The project’s objective was to create a machine-learning model capable of classifying repurposed timber components within an assembly process as either structural or non-structural, using factors such as defect quantity, age, and exposure to weather conditions as input.

Dataset Generation and Analysis
The dataset was produced using Roboflow by utilizing scans of the timber elements already available. The dataset’s output was a CSV file containing information such as the index of each element and the quantity of various types of defects present, including screws, long cracks, short cracks, live knots, dead knots, holes, and bad edges. Using this data, each defect was assigned a specific weight, and a formula was devised to compute aggregate points. These points were used in determining whether the elements should be classified as structural or non-structural.

Model Explorations
Shallow Learning
To ensure the accuracy and effectiveness of our process, we have decided to utilize Classification models for training and testing. This approach will allow us to produce the required binary output, i.e. Structural or Non-Structural.
We have trained a basic classification model that takes into account two parameters – the number of defects in the stick and the weathering score. These parameters have different ranges of numbers and cannot be compared to each other as they are in their raw format. Therefore, we have scaled them to a specified minimum and maximum value, which will enable the model to better compare the differences and provide more accurate results.
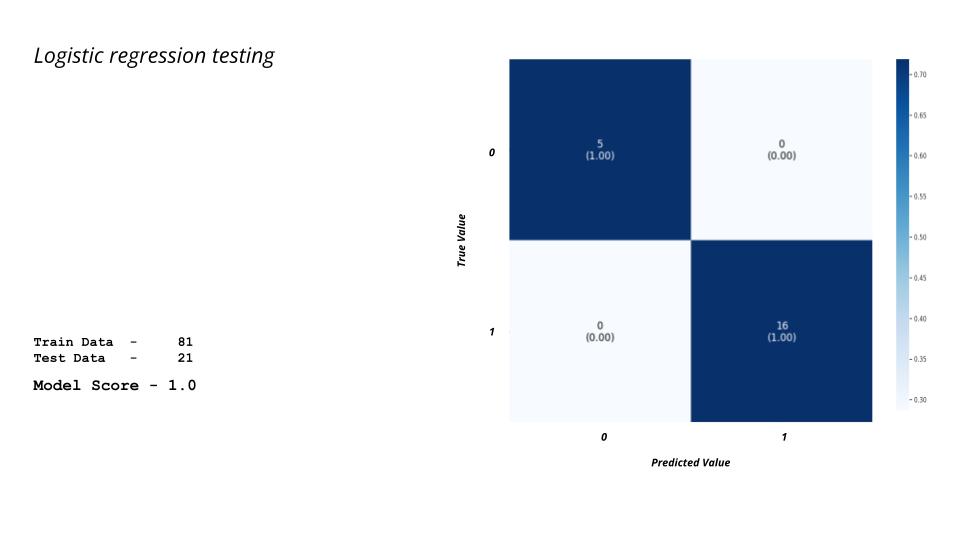
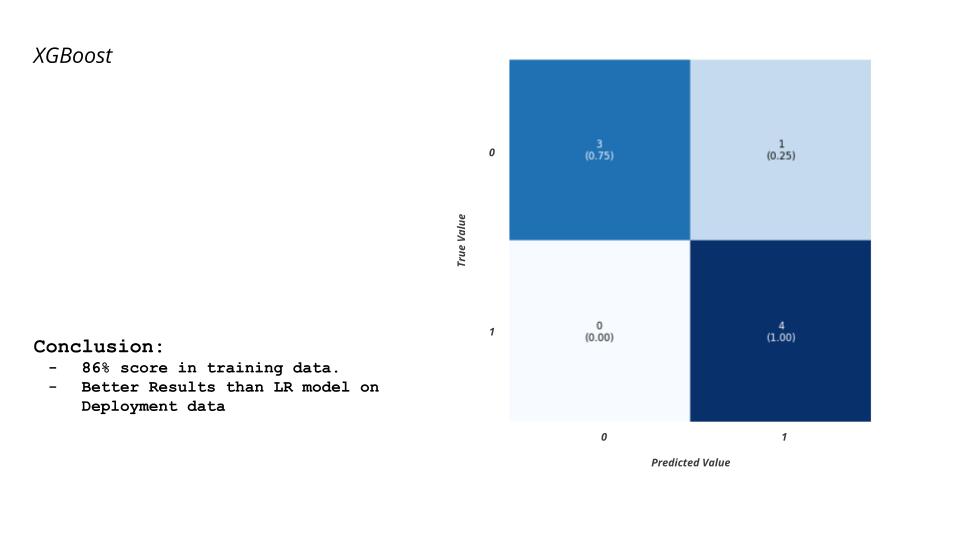
It’s worth noting that achieving a 100% score in the testing data is a remarkable accomplishment. However, it’s important to consider whether our model is overfitting or if we have created a powerful model with a small data set. By analyzing these possibilities, we can gain insights on how to improve our model and further enhance its performance. So, we tried training the same data using the XGBoost method, and the following are the results.
