
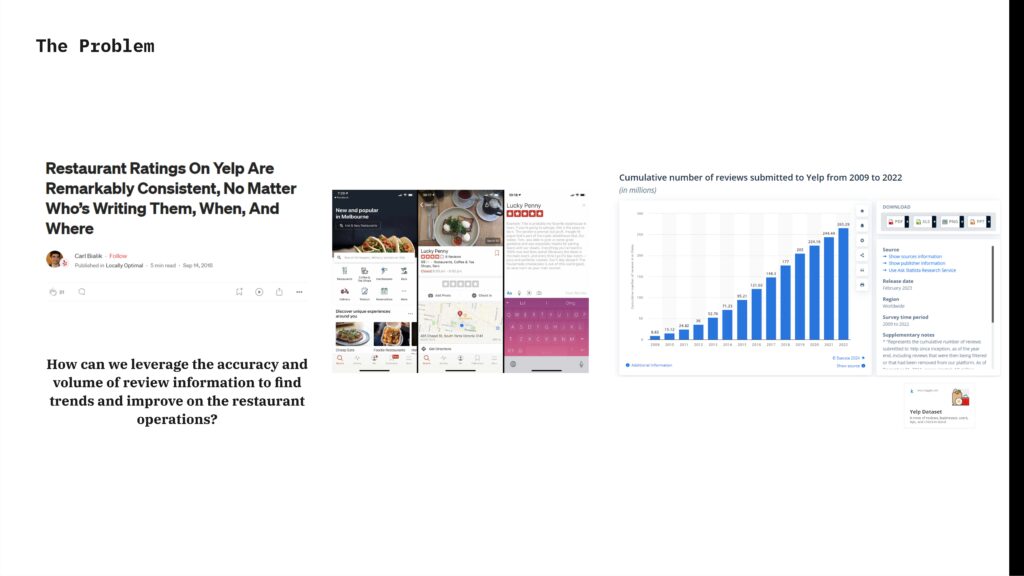
The exercise analyses Yelp reviews on restaurants and tries to investigate on how we can leverage the accuracy and the volume of the review information. The data structure then, is built up directly from the YELP web sites and associate the “review id” to a code that than has been analyzed though a RAG method…. and through the knowledge pool vector embedding.
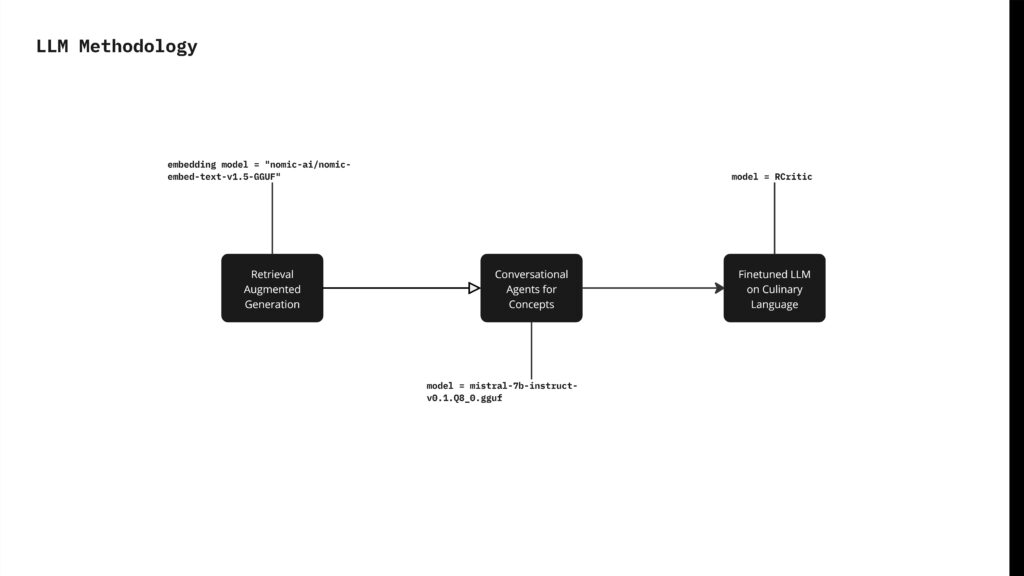
The process we followed is by starting with the yelp dataset as a knowledge pool to build a retrieval augmented generation to extract key information about the restaurant, this was vector embedded with nomic ai, then moving further to develop new concepts for development for the restaurant using conversational agents with mistral 7b, and finally finetuning the model based on culinary language to create our final LLM (Rcritic).
