
Slim Aarons’s Aesthetic Meets Generative AI
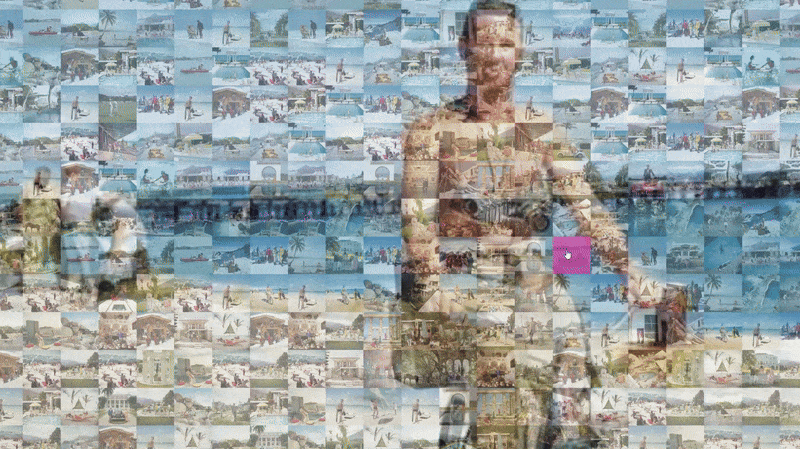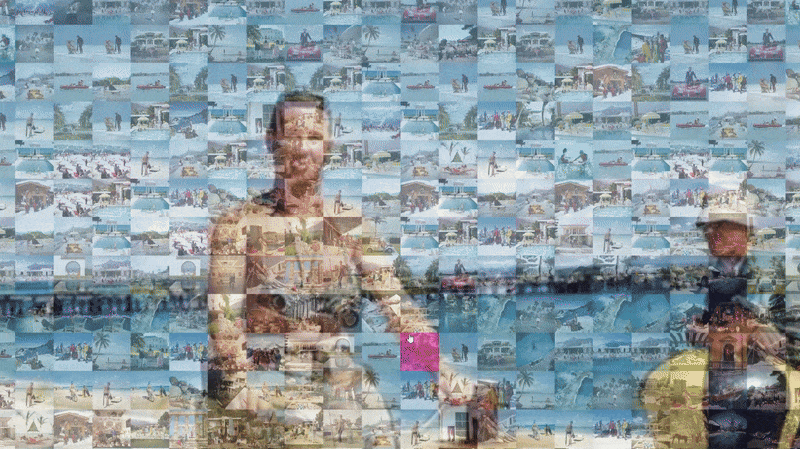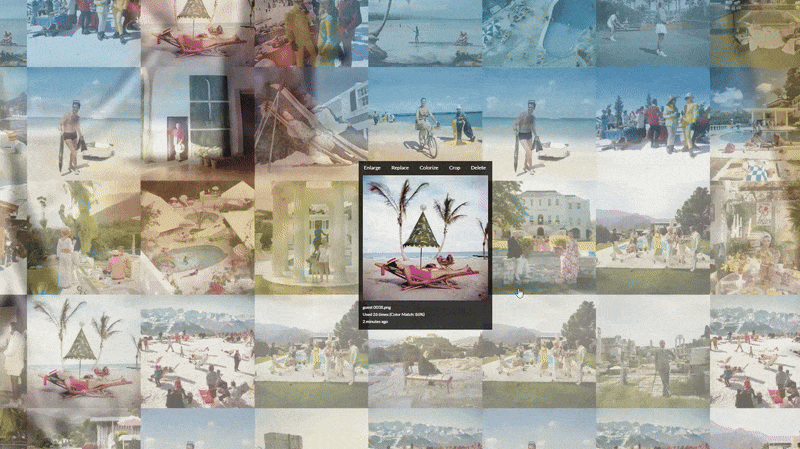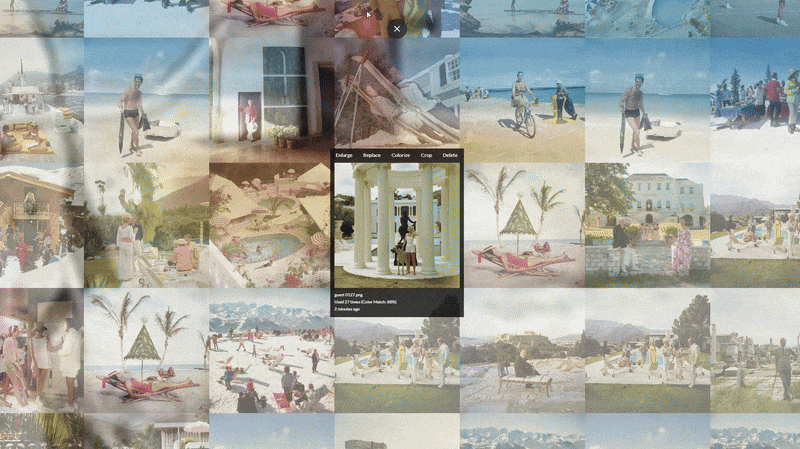
Slim Aarons’ Aesthetic and Legacy
Slim Aarons (1916–2006) built a career photographing the glamour of high society in the postwar 20th century. A combat photographer in World War II turned lifestyle chronicler, Aarons famously vowed to only capture “attractive people doing attractive things in attractive places” after witnessing the horrors of war. His work for magazines like Life, Town & Country, and Holiday portrayed an idyllic world of privilege and leisure, sun soaked pool parties, elegant ski getaways, and garden cocktail soirees – all rendered with a crisp, colorful joie de vivre. The aura of a Slim Aarons photograph is “life as it should be” enjoyed: an escapist vision of beauty, luxury, and relaxation far from any darkness. With their buoyant mood and almost fetishistic attention to detail, Aarons’s sunny portraits of affluence continue to influence today’s tastemakers in fashion, design, and advertising. In essence, his photos are a visual archive of a vanishing world, a mid-century jetset lifestyle frozen on film, equal parts documentary and aspirational fantasy.



It is precisely this iconic and cohesive style that made Slim Aarons’s body of work an ideal muse for a generative AI project. By training an AI on Aarons’s photographs, we aimed to preserve his distinctive aesthetic sensibility and reinterpret it through new, AI generated imagery. The goal was not to replicate his images pixel for pixel, but to capture the codes of his style, the composition, lighting, color palette, and subject matter that make a photo immediately recognizable as “A Slim Aarons.” In doing so, we hoped to expand the legacy of Aarons’s work: imagine new scenes he never shot, animate his still photos into living moments, and even extrapolate them into 3D. The following sections walk through how we turned this vision into reality, from data curation and model training to an interactive app that brings Slim Aarons’s world to life for the digital age.
Gathering a Slim Aarons Image Dataset
Any AI model is only as good as the data that teaches it. We began by collecting and curating 150 high definition images from Slim Aarons’s portfolio, spanning the breadth of his career and subject matter. This dataset included many of his most emblematic scenes, think poolside gatherings in Palm Springs, elegant European beach holidays, snowy mountain lodge parties, and society events in lavish estates. By selecting photos from different decades and settings, we ensured the model would learn the consistent hallmarks of Aarons’s style (bright natural light, rich Kodachrome colors, carefully balanced compositions of people and environments) while being exposed to a diversity of contexts. High resolution was important so that fine details (the “fetishistic” details like fashion, architecture, and foliage that Aarons paid attention to) could be captured in the training. Each image was carefully vetted for quality and scanned or sourced in high resolution to preserve the grain and tonal character of Aarons’s photography, and in some instances their edges had to be regenerated with AI in order to match a 1:1 aspect ratio.

Crucially, we also developed a detailed metadata spreadsheet to accompany these images. For each photograph, we wrote a descriptive text prompt encapsulating the key composition and mood elements. This is essentially a form of prompt engineering for the dataset: by pairing each image with a richly detailed caption, we guide the AI to learn the associations between textual descriptions and visual features. For example, one caption might read: “SLMRNS A Slim Aarons photograph of a 1960s Palm Springs pool party, chic group of friends lounging by a turquoise pool at a modernist villa, mountains in the background, vibrant sunshine.” In this example, we specify the era (“1960s Palm Springs”), the setting (pool party at a modernist villa), the subjects (chic group of friends lounging), and atmospheric details (turquoise pool, mountains, vibrant sunshine). Across the 150 images, these prompts consistently highlight Aarons’s thematic elements, fashionable people, luxury locations, relaxed leisure activities, and vivid settings so the model can learn what makes an image “feel” like Slim Aarons. Notably, we included a special token “SLMRNS A Slim Aarons photograph of” in every caption as a trigger word for the style. This unique identifier (a truncated form of Slim Aarons) was used to associate the concept of Aarons’s photographic style with the images during training. Later, when we want the model to produce an image in Aarons’s style, we simply include the token in the prompt, and the model will be primed to invoke the learned aesthetic. This technique ensures that the model’s knowledge of Slim Aarons’s style is tied to a specific keyword, avoiding interference with other styles or concepts the base model knows.


