
Vocal Commands for Autodesk Revit
Problem

Despite decades of technological advancement, the core user experience between man and computer has remained nearly unchanged. This tedious and repetitive process requires designers to spend extreme amounts of time that could be saved through updated methods. This thesis explores a potential future for computer user experience, utilizing AI language models to interpret and execute commands.
Solution

Instead of the traditional method of manual CAD, the proposed combination of Speech Recognition, Python Coding, and AutoDesk Revit can provide an alternative and more effective method of automated CAD.
The automation of Revit commands through spoken prompts could lead to reduced design time required by Revit users. This will in turn produce an accelerated iteration process and faster turn around on future projects.
State of the Art
Voice-to-Command
When considering current available technologies to consider as precedents for this research thesis, successful uses of Spoken Prompts translated into Computer Commands will be crucial. One impressive existing method is the Voice2CAD program. This is a stand alone software that allows users to program their own “spoken shortcuts” or “hot keys”. While Voice2CAD does successfully interpret spoken prompts, the software specializes in dimension conversion; For example, instead of typing out “L2 [1/2 x 1 1/2 x 48] x (3)” to specify the dimensions of 3 members all labeled “L2”, the user can simply speak that command: “ Change the three L2 members to be one half by one and one half by 48.” While this does save time in manual typing, this is a very specific case that has many limitations. Another example of voice powered commands is the offering of Voice Recognition by AutoDesk within Fusion360. However, this product is still in its infancy with many limitations and inefficient results.
In addition to Speech Recognition technologies offered by third party software, it is important to understand the Natural Language Processing (NLP) models that many of these programs utilize. There are many NLP systems that can be utilized within Python code for Speech Recognition based on needs and uses. However, for the scope of this thesis, we will focus on three popular and effective NLP systems: nltk, spaCy, and Google Speech-Recognition.
While Google’s Speech Recognition technology is extremely effective, the use of the product requires an active Internet connection as well as importing of specific Google dependencies. Because the goal of this product is to use the minimum required outlying dependencies and services, this avenue will be effective but not the main implementation to allow for maximum ease during user experience.
After researching the NLP spaCy, it became clear that this system was not only capable of easily running within a Python environment, but also extremely useful in terms of handling large amounts of information. However, due to its large amount of requires dependencies to be installed within the Python environment, the use of spaCy would likely lead to a drastic increase of CPU usage and time required to run. Preliminary research and testing with the nltk NLP seemed to yield the best results. Because nltk requires minimal installed dependencies and is still able to handle lengthy volumes of information, this NLP will likely be the primary focus in initial Python iterations.
Finally, when looking at precedents for artificial intelligence (AI) influenced programs that produce CAD models, AutoDesk’s Fusion360 once again offers an example. While Fusion360 boasts Generative Design aided by AI within the native UI, it comes with its own limitations: The generative design tool is limited to basic functions and commands unless the user pays for additional subscriptions. In addition, the process remains reliant on the out dated manual CAD process.
When considering the current availabilities to designers, Speech Recognition and AI are being utilized but in very specific use cases with limited capabilities. Taking these precedents and expanding upon their capacities will not only prove useful to this thesis, but future research as well.
Large Language Models & Vector Calculations

Large language models are advanced artificial intelligence systems designed to understand, generate, and manipulate human language. These models are built using massive neural networks trained on vast amounts of text data, allowing them to capture intricate patterns and nuances in language. They can perform a wide range of tasks, from answering questions and engaging in conversations to writing essays, translating languages, and even generating code. The “large” in their name refers not only to the enormous datasets they’re trained on but also to their immense number of parameters, often in the billions or trillions, which enable them to model complex linguistic relationships.
Building on the concept of large language models, their ability to understand and process language is deeply rooted in the use of vector embeddings. These embeddings are numerical representations of words or phrases in a high-dimensional space, where the relationships between words are encoded as mathematical relationships between vectors.
In this space, words with similar meanings or usage patterns are positioned closer together. This allows the model to capture the nuanced, contextual meaning of words, going far beyond simple dictionary definitions. For instance, the word “bank” might be represented differently depending on whether it’s used in a financial context or referring to a river bank. The model can understand these distinctions by analyzing the surrounding words and the overall context of the sentence. This contextual understanding enables LLMs to grasp subtle variations in meaning and even interpret figurative language to some extent. As a result, these models can engage in more human-like language processing, adapting their understanding based on the specific context in which words are used.
The vector representations in large language models enable powerful mathematical operations that contribute to the model‘s language understanding and generation capabilities. One of the most impressive examples is the ability to perform reasoning through vector calculations.
The classic example:

This calcuation demonstrates how semantic relationships can be captured and manipulated in the vector space. LLMs can also use vector similarity calculations, such as cosine similarity, to find words or concepts that are semantically related. This allows the model to suggestsynonyms, complete sentences, or find relevant information. Moreover, these vector operations extend beyond individual words to phrases and even entire sentences, enabling the model to understand and generate coherent text across longer contexts. A common use case of these vector similarity algorithms is in RAG, which will be discussed later in the thesis.
The model can also use these vector representations to perform tasks like clustering similar concepts, identifying outliers, or even translating between languages by mapping words from one language‘s vector space to another‘s. These mathematical operations on word vectors form the foundation of many advanced NLP tasks, from sentiment analysis to question answering, showcasing the power and versatility of vector-based representations in LLMs.
Methodology

