
Abstract
Architectural drawings and construction documentation are critical in the construction industry, serving as the main means of communication between different disciplines and acts as a blueprint on guiding the construction of the built environment. However, errors in these drawings are quite common and often leads to significant delays, cost overruns, and structural issues.
This thesis explores the application of machine learning techniques to analyze architectural drawings for errors, aiming to enhance the accuracy and efficiency of error detection in the architectural and construction fields and minimizes the room for error. Our research begins with a comprehensive review of the current state of architectural drawing analysis and the integration of machine learning in this domain. The unique challenges of interpreting architectural drawings, such as varying styles, scales, and notations, are discussed.
The primary data sources for this research include a diverse set of architectural drawings in both digital and scanned formats, annotated with known errors along with international drafting standards and universal drawing codes. The framework is designed to identify common errors, such as dimension discrepancies, misalignments, and missing elements. Advanced feature extraction methods are employed to enhance the model’s accuracy, and the models are trained and validated using a labeled dataset of architectural drawings. The project aims to demonstrate that machine learning models can effectively detect errors in architectural drawings with a high degree of accuracy. The predictive models developed in this research can serve as automated review tools, significantly reducing the time and effort required for manual error checking.

State of The Art
Vision Language, Image Segmentation and Object Detection Machine Learning Models have been successfully implemented in various sectors. The research by Guido Maciocci using VLM, Florence-2 in specific to identify architectural elements.

As well as in the medical field researchers using YOLO models to identify different types of cancers from patient photo scans

Process Overview
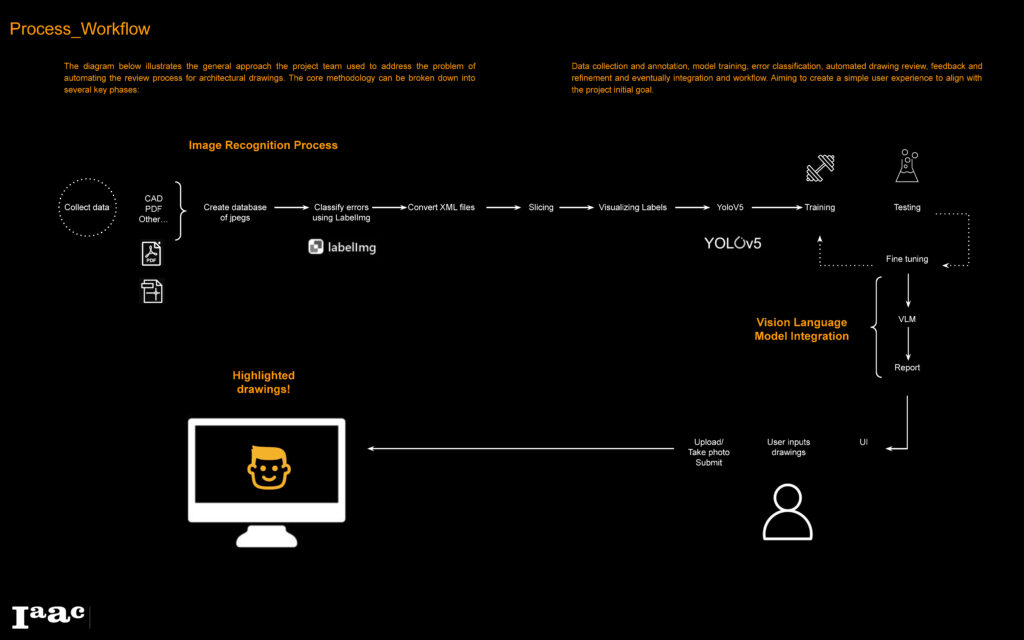
Dataset Preparation
The first step in the process was to collect as much relevant data as possible, specifically focusing on gathering a diverse and extensive set of architectural drawings. Leveraging the team’s access to a professional environment, we were able to amass a significant number of architectural drawing submissions, primarily from projects in the advanced stages, such as schematic design and detailed design phases. This provided a rich dataset of high-quality, well-developed drawings.
The collected sample encompassed a wide variety of drawing types, including plans, sections, elevations, and technical details, as well as a diverse range of project typologies. The intention behind this broad collection was to ensure representation of different architectural challenges and to replicate the potential problems that can occur across various scales and drawing types. By covering a broad spectrum of architectural styles and functional building types, the dataset allowed us to analyze common and unique drafting errors in different contexts.