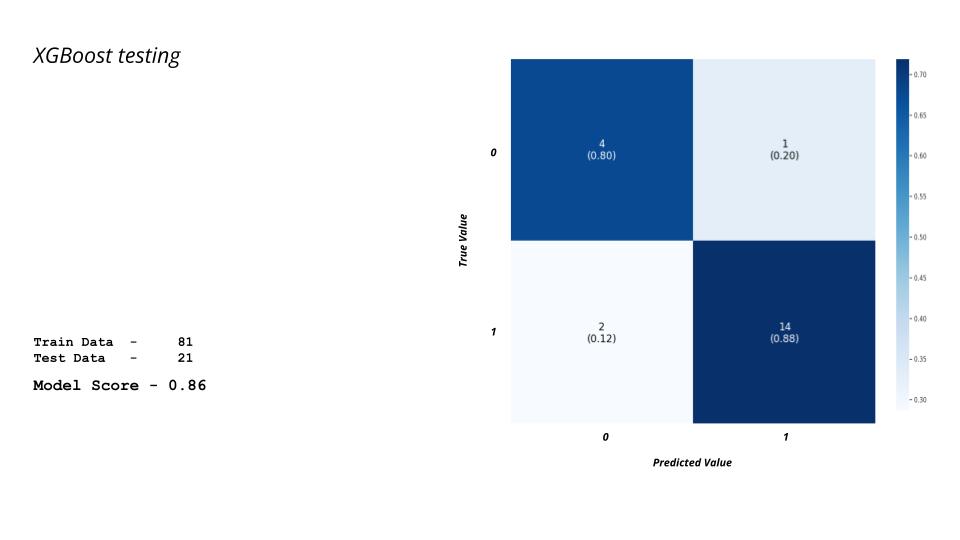
Here, we have observed that the score is not as good as that of the Logistic Regression model. However, it is still a really good score when it comes to machine learning.
Deployment Data
Now that we have successfully trained our models, we are taking the next step to ensure their accuracy. To evaluate the validity of our models, we have generated additional data from 8 sticks.
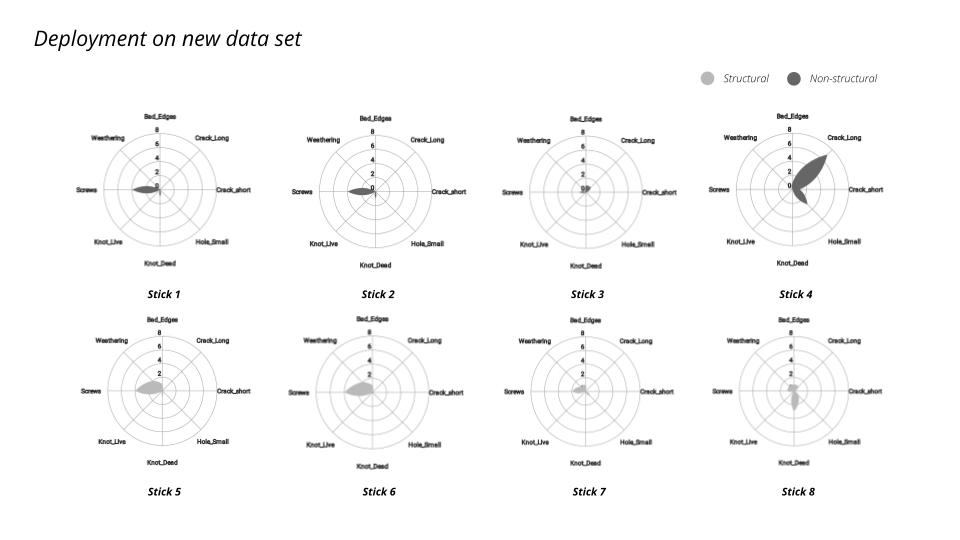
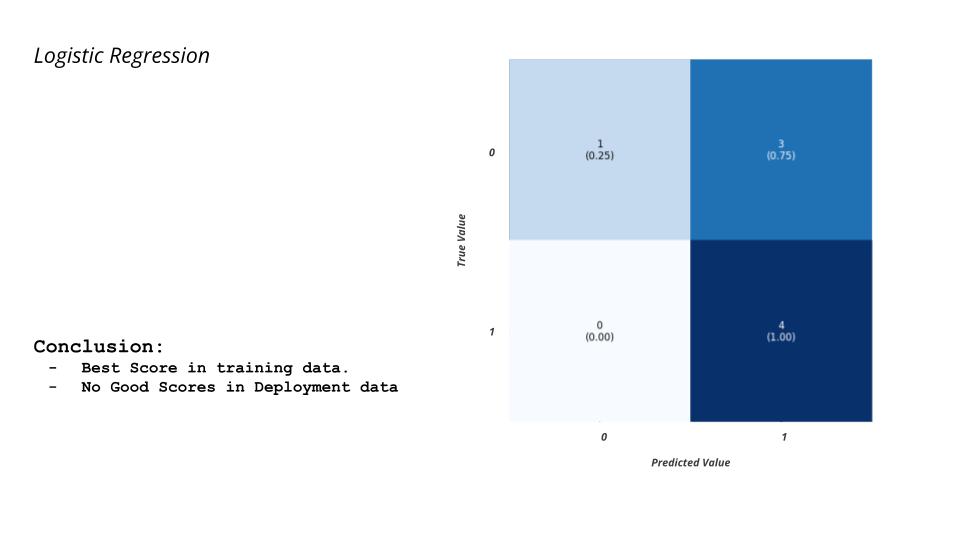
