Visual Storytelling using SDXL _LoRA_Gradio
Exploring Dali and Bosch-inspired storytelling with SDXL + Gradio
Our project is a tool that helps architects turn stories into surreal image sequences. We explored styles inspired by Dali and Bosch to create dreamlike visuals. Although we trained a custom model, we used prompt-based image generation in the final version. Our Gradio app lets users enter a short text and get a Video showing a visual journey — offering a creative way to present projects.
Use – Case
Storytelling Tool for Architectural Presentations
User: Architects & designers
Need: Architects need to tell compelling project stories in early design or competition stages.
Problem Solved: Manually composing narratives from renders is time-consuming and fragmented.
Frequency of Use: During client presentations, design reviews, competitions, or stakeholder pitches.

SDXL _LoRA + User Input: Story Text + Style



30 images as a dataset

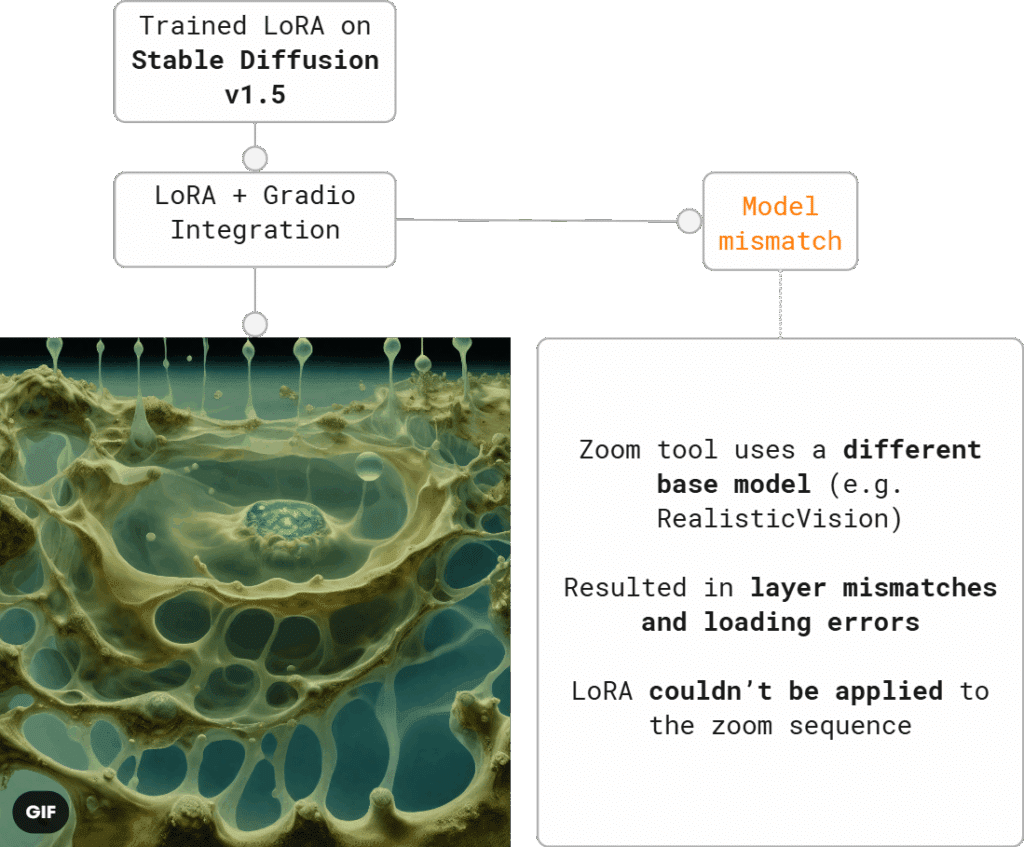
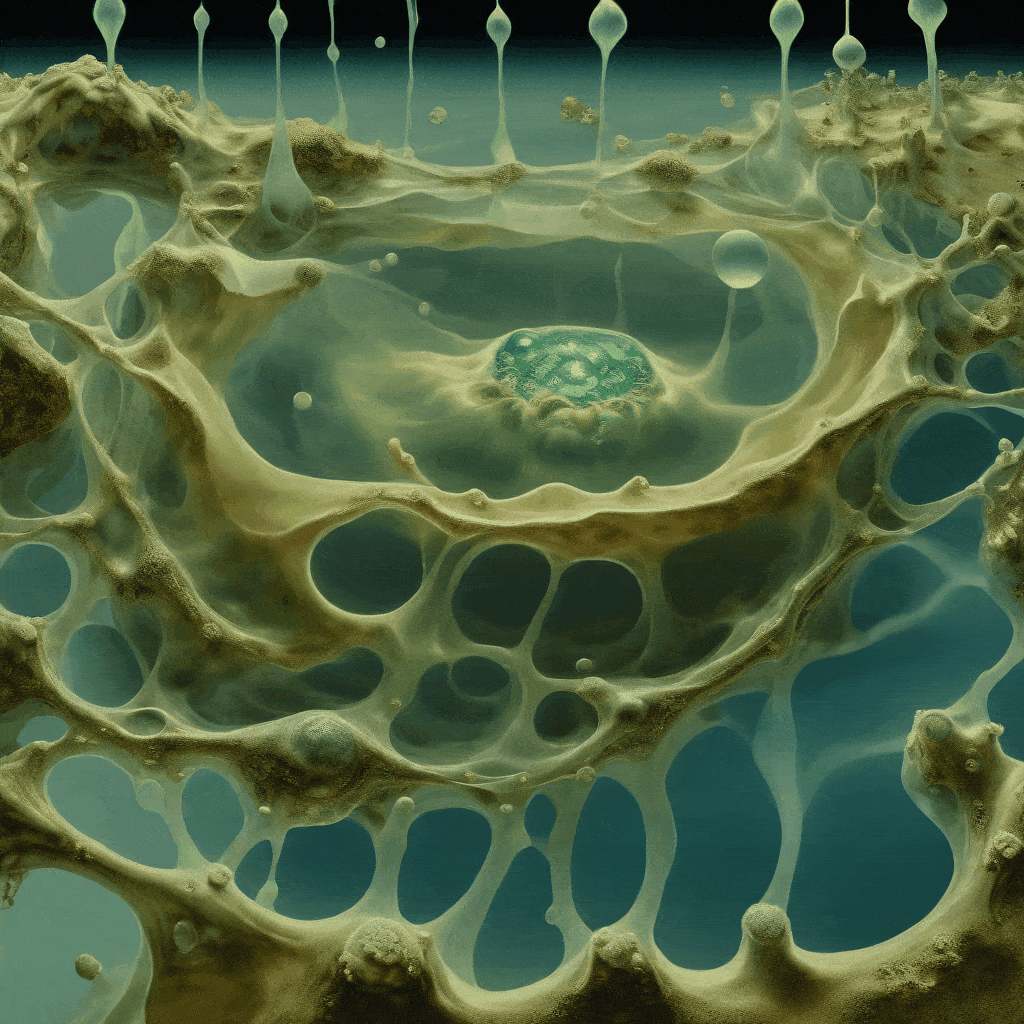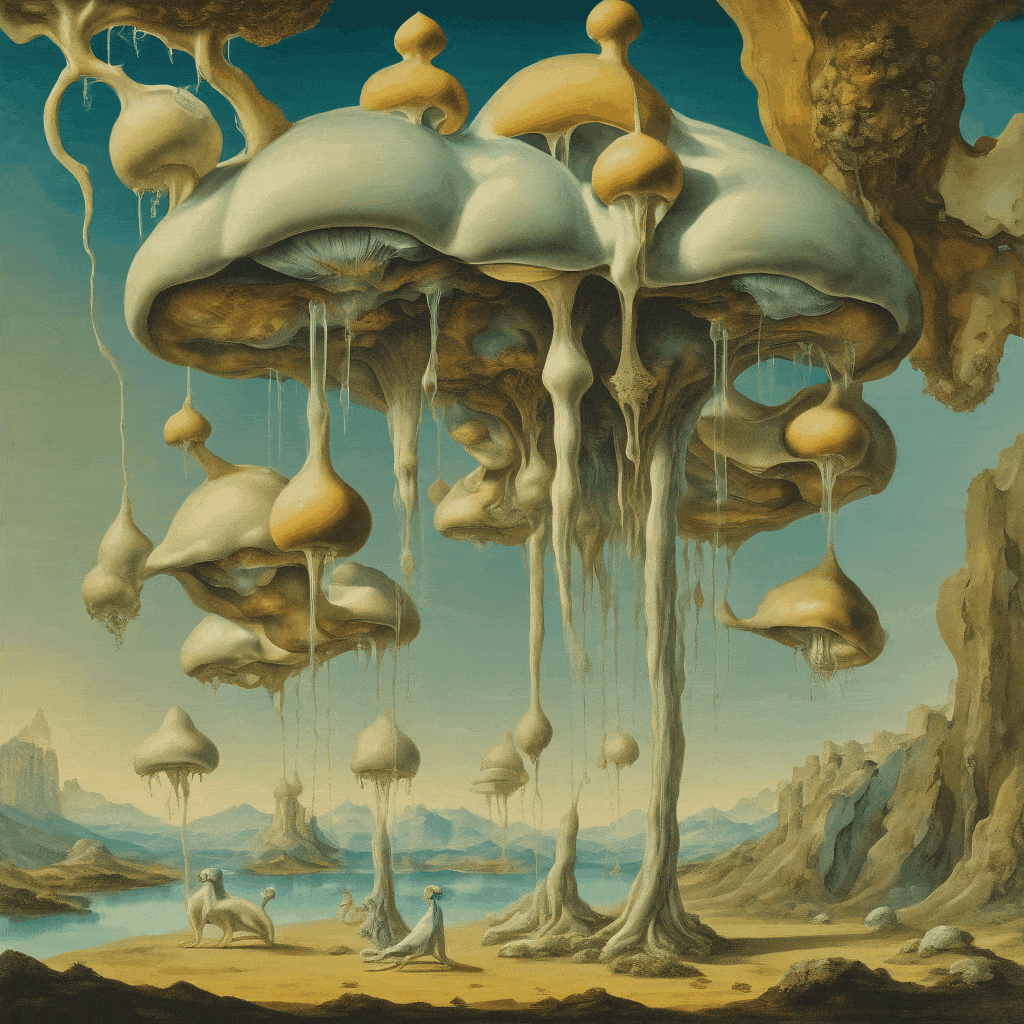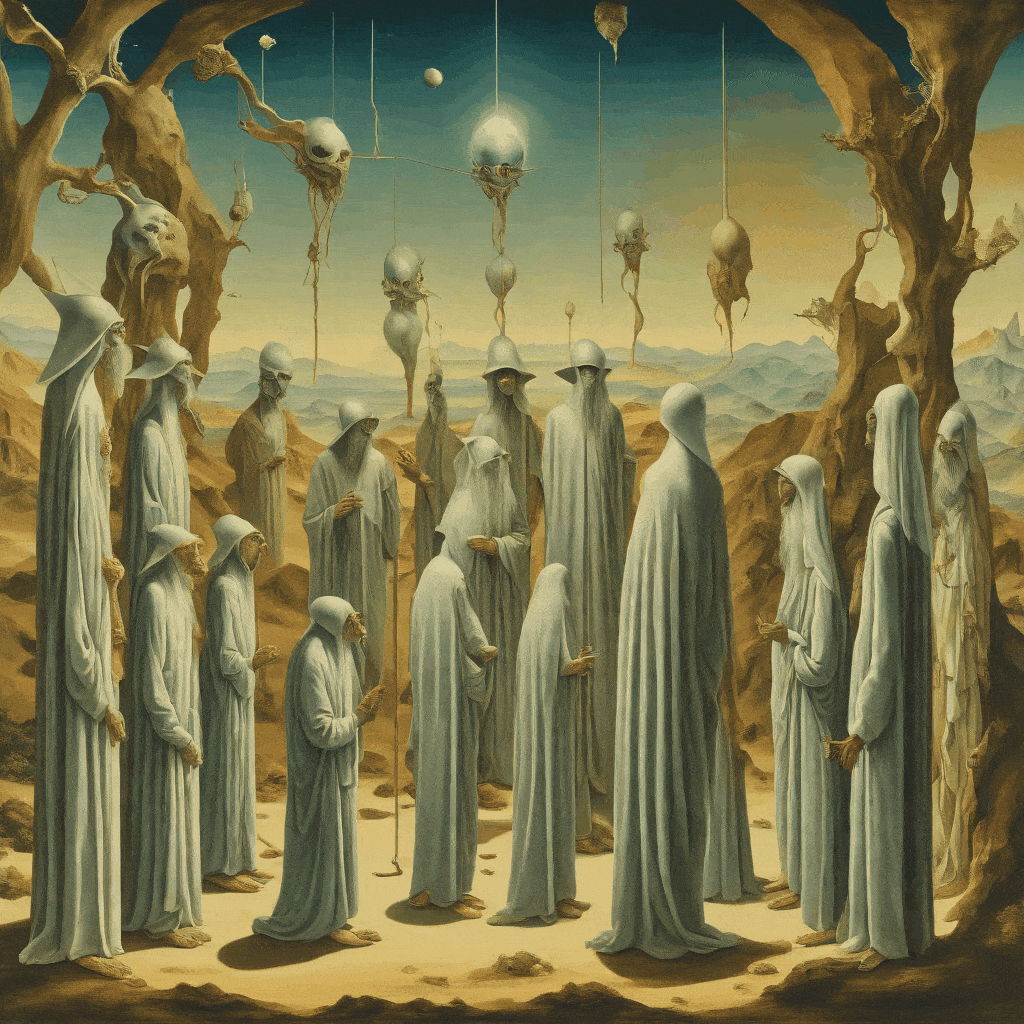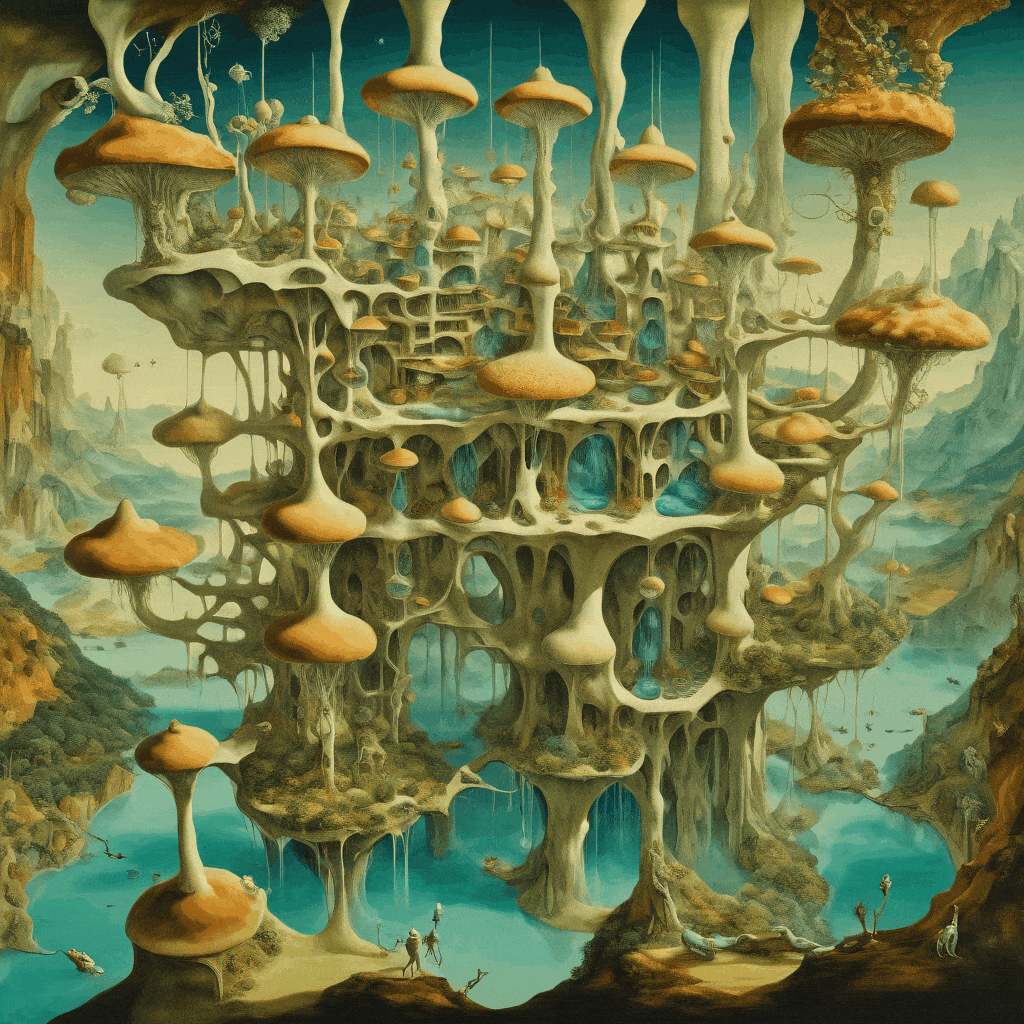
