
Aim:
To predict the number of seating spaces based on various types of seating layout, number of corridors and dimensions of generative enclosed rectangular spaces such as an auditorium.
Objectives:
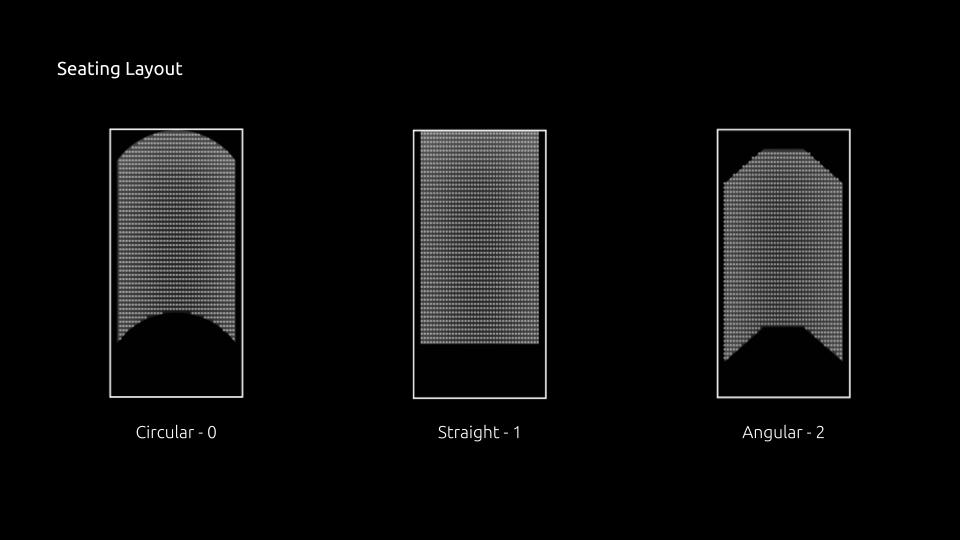
- 1) Predict seating capacity based on seating layout (circular, straight, angular)
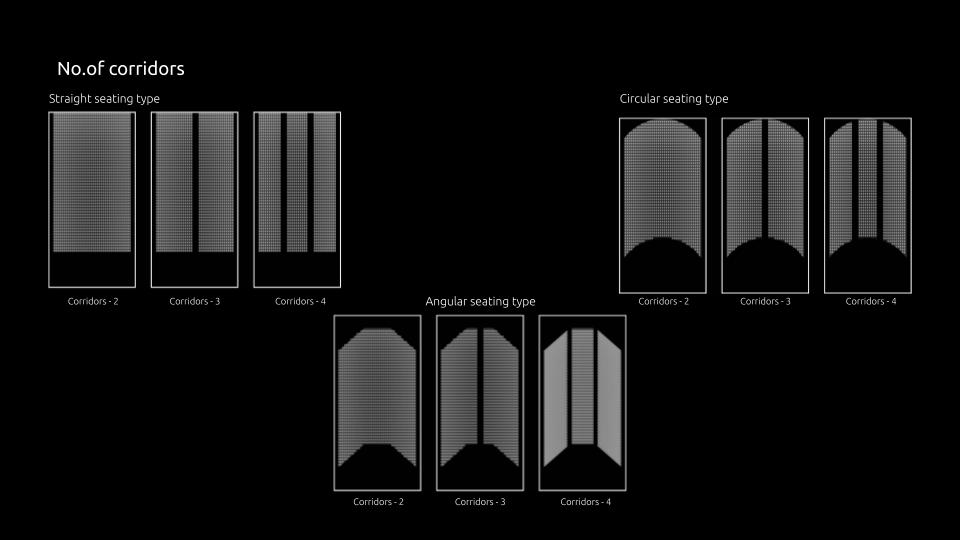
- 2) Analyze the impact of the number of corridors and room dimensions on seating capacity
- 3) Evaluate different machine learning models to find the best prediction method.