Training a LoRA Model with FLUX
With our curated dataset in hand, the next step was to train a custom AI model to emulate Slim Aarons’s style. Instead of training a brand new model from scratch (which would require enormous data and compute power), we used a technique called LoRA (Low Rank Adaptation) to fine tune a pre existing state of the art image generator. LoRA is a parameter efficient training method that adds a small set of trainable weights to an existing model rather than modifying all of the model’s parameters. In practical terms, this allowed us to teach the model a new style (Slim Aarons’s aesthetic) by only training a few extra layers (the “low rank adapters”), which is much faster and requires far less data than full model training. During inference, these LoRA layers can be overlaid on the base model while the base model remains unchanged, and the LoRA “injects” the learned style on the fly. This efficiency was key, as it enabled us to do the fine tuning on a single GPU within a feasible timeframe.
Base Model – FLUX.1-dev: For our base generative model, we chose FLUX.1 [dev], a 12 billion parameter transformer based image generation model released by Black Forest Labs in 2024. Flux is one of the top performing text to image models of the moment, known for its excellent image quality and strong prompt adherence (it can understand detailed, natural language prompts very well). After some back and forth testing of several trained LoRA’s , including SDXL models, we opted for Flux.1-dev because it is nearly state of the art and available for research use, providing a powerful foundation on which to imprint Slim Aarons’s style. In essence, Flux brings the general knowledge of how to generate photorealistic images, and our LoRA will bring the specific knowledge of Aarons’s visual style, while balancing both photographic and architectural styles with human generation which we struggled achieving with SDXL models. Using Hugging Face’s Diffusers library, we loaded the black-forest-labs/FLUX.1-dev checkpoint and prepared it for fine tuning.
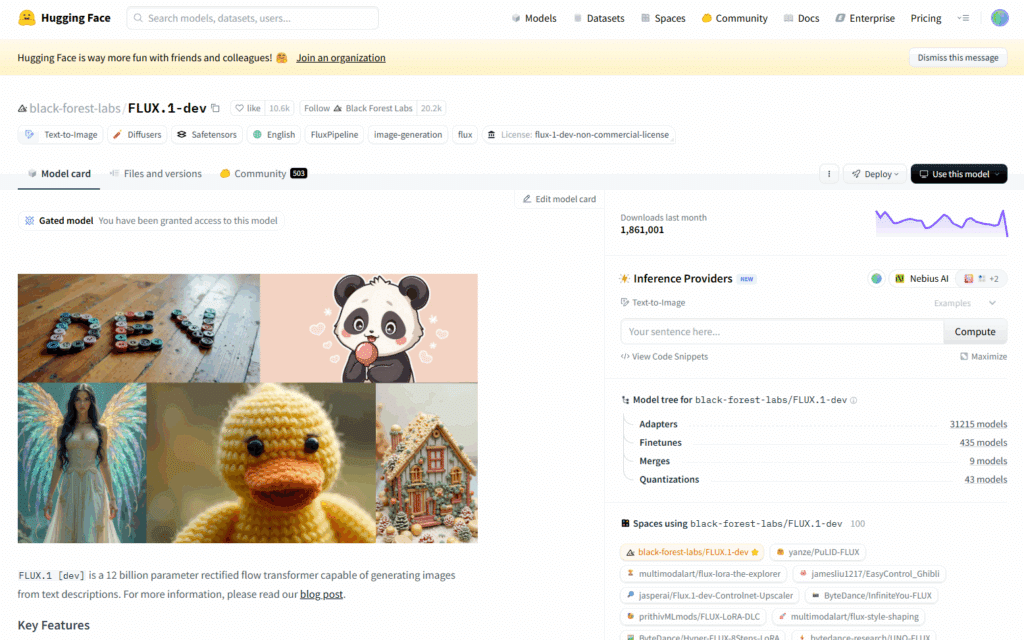
Training Setup: The fine tuning was carried out in a Google Colab Pro environment with an NVIDIA A100 GPU. We utilized Hugging Face’s LoRA training scripts (built on Hugging Face Diffusers and the Accelerate library) which streamline the process of training a LoRA on a diffusion model. After mounting our dataset and metadata, we began training with the following key hyperparameters:
- Resolution: 1024×1024 pixels. We trained at a high resolution to fully capture the detail and composition of Aarons’s images (Flux is designed for up to 1024px generation).
- Batch size: 2 images per step (with gradient accumulation over 4 steps to effectively use a batch of 8 for stability)
- Training steps: 2,000 iterations. We found this sufficient for the model to converge on the style given 150 images, a relatively small but fairly diverse set. (LoRA fine-tunes often converge quickly; 2–3 epochs through the data were enough here.)
- Learning rate: 4e-4 (with AdamW optimizer in 8 bit mode for memory efficiency). This higher than typical rate for diffusion models is feasible because LoRA is only adjusting a small subset of weights, making training more robust to learning rate compared to full model fine tuning. We also employed gradual warmup and no significant LR decay, treating 2000 steps as a fairly short, controlled training run.
- LoRA rank: 8 (with an alpha of 16). This means the LoRA inserted rank-8 update matrices into the model’s attention layers, which is a common setting balancing expressiveness and size. Rank 8 was expected to capture the nuances of a style reasonably well; Slim Aarons’s style, while distinctive, is consistent enough that a relatively low rank can encapsulate it.
- Trainable components: Both the UNet (image generator) and the text encoder were set to train. Training the text encoder (CLIP embeddings) for a style LoRA helps the model better associate our textual prompts (which often include scene descriptions and the trigger token) with the visual style. We set
content_loss_style_lossto “balanced” mode, ensuring the fine tuning didn’t overly distort content or style at the expense of the other. - Noise scheduler: We used Flux’s native flow matching scheduler, which is specific to the Flux model architecture (a hybrid of diffusion and flow based generation). This scheduler aligns with Flux’s training, helping achieve faster convergence.
- Other settings: We enabled gradient checkpointing to reduce memory usage, used bfloat16 precision for training to save VRAM, and applied a 10% text caption dropout (meaning sometimes the model sees the image without its caption) to improve robustness. We also saved checkpoints periodically and generated sample images every 250 steps to monitor training progress.
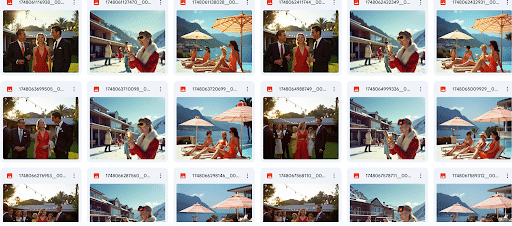

Throughout training, we observed the model’s sample outputs gradually learn the look of Slim Aarons. Early on, generations had the right general subjects (people at pools, etc.) but with inconsistent details or colors. By around 1500 steps, however, the outputs showed notable fidelity: women in vintage fashion lounging by vivid blue pools, well composed groups in glamorous settings, all bathed in natural golden light, essentially hallucinations of scenes that felt uncannily like Aarons’s unpublished work. The final LoRA (after 2000 steps) was saved as a small ~200MB safetensors file. When applied to the Flux model, it effectively transforms Flux into a “Slim Aarons generator.”
Comfy UI Deployment
To fully explore and validate the creative potential of our trained Slim Aarons LoRA, we turned to ComfyUI, a powerful node based interface for generative diffusion workflows. Unlike traditional linear pipelines, ComfyUI allows modular experimentation with model inputs, conditioning methods, and visual outputs which was perfect for a nuanced project like ours, where style fidelity and image control are critical. Using ComfyUI, and with the help of our faculty we constructed a variety of custom workflows to test the model’s behavior under different scenarios: text to image, image to image, and controlnet based methods such as Canny edge detection and Depth mapping.
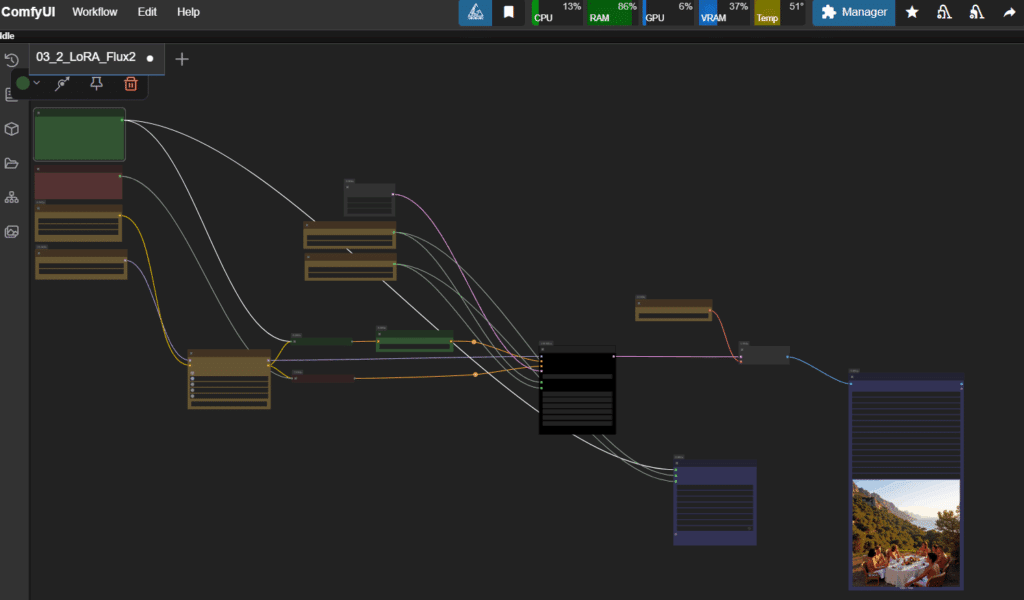
The text to image pipeline served as our baseline, leveraging the “SLMRNS” trigger token and our curated prompts to synthesize brand new scenes from scratch. For more directed creativity, we deployed the image to image workflow, where a source photograph is used as a starting point and gently transformed into a Slim Aarons aesthetic using a controlled denoising process. This allowed us to restyle contemporary or AI generated images with vintage textures and compositions. We also tested Canny and Depth conditioning through ControlNet nodes.










