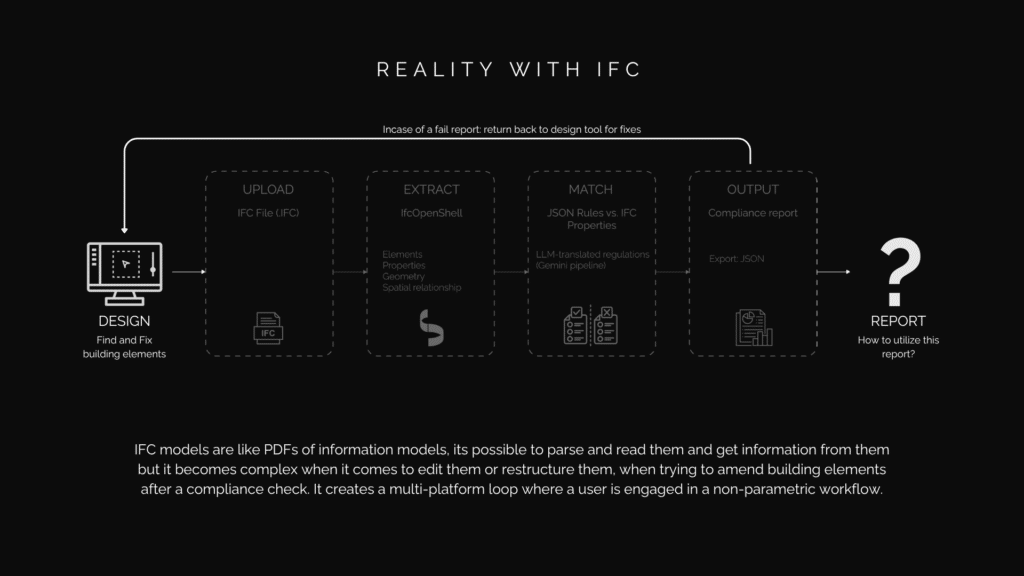
Can you edit IFC?
Short answer: not directly. IFC models are like PDFs of building information. You can read them, parse them, extract data. But editing them after a compliance check? That’s where it breaks down. If something fails, you can’t fix it in the IFC directly. You have to go back to your design tool, make changes, re-export to IFC, re-run the check. It’s a non-parametric, multi-platform loop. The exact opposite of what a designer needs during fast iterations.
So if IFC creates this loop… what if we just skip it?
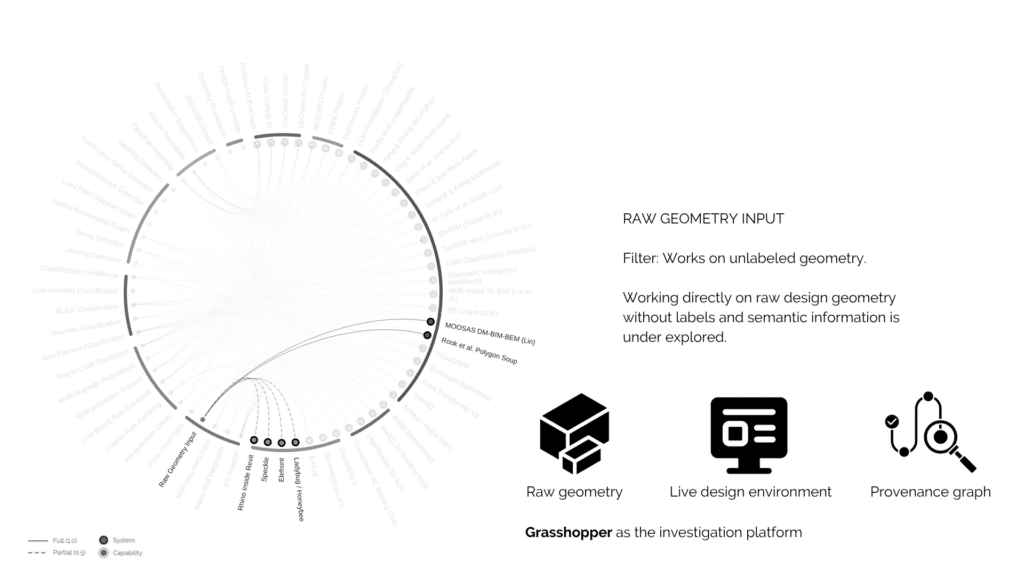
Here’s where the thesis pivots. And the main research question is, Can the semantic layer needed for compliance checking be reconstructed from raw geometry alone, no IFC, no BIM labels? Which regulations can be verified geometrically, and what new checks become possible once you infer spatial relationships between elements? Basically, can we get IFC-level understanding from just Breps?