From Mycelium to Society: A Surreal Narrative in LoRA Training
“Mycelium awakens, evolving into a human-like creature. It walks, spreading spores, forming a society shaped by surreal architecture”

Gradio tool uses an LLM to turn stories into animated zoom sequences
Code insight – How it works
NARRATIVE TO VISUAL PROMPT PREPARE THE BASE FRAME SIMULATE ZOOM-OUT EXTEND SCENE WITH INPAINTING

COMPOSITE THE NEW OUTPAINTED IMAGE GENERATE INTERPOLATION FRAMES REPEAT FOR MULTIPLE STEPS COMPILE THE FRAMES INTO A VIDEO
Beyond the Frame Gradio Interface
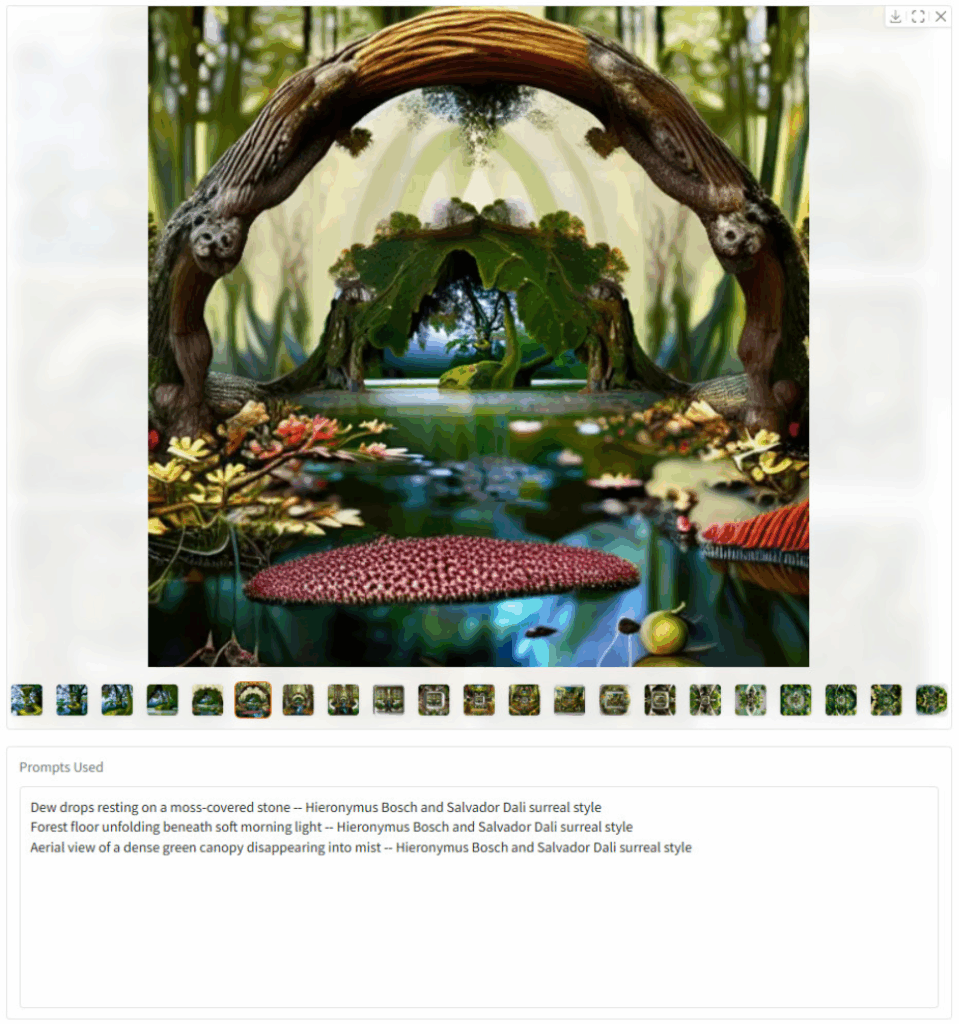
Output
Users Can View a Frame Carousel Alongside the Full Prompt Sequence
Inpainting Model Comparison
Prompt a castle in a jungle, a jungle in a cave, a cave in a cathedral
Model ID stabilityai/stable-diffusion-2-inpainting
Outpaint Steps 20
Zoom Strength 128
Frame per Steps 30
Seed 0
Prompt a castle in a jungle, a jungle in a cave, a cave in a cathedral
Model ID parlance/dreamlike-diffusion-1.0-inpainting
Outpaint Steps 20
Zoom Strength 128
Frame per Steps 30
Seed 0
Zoom Factor Comparison
Prompt a castle in a jungle, a jungle in a cave, a cave in a cathedral
Model ID stabilityai/stable-diffusion-2-inpainting
Outpaint Steps 20
Zoom Strength 128
Frame per Steps 30
Seed 0
Prompt a castle in a jungle, a jungle in a cave, a cave in a cathedral
Model ID stabilityai/stable-diffusion-2-inpainting
Outpaint Steps 20
Zoom Strength 64
Frame per Steps 30
Seed 0
Prompt input
The primary input mode is a list of individual prompts. An automated system appends a style suffix to each prompt to ensure visual and stylistic continuity.
