
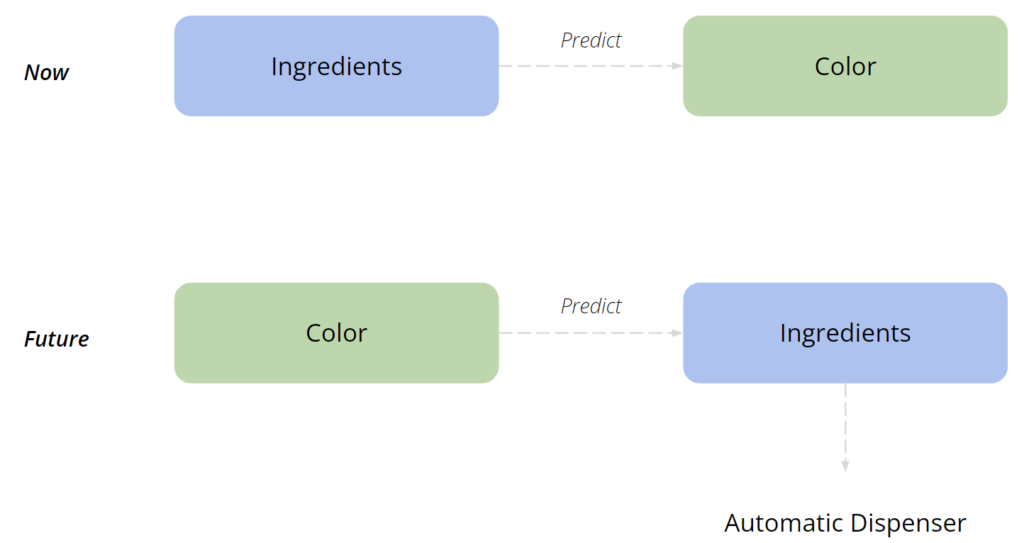
Our aim is to develop a machine learning model that accurately predicts the color outcome of ceramic underglazes based on their ingredient compositions and firing conditions.
In the world of ceramic art, the process of underglazing involves applying colors to pottery which are then sealed under a transparent glaze before firing. However, predicting the final appearance of these colors can be challenging due to the oxidation of underglaze ingredients during the firing process. This oxidation can significantly alter the final color outcome, often leading to unpredictability and inconsistency in results. Our project seeks to address this issue by developing a machine learning model that can predict the color outcomes of underglazes based on their ingredient compositions.
Why are we doing this?
Currently, we are trying to take the ingredients to predict the color, but in our Studio Project, Glazing Virtuoso, we are looking to create a machine where we can input the color we want and it outputs the ingredients. Mixing underglazing is different to mixing paint due to the chemical oxidization, which means we need to have a more informed approach to understanding how we mix different colors, and this is where this project comes in.
