

A conversation in which Jane Jacobs and Rem Koolhaas try to get LeCorbusier to think differently about the city… or the opposite!
The Challenge
We used Conversable Agents and Retrieval-Augmented Generation (RAG) to simulate a discussion between three influential architects: Jane Jacobs, Rem Koolhaas, and Le Corbusier. These theorists have shaped our understanding of the modern city.
Methodology
- Text Collection: We gathered articles that critique the Modern Movement’s vision of the city, written by or about our featured architects.
- Text Parsing: Koolhaas’s PDF texts were converted to .txt files. We use a Python script that utilizes the LlamaParse library to parse PDF documents within a specified directory and convert them into markdown format, saving the results as text files. The script begins by importing the necessary modules and configurations, including an API key set up in a separate keys.py script. The LlamaParse object is configured with specific parameters such as the API key, desired output format (“markdown”), number of worker threads, verbosity, and document language (“en”). The script targets a directory labelled knowledge_pool_dir, iterating over each file within. The script constructs the full path for each PDF file detected, processes the PDF through the LlamaParse instance, and extracts the text. This text is then written to a newly created text file in the same directory, replacing the original PDF extension with “.txt”. Each successful operation prints a completion message for the individual document, with a final print statement signalling the end of the entire parsing process, indicating that all documents have been successfully parsed and saved.
- Along with texts from Jacobs and Le Corbusier, which were already in a .txt format, these were split into chunks and embedded into JSON files. For this step, we use a Python script to convert the .txt files into a structured vector format, facilitating semantic analyses and other machine-learning applications. The script operates locally, using LLamaParse, which runs locally on LM Studio to generate the embeddings. It begins by importing necessary configurations and setting the path to a specific text document. The core functionality lies in its ability to process this document and convert its content into embeddings using a predefined model specified in the script. This is achieved by reading the entire document and then splitting the text into manageable chunks—either lines or paragraphs based on structural cues within the text, such as empty lines signifying paragraph breaks.
- Generating embeddings involves iterating over each text chunk, cleaning it by removing newline characters, and passing it through the embedding model to obtain a vector representation. Each resulting vector is paired with its corresponding text and stored in a structured format, creating a database of content and its embeddings. These embeddings are then saved into a JSON file, named according to the original document but with a .json extension to indicate its data format. The script concludes by printing a message to indicate the successful completion of the vectorization process, providing a clear endpoint and a reference to the newly created JSON file that contains the embedded representations of the document’s content. This automated embedding generation facilitates further data analysis tasks, particularly in fields requiring a deep semantic understanding of textual data.

- Embedding and Simulation: The JSON files, serving as embedding files for each agent, were utilized by the LLM Mistral and the embedding model Nomic, which also runs locally on LM Studio.
- Utilizing embeddings and the
ConversableAgentclass from theautogenmodule, we configure each agent with distinct personalities and conversational styles reflective of their historical and theoretical stances on urban design. The agents are set up with unique descriptions, system messages that outline their conversational behaviour, and specific termination conditions for the dialogue. Each agent’s dialogue begins by pulling contextually relevant data from designated JSON files containing pre-generated embeddings, which facilitate the generation of responses using the RAG (Retrieval-Augmented Generation) technique, ensuring that each agent’s contributions are informed by a knowledge base reflective of their ideological positions. - The conversational flow is initiated and managed through several method calls that handle agent interactions. Starting with Le Corbusier, the script orchestrates an exchange where each agent responds based on inputs processed through their respective RAG results, which guide the conversation according to the thematic concerns associated with each figure—urban functionality, human-scale development, and the critique of modernist planning. As the conversation progresses, embedded logic checks for termination signals, which are determined by the number of exchanges or specific dialogue conditions. This setup facilitates an interactive and dynamic discussion mimicking a real-world debate among these figures. It demonstrates the application of complex AI-driven dialogue systems in simulating intellectual discussions, making it a potent tool for educational and research purposes in understanding urban planning theories.