The projects in this dataset varied significantly in complexity, ranging from high-rise towers with intricate geometry to simpler single-story buildings.. The diversity of the data not only enriched the training process but also ensured that our analysis could be applied to a broad array of real-world scenarios.
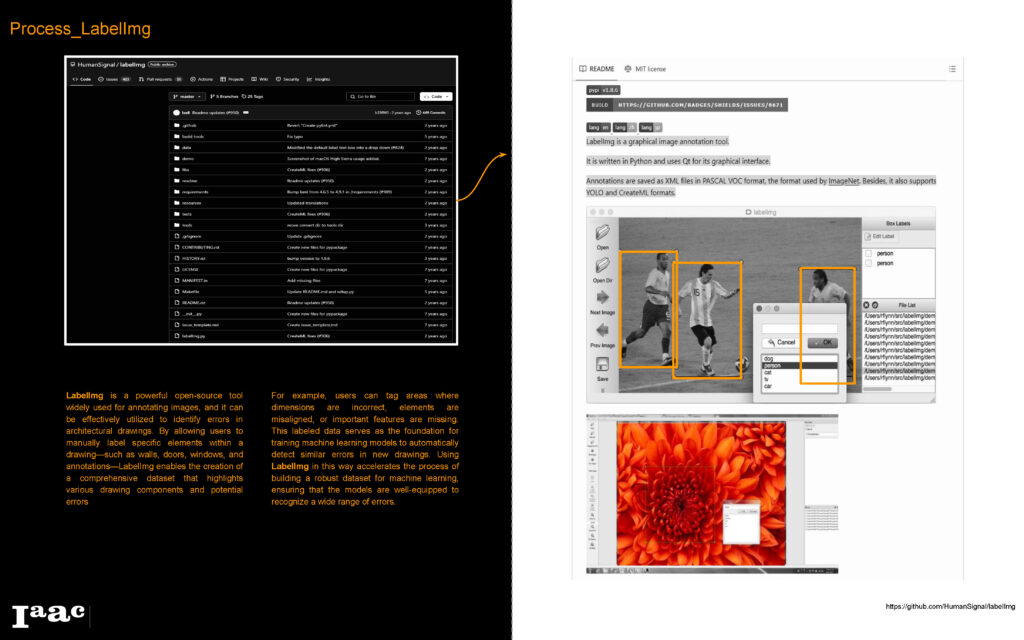
Starting by Labeling all errors using LabelIMg, we created a comprehensive dataset that includes a various samples of the selected errors.

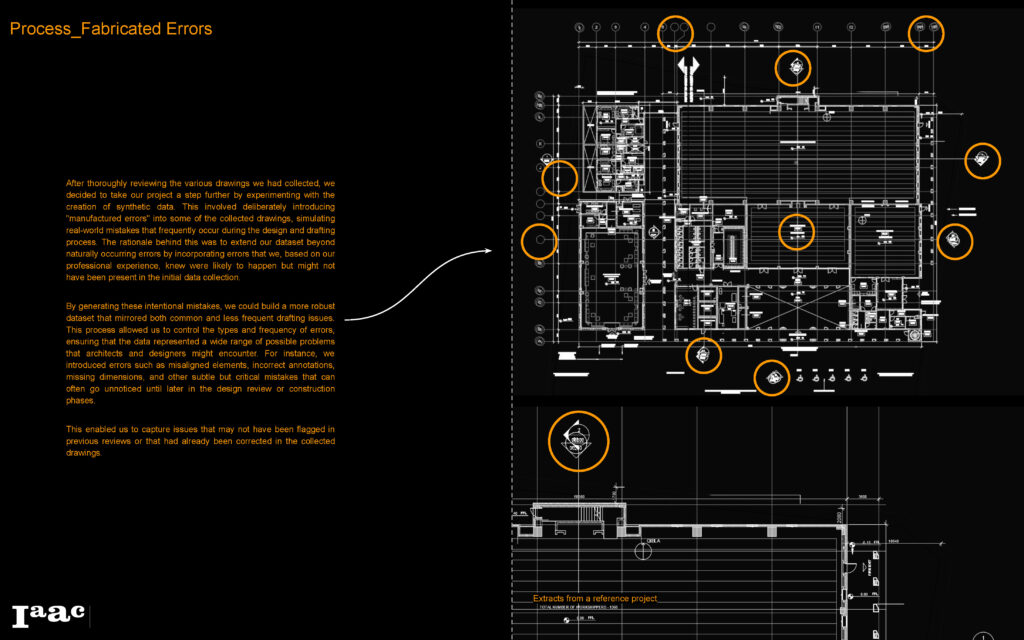
Then we start to synthesis some additional errors to ensure that all error classes are covered in various forms.