The Yelp Review dataset contains several key elements. Each review is identified by a unique review ID and is associated with a user, identified by a unique user ID. Reviews are also tied to specific businesses through a business ID. The dataset includes the text of each review and the date it was posted. There is a corresponding dataset for businesses, where each business ID links to details such as the business name and other relevant information. This structure allows for comprehensive analysis of reviews and their associated businesses.

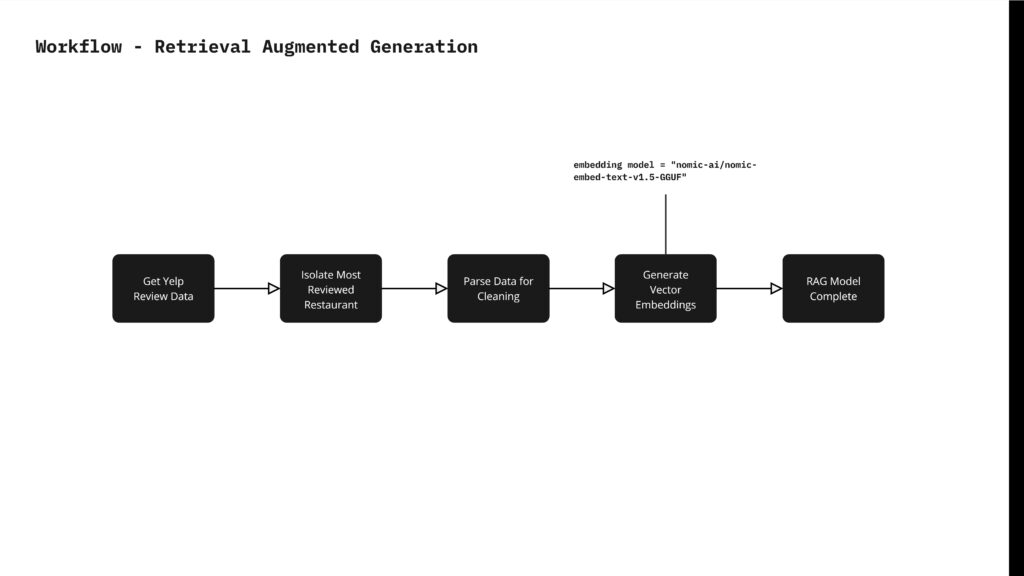
The RAG workflow isolates the most reviewed restaurants. After isolating these reviews, the data is parsed and cleaned to remove any odd symbols that could affect the quality of vector embeddings. Once cleaned, the vector embeddings are generated using Nomic AI as the embedding model. This ensures high-quality and accurate representations of the review text for subsequent analysis.
Parsing through the YELP dataset from Kaggle, we isolated the most reviewed restaurant which was Acme Oyster House in New Orleans.

The vector embedding turns the review text or categories into numbers that represent their meanings and relationships.

The completed RAG was tested to answer questions on the current state of the restaurant based on the reviews, and it did a good job extracting information based on the questions.


