
Fire Spread Prediction in Building Layouts
Project Goal
The goal is to predict fire safety risk at the unit level in a building.
We are conducting a fire spread analysis for building layouts by examining spatial, structural, and material features.
The objective is to model and understand how fire propagates through different parts of a building based on characteristics such as room connectivity, surface combustibility, ventilation, and ignition sources.
This analysis architects, fire engineers, housing client and insurance assess risk early in the design process, supporting safer architectural design


Building Investigation
What can cause fire?
We conducted a spatial-material analysis to identify features most correlated with fire propagation potential at the unit level.

How the data is distributed across the building.
the spatial distribution of unit types


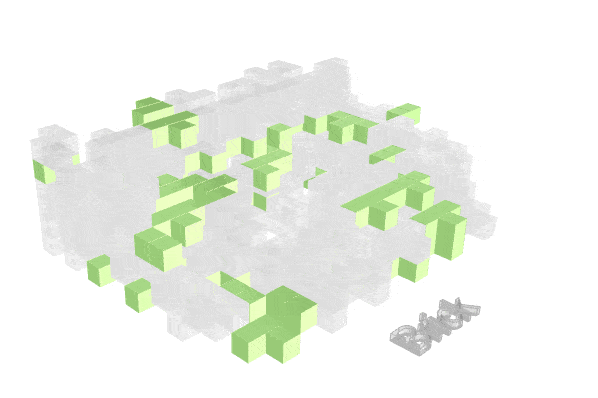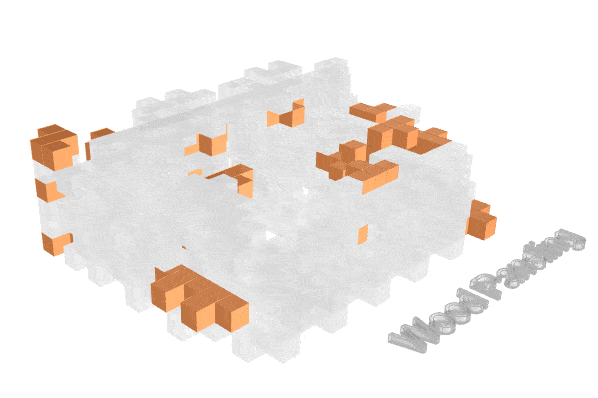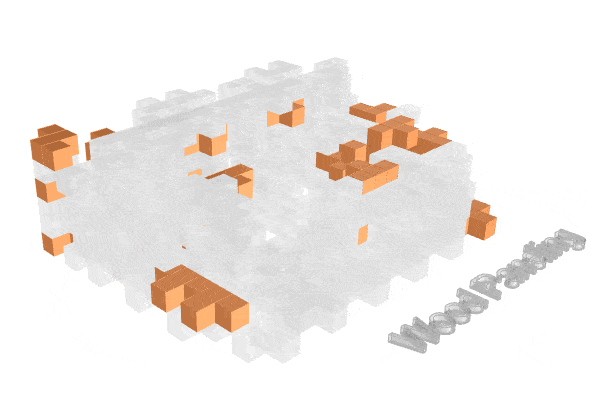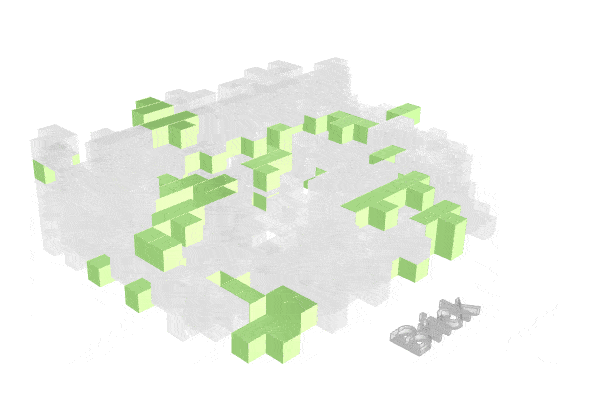

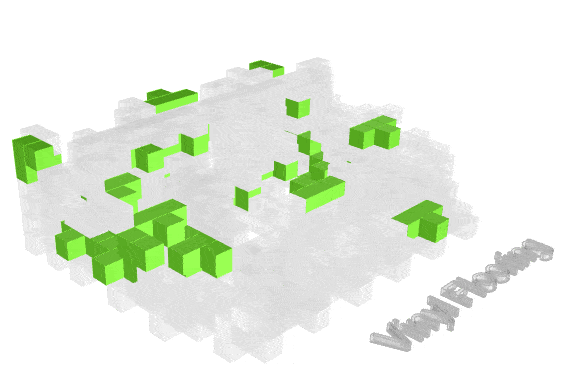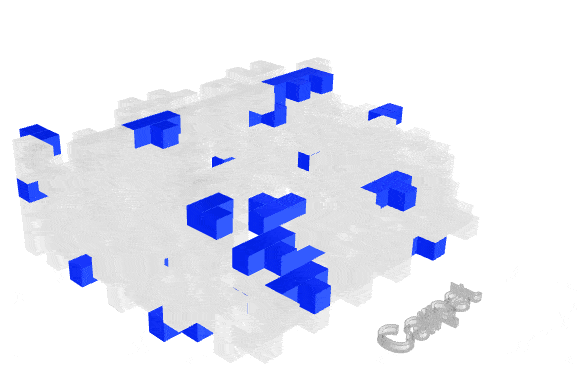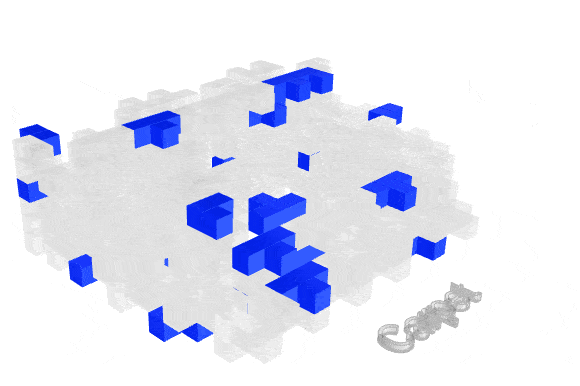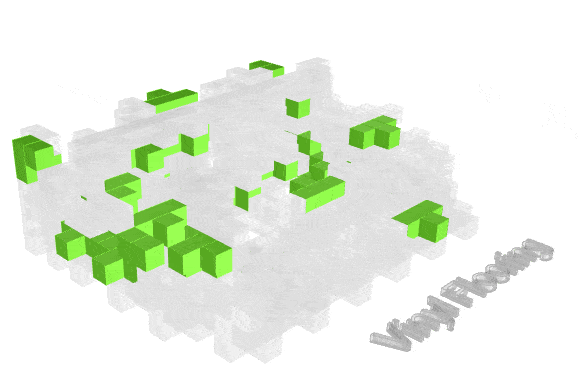

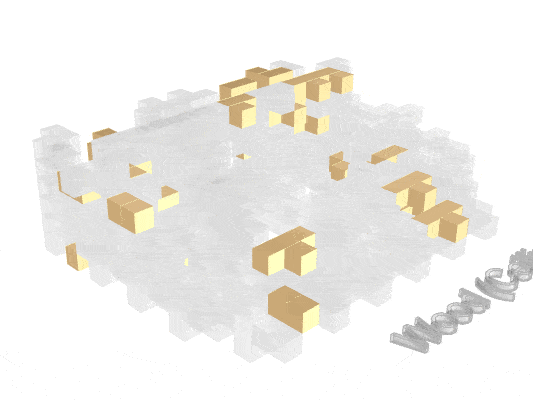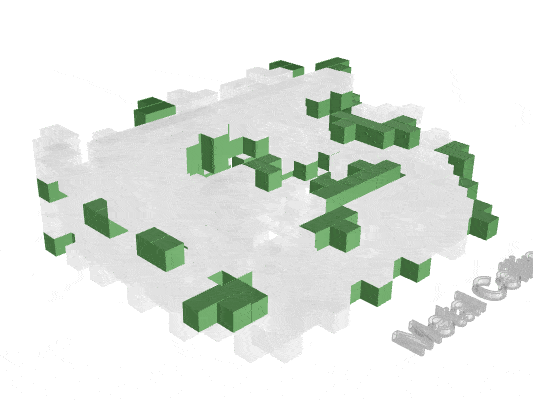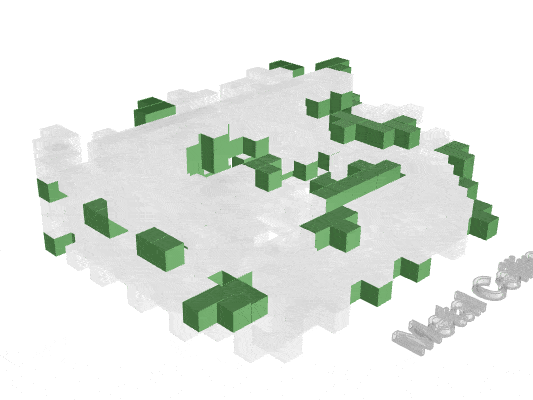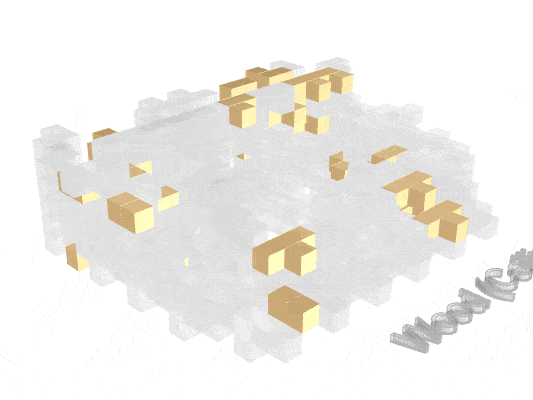
Visualizing how material finishes are distributed helps reveal where fire risk may concentrate spatially.