The following are the results and the conclusion we have arrived at for both the trained models.
Deep Learning
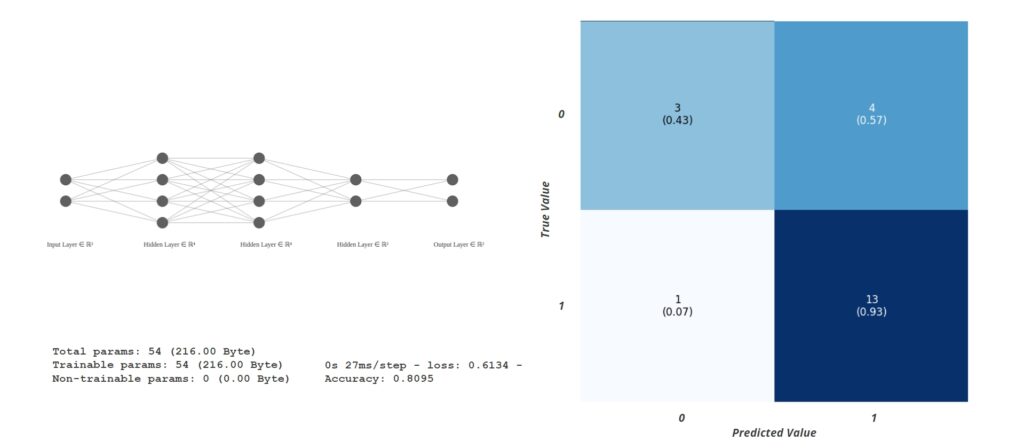
The first model was an Artificial neural network with 2 inputs and 2 outputs. The inputs were long cracks and dead knots, and the output was to classify the piece as structural or non-structural. In the confusion matrix, 1 is non-structural, and 0 is structural. The model was successful in classifying non-structural elements correctly but performed poorly when classifying structural elements.