i chose to investigate this inside of grasshopper
In Grasshopper the geometry is raw, just surfaces and breps with no meaning, generated by a parametric definition. this investigation is about classification of that raw geometry at the design stage, and use the parametric history of how each piece was made as a clue.
This is what my first attempt was. while trying to build a checker inside grasshopper, The geometry alone isn’t enough. You need semantic information. all these inputs are something which the checker needs to know about the design based on the regulations to perform compliance checks.
based on that, the aim was to Develop a computational pipeline that constructs the semantic layer from raw geometry, enabling regulations to be checked inside the design environment. With objectives For automatic classification, Building spatial relationships, LLM-based regulation extraction, and a compliance engine. Each of these is a stage in the pipeline.
This is what I have explored.
A pipeline to extract information from raw geometry and use it for compliance checks
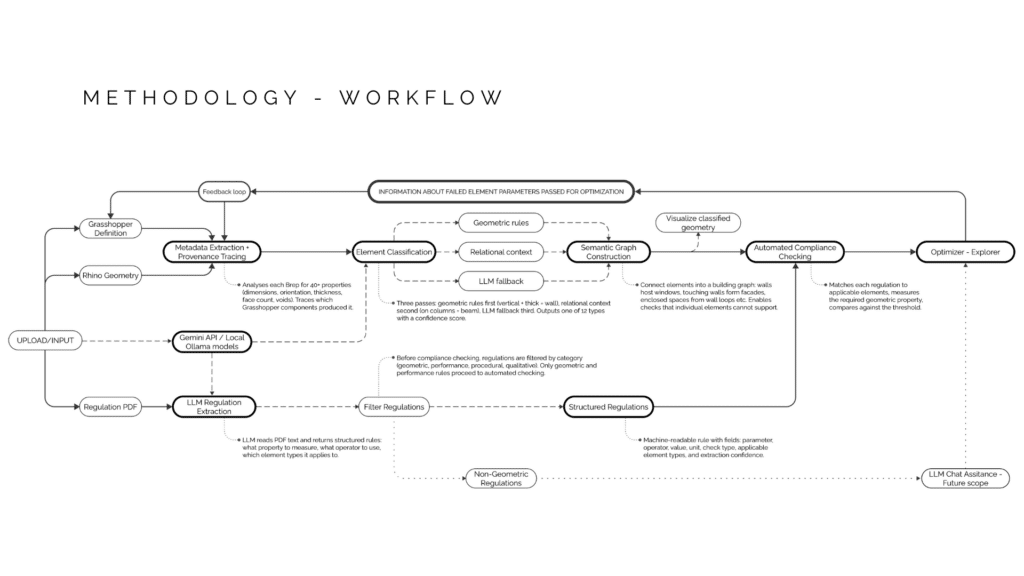
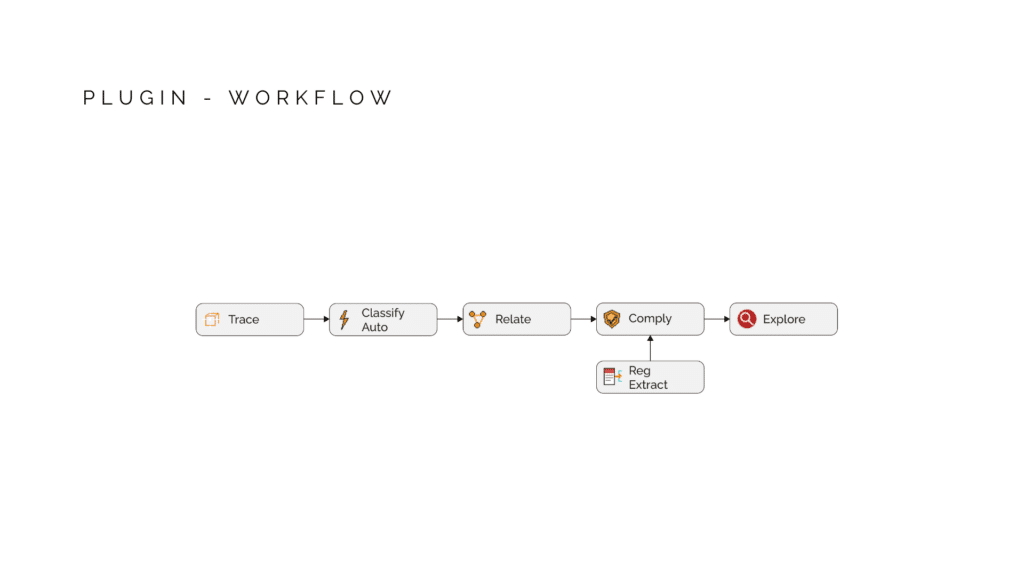
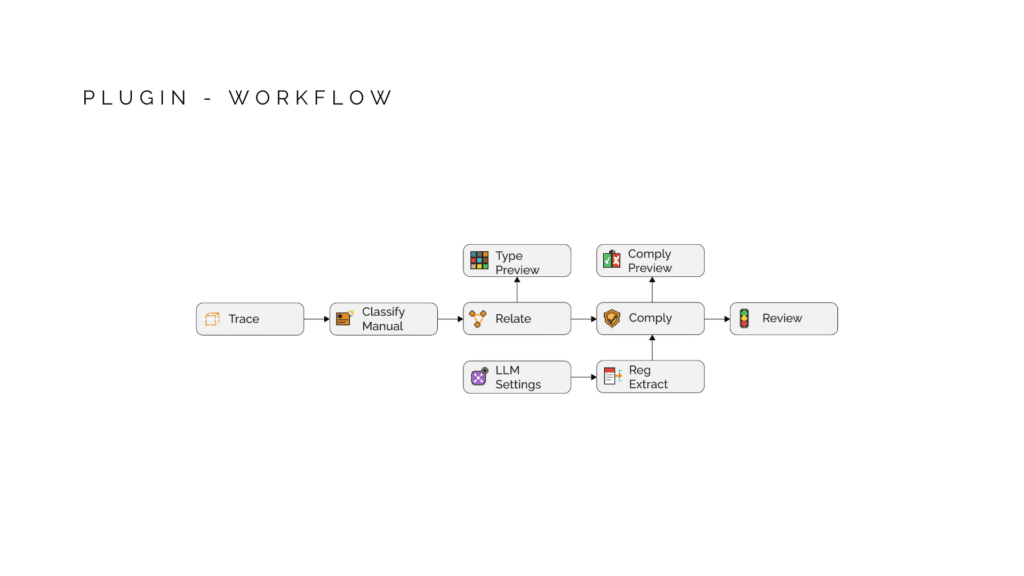
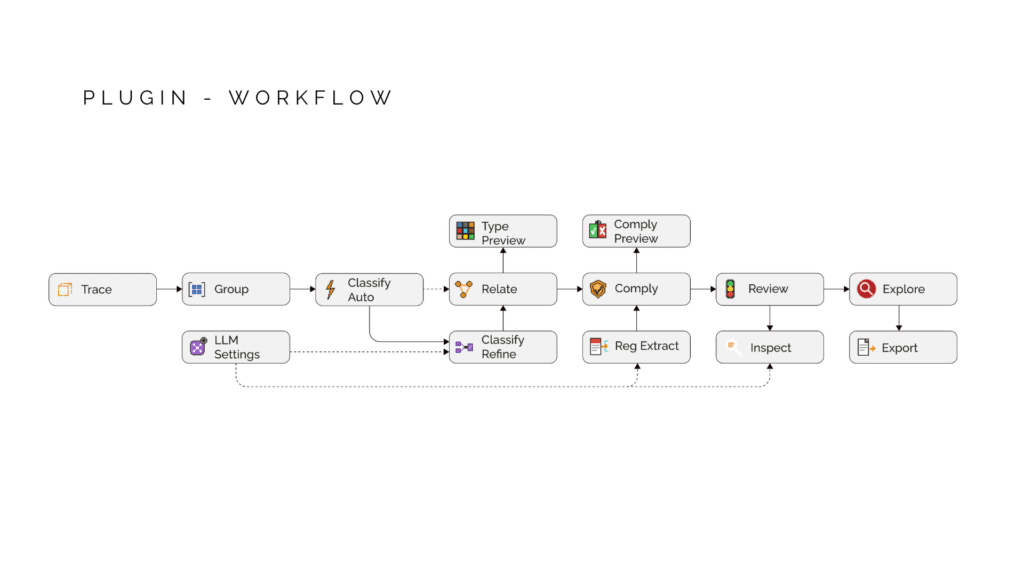
The plugin is a five-stage pipeline, each stage builds on the one before it. Trace. Classify. Relate. Extract. Comply.First… Trace. When you feed geometry into the plugin, it doesn’t just take the Brep. It walks backward through your Grasshopper definition and records where each piece came from. Which component created it, what transformations it went through. This provenance chain is stored, so we can tell exactly which elements fail compliance.Next… Classify. The system looks at each geometry and measures its properties, and based on the heuristics and semantic logic figures out A vertical closed solid with thickness around 200mm is a wall. Same shape but with inner loops