Dataset Composition
Initially Manipulating data through Grasshopper
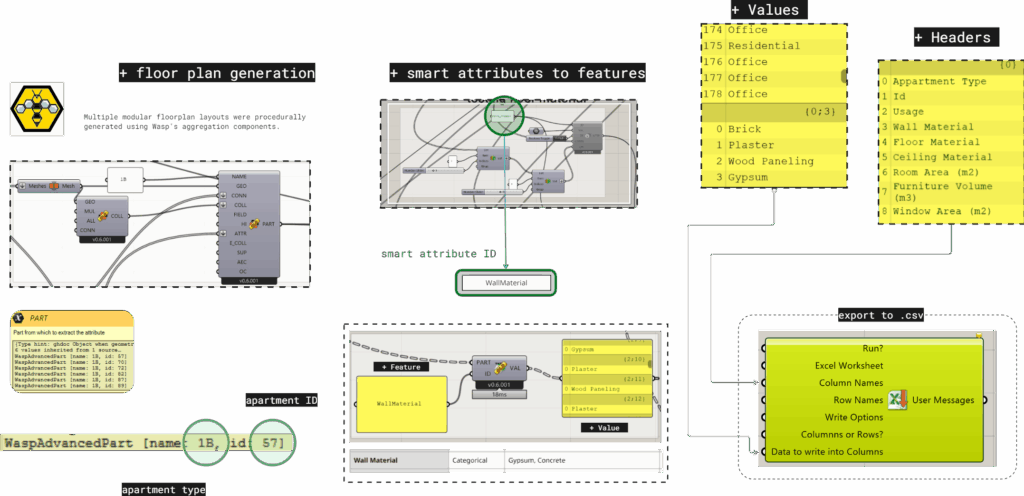
using the BDG we received we added new features to the modules wasp parts using the wasp smart attributes in Grasshopper.
and after aggregation we restored all apartments with These features labeled on them then exported as structured datasets for further analysis and modeling.
