
‘Navigating Future Convenience’
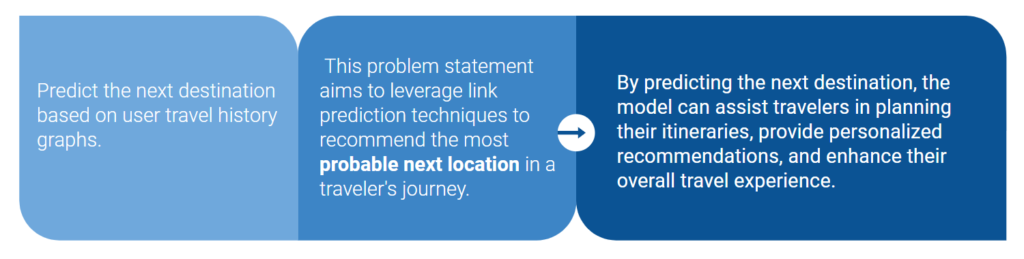
PROBLEM STATEMENT
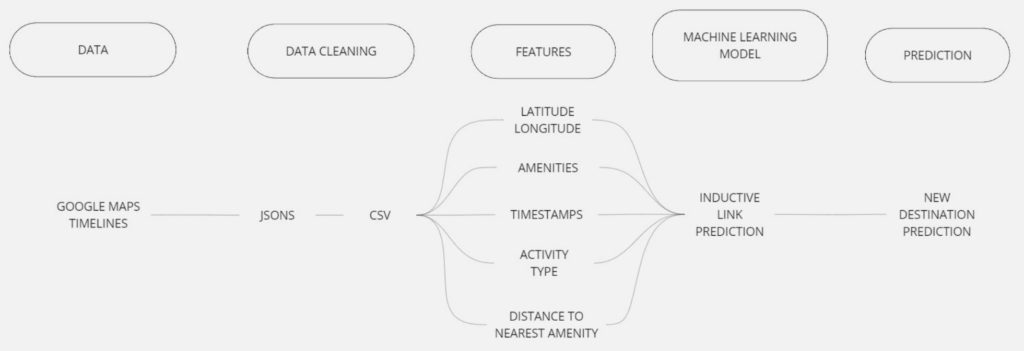
The dataset contains information about previous trips taken by users, where each trip is represented as a node in the graph. The edges between the nodes represent connections between destinations visited by the same user. Additionally, the dataset includes attributes such as location details, amenities, time of day, activity type, and user preferences.
METHODOLOGY
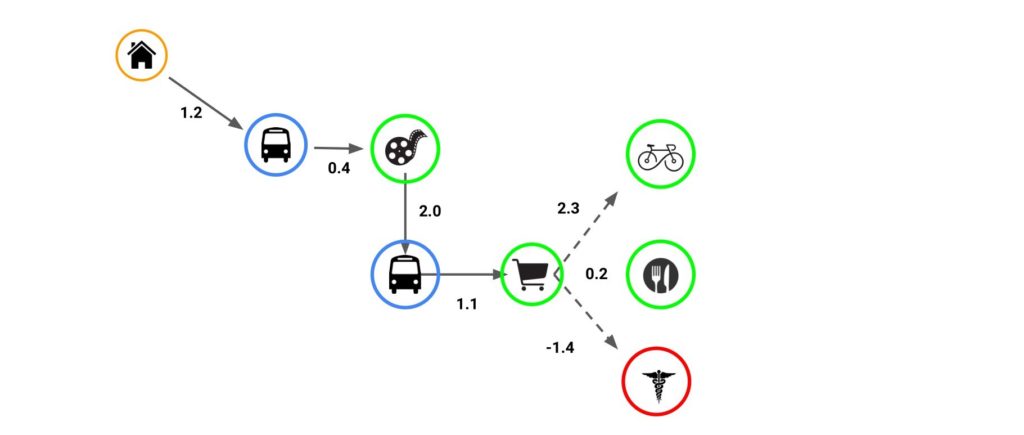
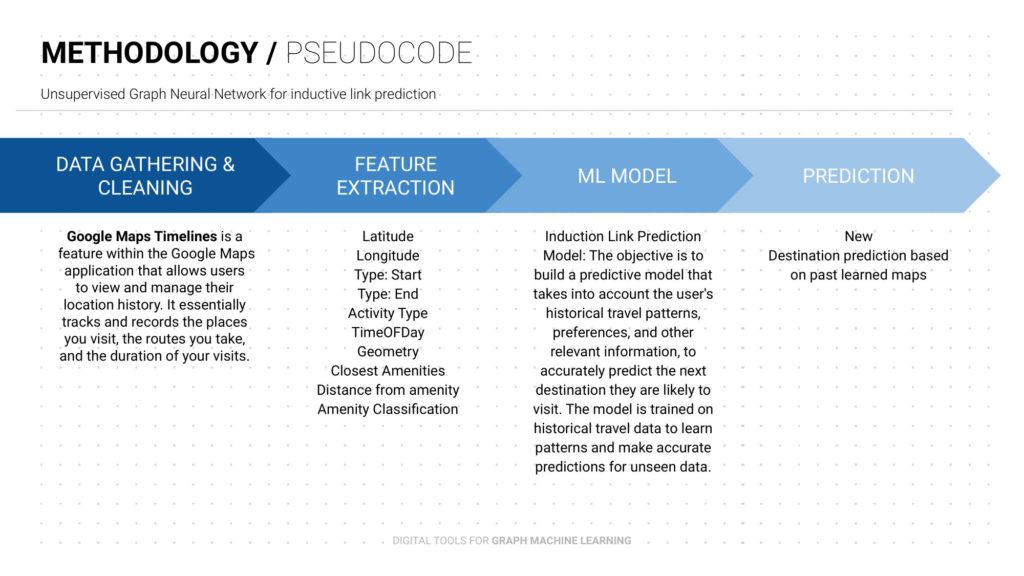
- The ML model will predict the next destination based on the past learned graphs based on the Google timeline.