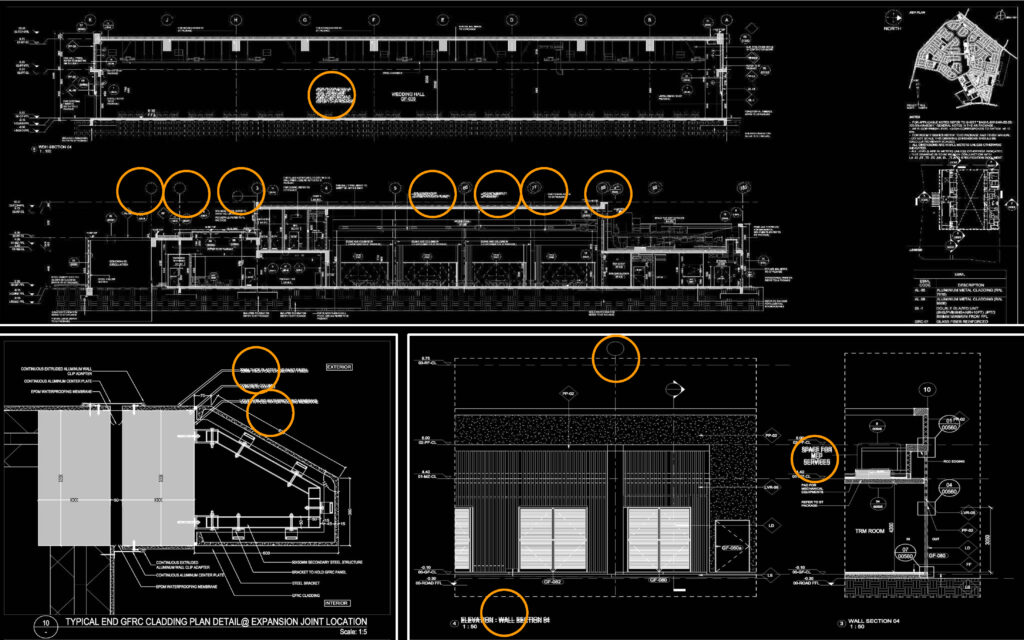
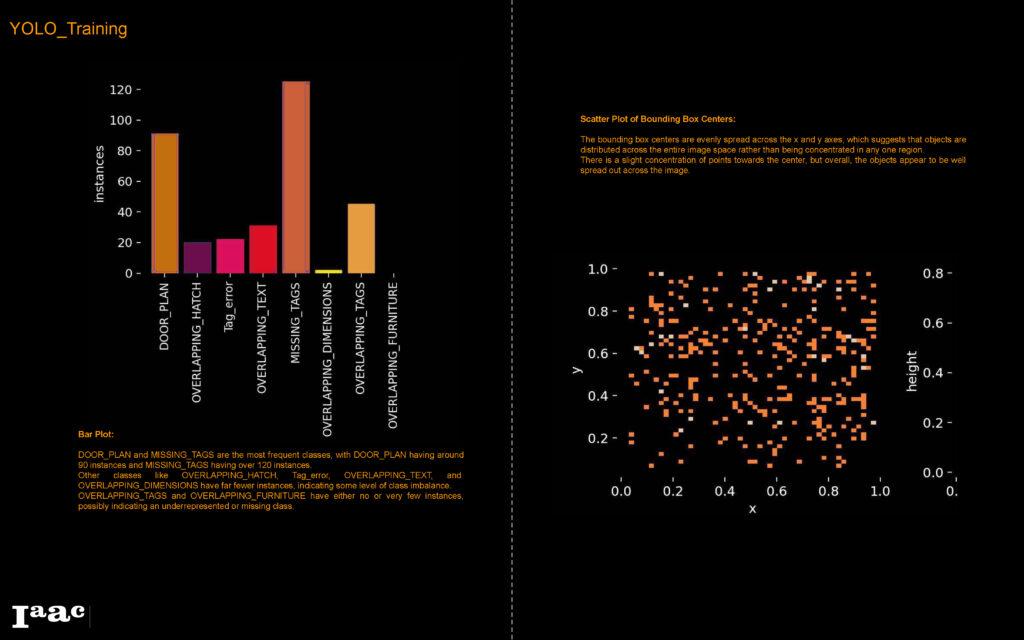
YOLO Training
We selected YOLO (You Only Look Once) object detection and image segmentation model due to its high accuracy and ability to handle various types of visual media.