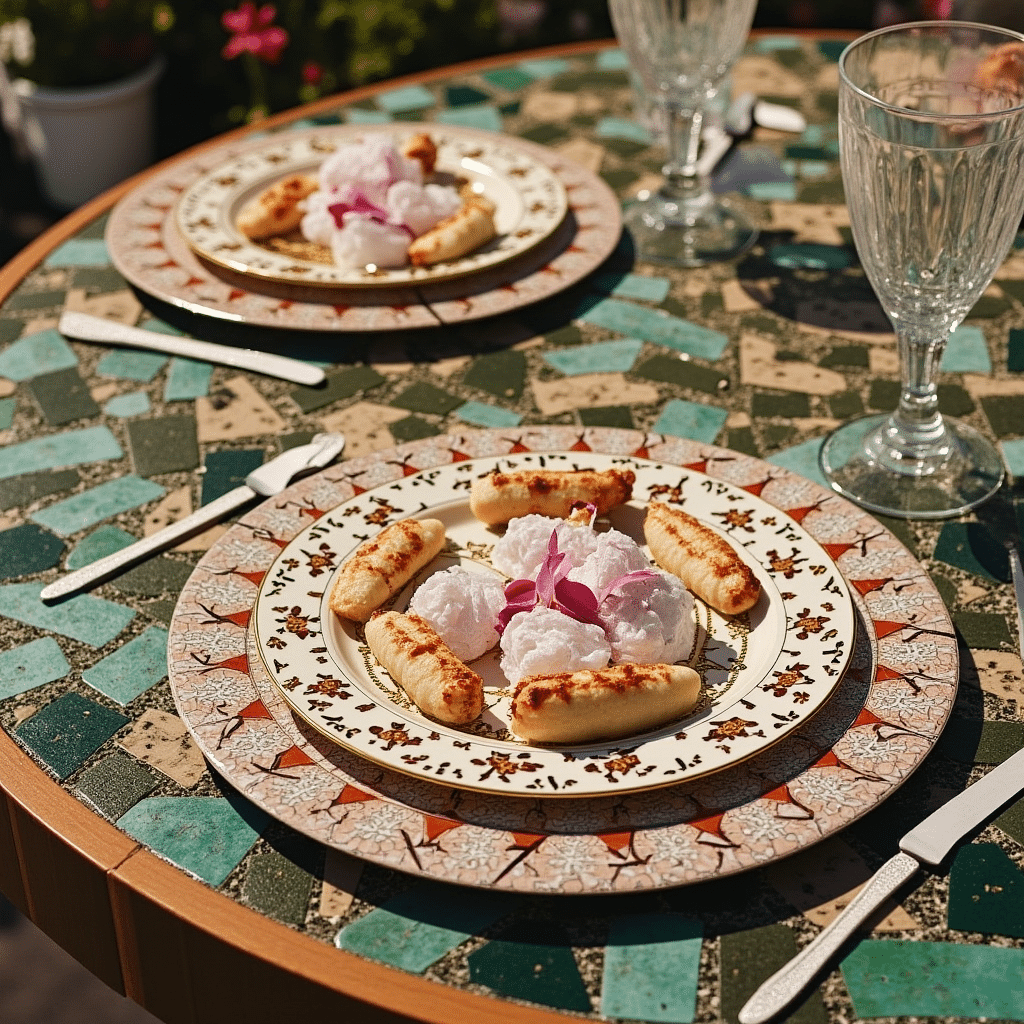

These workflows gave us robust creative control while preserving the visual hallmarks of Slim Aarons’s photography, allowing us to guide the AI’s interpretation with precision. The screenshot above illustrates one such ComfyUI nodegraph, combining text prompts, LoRA embedding, depth map input, and final decoding, producing results that honor both the form and feeling of Aarons’s world, as we can see in the gallery below with some extracted samples from ComfyUI.
The Canny workflow extracts edge outlines from an image, which act as hard constraints to preserve structure and we found it to be particularly effective for architectural or object heavy scenes. In contrast, the Depth workflow generates a depth map from a source image, helping the model maintain spatial coherence and lighting relationships, which Aarons often masterfully composed.