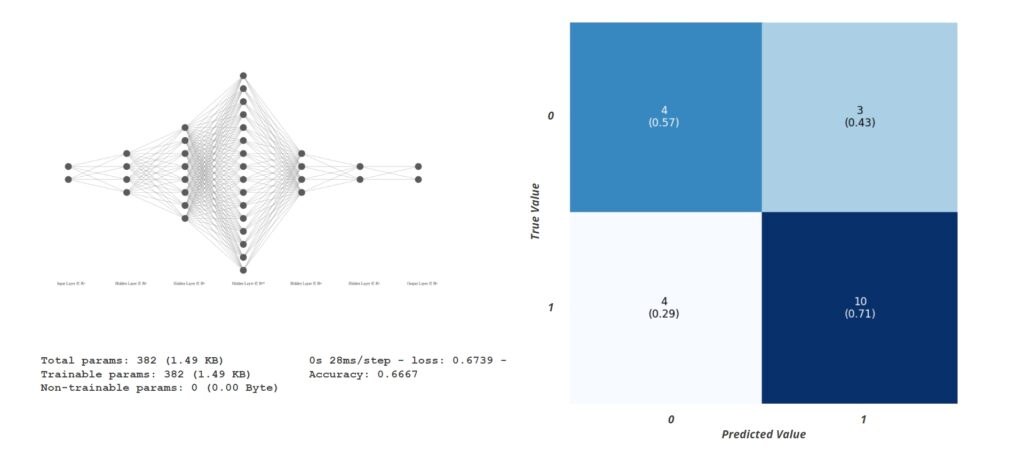
The second model was another classification model. It had 2 inputs, Bad edges and long cracks, and the output was to classify elements as structural or non-structural. It correctly classified non-structural elements 71% of the time, while it correctly classified structural elements 57% of the time during the training.
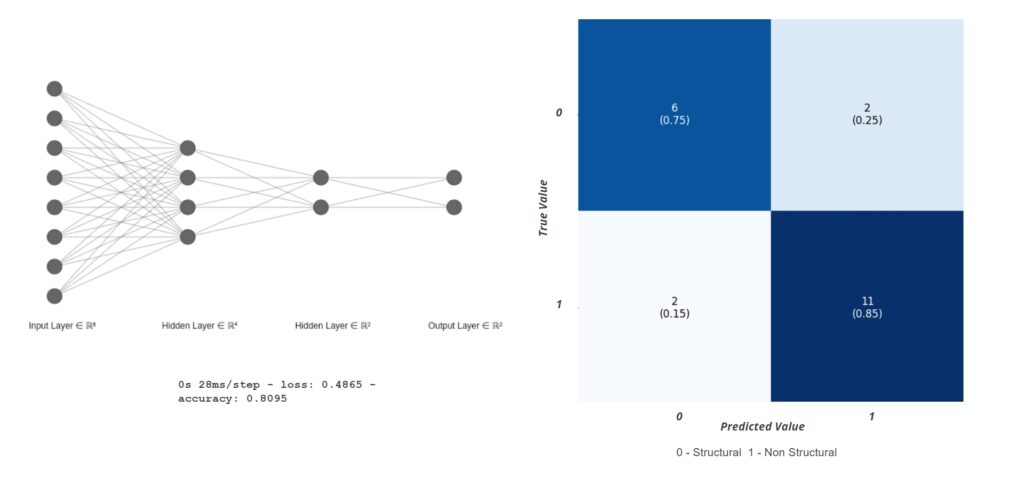
This model was again an Artificial neural network for classification. This had 8 inputs, all the defects and weathering and the output was to classify elements as structural or non-structural. This model performed better than the previous one. It showed 85% accuracy in classifying non-structural correctly and 75% accuracy in classifying structural elements correctly during the training.
Another classification model was trained using the same inputs but a different architecture. This model classified everything as a non-structural element.