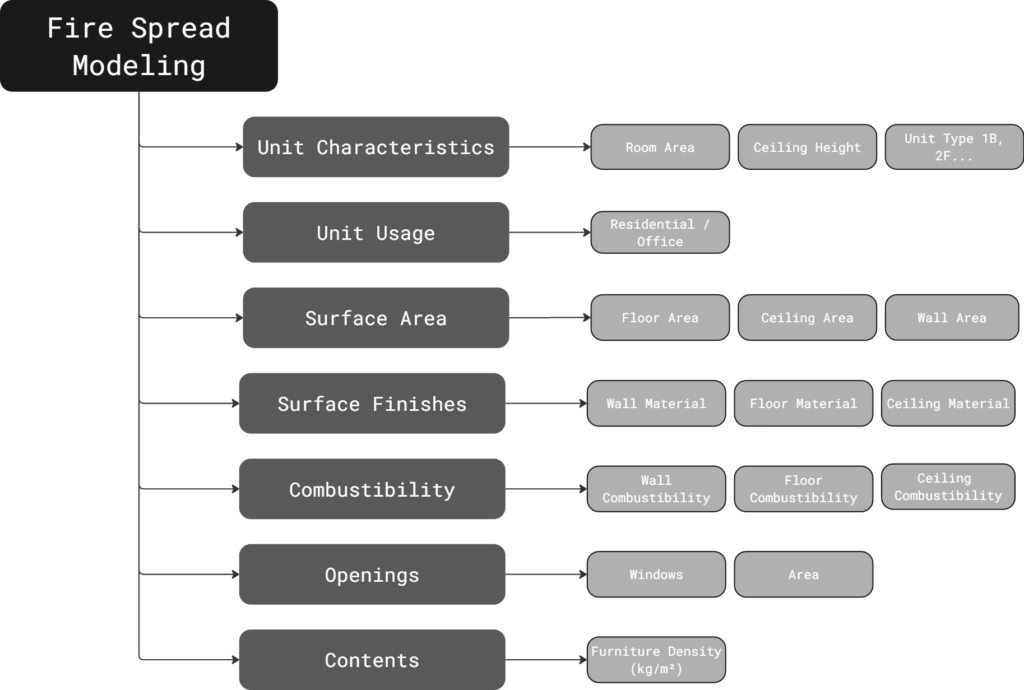
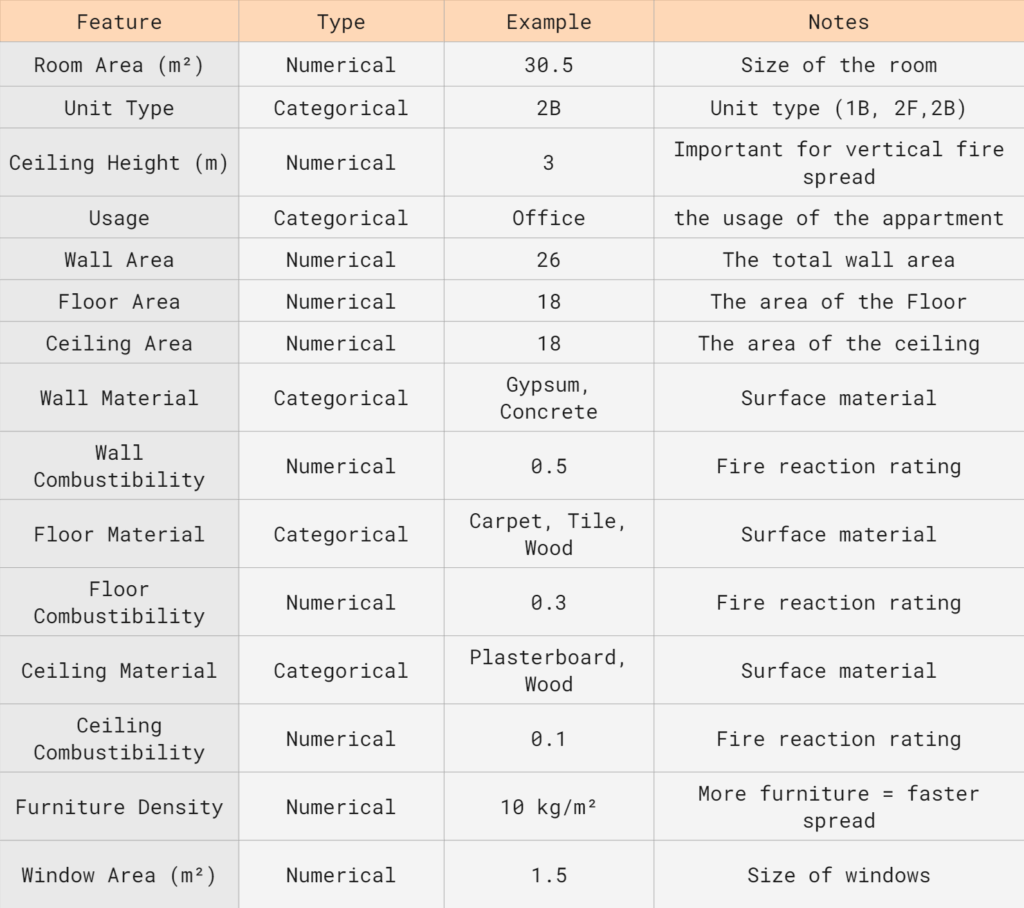
We categorized fire-relevant features into spatial, material, and combustibility domains to structure the dataset for predictive modeling.
Initial Dataset
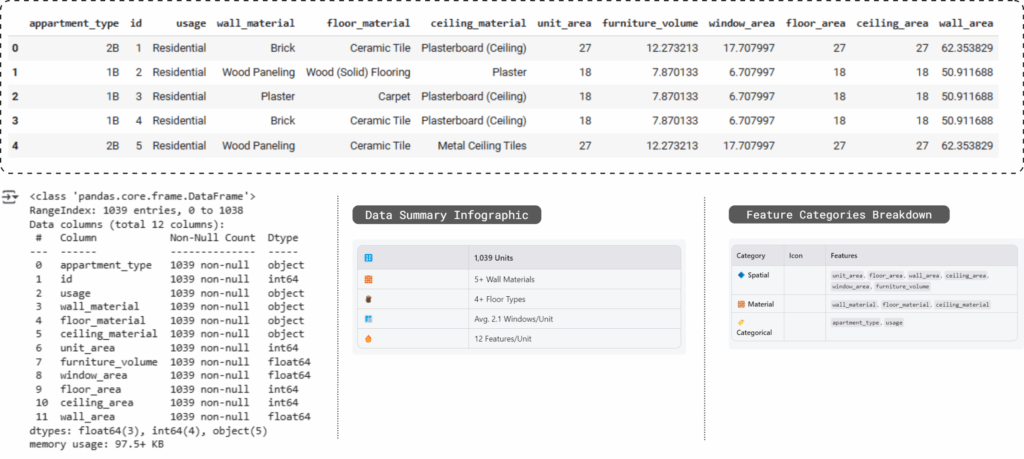
The dataset contains over 1,000 apartment units, each encoded with spatial, material, and categorical attributes relevant to fire risk analysis.