We first experimented with YOLOv5 and after training our model, we found that the performance on some error classes wasn’t very successful
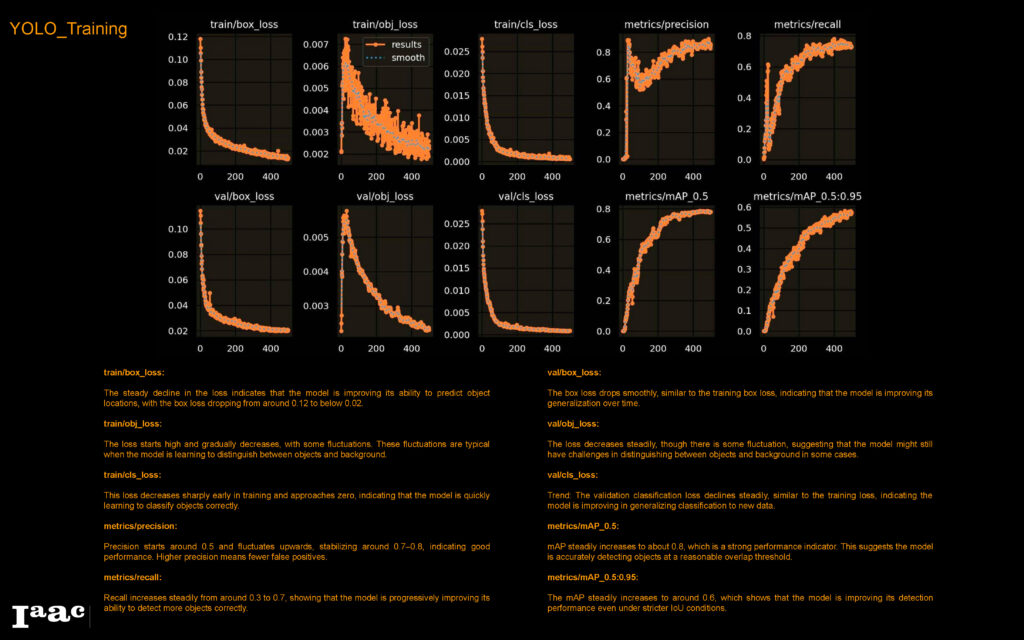
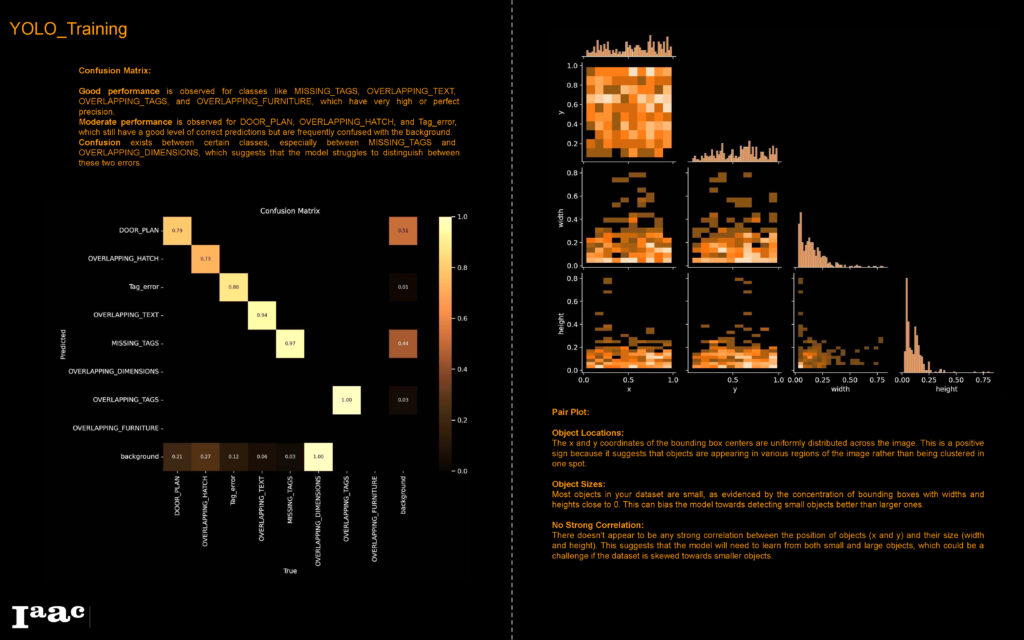
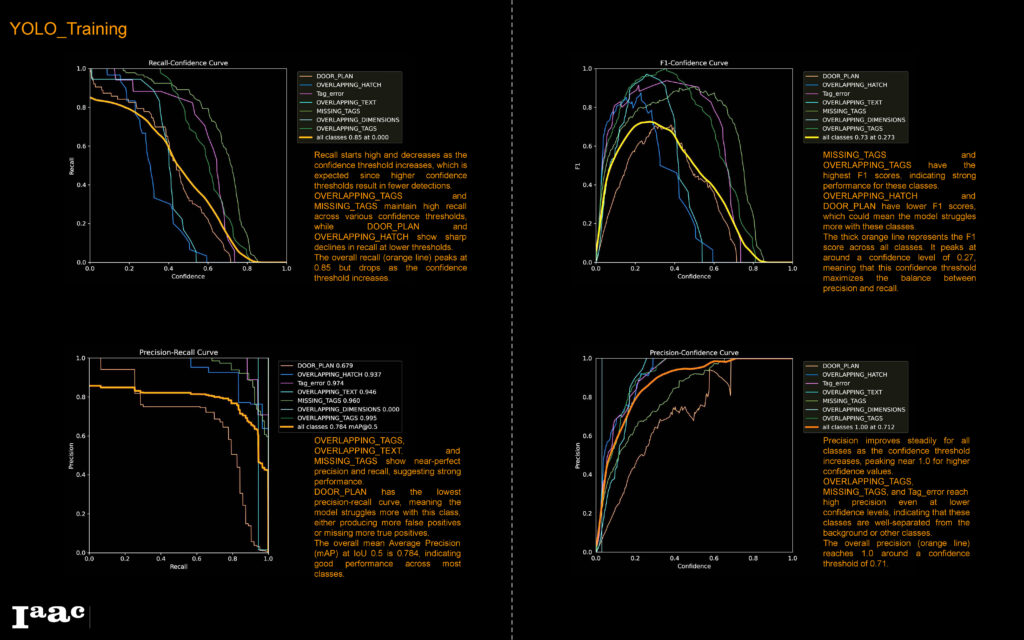
Based on that, we decided to experiment with additional YOLO Models that can handle more complex datasets; in our case, we used YOLOv5x and YOLOv8x

It was evident that both YOLOv5x and YOLOv8x are more accurate than YOLOv5 as well as faster, however, to see how each model would perform, we tested all three models on a drawing that wasn’t part from the dataset.