Data Preparation
We utilized a Dataset of 29 different Underglazes by Prodesco. We used the Datasheet to find out each of the ingredients that are used to create each color.
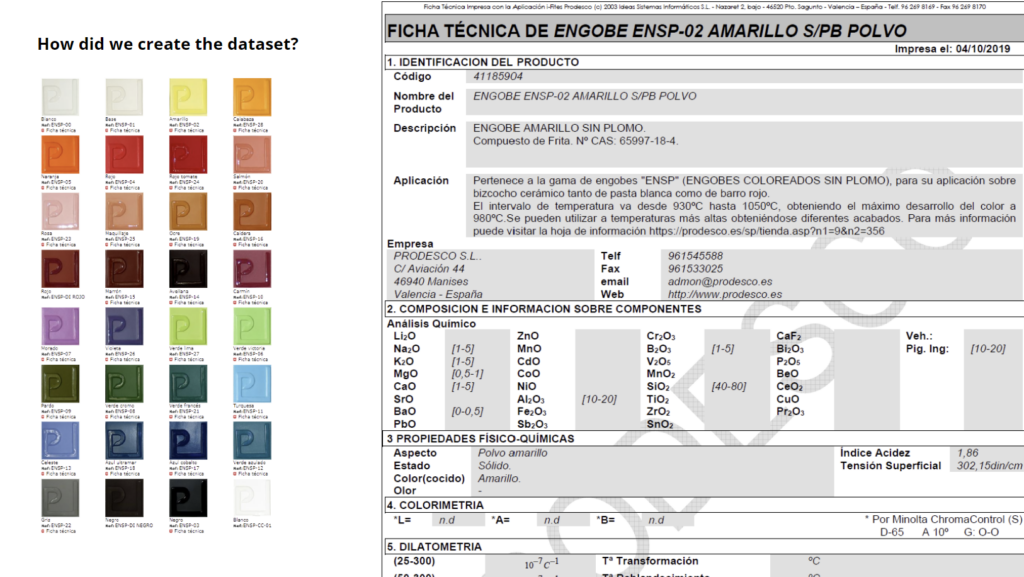
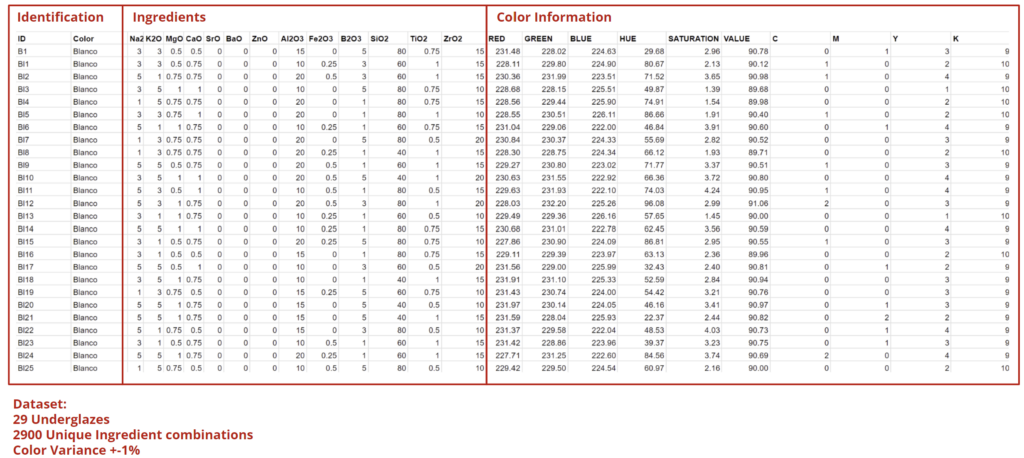
Each of the Data was plotted in a table with Unique ID’s, Color, Ingredients and Color information in RGB, HSV and CMYK. As seen on the Datasheet above the numbers come in ranges. This means we do not know the exact mix to create the color we are referencing. To compensate for this and exend the dataset we decided to create 100 unique combinations within each of the colors. This means we have 100 different compositions to create the same color. To ensure that the color is not exactly the same for each one of them we created a variance of +-1% to the RGB,HSV and CMYK values, creating 100 completely unique colors.
Data Analysis
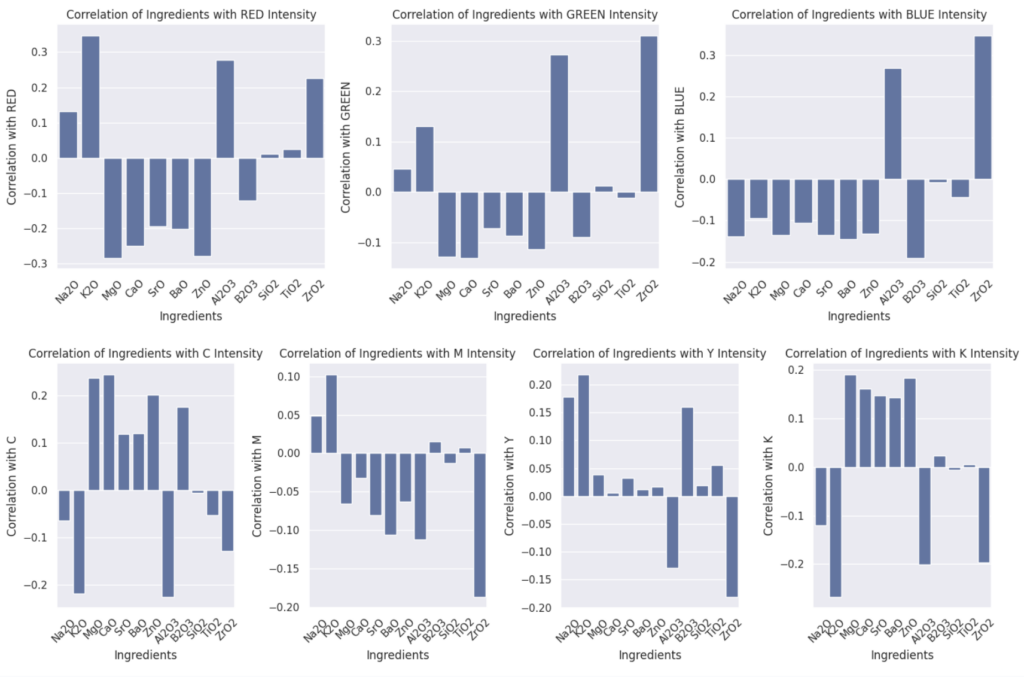
Before going into the ML models, we decided to plot the correlation between different Ingredients and different Color Values. This showed that it will be difficult to predict, but there is certain correlations such as Na2O and K2O, which is correlatd with Reds and but not Blues.