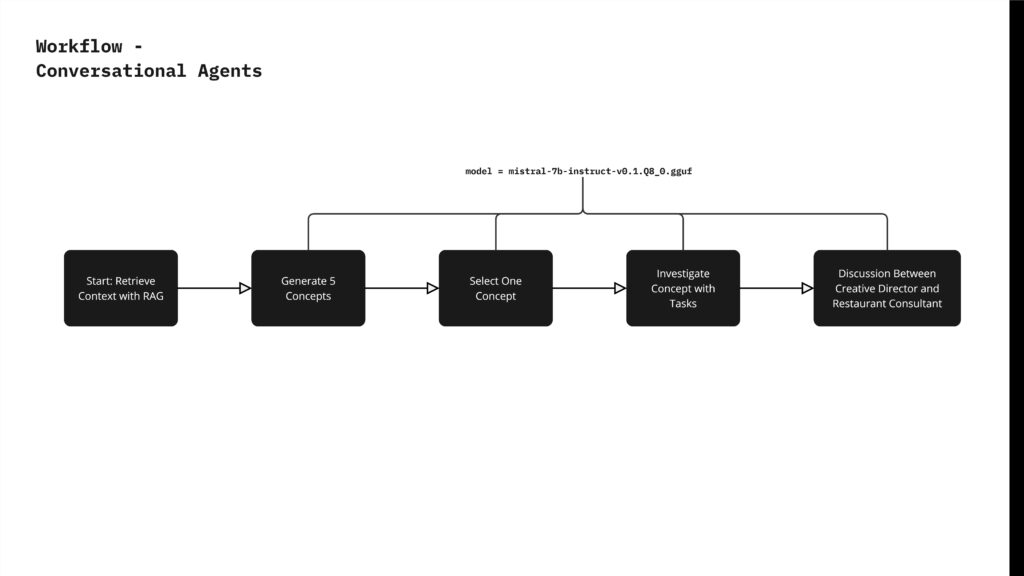
From the RAG workflow, we generated five concepts to improve the current operations of the restaurant based on the reviews. We then selected one concept and created a conversational agent to simulate a dialogue between a creative director and a restaurant consultant. In this dialogue, the creative director explores ways to enhance the restaurant’s operations, and the restaurant consultant evaluates the feasibility of these proposed improvements.






From the concepts generated using Mistral 7B, a generic language model, we realized that the results were too generic and not tailored to culinary language. To address this, we decided to fine-tune the language model on more specific culinary language using data scraped from Grubstreet magazine.
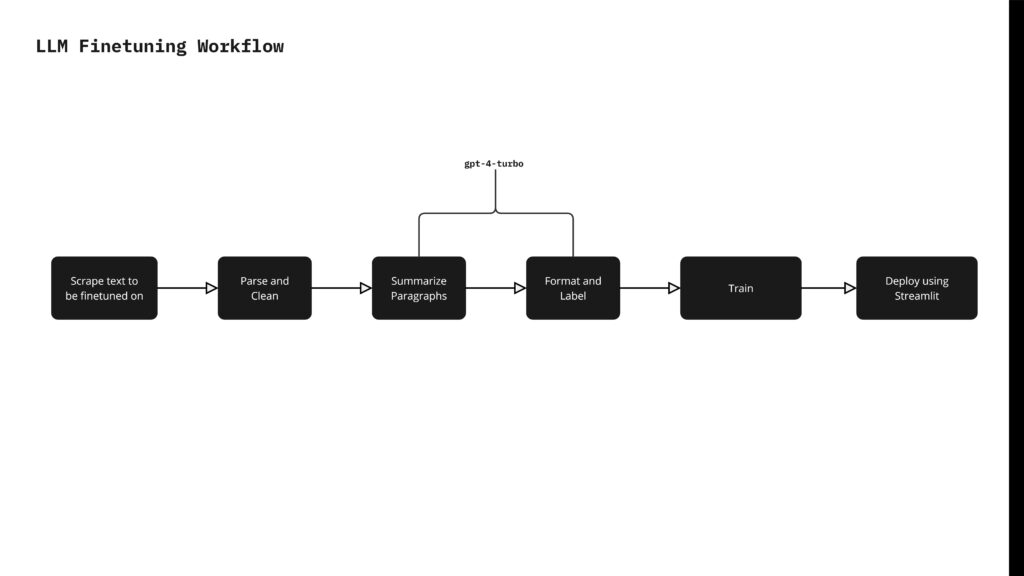

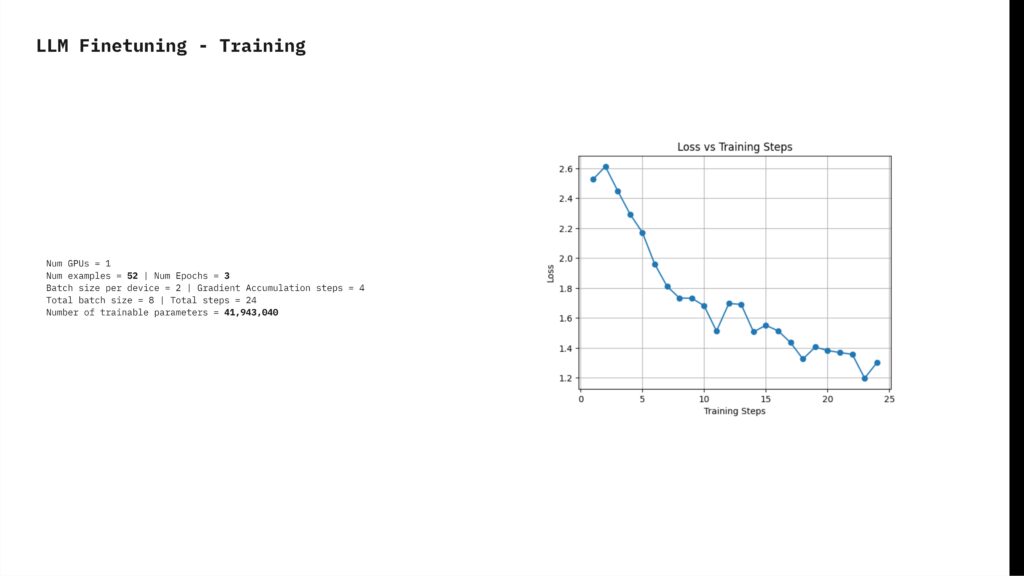