Dataset Design:
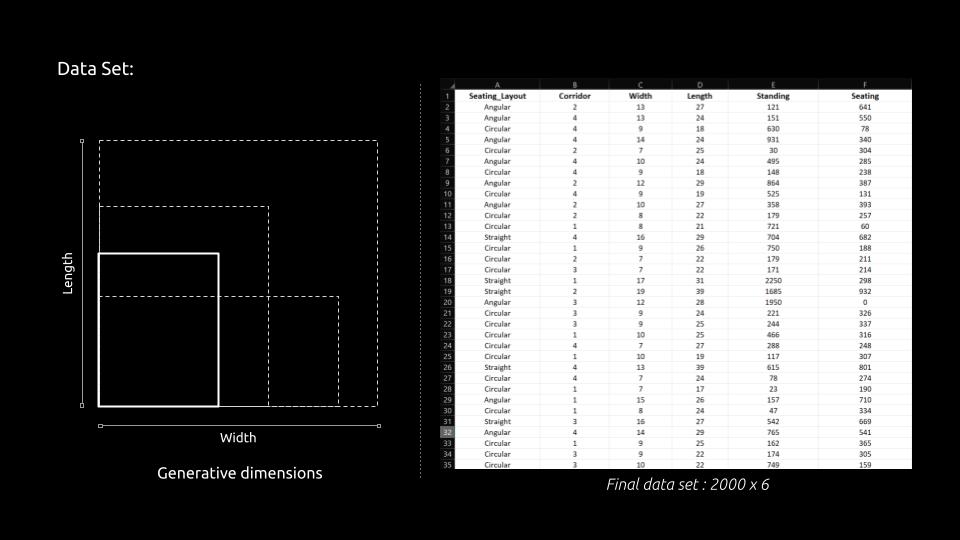
To create Dataset for the required problem, a synthetic dataset is designed with the help of various bylaws supporting the problem.
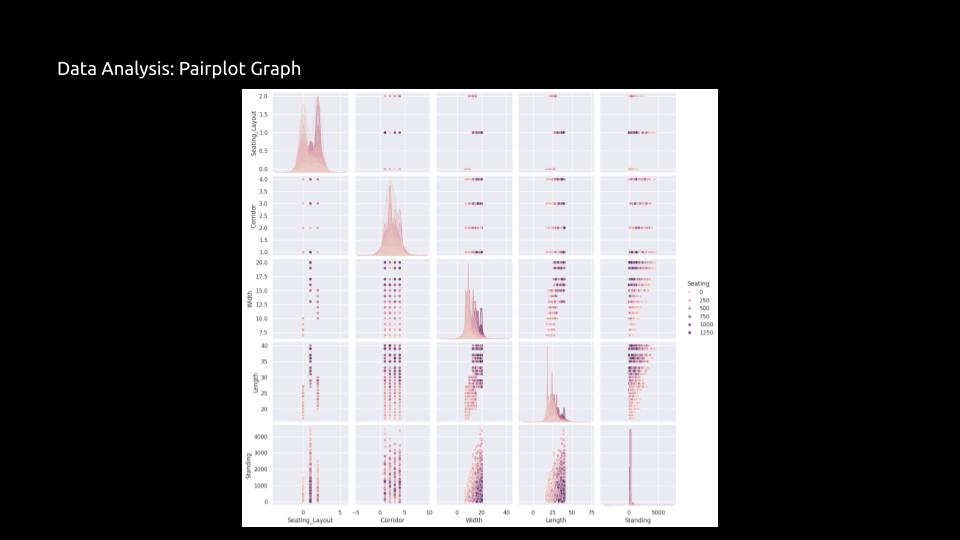
Data Analysis:
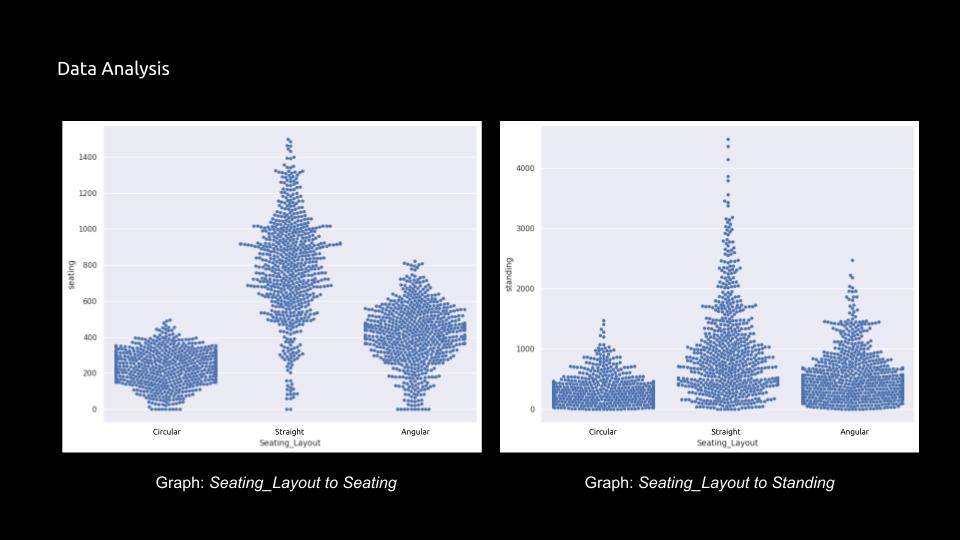
After creating the synthetic dataset, the dataset are analyzed based on Seating_Layout to Seating and Seating_Layout