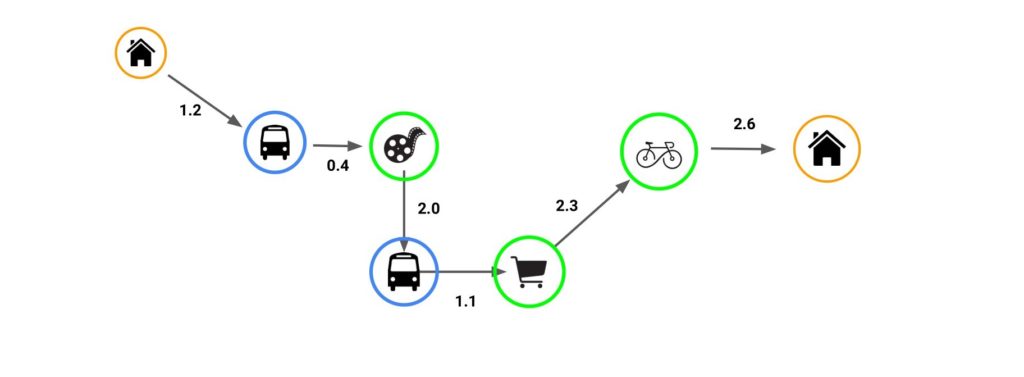
- Each edge has a weight that allows the ML model to predict the next destination.
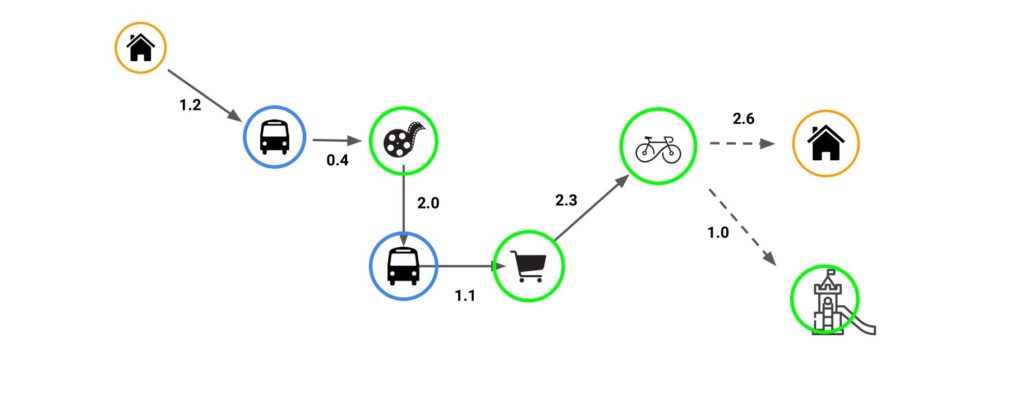
- The graphs keep on growing with respect to its previous prediction.
