
adapted from IaaC´s Artificial Intelligence Program’s study of machine learning for robotic pick and place. (https://blog.iaac.net/reinforcement-learning-for-robotic-pick-and-place/research).
Github Repository. https://github.com/LaurenD66/ROS-GridWorld-RL-with-Obstacles
In a recent study by IaaC´s Artificial Intelligence Program, students used reinforcement learning models to train an (robotic) agent to move through a space defined by a simple grid from an origin to a goal, while various avoiding obstacles. The agent was rewarded for each epoch where the goal was reached and penalized for collision with the obstacles.
Building upon the foundational work, this study introduces other obstacles behaviors to the robotic pick-and-place path– (1) one where the obstacles are clustered in groups, (2) one where the obstacles are moving in the opposite direction of the agent through the grid, (3) and finally one where proximity to certain obstacles yeilded a greater penatly (more dangerous) than others. These scenarios, in addition to the original obstacle code, were introduced to similute some common construction site conditions a moving robotic arm may be subjected to in completing a pick and place task.
Construction Industry Fabrication Workflow + Machine Learning Integration
Workflow: Robotic navigation in dynamic construction environments, focusing on obstacle avoidance during material handling tasks.
Construction sites are inherently dynamic, with unpredictable obstacles and changing layouts. Traditional rule-based navigation systems struggle to adapt in real-time. Integrating Reinforcement Learning (RL) allows robots to learn optimal navigation strategies through interaction with the environment, improving adaptability and efficiency.
Application Details
- What: Develop an RL-based navigation system enabling robots to perform pick-and-place tasks while dynamically avoiding obstacles in a grid-based environment.
- Why: Enhance robotic autonomy and efficiency in construction settings by enabling real-time adaptation to changing environments, reducing human intervention, and minimizing downtime.
- How: Utilize Q-learning within a ROS-integrated GridWorld environment, employing Gymnasium for environment simulation. Implement reward shaping to guide learning and obstacle clustering to manage dynamic obstacles.
Assumptions.
- The environment can be simplified into a grid format.
- Robots will ultimately have access to sensors for obstacle detection.
- Obstacles can be static or dynamic, and their behaviors can be modeled or learned.
- In the case of moving obstacles, robots may ultimately be able to apply the training to real-time response.
Expectations.
- Robots will learn to navigate efficiently avoiding obstacles to effectively and efficiently reach goals.
- The system will generalize to various obstacle configurations and dynamics.
Inputs, Outputs, Data Flow, and Data Types
Inputs.
- Current robot position (coordinates)
- Obstacle positions and dynamics
- Goal position
Outputs.
- Next action for the robot (e.g., move up, down, left, right)
Data Flow.
- Robot perceives the environment (state).
- Reinforcement Learning agent selects an action based on the current policy.
- Environment updates based on the action, providing new state and reward.
- Agent updates its policy based on the reward and new state.
Data Types.
- States: Tuples representing grid positions (e.g., (x, y))
- Actions: Discrete actions (e.g., ‘up’, ‘down’, ‘left’, ‘right’)
- Rewards: Floating-point numbers indicating the desirability of actions
Proof of Concept Design
Dataset.
- Simulated grid environments with varying obstacle configurations.
- Logs of robot interactions, including states, actions, rewards, and outcomes.
Implementation Steps.
- Set up the ROS environment + Docker Container with the provided repository.
- Define the GridWorld environment using Gymnasium, incorporating dynamic obstacles.
- Implement Q-learning with reward shaping to guide the learning process.
- Train the agent over multiple episodes, allowing it to learn optimal navigation strategies.
- Evaluate performance by measuring success rates and efficiency in reaching goals.
Proof of Concept Video
Video Demonstration.
The below animation demonstrates the agent moving through four varient obstacles behaviors:
- the original
- clustered obstacles
- moving obstacles
- reward shaped (increased penalty for proximity to red obstacles)
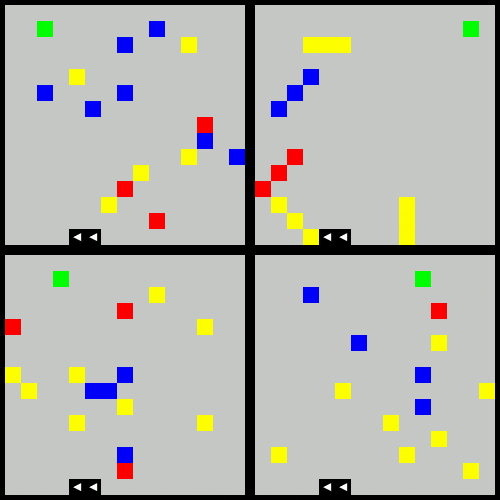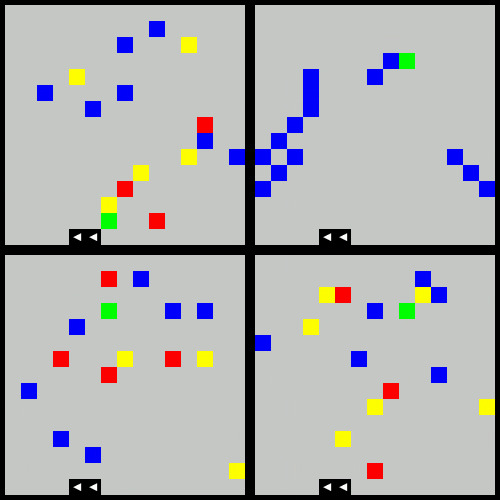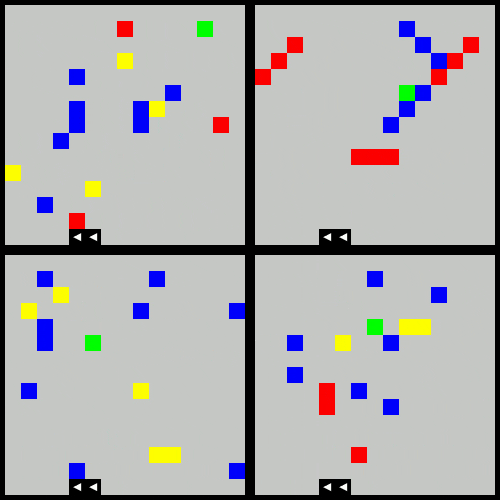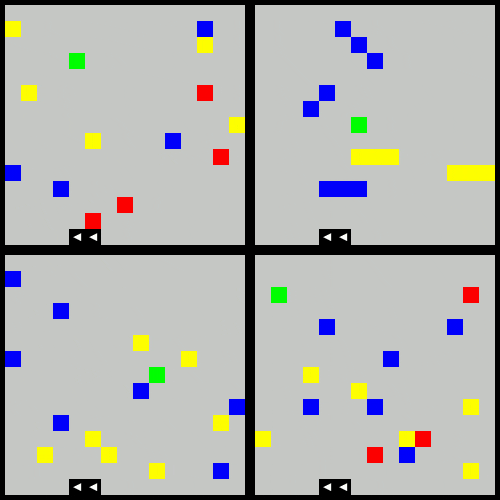
The following trained agent shows the learned behavior after 20,000 episodes of the above.

Results + Conclusion
The RL method was likely ineffective due to sparse rewards, poor exploration, and limited state representation. Fixed learning parameters and Q-table scalability issues also hinder performance, especially in dynamic or large environments. Improvements include reward shaping, better exploration strategies, and using Deep Q-Networks. Training across varied environments and applying curriculum learning can also boost generalization and overall navigation success.