to Standing, using various different graphical representations such as Pairplot Graph.
Shallow Learning Methods:
Shallow learning methods, such as linear regression and logistic regression are introduced as foundational tools for ML in architecture. These methods are simple and are easy to interpret, making them suitable for initial explorations of ML applications. Linear Regression is a technique that predicts continuous numerical outcomes based on one or more input features whereas Logistic Regression is used for classification problems where the output is categorical.
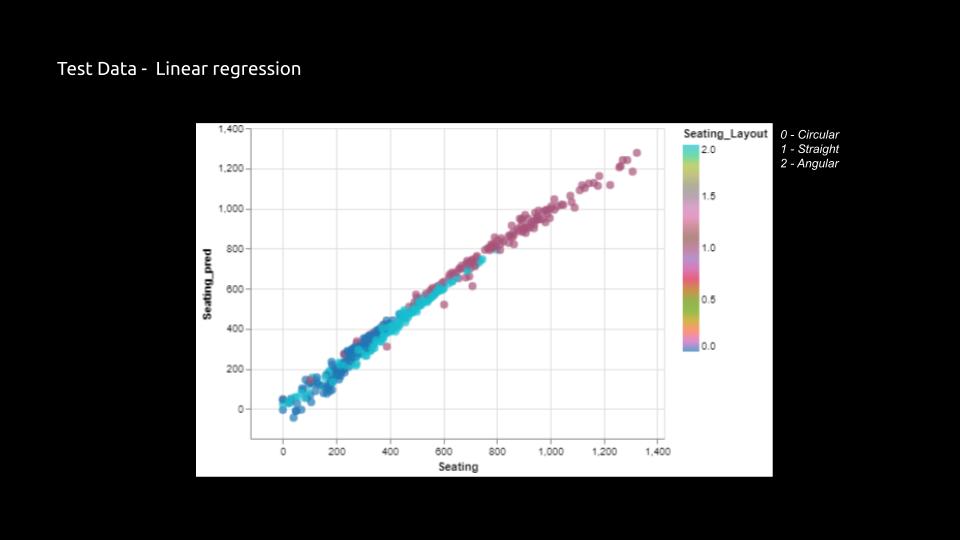
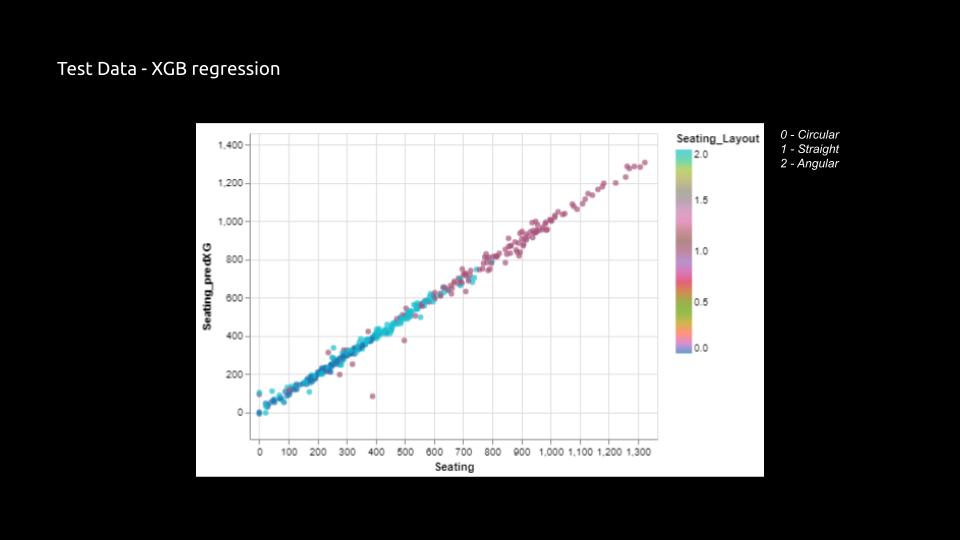
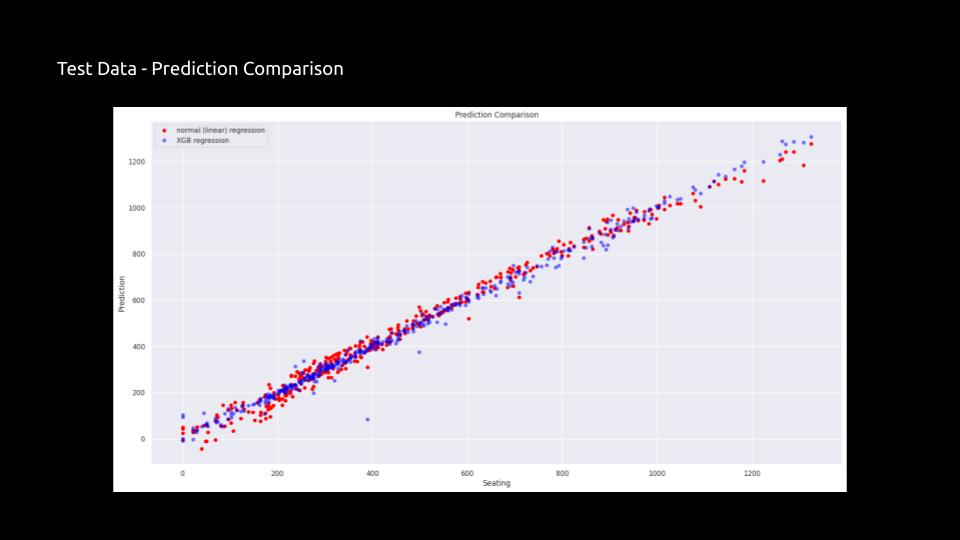
Prediction Comparison between normal (linear) regression and XGB regression
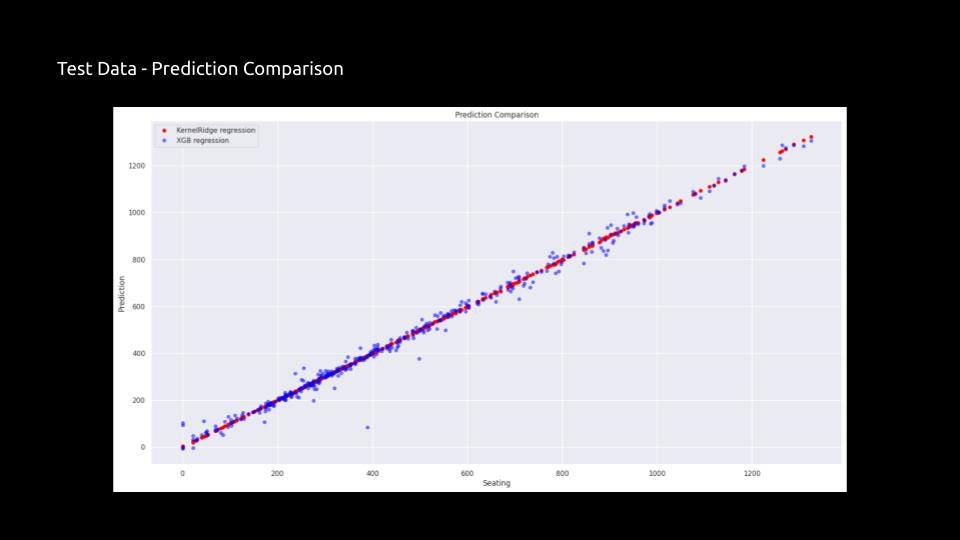