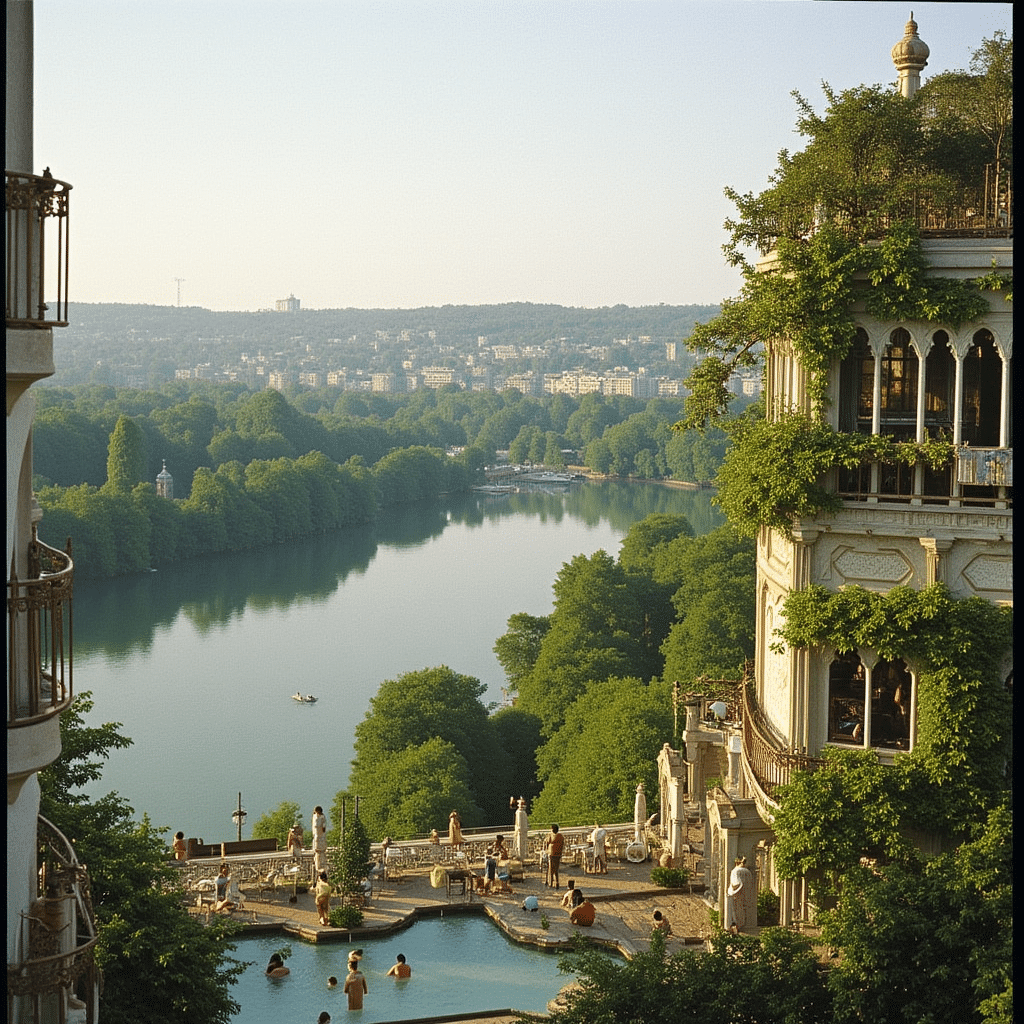







Building a Gradio Interface for the Slim Aarons Generator App
After achieving a working LoRA model, we sought to make it interactive and user friendly by building a web application. We developed a Gradio based interface that allows anyone to explore the model’s creative capabilities, not only generating still images, but also editing them, animating them, and even converting them into 3D. Our guiding idea was to create a “Slim Aarons Generative Studio” where one can input a simple prompt or photo and get an output that looks as if Slim himself had produced it, with options to further enhance or play with the result.
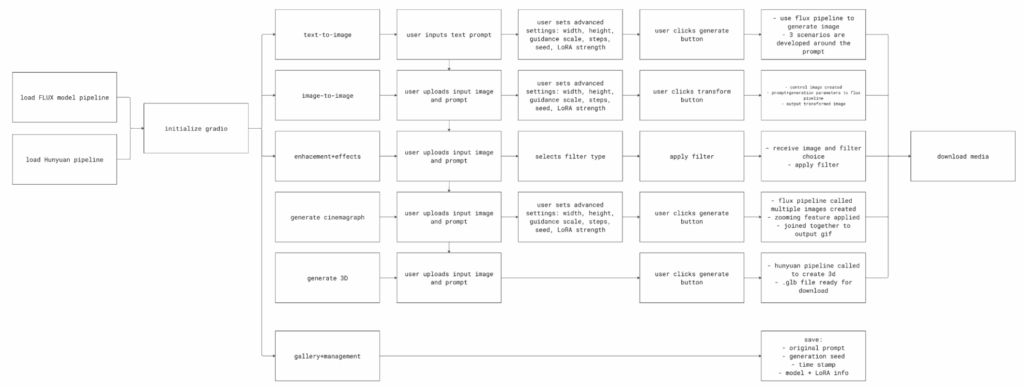
The Gradio app is essentially a front end wrapper around our trained model with multiple modes of operation. All modes leverage the same underlying LoRA enhanced Flux model (with the SLMRNS trigger token ensuring Slim Aarons’s style is infused in every result), but they offer different types of transformations. The interface was organized into tabs for each functionality, with custom controls (sliders, buttons, image upload fields) for user input. Below we describe each feature of the app and how it works:
Text 2 Image Generation
This is the core functionality, generating a brand new image from a text prompt, in Slim Aarons’s style. The user enters a description of a scene, and the app produces a high res image (1024×1024) that visualizes that description as Slim Aarons might have captured it. Under the hood, the prompt is automatically prepended with the trigger phrase “SLMRNS a Slim Aarons photograph of” to invoke the style. For example, if the user types “a sunny luncheon party on a yacht”, the actual model prompt becomes “SLMRNS A Slim Aarons photograph of a sunny luncheon party on a yacht”. The output would likely feature well dressed guests dining on the deck of a luxurious boat, bathed in bright sunshine, very much in line with Aarons’s jet set themes.
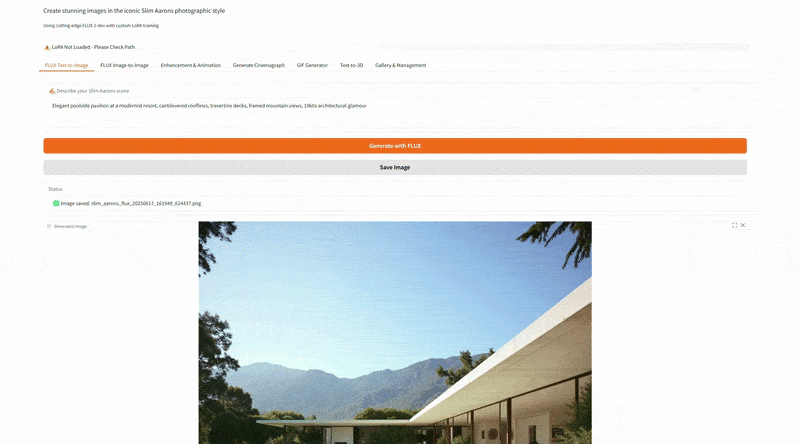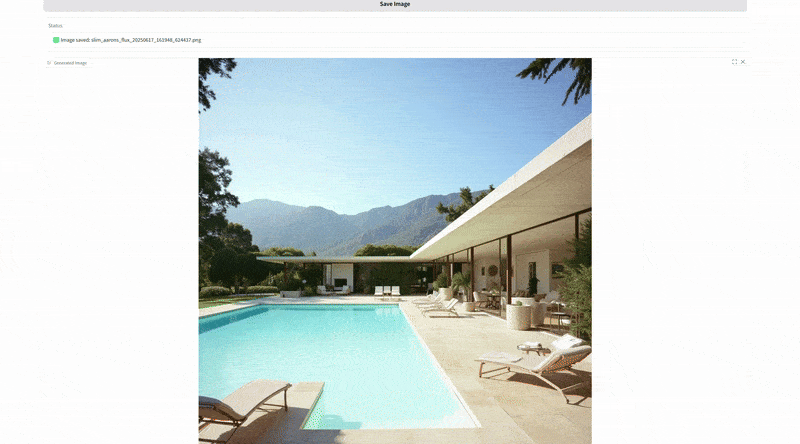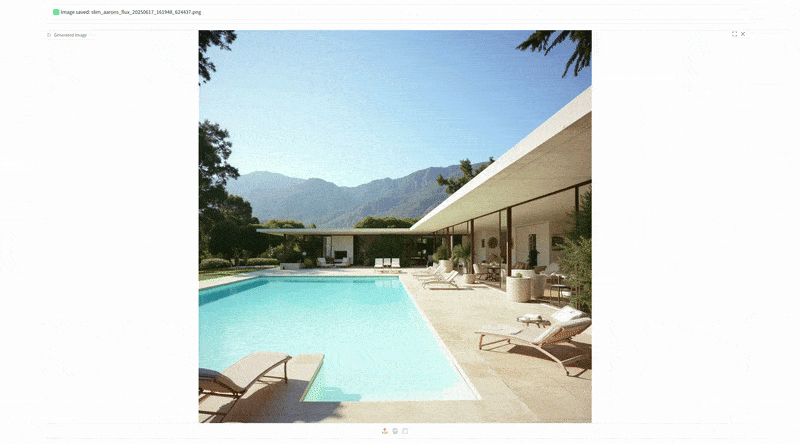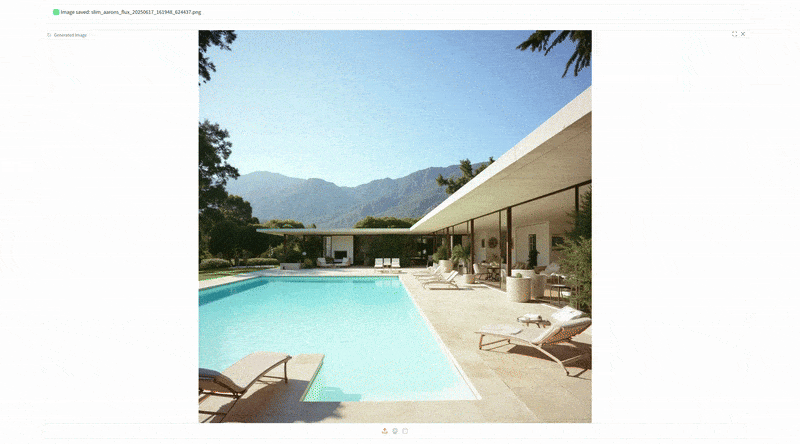
The interface provides sliders for guidance scale (how strongly the model follows the prompt versus creativity) and number of inference steps (controlling quality vs. speed), as well as a random seed for variability. We also expose a “LoRA strength” slider which lets the user dial the Slim Aarons style influence up or down.

At full strength (1.0) the outputs are unmistakably in Aarons’s aesthetic; at lower values, one could blend in more of the base model’s own style for comparison. This feature essentially lets users create new “vintage” images on demand. Side by side comparisons of an original Slim Aarons photograph and a AI generated counterpart can be striking, often showing that the AI has learned to mimic the color palette and composition cues extremely well.
Image 2 Image Transformation
Sometimes a user might want to take an existing photograph and give it the Slim Aarons treatment. The image to image feature allows exactly this. The user can upload a source image and provide a prompt describing how they’d like it to appear. The app will then use image to image diffusion to transform the input while preserving its basic content. In technical terms, we use Flux’s image to image pipeline with our LoRA, injecting noise into the original image and denoising it back guided by the prompt/style.

A “transformation strength” slider controls how much of the original image is preserved, at low strength the output stays very close to the original (just recolored and restyled), at high strength the output may deviate more creatively from the source. This is a powerful tool for style transfer, since essentially the app goes beyond simply redressing and re lightening the photo, since even without explicitly doing so, it would find the underlying conditions of what makes an element belong to a Slim Aarons world aesthetically and apply it to the image. Of course, we found that using prompts that reinforce the setting (e.g. “1960s Palm Springs” or “a luxury estate in Europe, 1975”) in combination with the image leads to stunning results that mix the original content with Aarons’s visual signature, but still we found the power of this tool to be the ability to allow users experiment with different prompt tweaks while keeping the same uploaded photo, to see various stylized outcomes and all their endless possibilities.
Image Editing & Enhancement
In addition to broad transformations the the stylistic filters and enhancers shown below, our interface could eventually support more granular image editing operations. Leveraging the generative model’s capabilities, users might be able to make targeted edits to an image, for example, removing unwanted objects or changing a background while the model fills in the edit in Slim Aarons’s style. This could be implemented via an inpainting approach: the user provides an image and a mask (or selects an “edit region”), along with a prompt for what should replace the removed content. The model then generates the new content consistent with the prompt and the surrounding context.