is Wall with openings. No labels from the user needed. Classification is focused at Twelve element types in total.looking deeper at classification, My first plan was to classify everything with rules I write myself. I work out the geometric signature of each element type, its proportions, its orientation, and reference these features into rules which runs on every piece of geometry. The plan was: if I can describe what makes a wall a wall, then i can find every wall from unlabeled geometry.My second plan was to let a model learn the building elements from data. Rather than me deciding what makes a wall a wall, I show the model 41,000 labelled building elements and let it understand the geometry through points on the geometry and geometry features. it works at 70% for unseen isolated geometry.All the benchmarks we done on isolated elements. Heuristic hit a ceiling on anything that needs context. and the ML models also falls short even after adding spatial context in training because A wall in a hospital looks different from a wall in a villa. No amount of spatial context fixes that because context only operates within one building, its due to lack of varied dataset. So the next step is to build this spatial context and perform another pass of refinement classification.that’s were Relate comes. This is where individual elements become a building. The system connects everything into a semantic graph. Walls host windows. Slabs carry walls. And by traversing wall loops, the system discovers rooms and spaces that were never modeled, just implied by the geometry. This relational layer is what makes compliance checking possible.Now the regulation side… Extract. You give it a PDF of building regulations. The LLM reads the text and breaks it down into machine-readable fields. Parameter, Operator, Value, Unit. It resolves the legal language, And tags which element types this applies to, what category of check