METHODOLOGY / PSEUDOCODE
FEATURE EXTRACTION

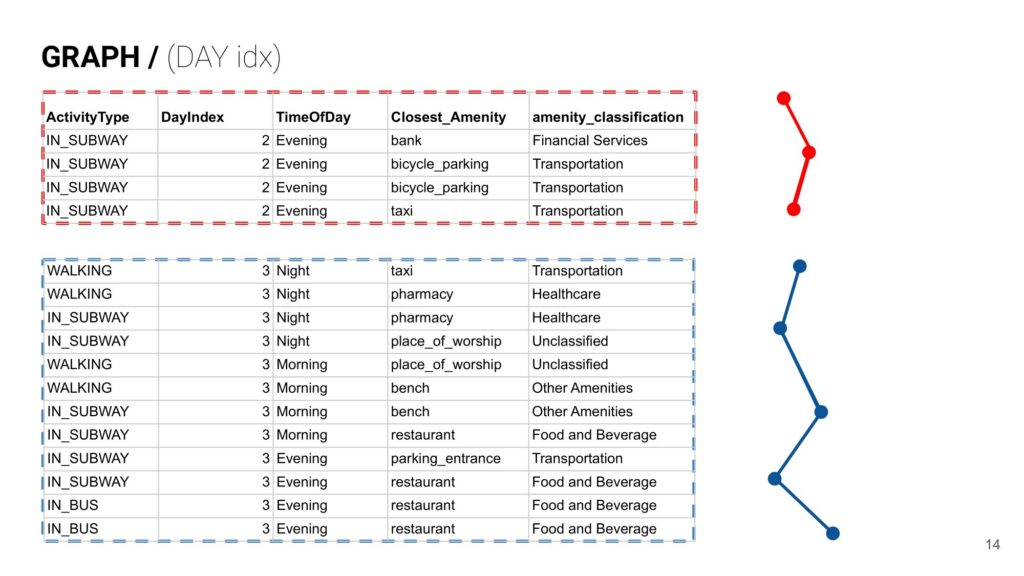
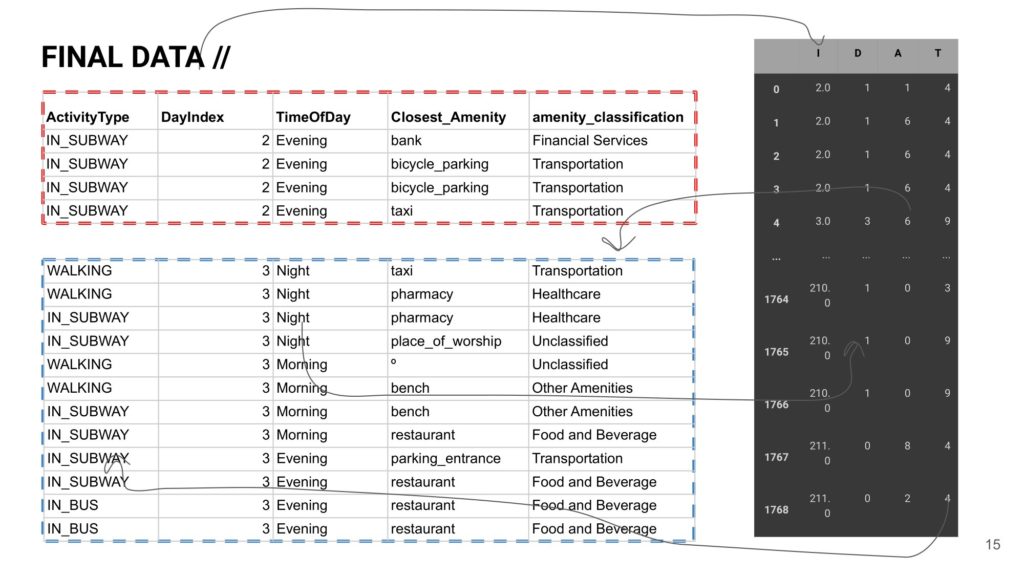
- The features of latitude, longitude & activity type can be extracted from the json file from google timelines.
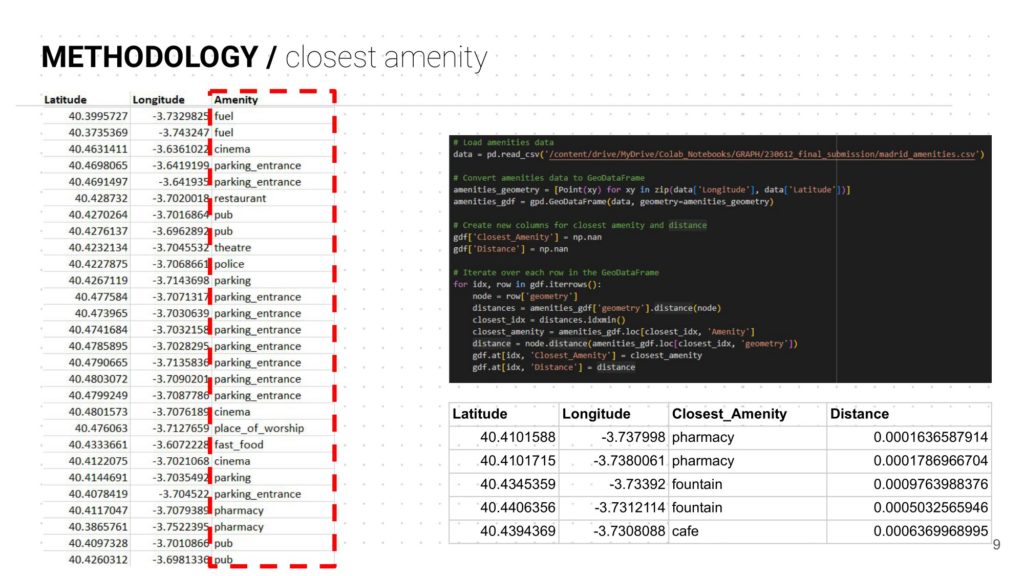
- Closest Amenity: The closest amenity is extracted from OSMNX, which picks the closest amenity from the latitude and the longitude.
