
Machine learning has been applied to a wide range of domains, including transportation, to improve the accuracy of predictions and optimize systems. In the context of taxi services, predicting the trip duration is an essential task to optimize route planning and estimate arrival times. In this post, we present a machine learning approach using Python to predict the trip duration from a dataset of taxi routes in New York. The dataset includes almost one million features such as pickup and drop-off locations, date and time & number of passengers. By applying different regression models and feature engineering techniques, we aim to obtain the most accurate predictions possible concerning the trip durations.
Feature engineering
1)First of all, we need to transform the daytimes into floats so we can work with them in our prediction.For now we will keep everyhting aprt from the seconds.
2) At this moment, we can ceate an additional column estimating the distance from the coordinates.
3) In order to make the prediction better we will try to add a feature for the time of day. We will actually create a function that maps the pickup hour to a specific time of day.
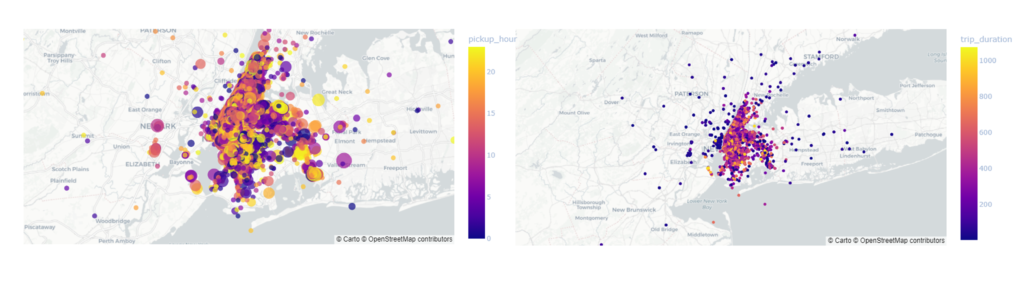
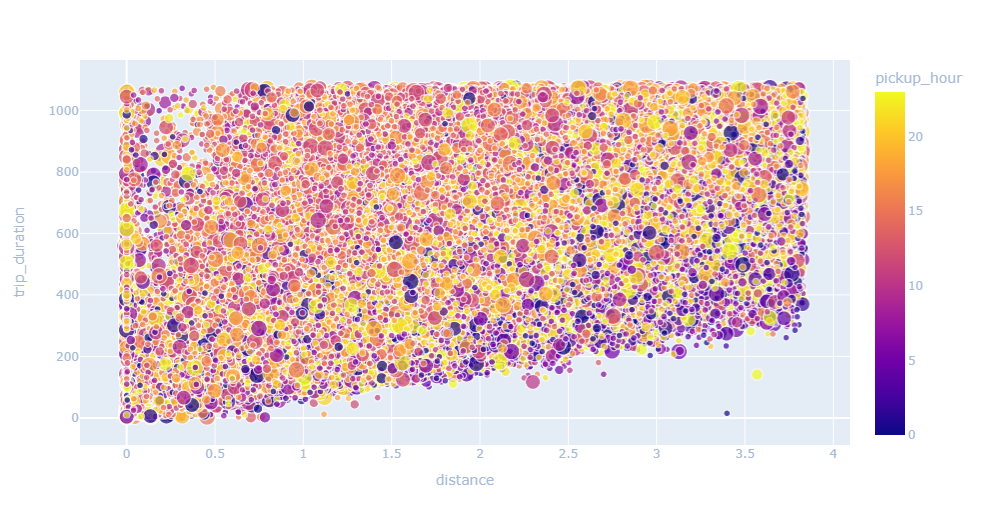
Observing the maps bellow see that most of the trips are taking place within Manhattan. From the following graphs we see that probably we will need to do a polynomial regression. To improve our prediction we can remove the outliers from the distance.
After understanding and cleaning the data we will apply the regression.
1) We will drop the column we want the prediction for as well as the drop-off information which is highly correlated with pickup.
2) After dropping columns with highly correlated features we will scale featured using the Standardization method.
3) So as we mentioned earlier, we will use polynomial prediction. Overall, the code is performing a polynomial regression with degree 2 using Linear Regression from sklearn, evaluating the model’s performance using cross-validation, and making predictions on the test data to assess the accuracy of the model.
