Data Encoding

Source: Data Encoding 2025-26 seminar, by Students: Maria Sanchez Dominguez, Charles Abi Chahine, Emilie El Chidiac, Lakzhmy Zaro.
In a moment where architectural practice is increasingly saturated with AI-driven marketing, buzzwords, and opaque “black box” claims, it is becoming harder to distinguish genuine mathematical principles from technological hype. This course intentionally steps away from the noise to focus on fundamentals. As architecture enters the AI race, future practitioners need a clear, hands-on understanding of how these technologies actually work, not just how they are advertised. This seminar offers a scaffolded, practice-based introduction to the core mechanics of machine learning. Through best-practice examples, rigorous dataset curation, and simple yet powerful modelling workflows, students will learn how targeted ML predictions can be meaningfully applied to architectural questions. Emphasis is placed on designing custom datasets and understanding how their structure interfaces directly with model behavior, laying the foundation for reliable, interpretable, and domain-specific AI applications informed by architectural domain knowledge.
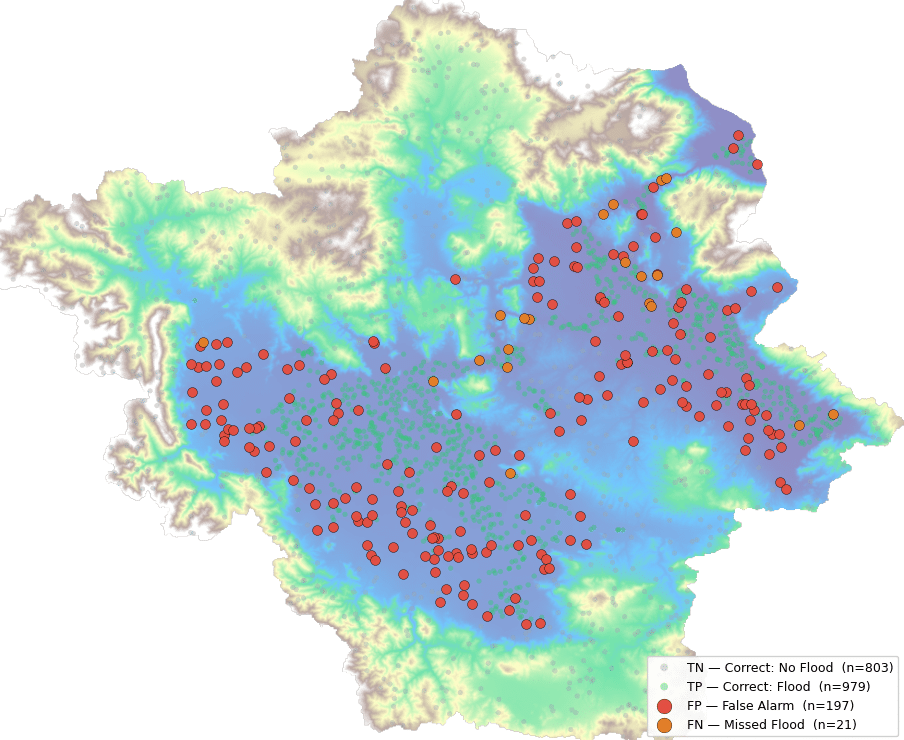
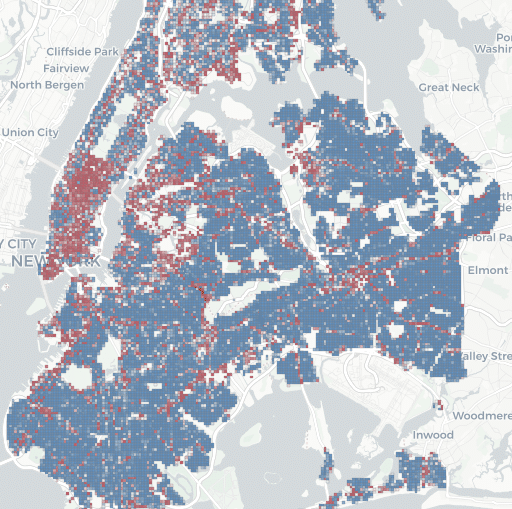
Here we don’t look at ML as “intelligence” but rather as an alternative data-driven modelling paradigm for problems that might be too complex for mechanistic computation. Differently from analytical or procedural models where processes are computed using iterative, time-based, heavy calculations and pre-assigned property parameters, machine learning models learn by example through searching for an approximated relationship between the inputs and the targets. Once trained, they can be easily deployed within a design workflow to offer targeted predictions. While these models promise advantages and productivity, they are notoriously data-hungry. Many open source datasets are available online for training of state-of-the-art models, however these datasets are not relevant for architectural applications.
Dataset design is the enabler to using Machine Learning algorithms in different fields. While an existing ecology of algorithms provides architectures suitable to specific types of problems be classification or regression, the models must be trained on datasets pertaining to the problem they are expected to solve. These custom datasets can be composed through web-scraping, or be generated, either computationally through heuristic algorithms, or through sensing and digitizing physical samples. Dataset design requires several criteria to be followed: Increased sample diversity, bias avoidance and ambiguity avoidance. These criteria ensure that the problem is well represented, with equal distribution and without confusion – and is the key to a successful ML training campaign.
In this seminar, you will be introduced to conceptual perspectives around dataset design, feature encoding, for targeted ML applications. You will develop your own ML pipeline for a use case of your choice taking departure from an architectural application of your interest. Working in groups, you will be tasked to curate a dataset and train an adequate model for your predictive task. Through the study of the parameter space and feature distribution and representation, you will propose a dataset encoding method, and evaluate it through the training of shallow models as well as artificial neural networks. A key milestone will be designing a computational pipeline bringing the prediction back into the design workflow. This is an occasion to step back from “mega-models” such as LLMS and Diffusion Models, and build a foundational understanding of the basics of ML.
Learning Objectives
At course completion the student will:
- Become knowledgeable of fundamental machine learning concepts and workflows.
- Reflect analytically on notions of parameter space, data encoding and feature selection
- Acquire competences in developing custom datasets for architectural application
- Acquire competences in feature engineering (dimensionality reduction, data analysis)
- Acquire a hands-on experience in using state of the art machine learning libraries
- Develop appropriate representational methods and tools to showcase your findings
- Collaborate effectively within a group-working exercise