Cinemagraphs & GIF Creation
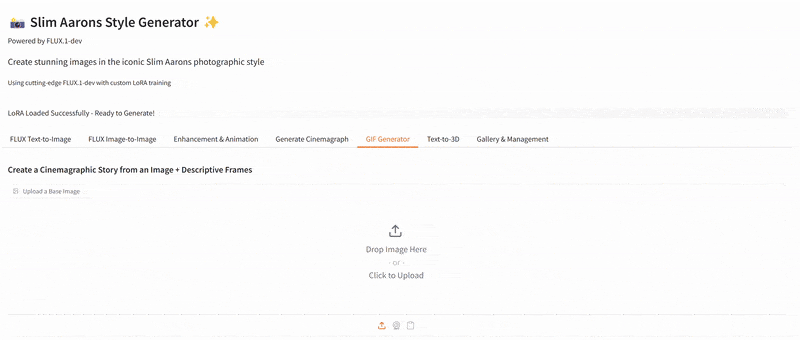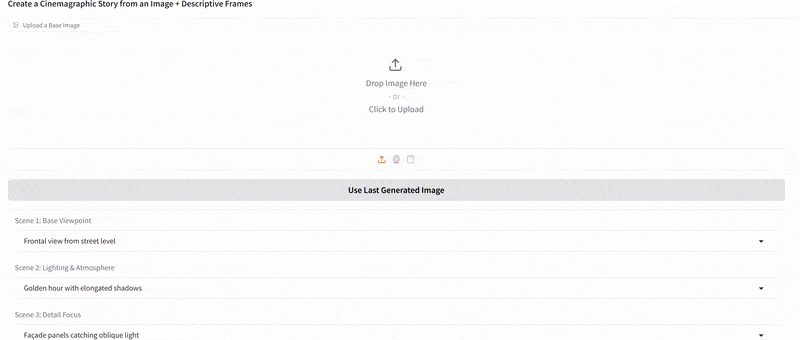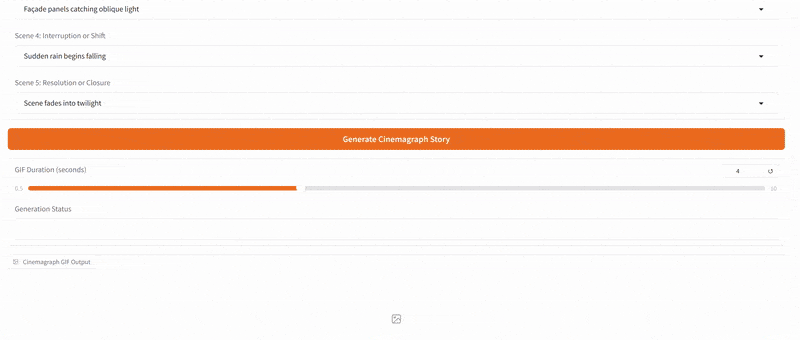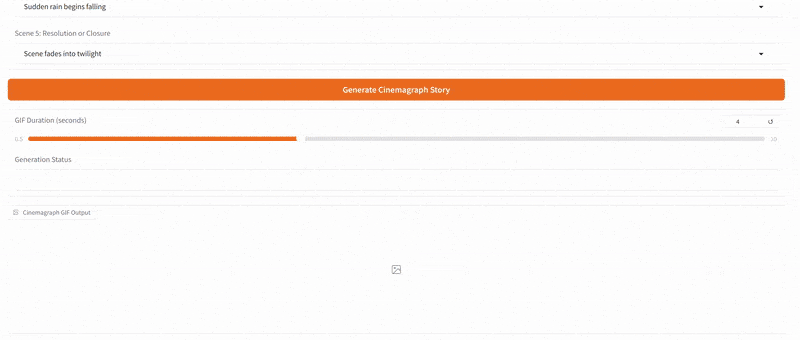
One of the more creative extensions we explored was bringing motion to Slim Aarons’s still imagery. Using our app, a user can create a cinemagraph (a hybrid between a photo and a video), where subtle motion is added to an otherwise static scene. We implemented a simple “pan and zoom” animator that takes a generated image (or an uploaded one) and produces a gentle Ken Burns style