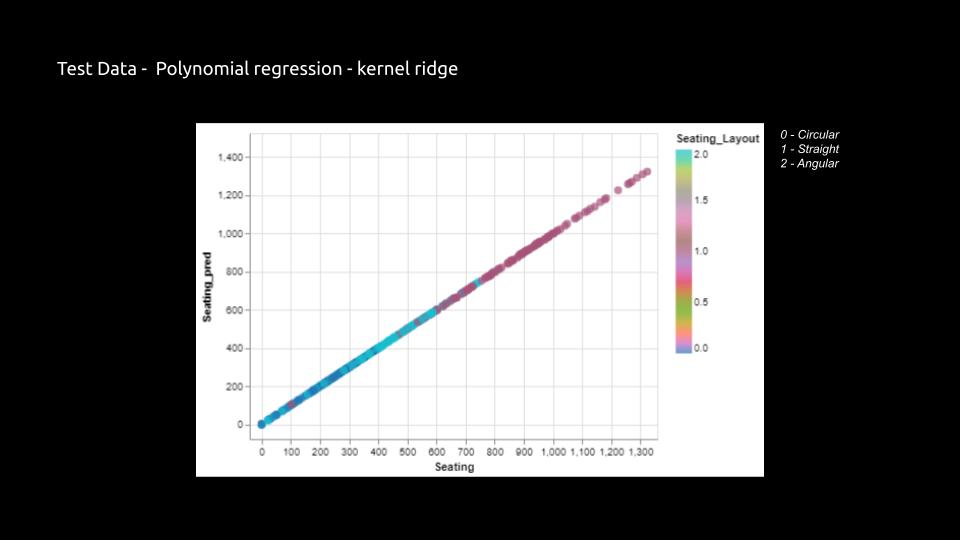
Prediction Comparison between Kernel Ridge regression and XGB regression
Deep Learning:
When shallow learning techniques are insufficient for achieving satisfactory results, deep learning methods are introduced. Deep Learning methods involves Artificial Neural Networks (ANNs), which can handle large, complex datasets with numerous features.
