
Brief
Our aim in this project was to generate real time mapping with object detection and object avoidance with a Turtle_bot using ROS. Embracing Ubuntu and creating workspaces alongside docker, we were able to create a system which allowed us to map an environment and find obstacles within. From this we were curious into what other details we can find within the process, thus we looked into obstacle detection to identify targets within our mapping.
Inspiration



From left to right: 1- Robotic scanning for architectural data extraction, analysis and validation. 2- Dynablox: Real-time Detection of Diverse Dynamic Objects in Complex Environments
Workflow
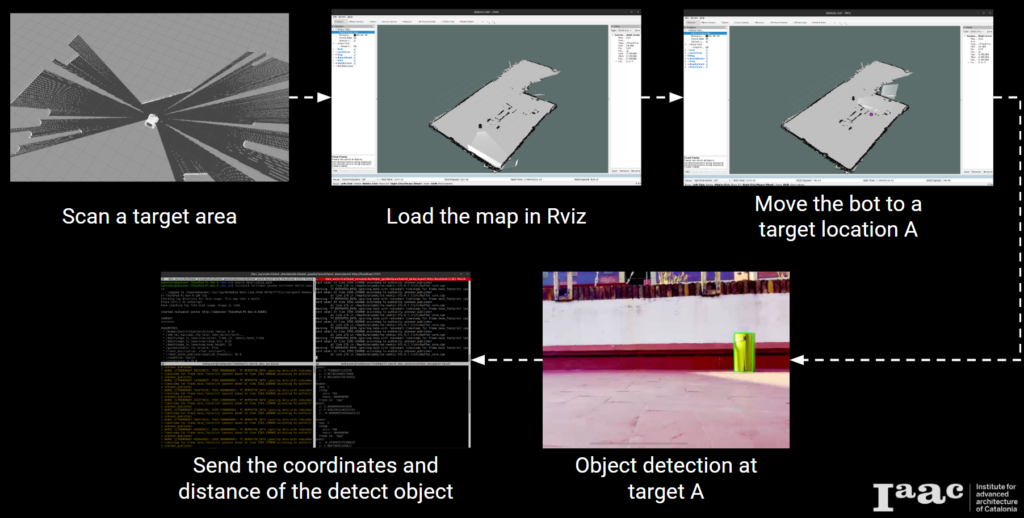
Scanning and Gmapping
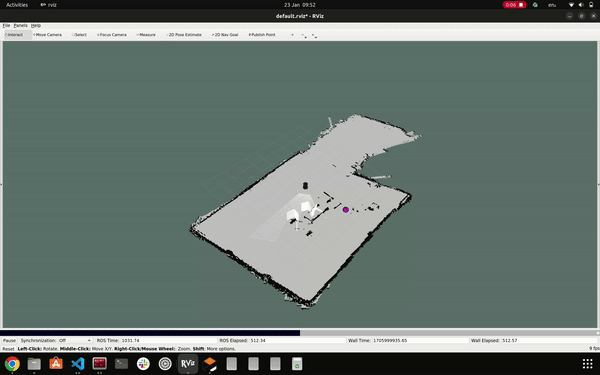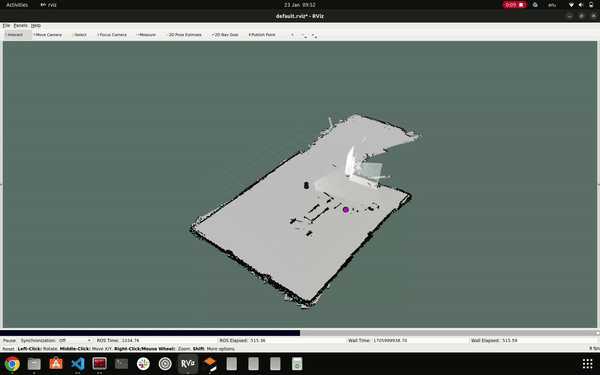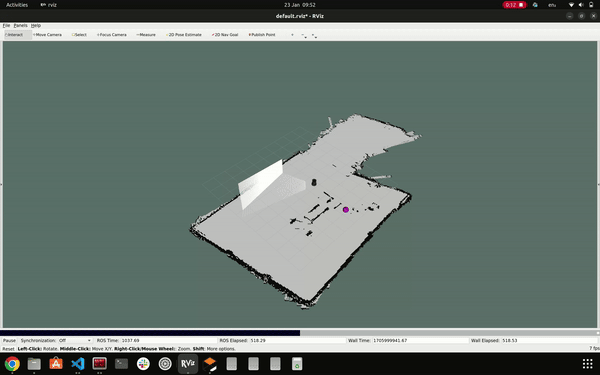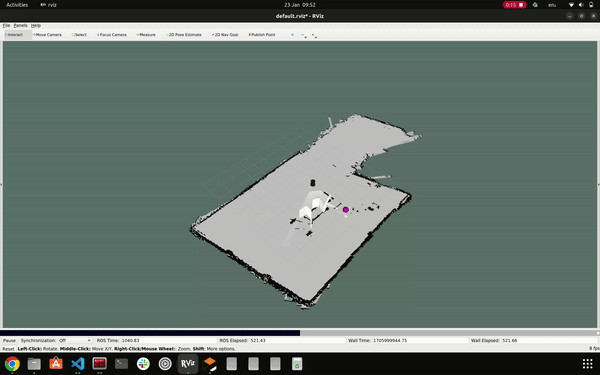
To conduct scanning, we utilized the Gmapping package. Our process began by connecting our PC to the TurtleBot and initializing the TurtleBot equipped with a LIDAR sensor. Subsequently, we launched the Gmapping package. Teleop was utilized for controlling the robot, and RViz served as the tool for obtaining the map. Object