Model Training and Testing
We experimented with various model training techniques and fine-tuned parameters to optimize our output. We played around with RGB and CMYK as outputs in 3D and used the 13 ingredients/elements as inputs. We tested three types of models:
- Linear regression
- Second degree polynomial regression
- Artificial Neural Network (with different layer numbers, loss functions and learning rates)
However, no matter the complexity of our solution, none of them were accurate enough. Interestingly, colors on the blue end of the spectrum gave us the worst results. Maybe it is because our dataset does not have enough blue shades, or maybe blue just has a lower correlationship with the ingredients.
Below are the summarized results of our experiments:
- Linear Regression
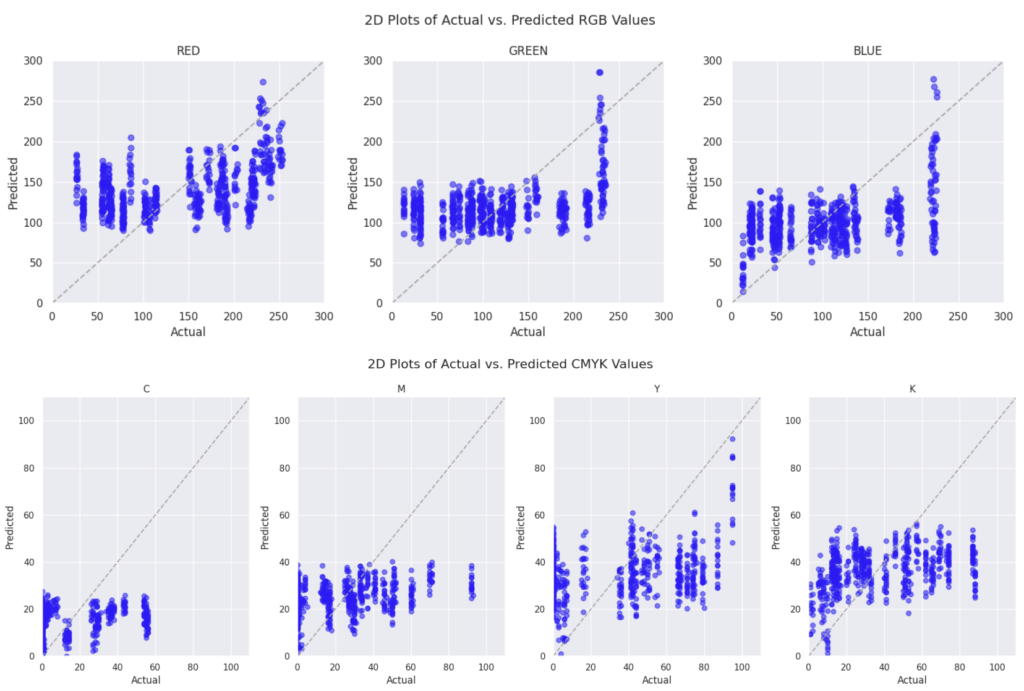
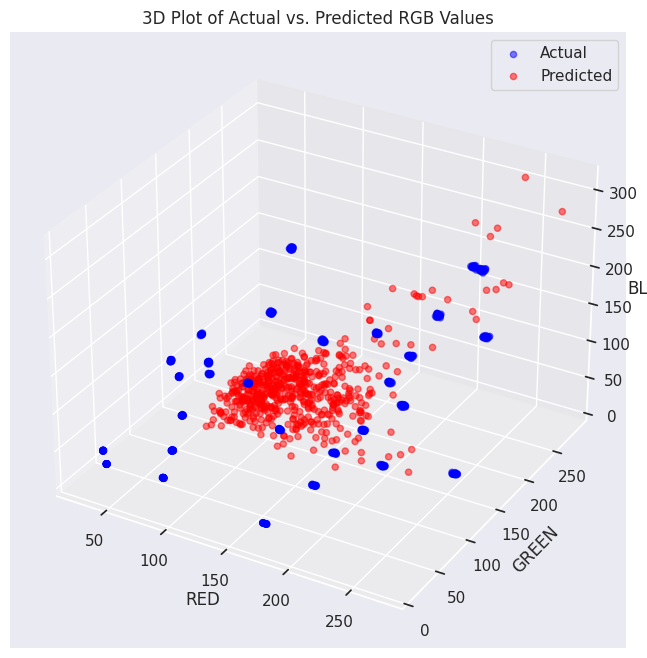

2. Second Degree Polynomial Regression
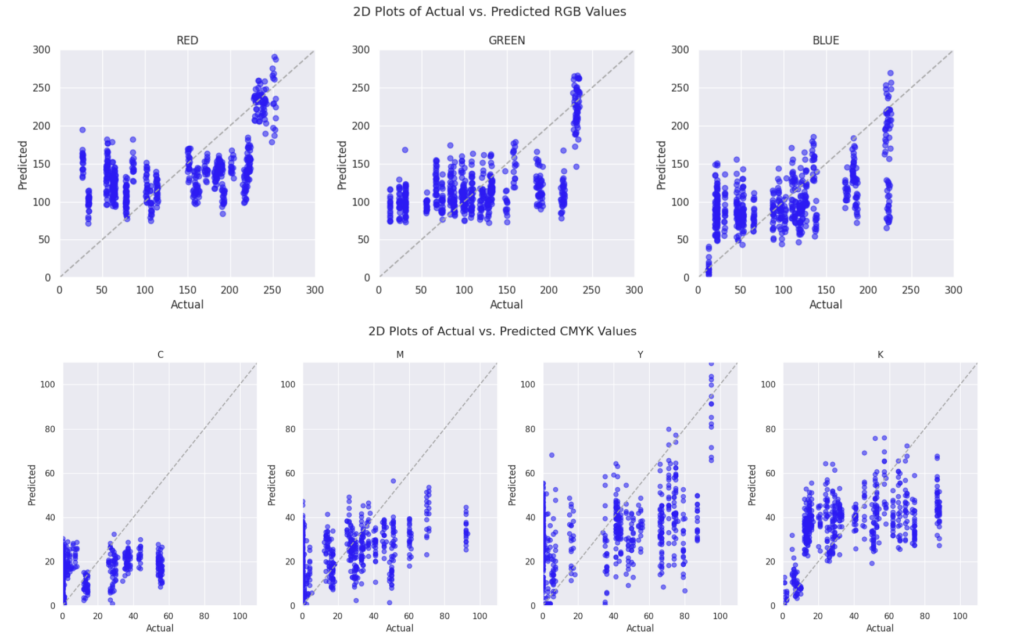
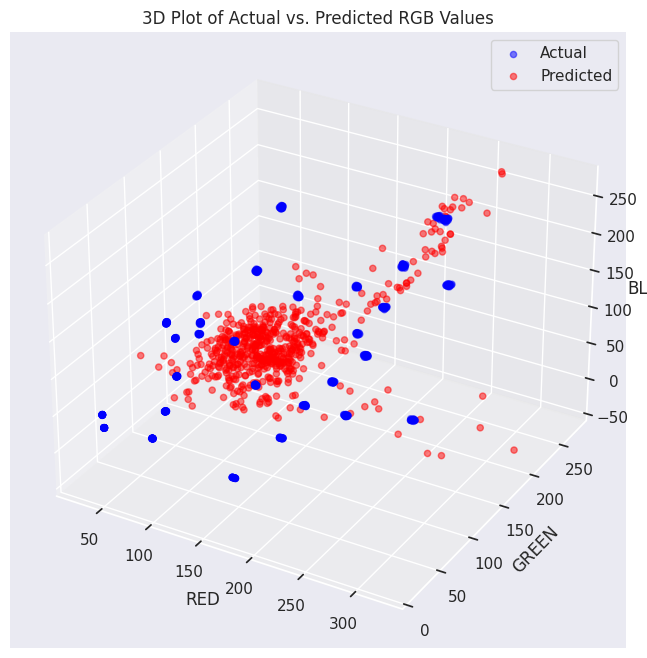

3. Artificial Neural Network (ANN)
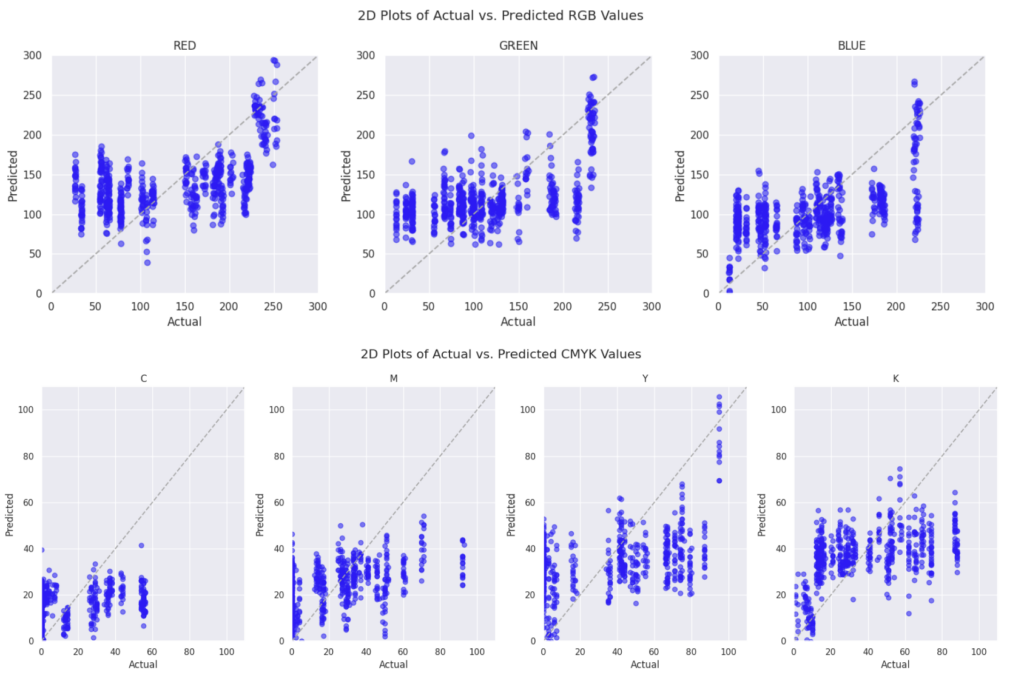
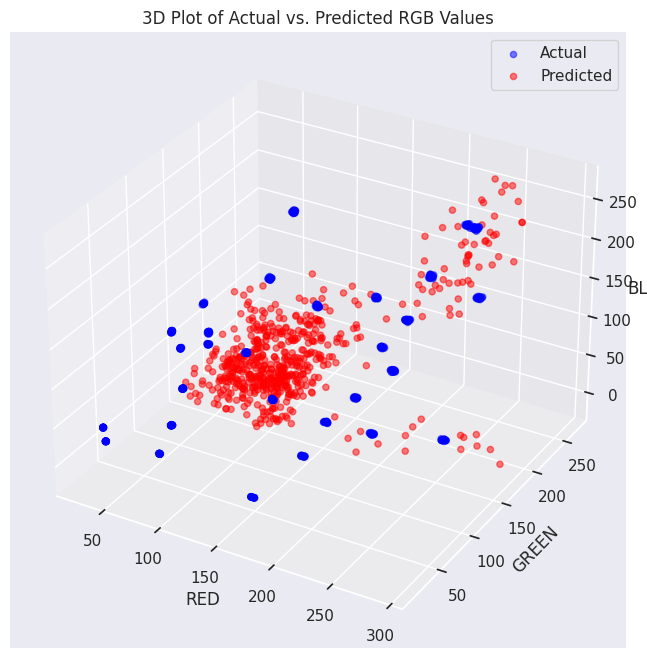

Conclusions and Future improvements
Due to the inaccurate results we have come to a couple of conclusions and aspects we would improve to make the project more accurate:
- Initial Hypothesis: The assumption that chemistry solely determines color was incorrect.
- Issues Identified:
- Underfitting: The model couldn’t capture the relationship between data points.
- The dataset lacked crucial parameters: pigment information?
- The data is approximate rather than precise.
- Modeling Attempts:
- Deepening the neural network (e.g., using five layers) didn’t improve results.
- Next Steps:
- Revisit dataset completeness, including pigment data (and consider factors beyond chemistry that influence color perception).
- Explore alternative modeling approaches.