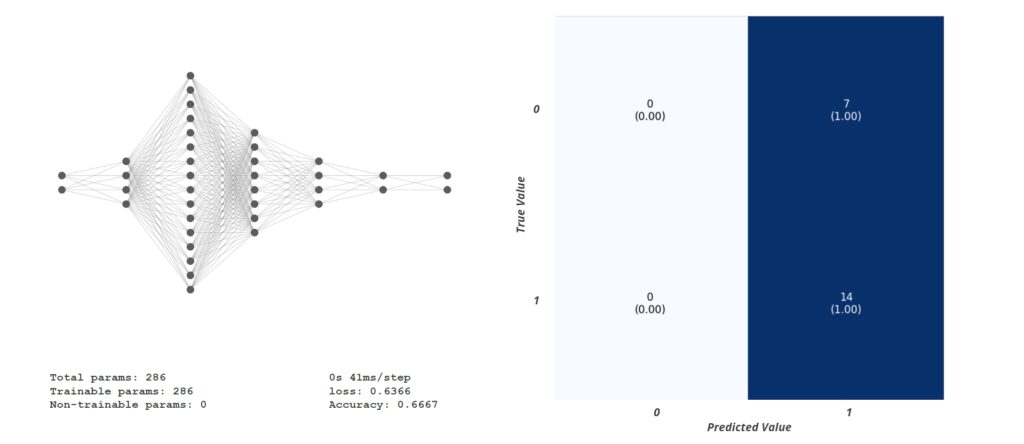
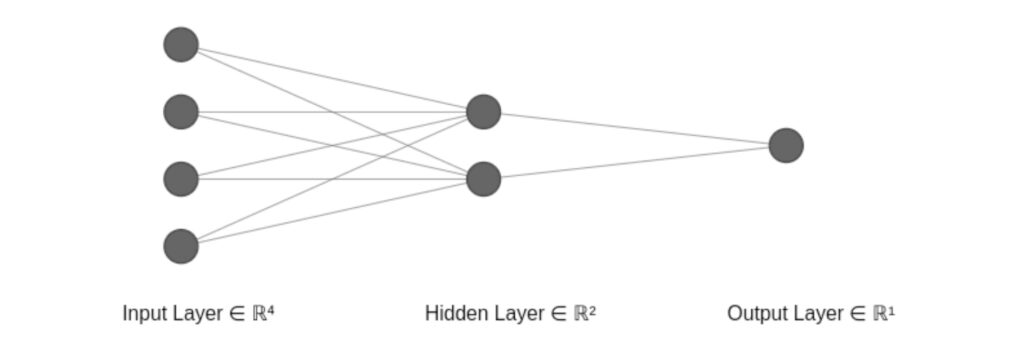
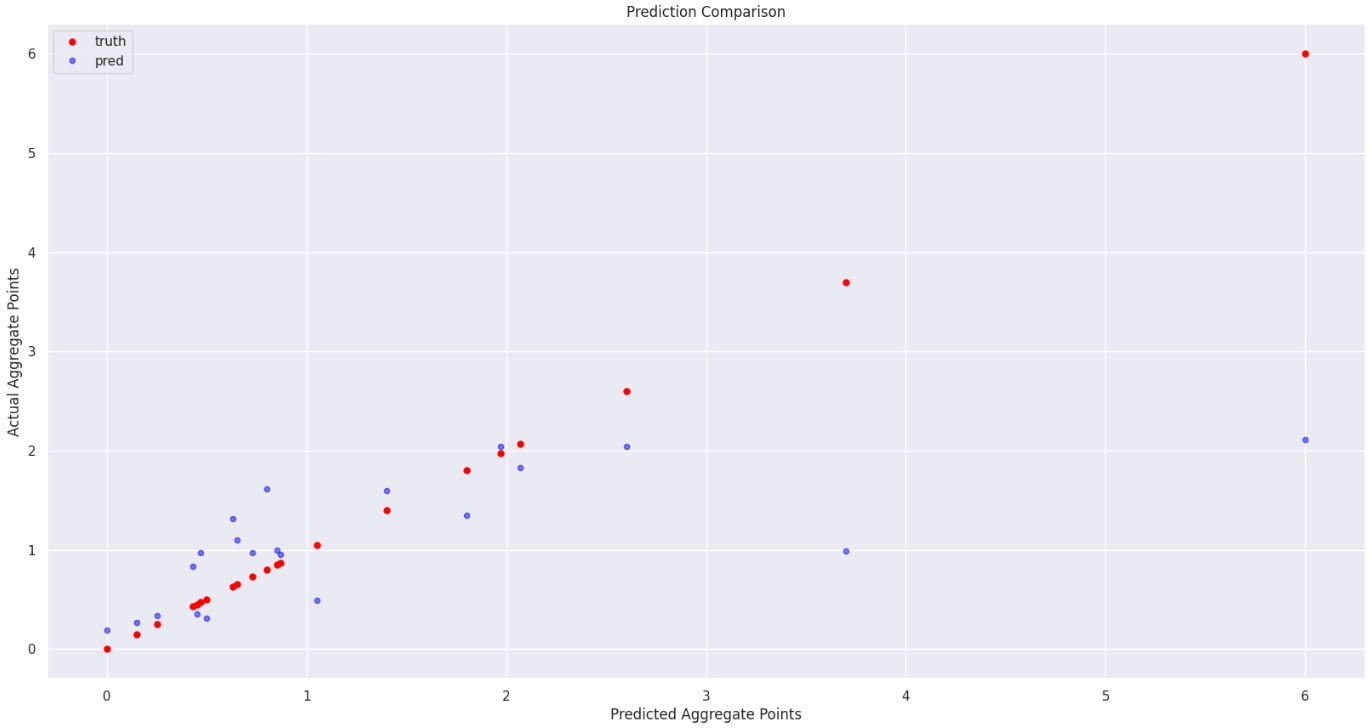
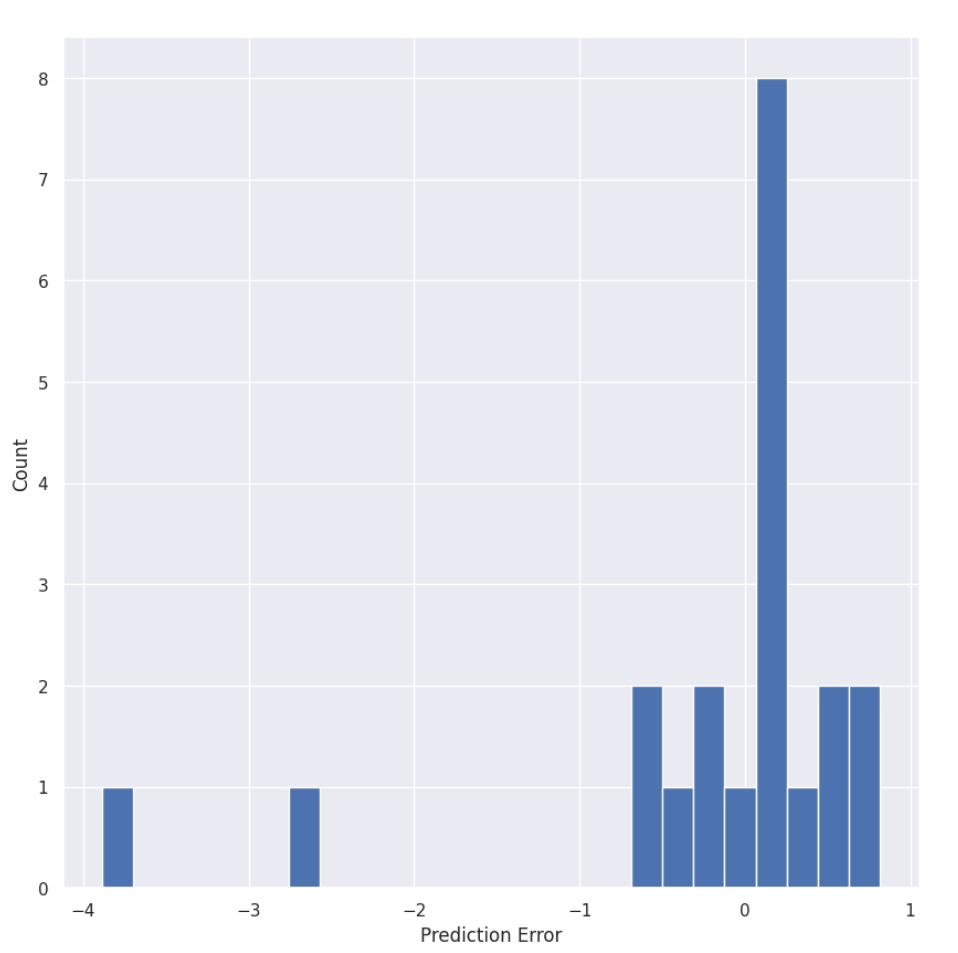
This model was a regression model. The idea was to train the model to predict the aggregate points, and based on the threshold, the elements were classified by a human. It had a simple architecture. It had four inputs: total Weight points, Total number of defects, aggregate points and weathering.The Output was predicting the Aggregate points.