detection during mapping and navigation was facilitated through the use of a RGB USB camera. Prior to deploying these operations on the actual robot, we conducted multiple simulations.

hardware utilized for scanning, mapping, and navigation
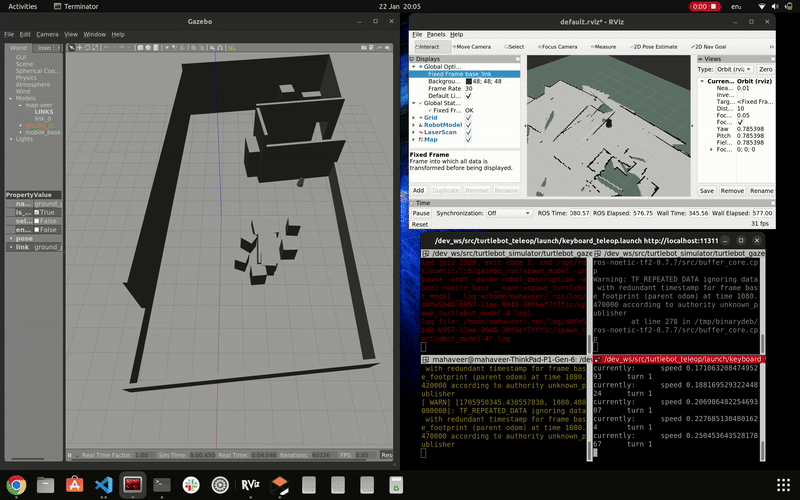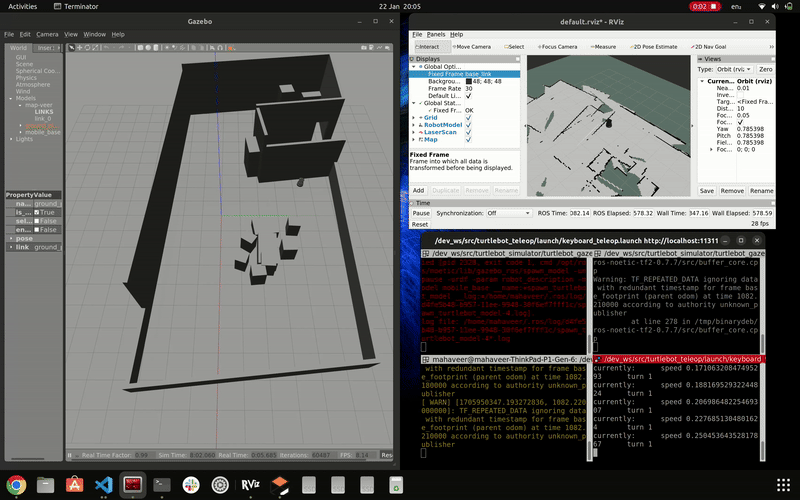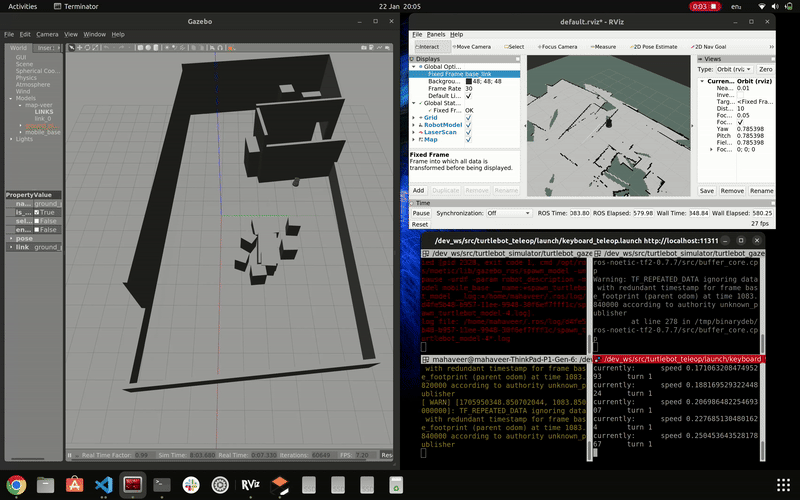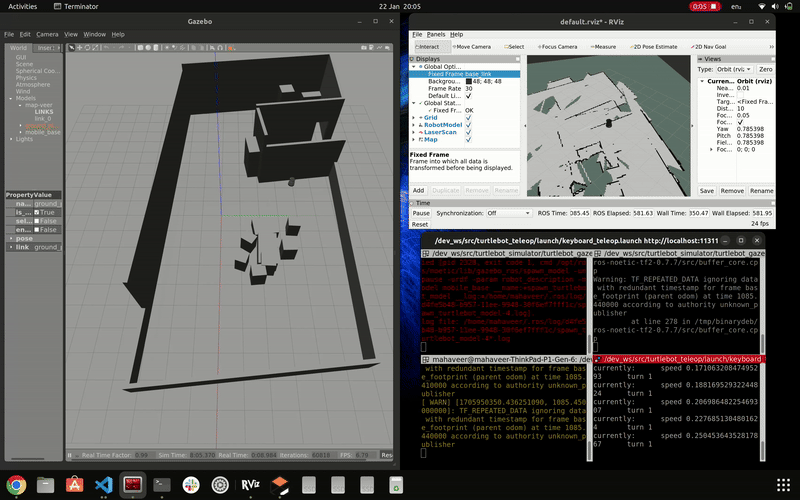
simulation of gmapping
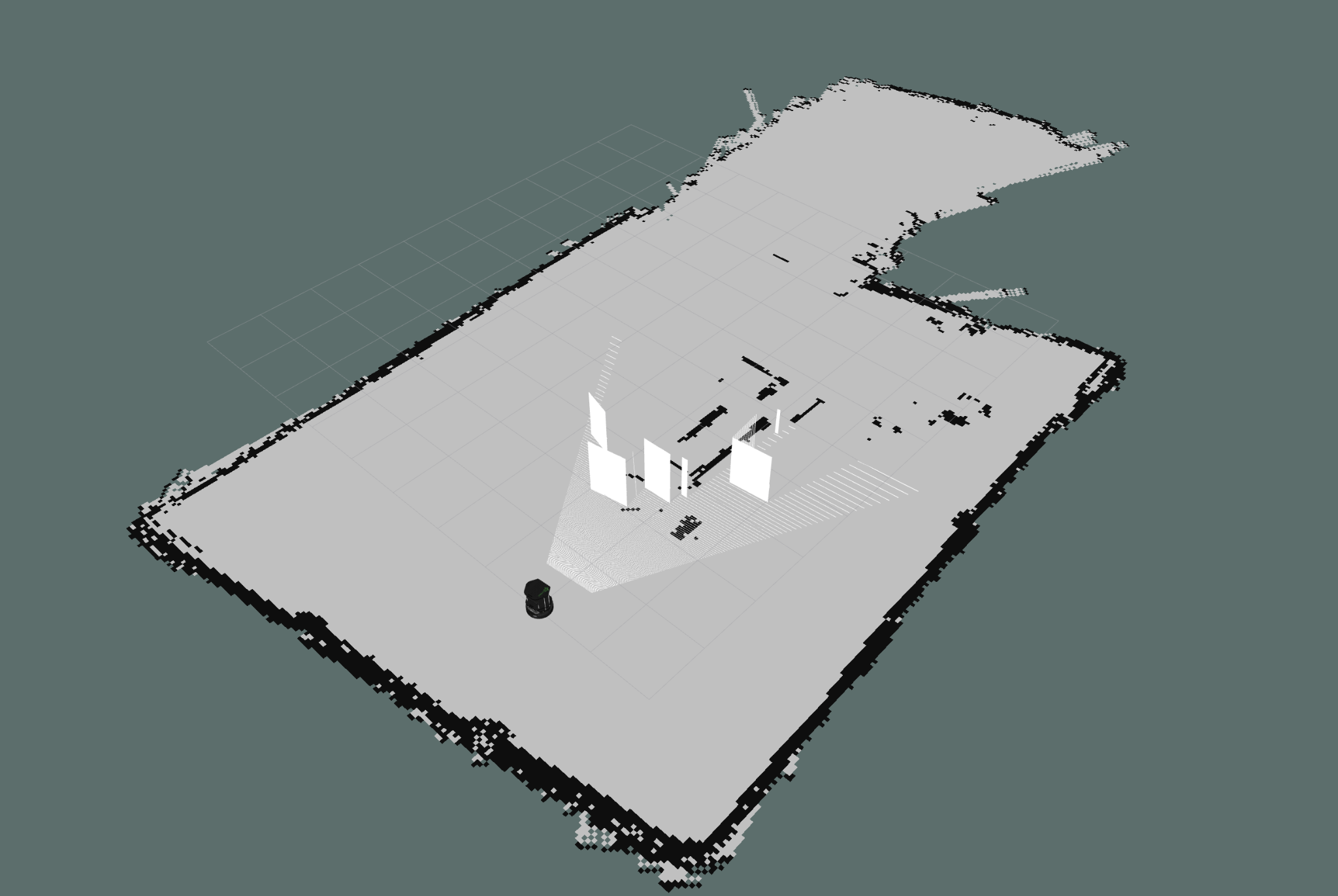
mapping using LIDAR sensor
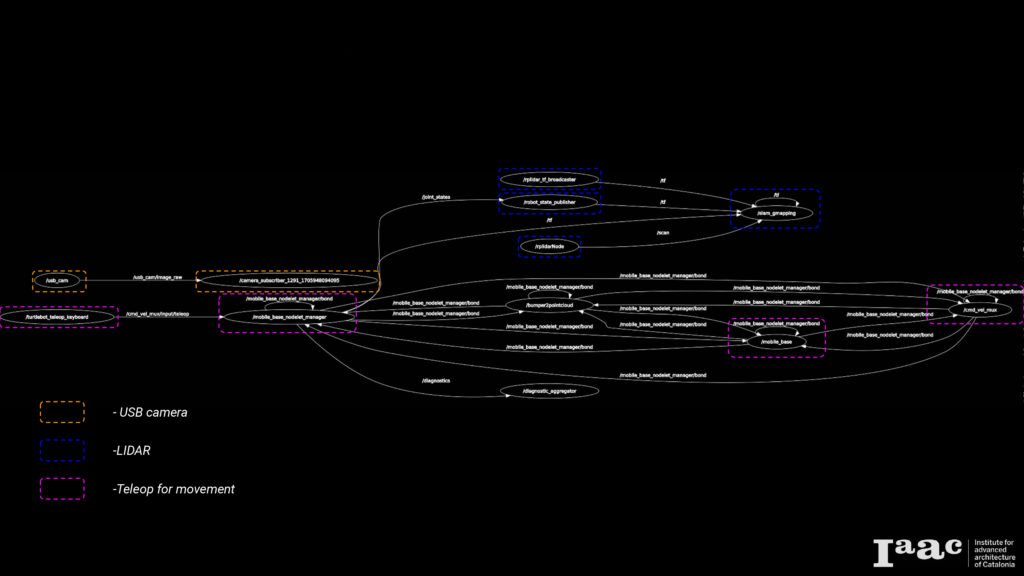
rqt graph of nodes
Navigation
In order to guide the robot through a series of predefined goals with respect to the map, the Navigation Node plays a pivotal role. This node is tasked with storing the various goal locations that the robot needs to traverse. Subsequently, it publishes these stored points to the move_base node, organizing them into a sequential order. This sequence of goals enables the robot to navigate through each point, effectively reaching the final destination by successively traversing the specified goals. This process allows for efficient and controlled navigation, ensuring the robot follows a predetermined path in achieving its objectives.