animation, outputting a looping GIF. For example, a photograph of a poolside scene can be animated with a slow zoom in and a slight pan from left to right, as if the camera were alive in the scene. This small movement, when looped, gives the image a dynamic quality while preserving its photographic essence, the water might glimmer or the camera motion reveals different details, engaging the viewer longer.
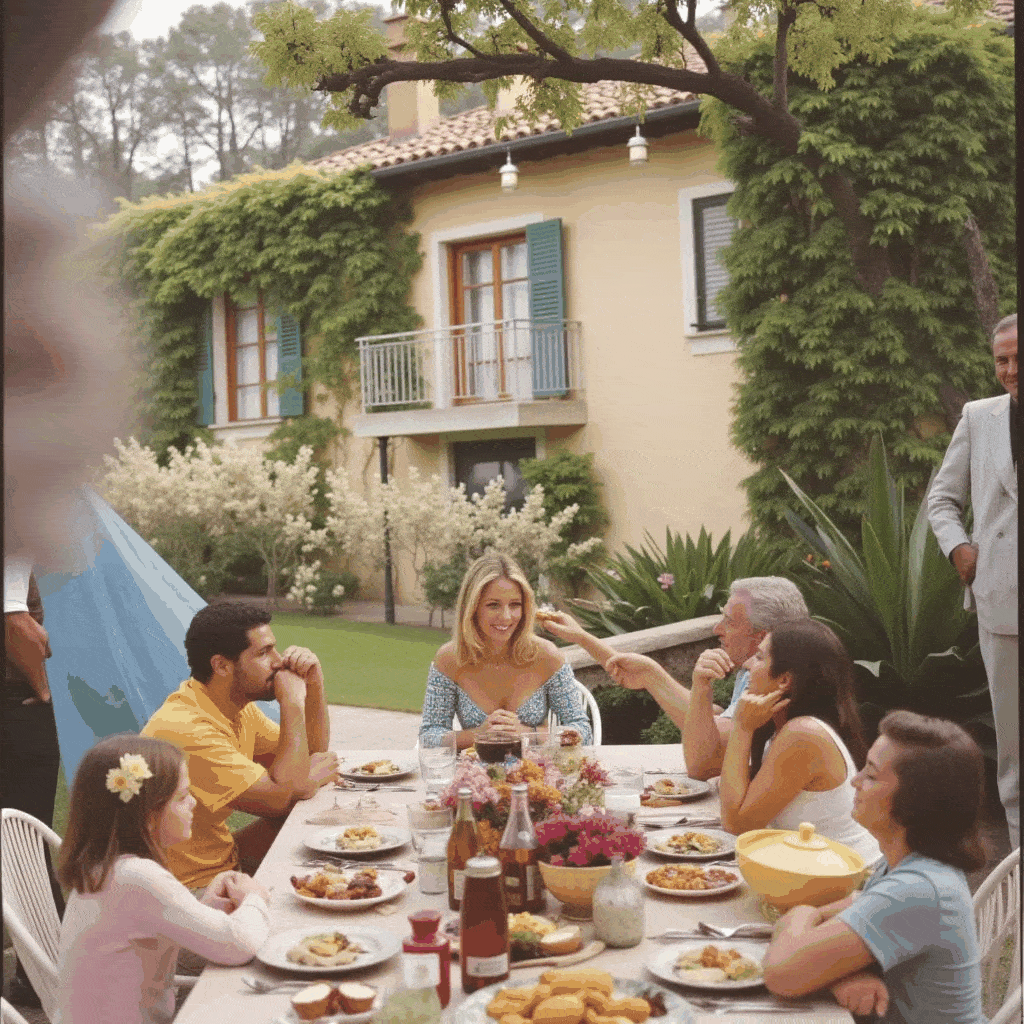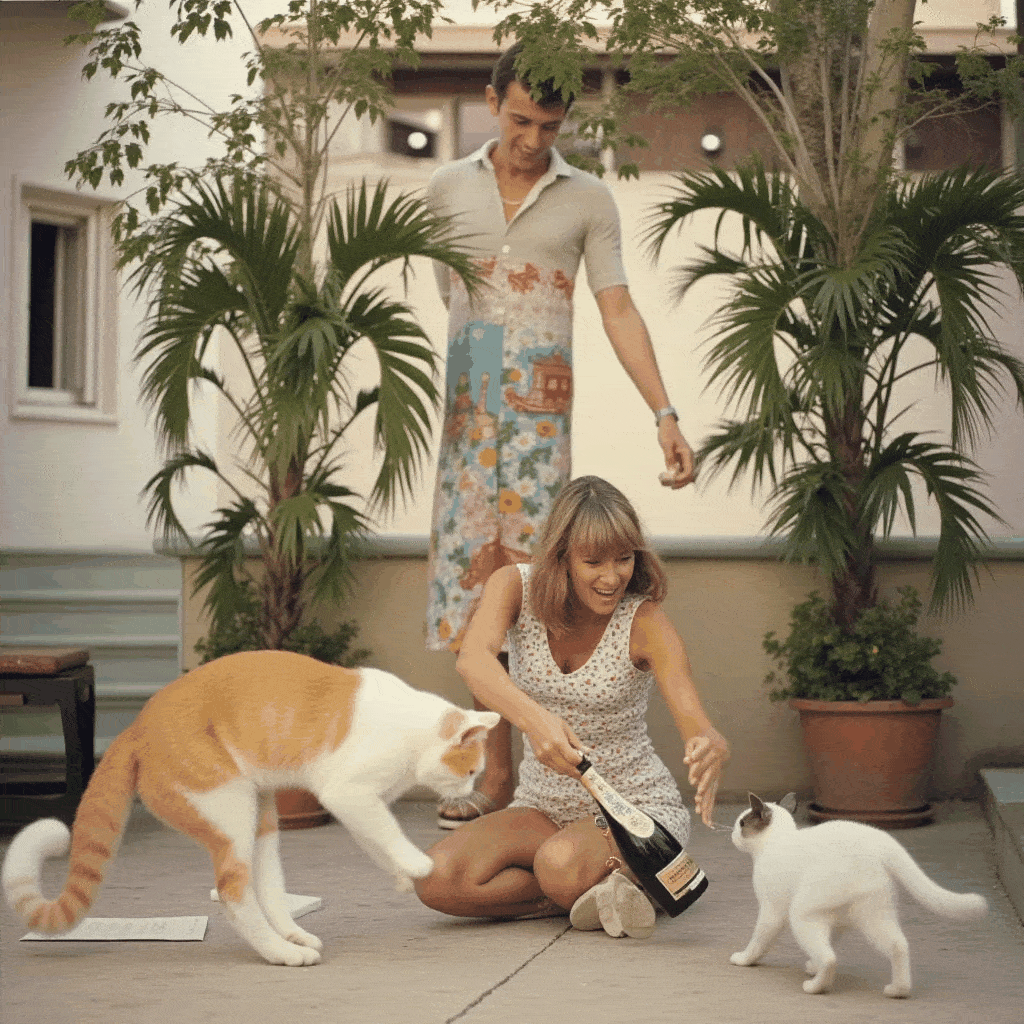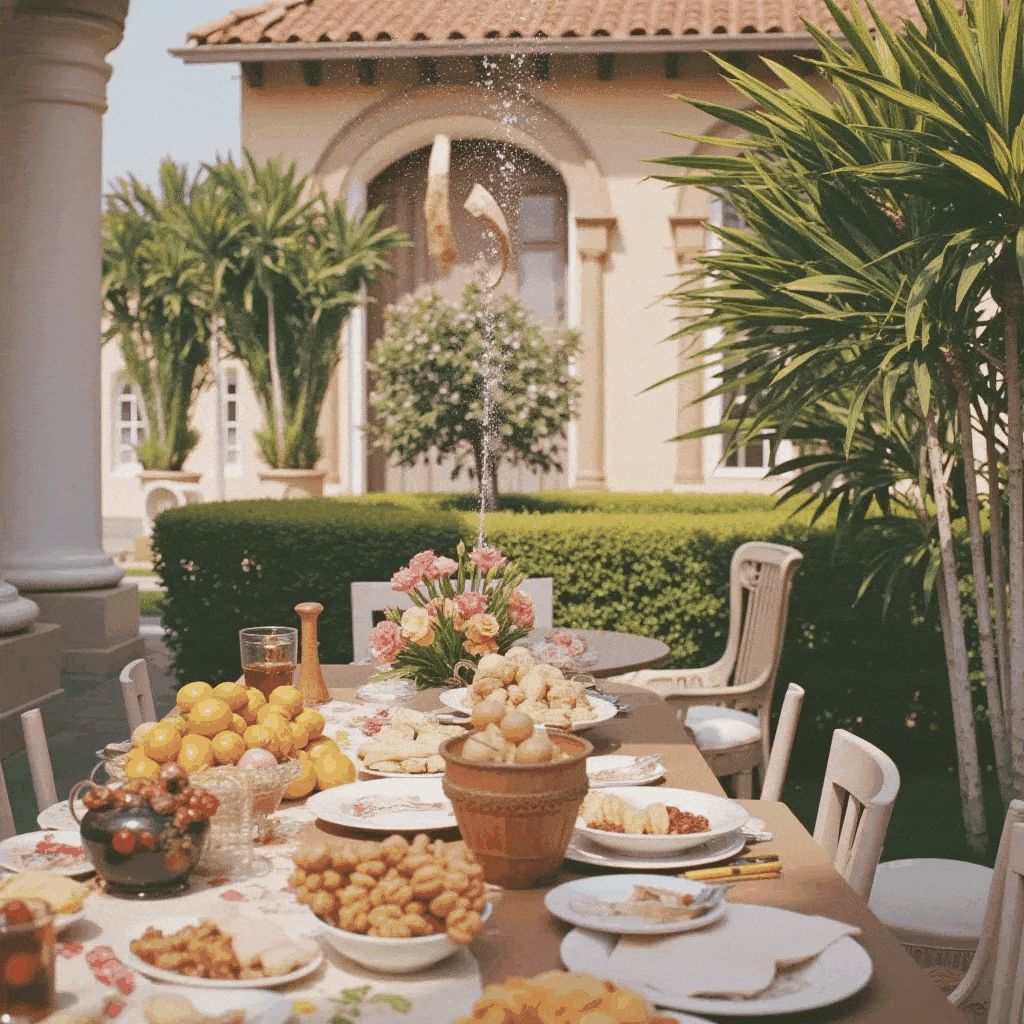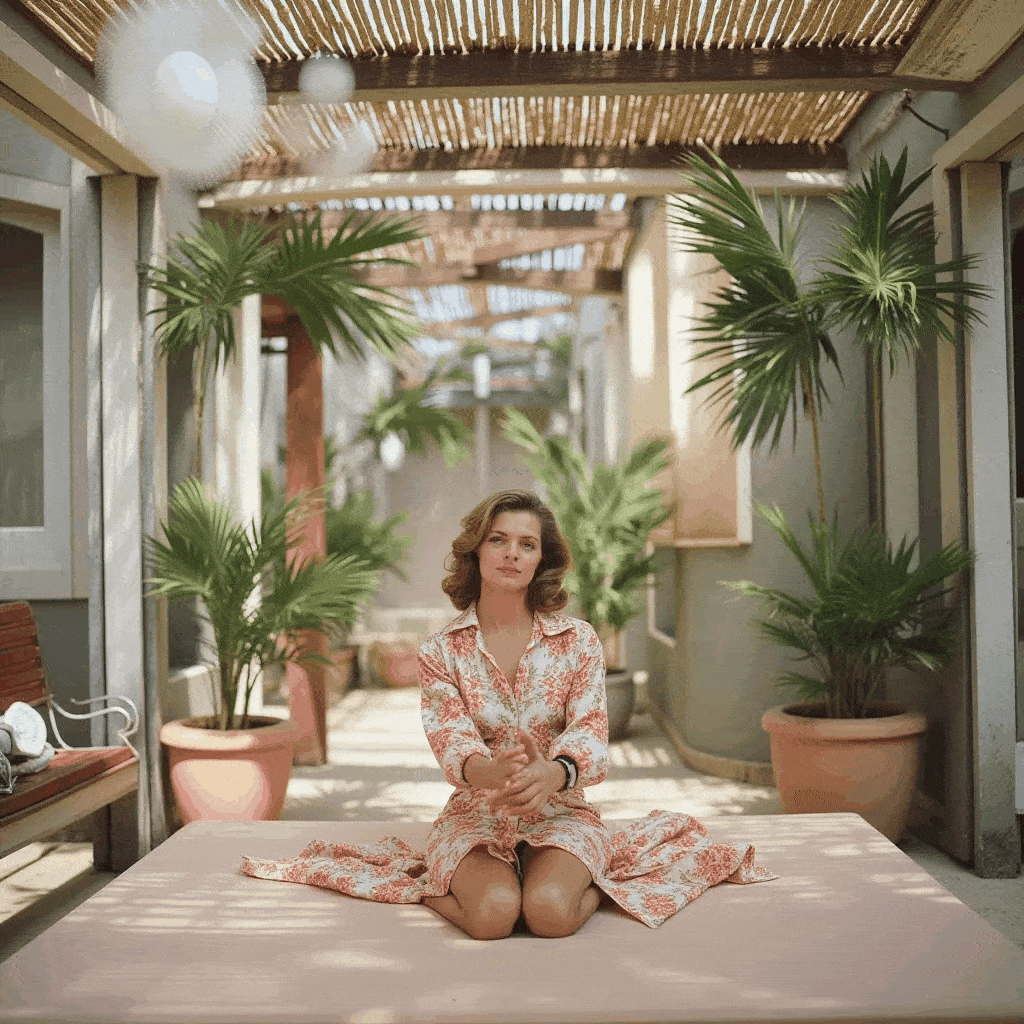