Prompt a beautiful room with a window, a corridor with dark boiserie, a window carved in stone
Model ID parlance/dreamlike-diffusion-1.0-inpainting
Outpaint Steps 35
Zoom Strength 128
Frame per Steps 30
Seed 170727
Prompt generated
a beautiful room with a window — Hieronymus Bosch and Salvador Dali surreal style
a corridor with dark boiserie — Hieronymus Bosch and Salvador Dali surreal style
a window carved in stone — Hieronymus Bosch and Salvador Dali surreal style
Prompt + image input
In this mode, generation begins from an initial image and a prompt. The prompt guides the style and content of the first frame, which then evolves through successive zoom-out steps.
Prompt a floating castle, a sea full of boat and mythological creatures, a land made of ice and mysterious rock formation
Model ID stabilityai/stable-diffusion-2-inpainting
Outpaint Steps 20
Zoom Strength 128
Frame per Steps 30
Seed 0

The same prompts are also tested without the initial image input
Prompt a floating castle, a sea full of boat and mythological creatures, a land made of ice and mysterious rock formation
Model ID stabilityai/stable-diffusion-2-inpainting
Outpaint Steps 20
Zoom Strength 128
Frame per Steps 3
Seed 0
Inside the LLM’s Process
This function uses a large language model (LLM) to turn a short text description into a sequence of visual prompts that gradually zoom out—perfect for creating frame-by-frame animations or infinite zoom effects. It sends the user’s input to OpenAI’s GPT model with a special instruction: break the description into a fixed number of short, Stable Diffusion–style prompts, each showing a slightly wider view than the last while keeping the subject, style, and lighting consistent. The result is a smooth, coherent series of prompts that can be used to generate a zooming visual narrative. If the LLM call fails, it falls back to a default sequence to keep things running.
Prompt A men in Venice
Model ID parlance/dreamlike-diffusion-1.0-inpainting
Outpaint Steps 35
Zoom Strength 128
Frame per Steps 3
Seed 0
Prompt generated
Mysterious man in a gondola on Venice canal — Hieronymus Bosch and Salvador Dali surreal style
Silhouetted figure against Venetian sunset — Hieronymus Bosch and Salvador Dali surreal style
Masked man wandering through narrow Venetian streets — Hieronymus Bosch and Salvador Dali surreal style
Glimpse of a man disappearing into Venetian mist — Hieronymus Bosch and Salvador Dali surreal style
Specter of a man haunting Venice’s grand square — Hieronymus Bosch and Salvador Dali surreal style
Story input with LLM
By providing a story, the system triggers a call to LLM, which elaborates a sequence of visual prompts. An automated suffix is attached to create style continuity.
Prompt A child stands at the edge of a quiet forest, staring into a floating mirror framed in ivy. As she steps through it, the forest unravels into a bioluminescent garden, where flowers pulse like jellyfish and trees stretch into the stars
Outpaint Steps 20
Zoom Strength 128
Frame per Steps 30
Seed 0
Prompt generated
Child enters mirror, forest transforms into glowing garden — Hieronymus Bosch and Salvador Dali surreal style
Bioluminescent flowers pulse, trees reach for the stars — Hieronymus Bosch and Salvador Dali surreal style
Trained LoRA Model Didn’t Integrate with Zoom Tool—But Future Integration Remains Promising