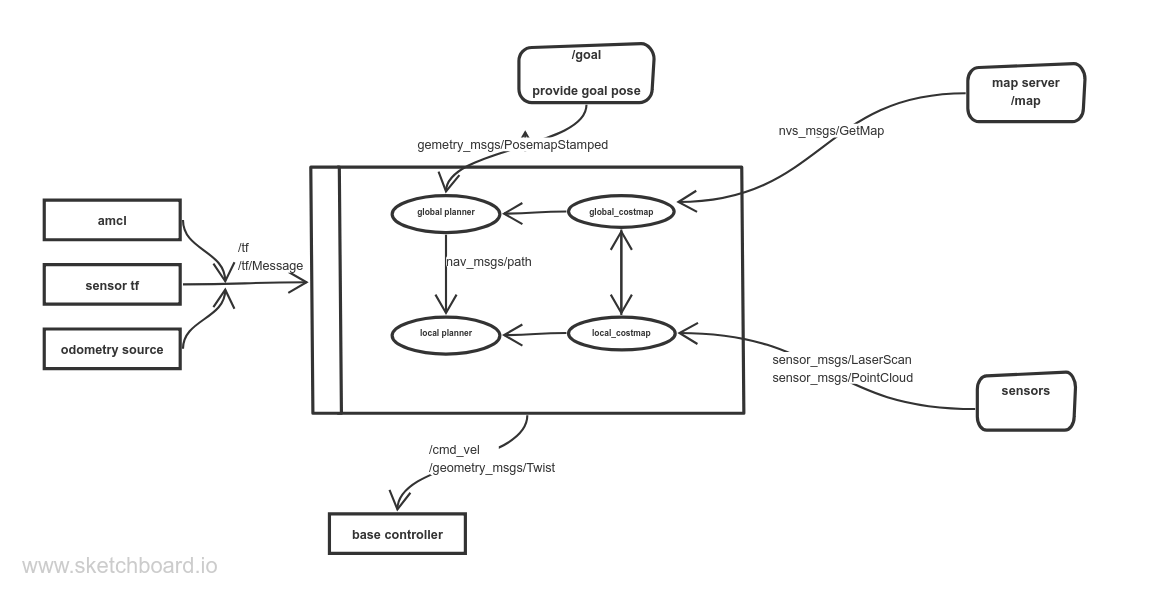
The graph shows how the move_base node interacts with other system components. The node implements SimpleActionServer from actionlib package, The Action server provides /goal topic that will provide the move_base node with goal positions.
Object Detection
For object detection we tested two different methods. The first method is detecting and matching features. Within this a database of base images was created. Each object used in testing would have a plethora of images in their directories which would be called upon on each frame to check if there are matching features between the live detected object’s features in frame and each feature in the database of images. This could create quite a lot of lag on each frame if every feature of each image would be checked. Going forward it was found to have better performance for each image to have there features pre-trained before runs of feature matching, instead of reading it on each frame. Checking each frame and comparing it to a database was still produced lag, thus a new method would be investigated.






With improved images many features would get picked up but would be matched inconsistently. Even with improved base images, there was a lack of features being matched, and incorrectly matched. However, this method is more flexible for a variety of objects.







The second method we tested was controlling colour channels and filtering for a specific colour was the other method. With this we could control the colour range, allowing certain amount of colour through on each Blue, Green and Red channel. In this instance we filtered for a Green/Lime colour. With this we could pick up contours. However this can be constrained by shadows, as it takes parts of the target out of the colour filter. This was more efficient in real time as per frame we only filtered what came through and reduced any holdup which negated any noticeable lag. This gave us a greater performance overall, and was more direct for the scope of our project.
Adjusting filters by setting : -100 shadows,
88 brightness,
98 saturation,
83 vibrancy
We were able to increase accuracy when identifying target objects. However basing the project on the terrace we were constrained by the inconsistent amount of light on screen for the RGB camera.

Further steps
We wanted to go one step further and place the new detected object upon the map, however we were constrained by time and developing that process. We started developing a node that would publish it on the map when the contour is detected and estimating the width, height and distance from the Turtle_bot’s camera and Turtle_bot coordinate.