EDA (Exploratory Data Analysis)
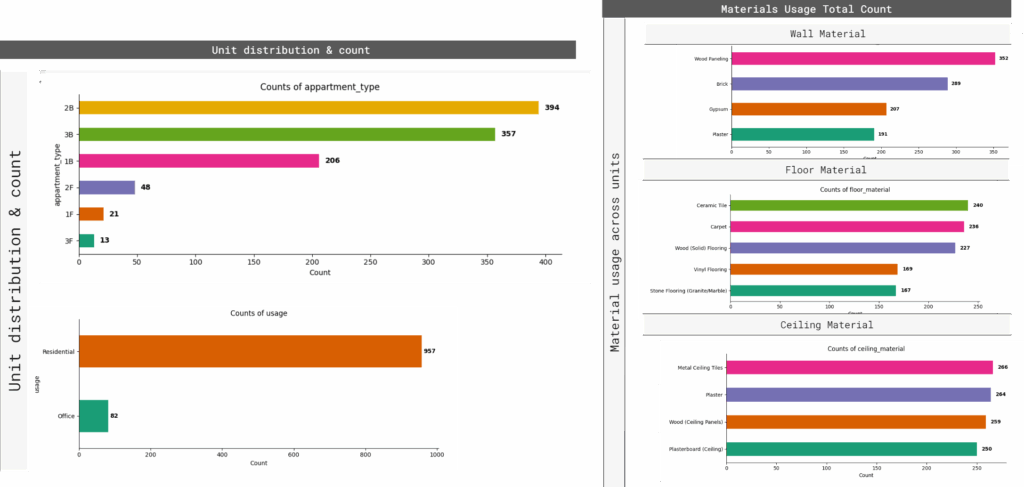
We performed an initial exploratory analysis to quantify the distribution of unit types, usage categories, and material selections.
This provided insight into the dominant feature classes, highlighting a high prevalence of residential layouts and materials like ceramic tile and plasterboard.
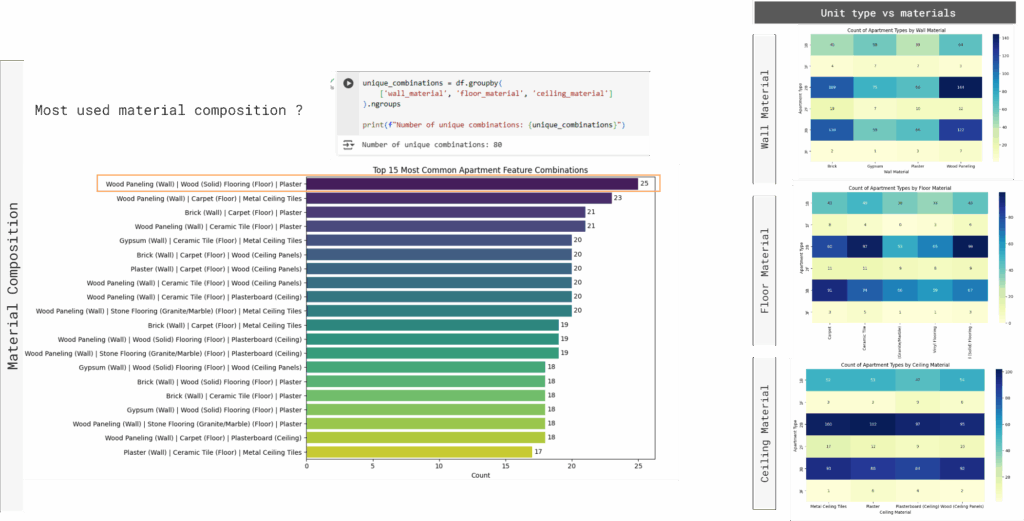
We examined the frequency of material combinations across wall, floor, and ceiling finishes to identify common construction patterns.
Heatmaps were used to analyze the correlation between unit types and materials, revealing dependencies that may influence fire risk profiles.
Training Trials and Efforts
Risk_Label Calculation trials
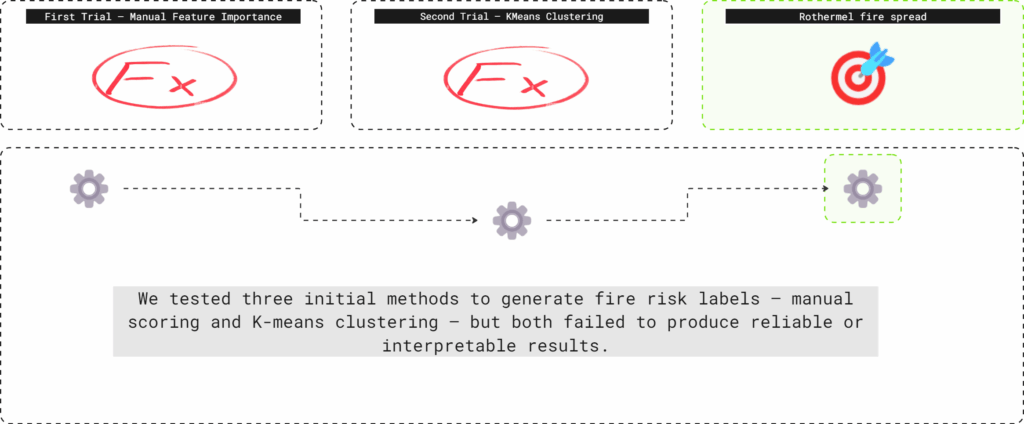
We tested three initial methods to generate fire risk labels — manual scoring and K-means clustering — but both failed to produce reliable or interpretable results.