Testing
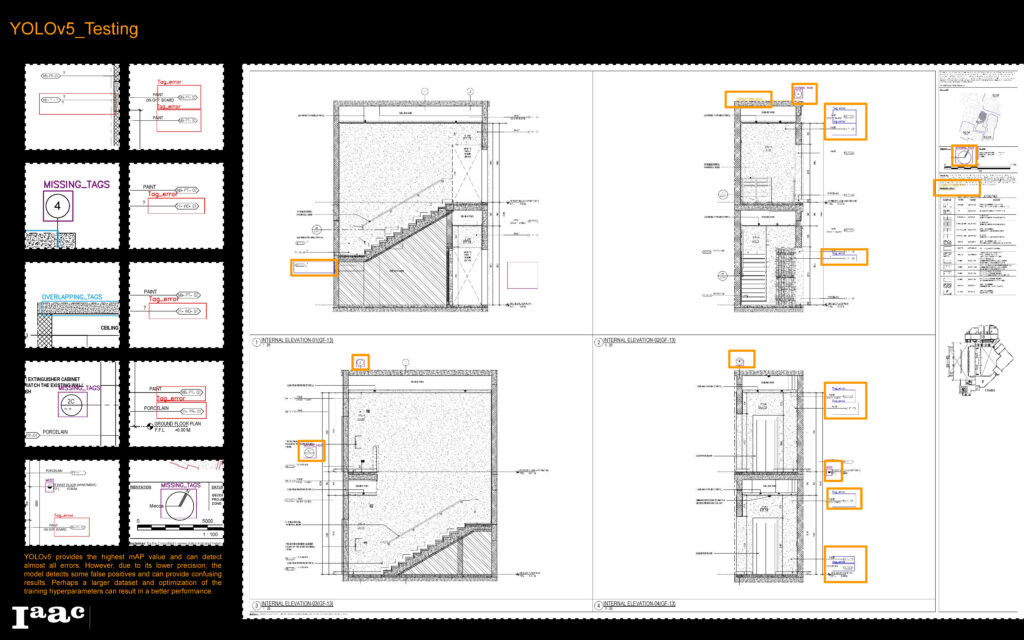

Upon testing all 3 models, the results were quite surprising! YOLOv5 managed to detect the most potential instances. However, in terms of accuracy and precession, it did not perform as well as YOLOv5x. One the other Hand, YOLOv8x was indeed the fastest in processing the results, but it couldn’t detect much of the errors. In conclusion, we found that both, YOLOv5 and YOLOv5x are both viable options for detecting errors in architectural documentation drawings.