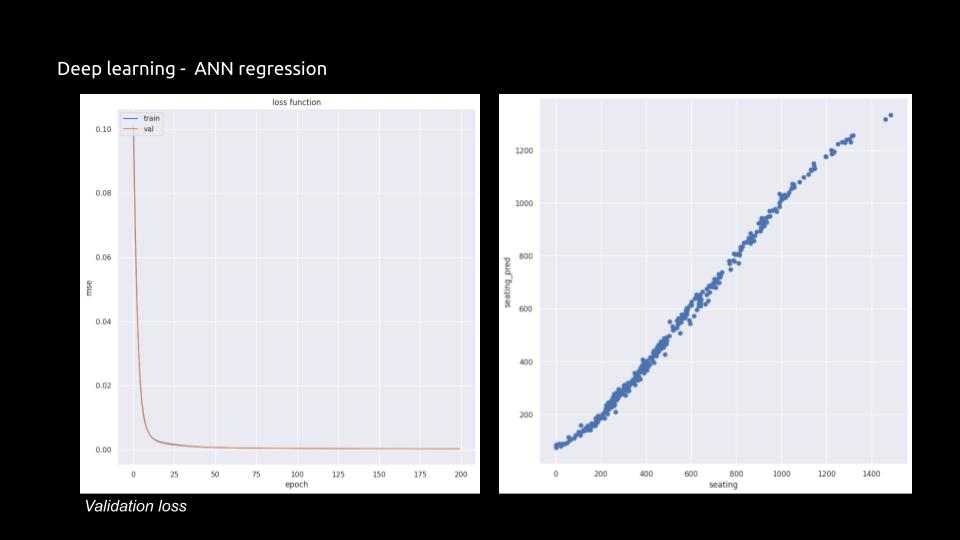
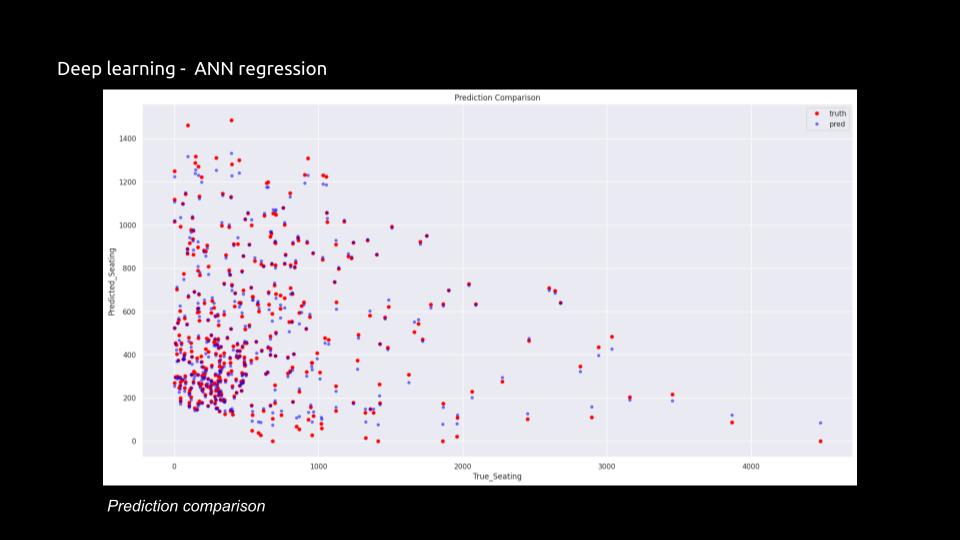
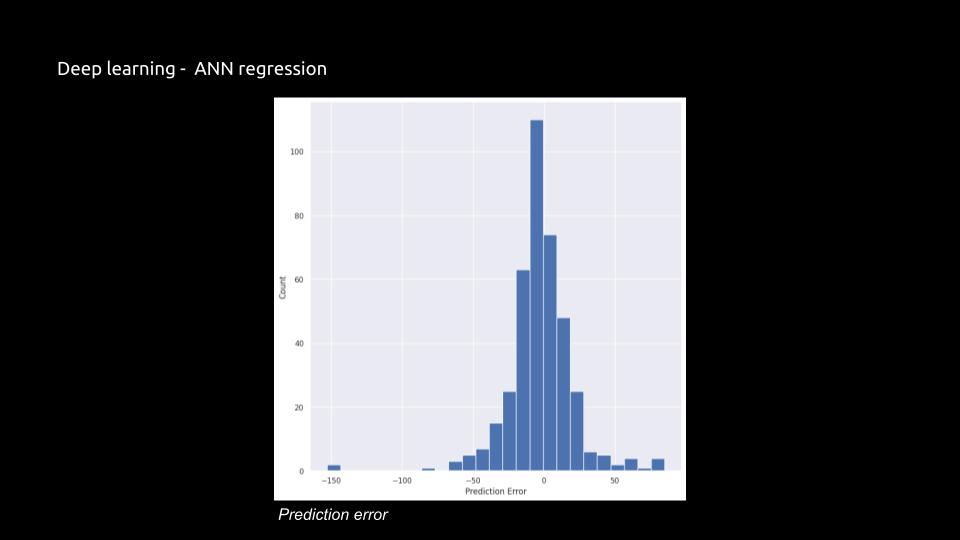
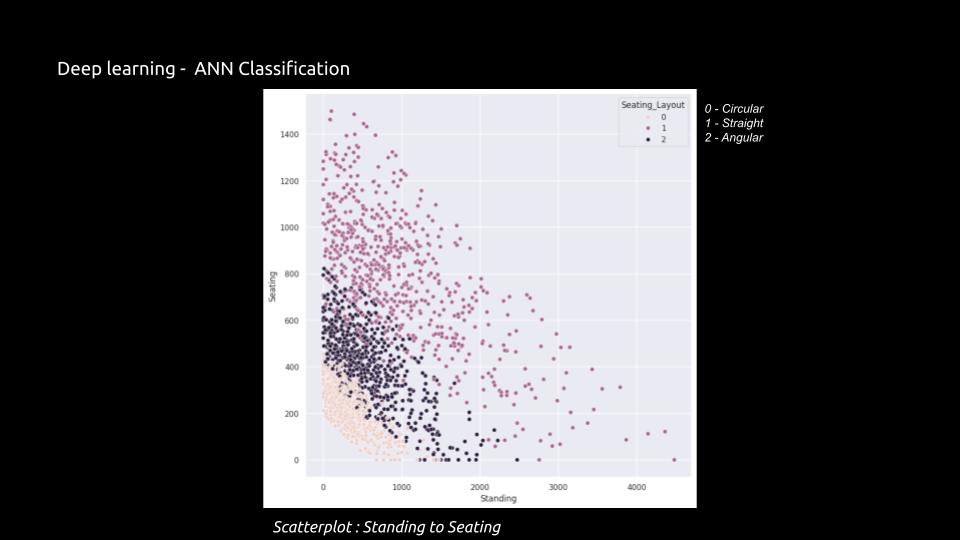
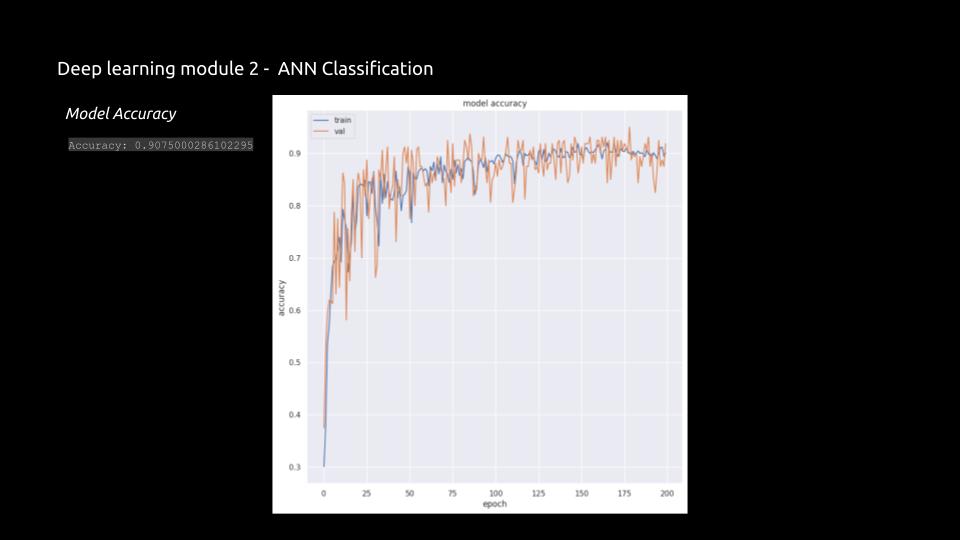
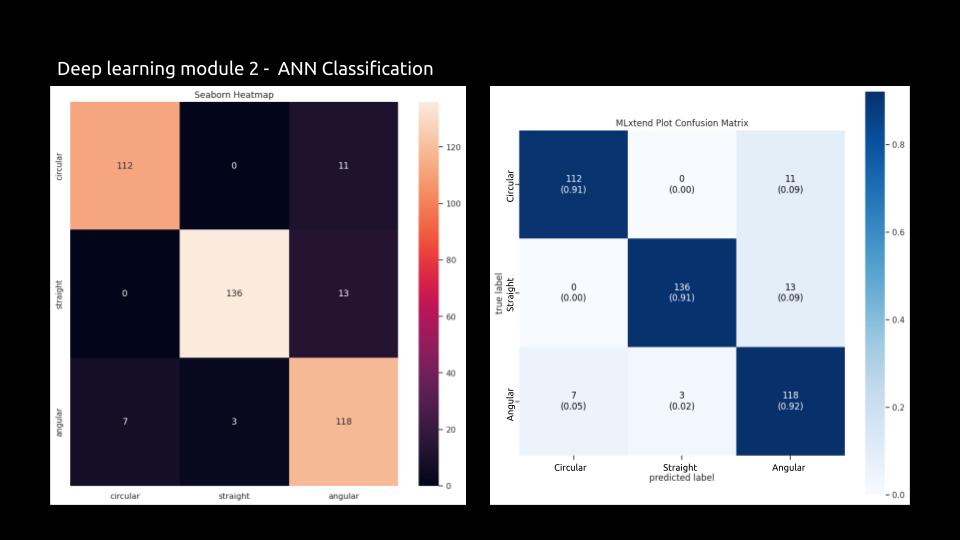
Visual Representation:
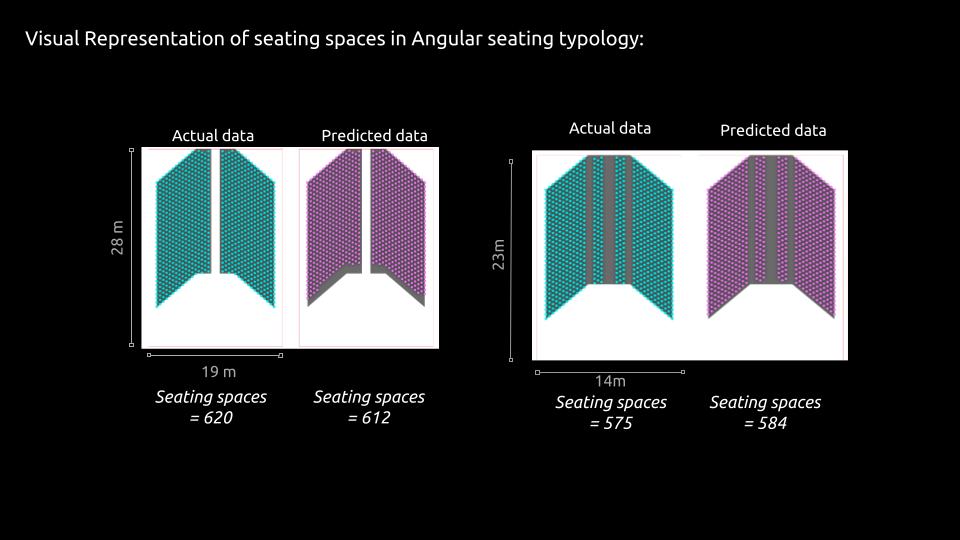
Conclusion:
The project successfully utilized various machine learning models to predict seating capacities based on multiple variables, demonstrating a strong understanding of data analysis and model training. Though it was able to successfully implement various MLs, the dataset size (2000 x 6) is insufficient for training complex models like ANN regression, potentially leading to overfitting. Therefore, to improve this problem, the dataset size could be increased by creating more synthetic data or gathering additional real-world data. Also, the project mainly focused on basic features (seating layout, number of corridors, dimensions) without considering additional contextual factors such as the purpose of the space, accessibility requirements, or audience demographics. To improve this, incorporation of more features that could influence seating capacity, such as aisle width, seat size, and emergency exit placement. This will provide a more comprehensive model input. Although ANN regression was found to be the best method, the complexity may not always justify the marginal performance gain over simpler models like XGBoost. To evaluate the trade-off between model complexity and interpretability, using simpler models that provide comparable performance, as they are easier to interpret and deploy.