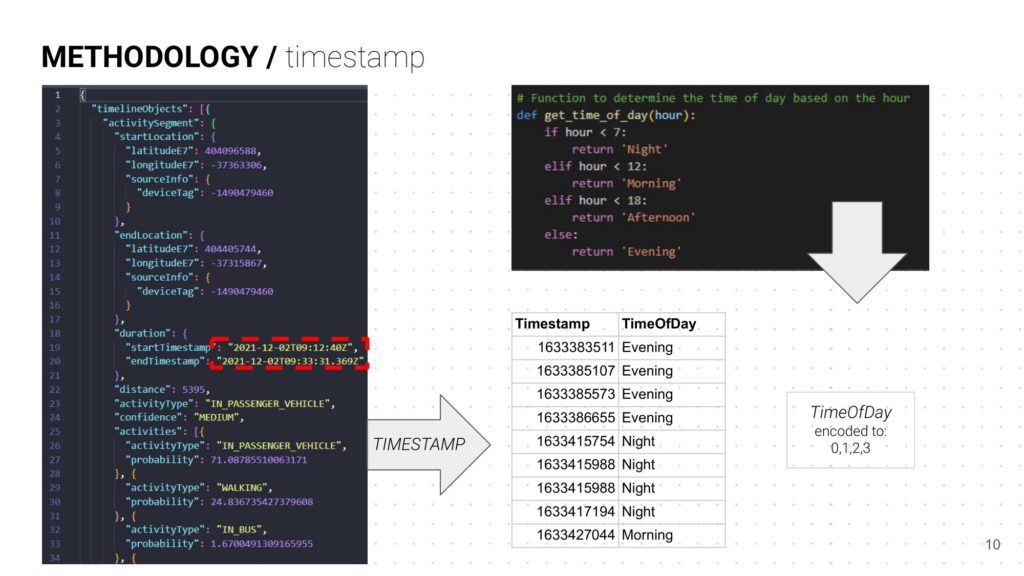
- The TimeOfDay is embedded as numbers to identify morning, afternoon, evening and night.
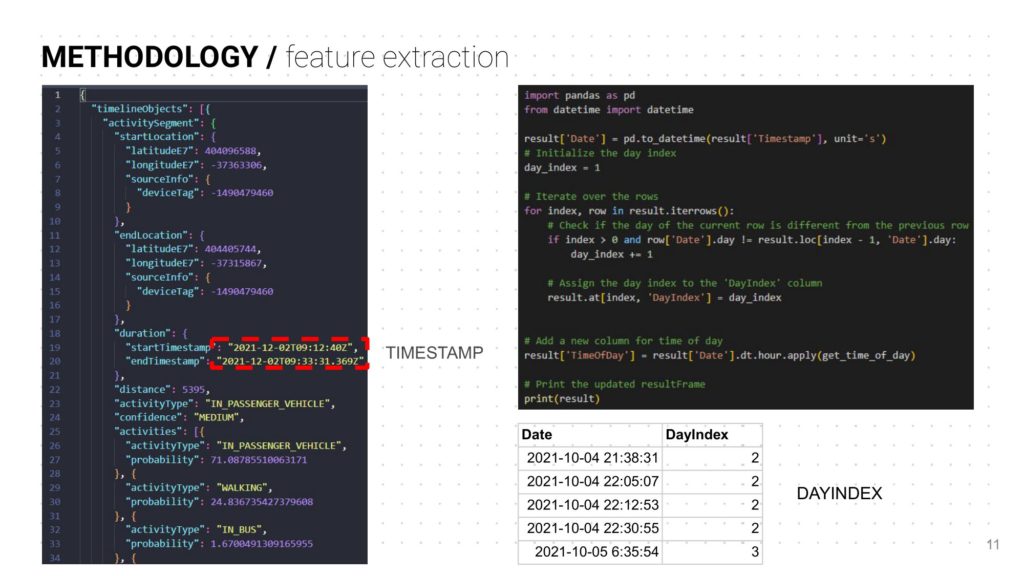
- There were multiple graphs showing travel patterns in one single day so it was important to classify them as DayIndex as in Day 1, 2, 3 and so on.
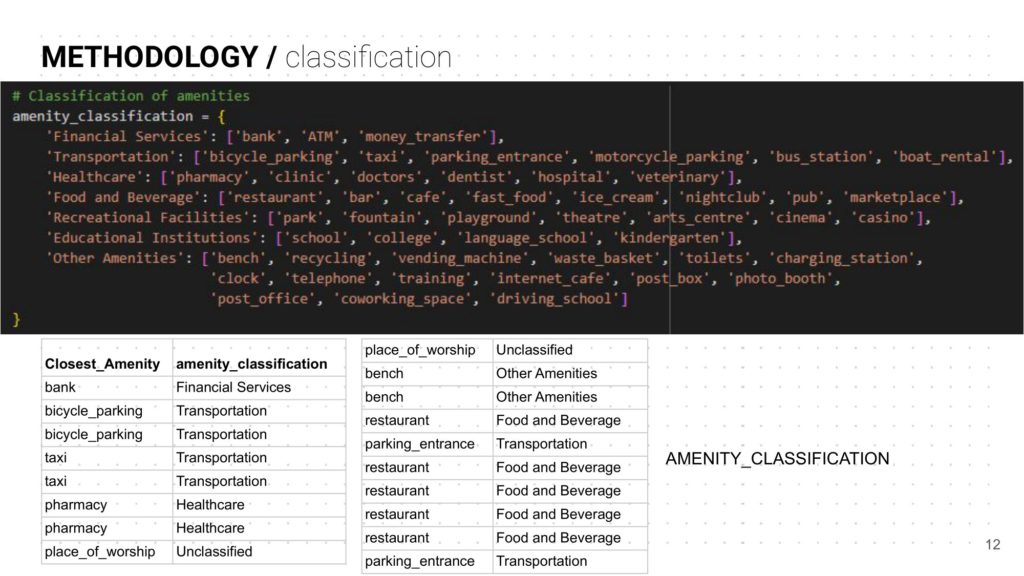
- All the similar amenities were classified under amenity_classification to make the ML model more nimble.