VLM Integration
Since we now managed to utilize YOLO models for detecting errors in Architectural drawings, we decided to explore how a Vision Language Model (VLM) might be able to take the project further by analyzing the error labels that were detected by YOLO and find out if there are any additional errors present on the drawing.

We stated by trying ChatGPT vision capabilities and compared to LLaVA 13-B.
A reasonable good performance by the chatgpt model, mainly identifying the errors within the bounding boxes. However it seems that it is not necessarily identifying new errors, but rather generalizing errors that would be within typical architectural/construction drawings
Llava seems to ignore the previously annotated errors (as it should) however the new error that it identifies regarding the staircase is not correct. But what is interesting is that the model is going beyond graphical errors/representations and is looking into potential design errors.

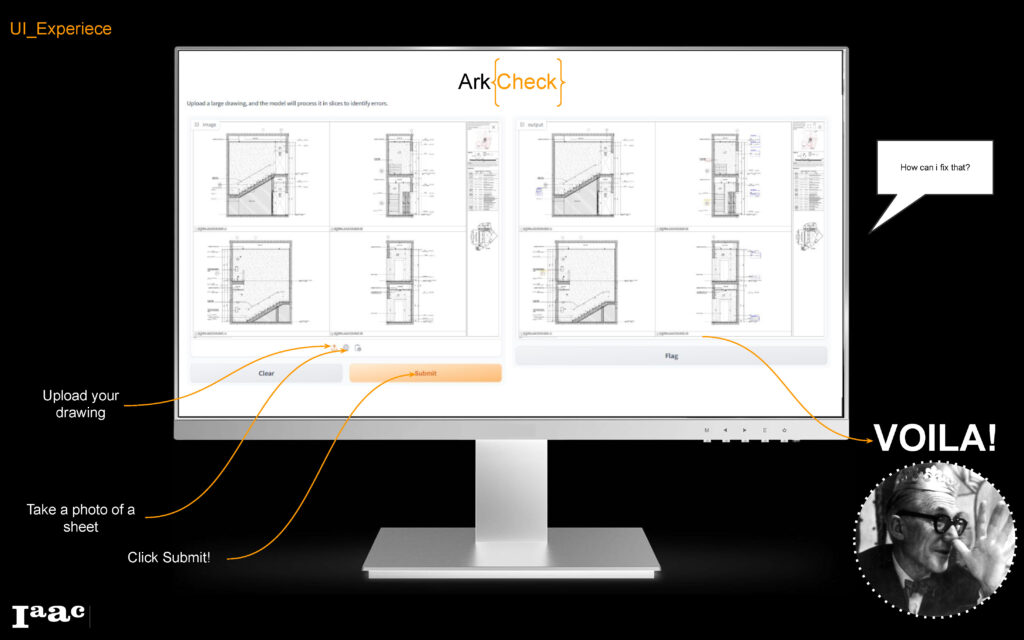
User Interface
For the UI we used Gradio, that has a great documentation part geared towards machine learning tools, a simple and user-friendly tool where you upload/take a photo of drawing…submit and voila
Conclusion
At the end of this research, we do believe that utilizing machine learning as a tool to review drawings can have a very positive impact in terms of saving time, reducing cost, increasing accuracy, and enhancing collaboration. However, at the time being our research shows that with more training, catching drafting and quality errors could be achieved but still coordination and design errors will need a designer’s input.
On average, an architectural drawing needs around 5-10% of its time on review, by alleviating the burden of manual error checking architects and designers can redirect their focus towards what truly matters: Innovation and Creativity in design…