- Discussion Limitation: A custom function limited the number of exchanges between the agents to ten. After ten exchanges, human intervention was needed to decide whether to continue or stop the discussion.
- Agent Personalization: To enhance their wit and humour, each agent was given a unique personality, speech style, and catchphrases.

The Conversation

Visual Representation
We trained a LoRA on Le Corbusier’s sketches to visualise our project and generate visual representations illustrating the architects’ discussion. The faculty of this course provided us with a Google Colab Notebook that became an invaluable resource for our team as we learned how to fine-tune a Stable Diffusion model using Low-Rank Adaptation (LoRA) techniques. The notebook starts with setting up the Google Colab environment, which is straightforward, thanks to the detailed instructions on installing necessary libraries and dependencies. We found the data preprocessing section particularly helpful as we progressed, guiding us through preparing our dataset for training. The clear explanations and code snippets for configuring the Stable Diffusion model with LoRA made the process much more accessible, even though it’s an advanced technique to reduce the parameter space for more efficient training.
One of the standout aspects of this notebook was its focus on practical implementation. The sections on hyperparameter tuning, iterative training processes, and evaluation metrics gave us a deeper understanding of optimizing model performance. We appreciated the advanced troubleshooting tips and optimization strategies, which helped us overcome several common issues during the fine-tuning process. By following this notebook, we improved our technical skills and gained confidence in using LoRA to enhance large neural networks for specific tasks. This hands-on experience has been instrumental in advancing our knowledge and capabilities in deep learning and image generation.

The initial sketches we obtained were challenging to process, so we needed to clean and describe them adequately before training.

Our team utilized a second notebook provided by the faculty, “LoRA Adapter Weights & Scales,” to explore integrating and manipulating LoRA weight files within Diffusers text-to-image pipelines. The notebook is structured to demonstrate the loading and unloading of LoRA weight files from Google Drive, followed by image generation with varied LoRA scale values. The initial sections guide users through setting the directory for LoRA weights and the specific weights file to be used. It includes essential steps such as mounting Google Drive, verifying the presence of weights, and installing necessary dependencies like diffusers, accelerate, PEFT, and torch.
The notebook constructs a text-to-image pipeline using the “runwayml/stable-diffusion-v1-5” model. After loading the LoRA weights, the notebook defines a prompt and seed to generate an image, showcasing the initial result with the default LoRA scale. Further sections delve into the effect of altering the LoRA scale, illustrating the process with concrete examples. This comprehensive demonstration not only aids in understanding the impact of LoRA scaling on image generation but also serves as a practical guide for integrating LoRA adapters into custom workflows.
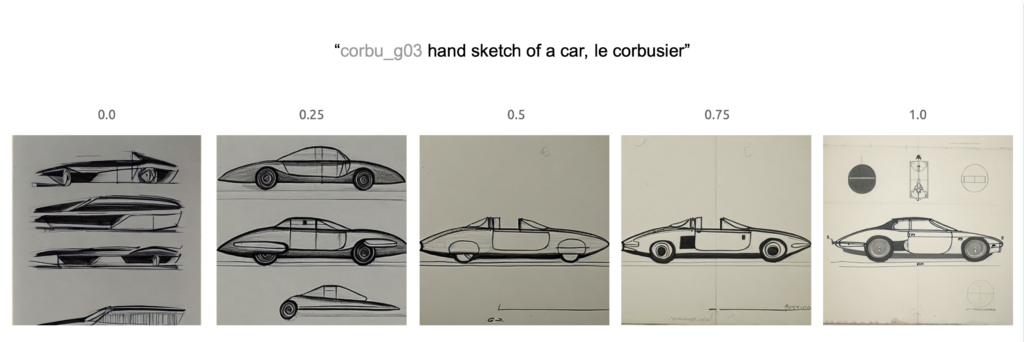
Here, we can visualize different validation steps visualized on our test prompt, “hand sketch of a car, le Corbusier.”

Here, we can see how different weights affected the test prompt.
Here are the final results of images generated based on prompts from our Agents and visualized by our LoRA model.


Challenges
Despite our efforts, the agents often ignored our instructions, leading to unexpected outcomes.