it is, and how confident the extraction was. My objective is to focus on the facade regulation of Mumbai DCPR for development and feasibility.All four stages flow into Comply. The engine takes classified geometry from one side, structured regulations from the other, and runs the checks. The key part is it traces the failure back through the provenance chain, and tells you: this is the component that controls your element. Modify here to fix. That’s the feedback loop. Design to compliance in one environment.
This is the full pipeline. Two inputs: Rhino geometry at the top which gets traced for metadata, classified with heuristics, refined with relational context, built into a semantic graph, and then checked against regulations. Regulation PDFs come in from the bottom: LLM extracts structured rules, they get filtered by category, and the geometric ones flow into the compliance engine and then optimization. The key thing is Everything runs inside Grasshopper. No export. No external platform. You change a wall dimension, compliance should update in real time.
this is the kit of parts which i used to test what the pipeline needs to function, where i slowly added the required functionalities.
the pipeline at its base
setup with preview as a base
here i also experiment with incorporating language models for regulation extraction and for the fallback classification of elements.
This is a collection of some tests I ran, from the simplest box to organic forms. I started with the obvious cases, then deliberately made the buildings harder, more storeys, windows, balconies, curves, fixing the plugin at each step. Many of these forms are built from hundreds of small pieces, so I added a grouping step that reads scattered parts as one element and classifies the whole. That’s what lets it hold up on freeform geometry that could exist in a parametric environment, still reading walls, floors and roofs correctly.