First Trial – Manual Feature Importance
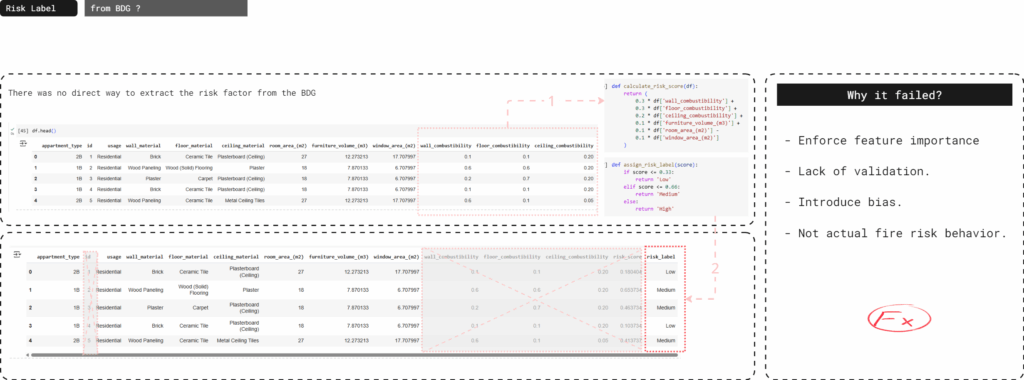
Manual scoring imposed assumed feature weights without validation, causing models to learn our logic instead of real fire risk behavior.
Second Trial – KMeans Clustering
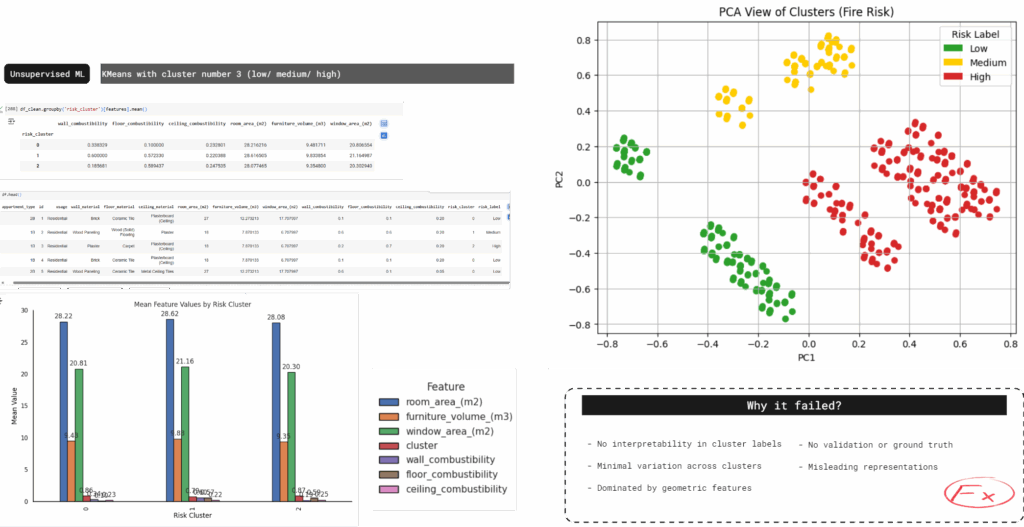
K-Means produced three clusters, but fire-related features showed no real variation across them. The grouping was dominated by size and layout, not combustibility — making the clusters visually clean, but practically meaningless.
Third trial – Rothermel fire spread
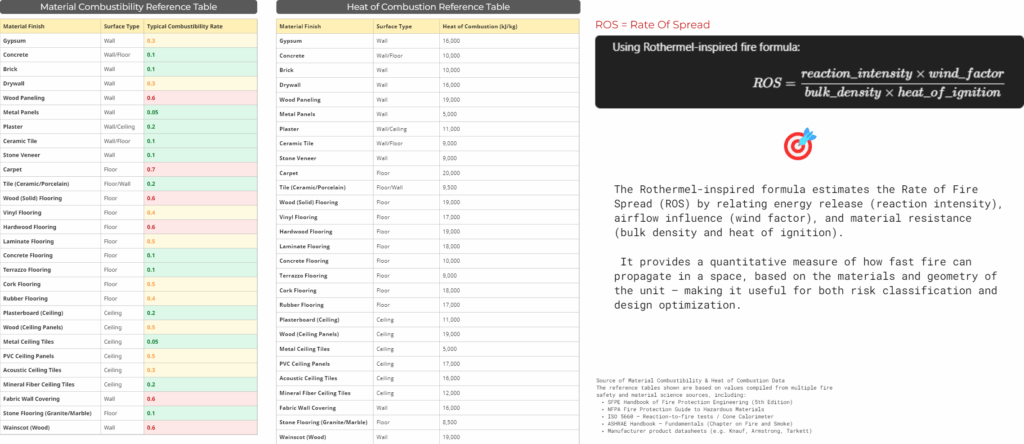
We used standard references to assign combustibility and heat of combustion to materials, then applied a Rothermel-inspired formula to compute Rate of Spread — enabling data-driven assessment of fire propagation risk based on material and spatial characteristics.