METHOD_01
METHOD_02
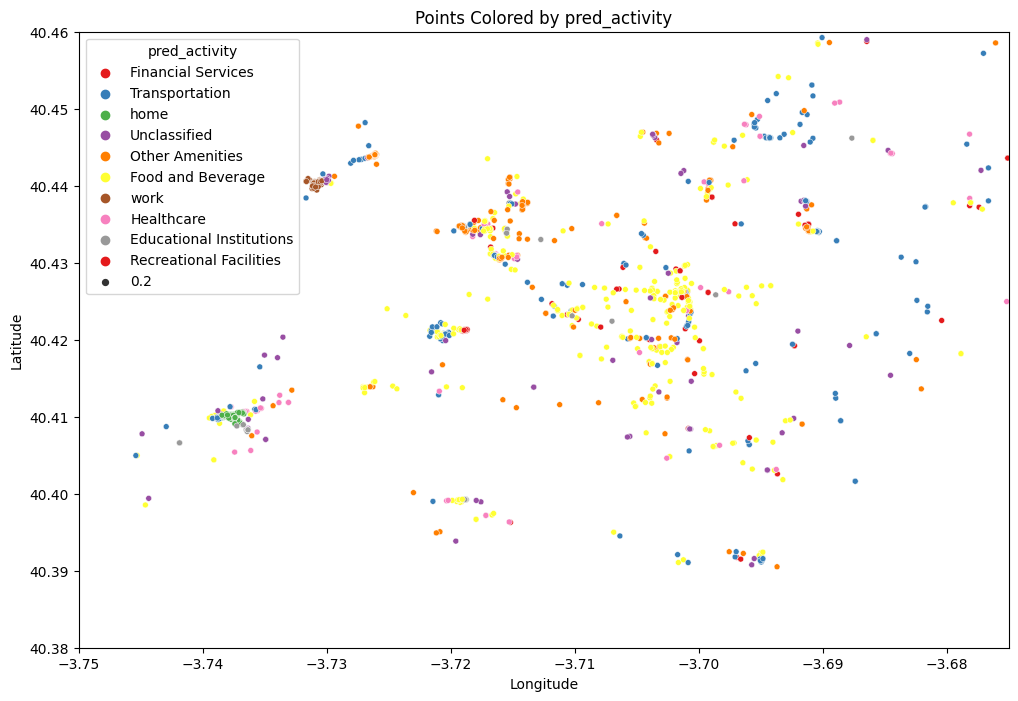
ACTIVITY MAP
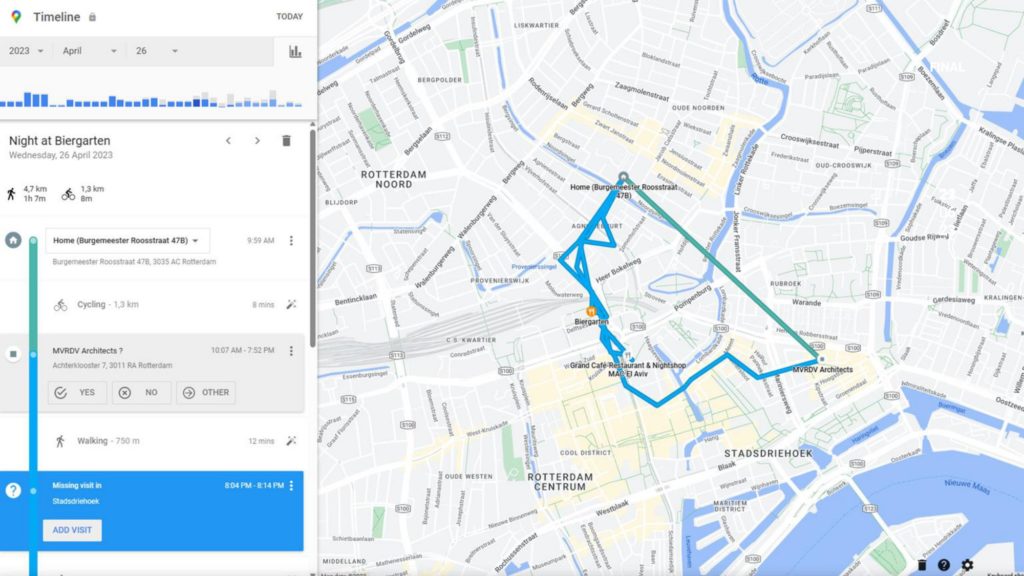
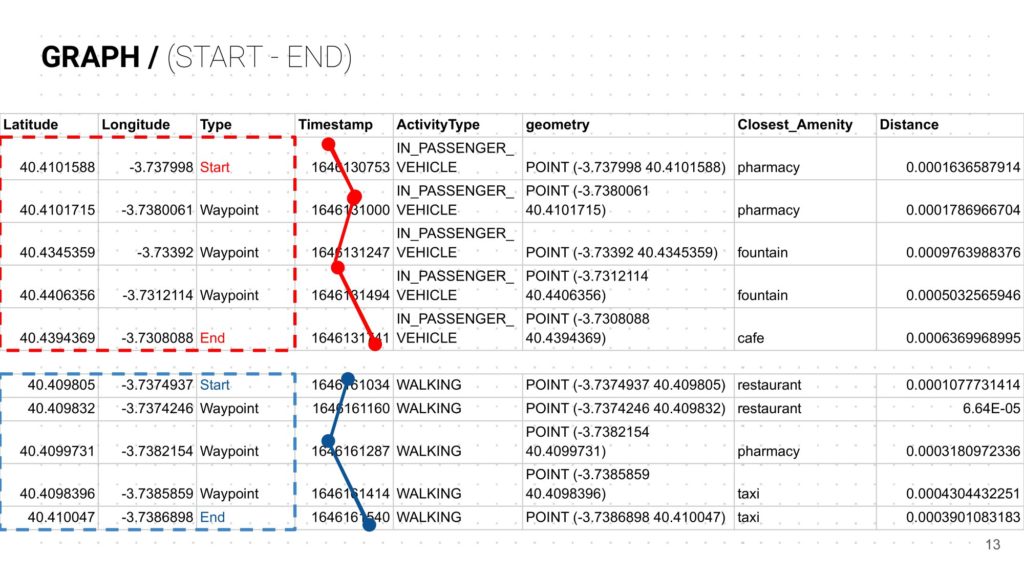
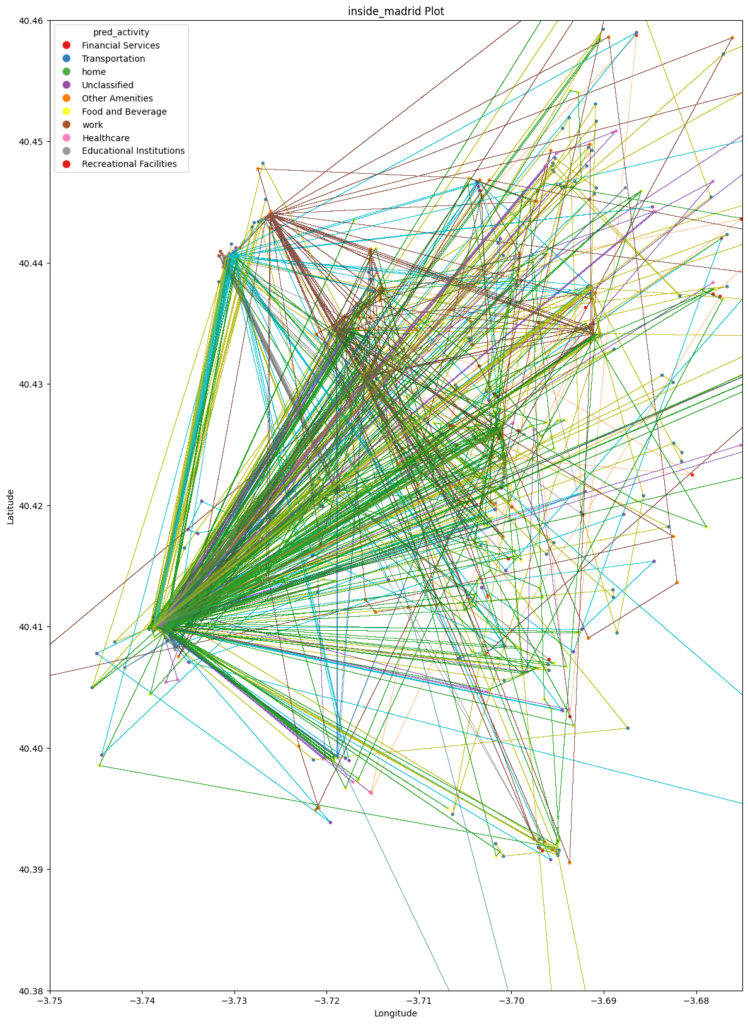
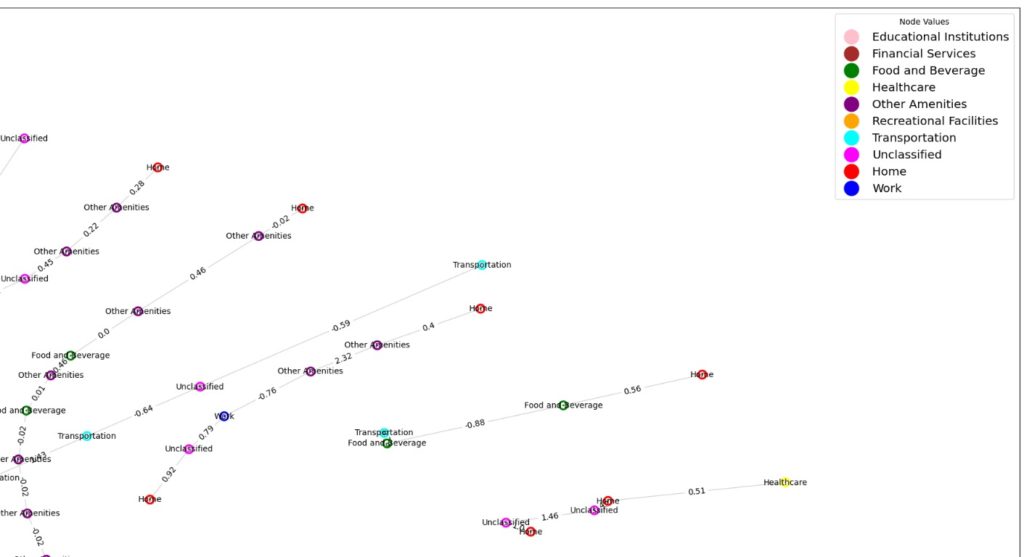
GRAPH MAP – SHOWING PAST TRAVEL PATTERNS
PREDICTION