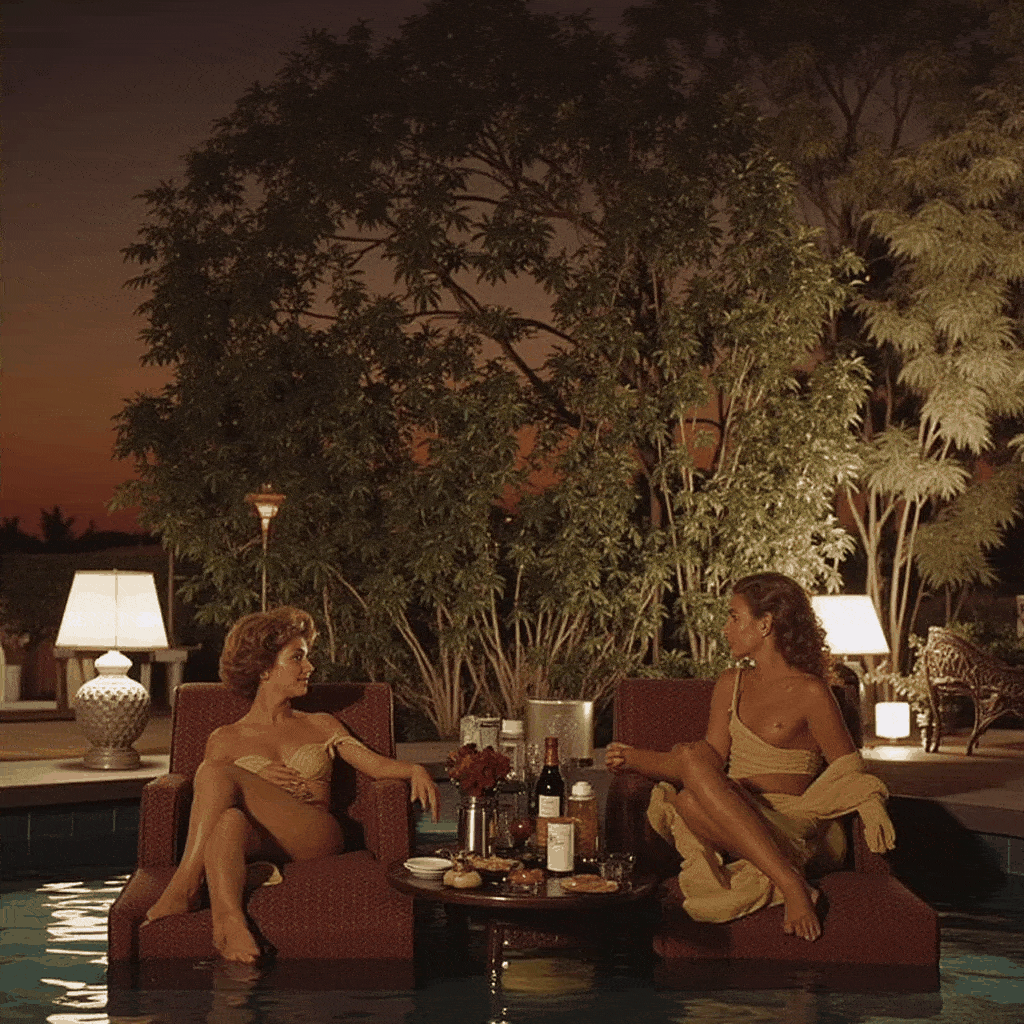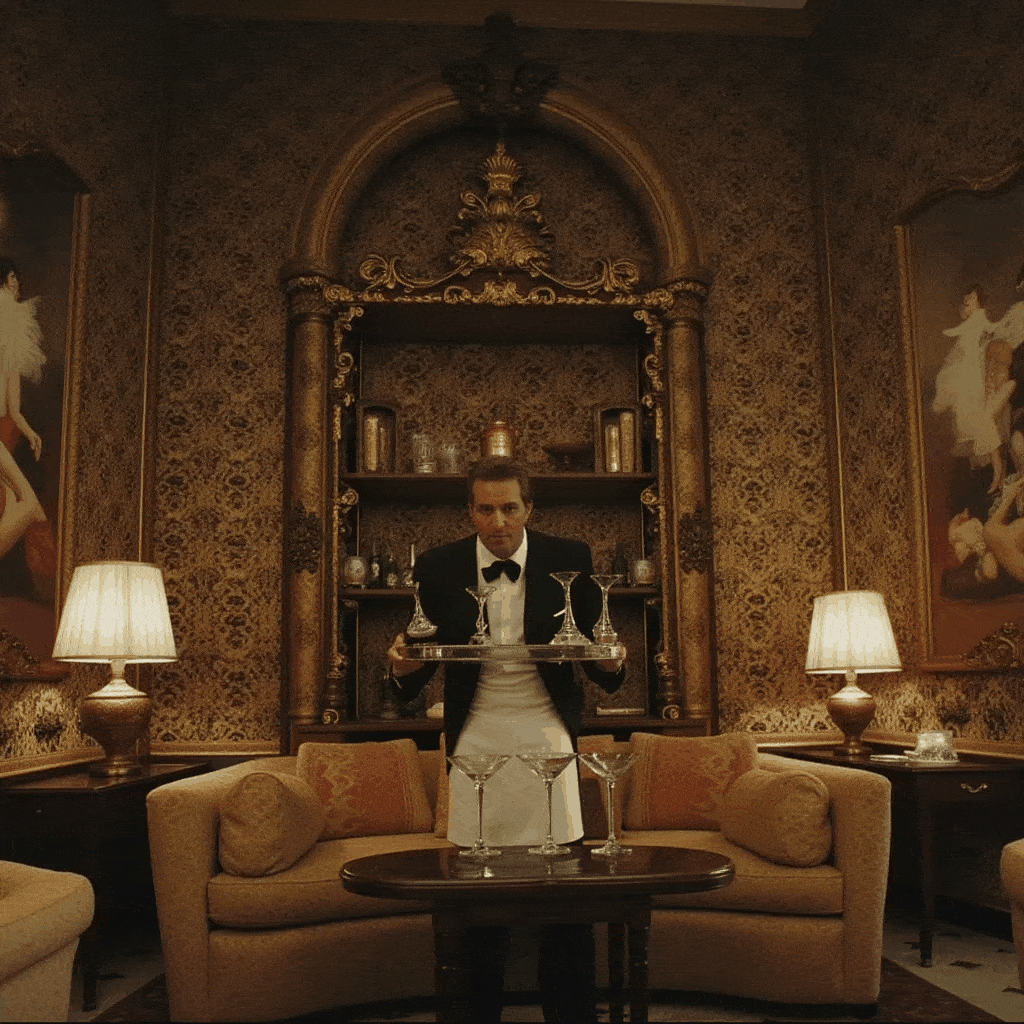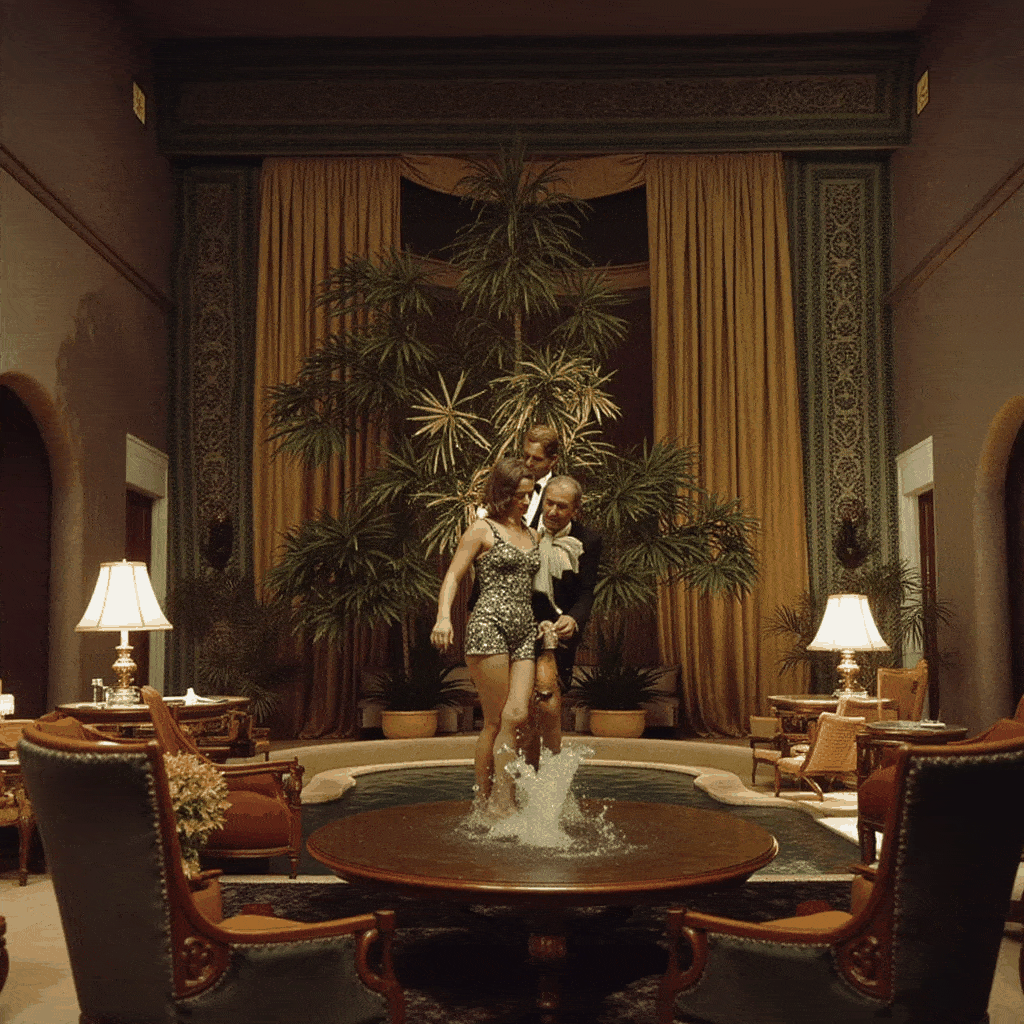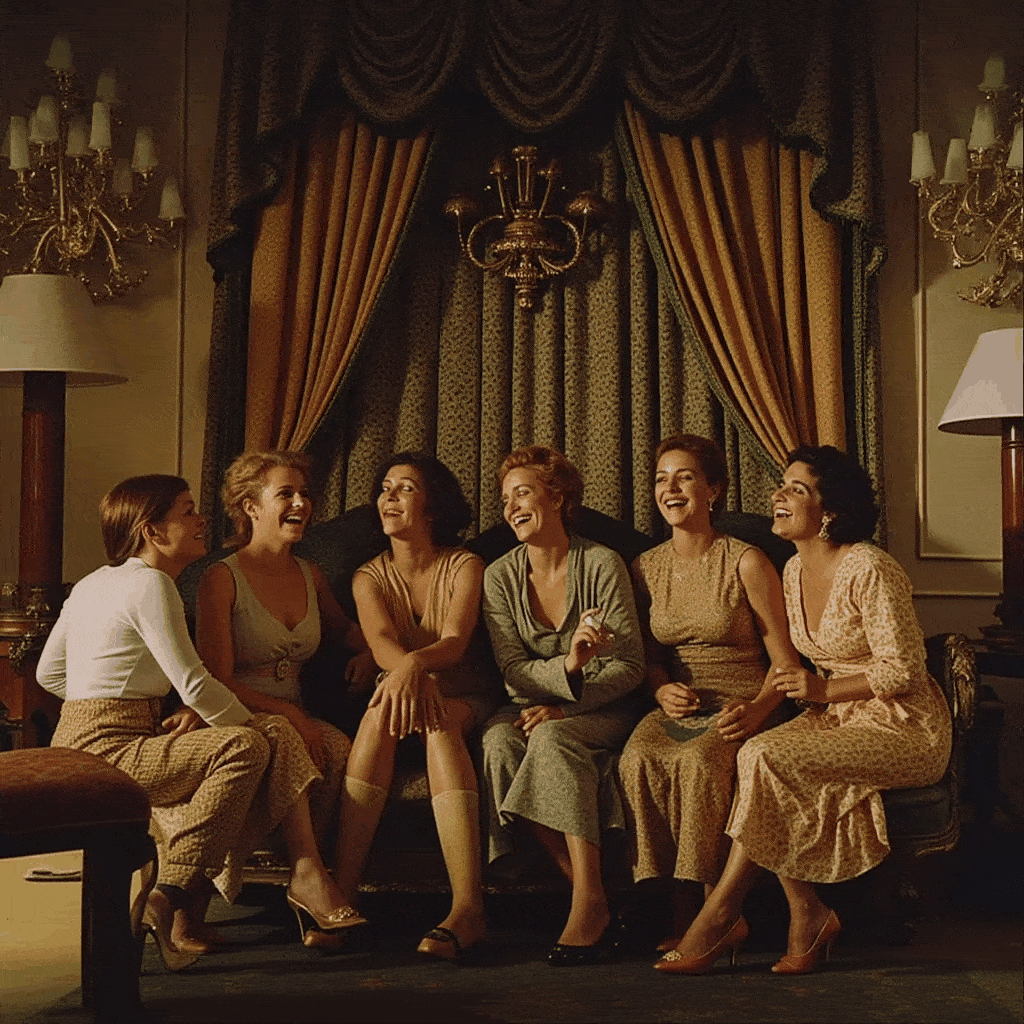
Additionally, we built a storyboard GIF generator that can string together multiple generated frames into a narrative sequence. In this mode, the user can specify a series of scene prompts or variations (e.g. different camera angles, lighting conditions, or times of day) and the app will generate each frame in Slim Aarons style and then compile them into an animated GIF. Imagine taking a static villa photograph and generating a short GIF that shows the villa at noon, then sunset, then under evening lights, it creates a micro story of the setting, as if one is seeing moments in time or different perspectives in one continuous image. Our interface provides dropdown suggestions (for instance, “Frontal view from street level” vs “Aerial perspective”, or “Golden hour lighting” vs “Nighttime lighting”) to help users pick these variations without needing detailed prompt engineering. The result is a fun, narrative cinemagraph that remains entirely in the aesthetic universe of Slim Aarons.
2D 2 3D Image Modeling
Perhaps the most futuristic feature of our project is the ability to turn a single Slim Aarons style image into a 3D model. We integrated a cutting edge 3D generation pipeline (based on Tencent’s Hunyuan3D system) to achieve this. Hunyuan3D is a two stage AI model that first generates a 3D mesh from an image (or text prompt) and then applies high resolution textures to that mesh.