Calculating Rothermel fire spread risk
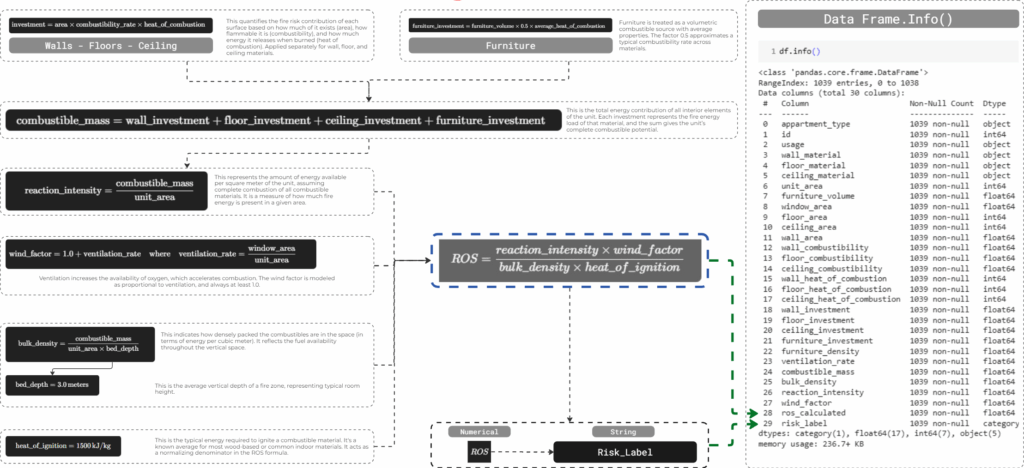
We implemented a simplified Rothermel-based formula to calculate a fire spread risk score per unit. Each term in the equation was mapped to available features — such as combustible material investment, floor area, and ignition thresholds — enabling us to quantify fire propagation in a scalable and interpretable way.
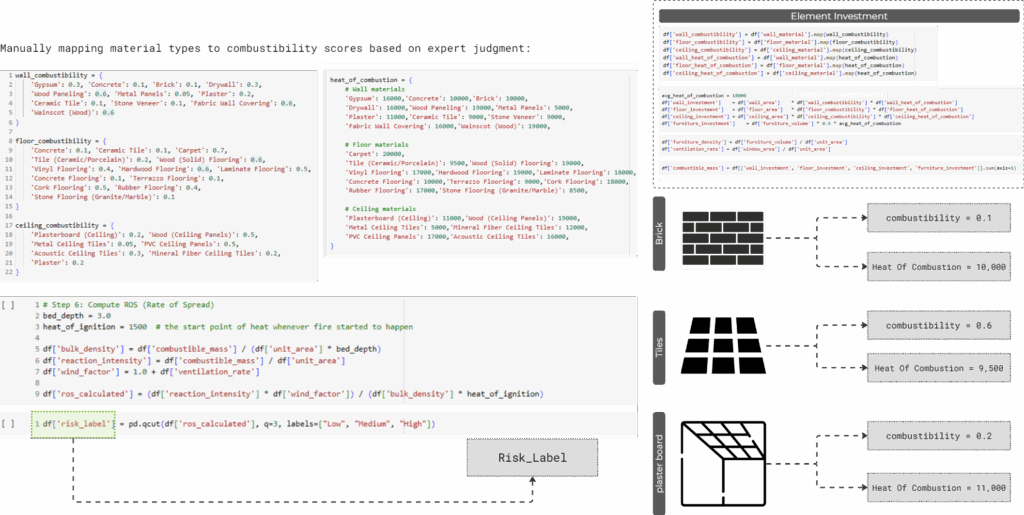
First, we manually mapped material types to combustibility and heat of combustion values. These were then used to compute investment scores per element surface, and combined into total combustible mass. Using this, we calculated the Rate of Spread, and finally classified each unit into low, medium, or high fire risk using quantile bins .
Final Dataset

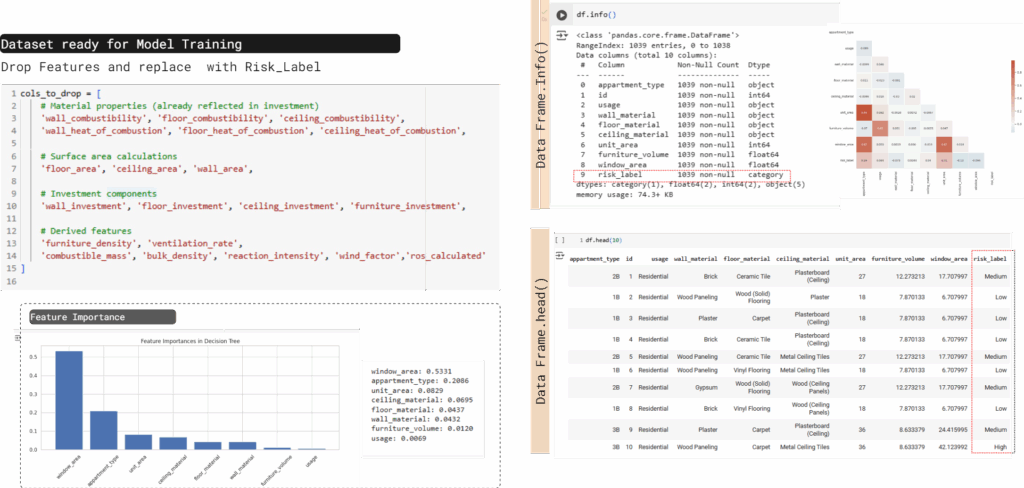
We cleaned the dataset by dropping intermediate features used in ROS calculation and kept only the final risk_label. This gave us a compact and interpretable dataset ready for model training, with risk_label as the target variable.