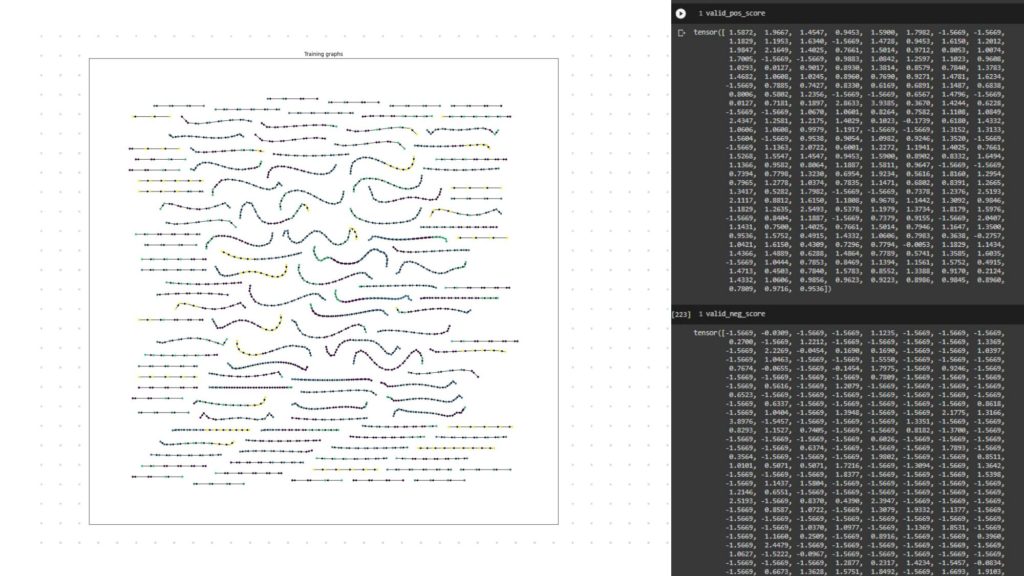
TRAINED GRAPHS – POSITIVE & NEGATIVE


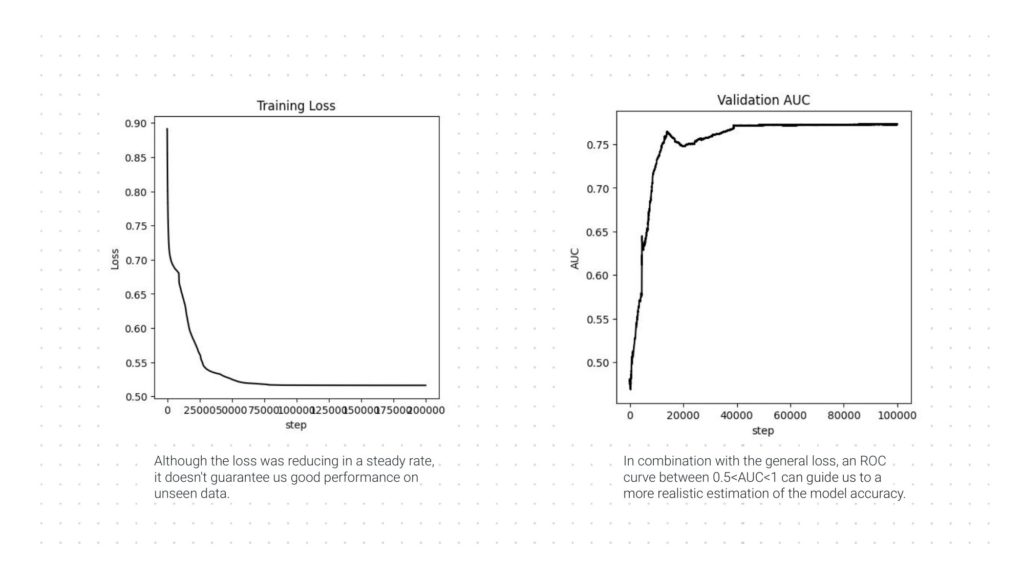
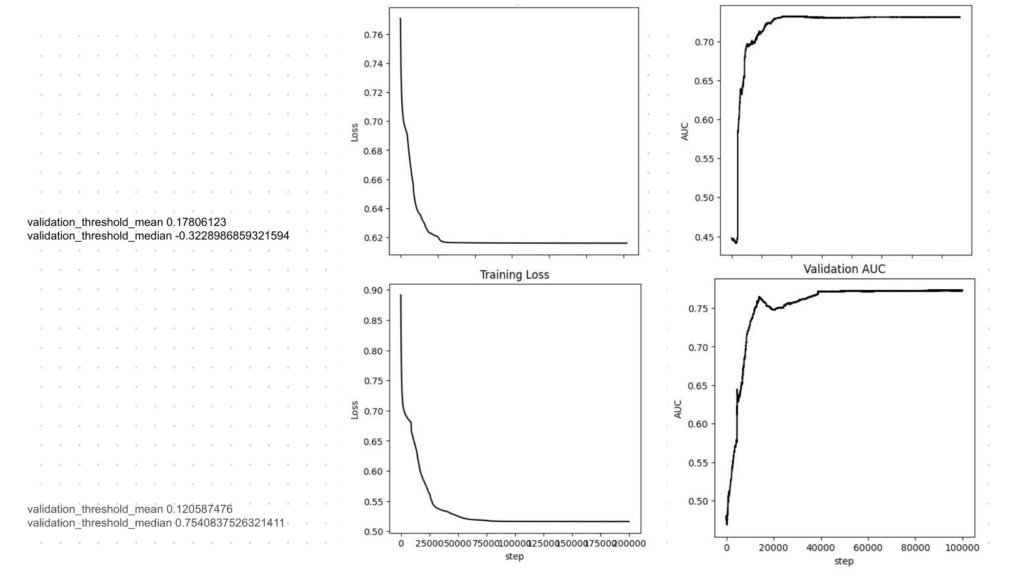
TRAINING LOSS & AUC
TRANING GRAPHS
PREDICTION – POSITIVE GRAPHS
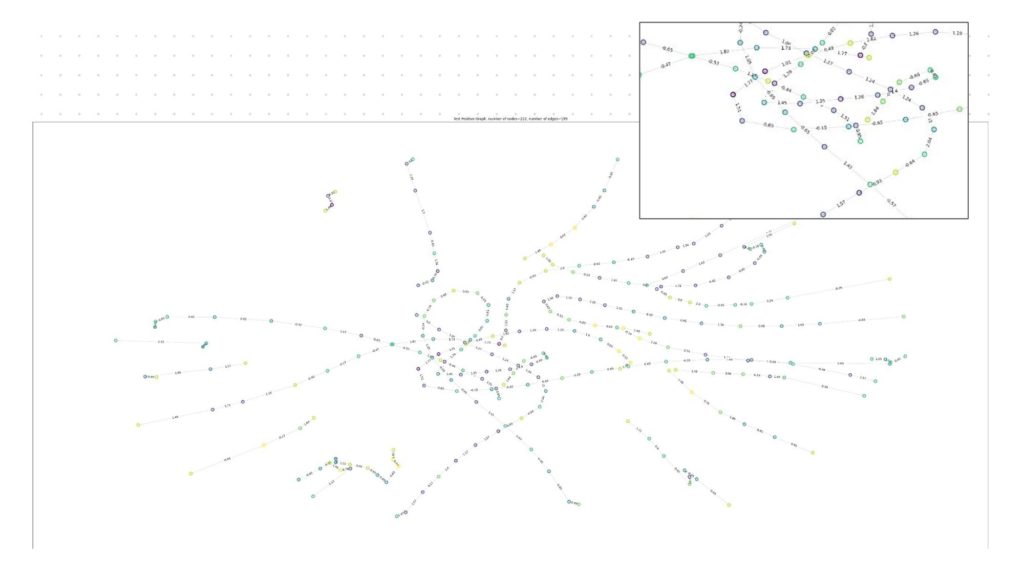
PREDICTION – NEGATIVE GRAPHS
CONCLUSIONS
- After training for over 100000 steps, the predictive linking achieved an AUC of more than 75% accuracy over true positives and false negatives.
- The cleaner and reduced dataset for training, the better prediction of reality was achieved regarding the links of the day journeys.
FUTURE WORK
- Once the data parsing is set up from Google timelines, the personalized dataset can be imputed for multiple graph models relatively easily, allowing for the training of new cities and users.
- Transport classification prediction, clustering of special locations, location classification