To fine-tune the Mistral 7B model, we began by scraping culinary-specific text from Grubstreet magazine. We then parsed and cleaned this text to remove unnecessary symbols and formatting issues. Using GPT-4 Turbo, we summarized the paragraphs, formatted the text, and labeled it to create data pairs consisting of instructions, inputs, and outputs. The model was trained for 3 epochs with 24 steps per epoch, resulting in 41,943,040 trainable parameters. We then deployed the trained language model, named RCritic, using LM Studio for the backend and Streamlit for the frontend, enabling user interaction with the model.
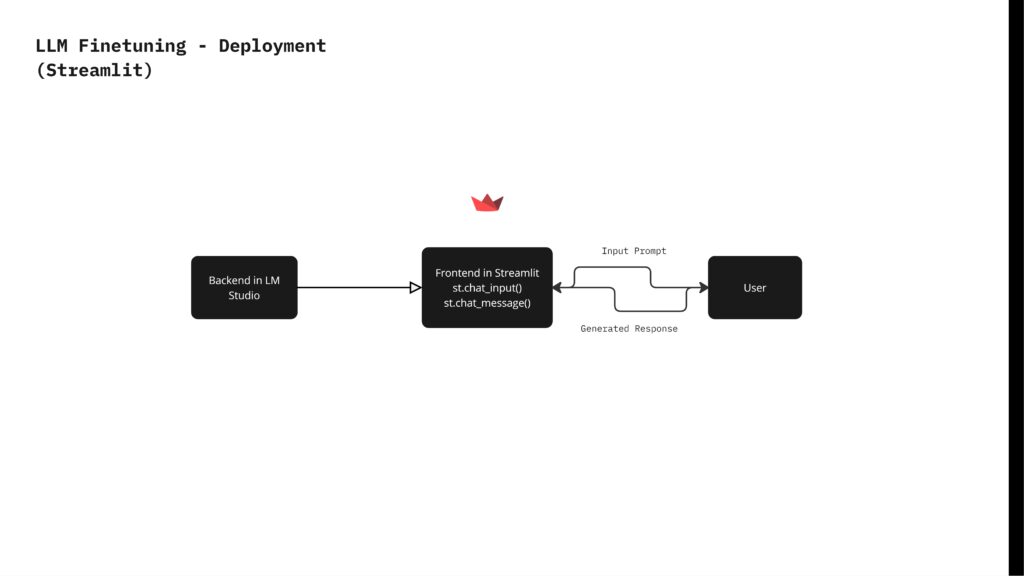
In conclusion, the trained model, RCritic, was tested against the generic Mistral 7B model using the same questions, and the responses clearly demonstrated the difference between generic answers and tailored culinary responses.