The dataset is now clean, compact, and ready for machine learning classification.
Model Training
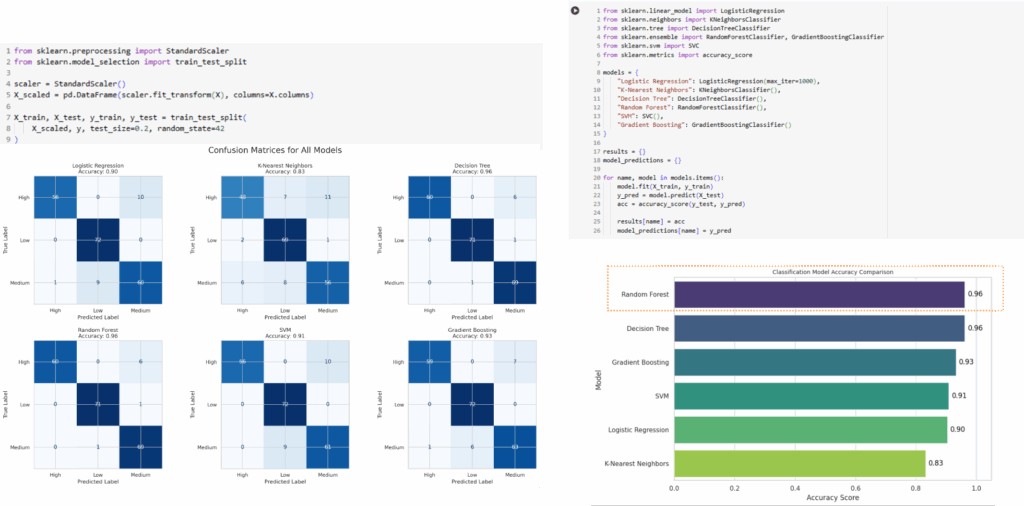
We trained six classification models using the final dataset and evaluated their performance with confusion matrices and accuracy scores. Random Forest achieved the highest accuracy at 96%, making it the most reliable model for predicting fire risk levels.
Random Forest gives the best accuracy on the test data.
Fire Spread Predictor (UI):
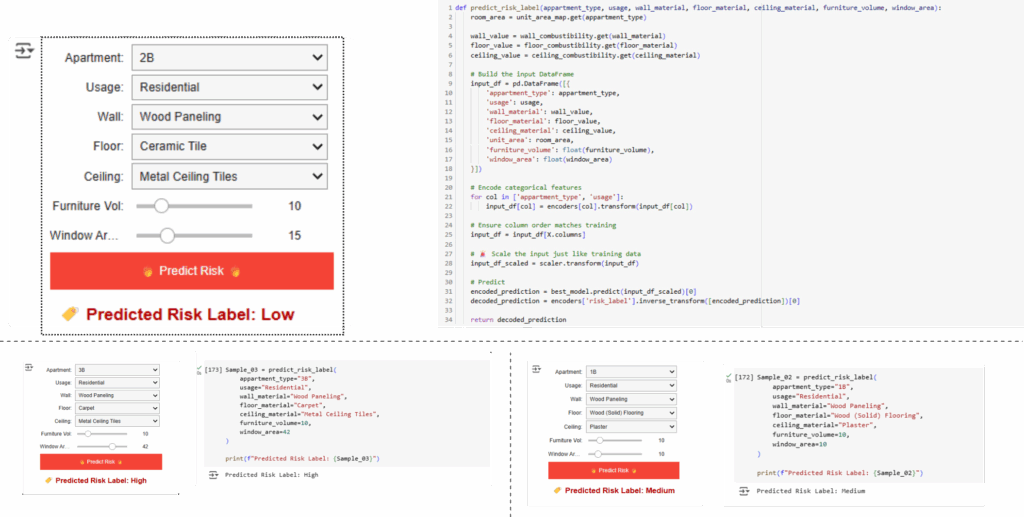
Finally, we built a simple UI that allows users to input layout properties and instantly get a predicted fire risk label. The app uses the trained model behind the scenes, making fire risk assessment more accessible, fast, and interactive for designers or planners.