In our app, after obtaining an AI generated image, the user can click “Generate 3D”, the backend will take that 2D image as input to the Hunyuan3D model. The result is a textured 3D asset where the content of the photo (e.g. a building, a pool, and surrounding scenery) becomes a three dimensional object that can be viewed from different angles. It’s important to note that this is an approximate reconstruction, the AI will infer geometry from the single view, so it’s not exact, but it’s often plausible and detailed enough for a dimensional approximation of the object.


For instance, from a single view of a Mediterranean seaside villa (in Slim Aarons style), the system might generate a 3D model with the facade, terrace, and pool, allowing us to orbit around and see those elements in 3D space. The textures of that model carry over the photographic details from the image, which means the output looks like a tiny virtual set straight out of a Slim Aarons photo. This feature powerfully demonstrates the expansive potential of AI, we are literally stepping into the photograph and exploring it as a space. A snapshot of a rotated view of such a 3D model would show how, for example, the patio and pool from a photo now have depth and can be seen from an angle that was not present in the original image. By leveraging Hunyuan3D’s advanced 2D to 3D conversion, our project links classic photography with immersive media. The 3D models can even be exported for use in game engines or VR, hinting at new ways to experience Slim Aarons’s world.
All these features were implemented in a single cohesive Gradio interface, with a clean layout and instructions so that general audiences could use it easily once we refine it and deploy it to Hugging Face. We even tried styling the UI with a retro color scheme to pay homage to the mid century vibe. The result will be hopefully an application where one can play art director and tech magician at once by crafting scenes, tweaking styles, animating moments, and exploring dimensions, all under the consistent artistic umbrella of Slim Aarons’s.
Reflections: AI as a Tool to Preserve and Reinterpret Style
This project demonstrated the remarkable power of AI to act as a bridge between past and future in the realm of art and style. By training on Slim Aarons’s work, our generative model learned not just to copy specific images, but to internalize the essence of his aesthetic. In doing so, it allows us to preserve that essence in a digital form. One could imagine, decades from now, someone using a similar model to recall the look and feel of mid 20th century glamour, the AI becomes a guardian of a cultural memory, much like a carefully maintained archive or a museum collection, but one that can also create new artifacts in that style.




More intriguingly, the AI enables us to reinterpret and expand upon Aarons’s legacy. We were able to pose “what if” questions that would be impossible otherwise: What if Slim Aarons had photographed this modern setting or that imaginative scene? What would his take on it look like? The model can give a plausible answer. We generated scenes that Aarons never did – fictional yet faithful to his vision – such as a tech startup office rendered as if it were a 1960s cocktail lounge, or a tropical space colony envisioned with the same leisurely opulence of a classic Aarons jet set location. The results often carry that uncanny mix of familiarity and novelty: instantly recognizable in style, yet fresh in content. This speaks to AI’s ability not only to preserve an artistic style, but to creatively apply it to new contexts, thereby reinventing the style without the artist’s direct involvement. It’s a form of stylistic extrapolation that both honors the original creator and showcases the AI’s generative imagination.
The project also ventured beyond static images, suggesting how iconic styles can live on in new mediums. By animating and generating 3D models from Slim Aarons inspired images, we took his style into realms he himself never explored (Aarons worked exclusively in still photography). Seeing a pool party from his photo come to life as a short GIF, or being able to virtually “step into” a scene via a 3D model, was a striking experience. It felt as if the AI was collaborating with the late photographer – giving motion and volume to his flat prints. In a broader sense, this hints at AI’s role in the arts as a kind of time machine: it can resurrect styles from the past and project them into the future’s forms of media. A photograph becomes an animation; an image becomes interactive 3D. The style persists and adapts, transcending its original format.

Of course, this project is also a reminder of the respect and care needed when using AI to emulate an artist’s work. We approached Slim Aarons’s archive with an ethos of admiration and learning. The AI was trained to celebrate his style, not to trivialize or exploit it. In practical terms, our results are clearly marked as AI generated (and the use of the trigger token SLMRNS is an internal way to acknowledge the source inspiration). Ethically and creatively, we see such a generative model as a tool for education, preservation, and artistic experiment. It allows students and researchers – like those of us in the seminar – to analyze what exactly comprises an artist’s signature style by attempting to reproduce it. In doing so, one gains a newfound appreciation for the original. If the AI struggles with a certain element (say, the subtle way Aarons backlit his subjects or the exact color grading of a Kodachrome slide), it points us back to studying the artist’s technique more closely.

In the end, our Slim Aarons generative AI project revealed a hopeful message: technology can preserve and amplify the legacy of iconic art styles, keeping them not only alive, but evolving. Just as his mages once offered an escape into a world of glamour and leisure, our AI driven extension of his style opens the door for new escapes and imaginings, be it through freshly minted “vintage” scenes, playful animations, or immersive 3D environments. The good life that Aarons depicted can thus continue to enchant future generations in mediums he couldn’t have dreamed of, all while reminding us of the enduring power of a well crafted aesthetic. In a way, it’s a collaboration across time: Slim Aarons provides the inspiration, the AI provides the innovation, and together they create something that neither could have achieved alone.