Due to the scope of the thesis, encompassing both manually written Python code and Revit API knowledge, we determined that our time would most effectively be spent divided. With both team members work on opposite ends of the technology stack, task items could quickly be accomplished alongside one another while working toward a common goal. This also allowed for effective collaboration to determine best paths forward for both James and Dom during weekly catch up meetings.
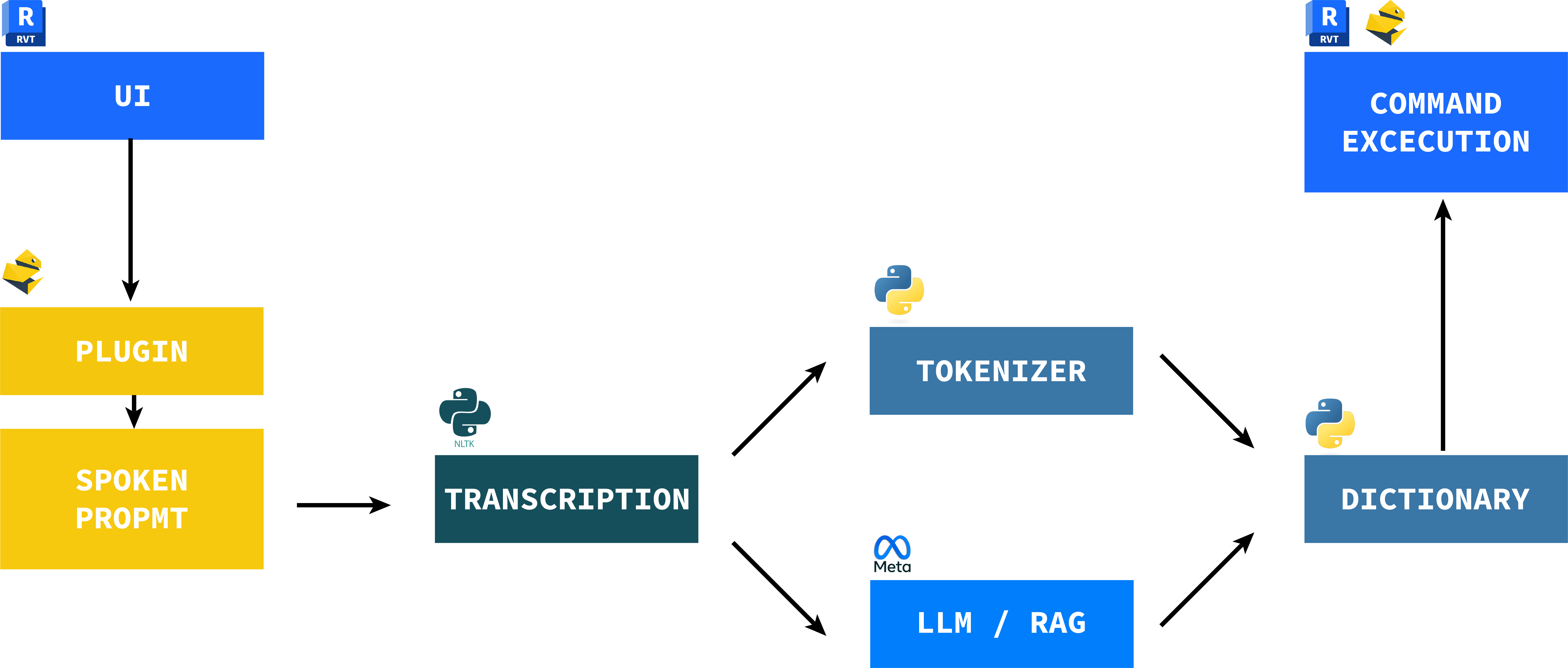
The diagram above shows the intended workflow process that will be executed during the final process. While being run inside the Revit environment, first the plug-in is installed via placing the dependent Python Notebooks into the Revit install directory. Once installed, the user will be able to easily record their prompt using their machine’s microphone. After successful installation and prompt recording, the plug-in then utilized the use of the nltk NLP in order to transcribe the user’s spoken prompt. Once transcribed, one of two separate actions can be performed to create a usable Revit Dictionary: either Python is used to tokeninze specific phrases that are predefined, or a large language model (LLM) can be used in combination with a retrieval augmented generation (RAG) search to handle larger amounts of information. Once the dictionary is created via one of the two processes, Revit is able to receive the dictionary and interpret its contents as commands and execute them.
Transcription

The images of code shown above demonstrate how the Recorder and Transcriber classes are defined within the Python environment. First, the recorder is defined to account for ambient noise, so that after a prompt is spoken, the transcriber will successfully be able to understand what was said and correctly transcribe that prompt as a variable available for reference.
Tokenizer

The outline above illustrates the order of the Python code created to prioritize tokenizing specific words within a spoken prompt. This process ensures that viable parameters and their values can be pulled from the prompt and used within Revit. First, the necessary Dependencies are installed, enabling nltk and the corresponding requirements for Speech Recognition.
Next, the Recorder and Transcriber classes are defined; these classes allow for the Python environment to utilize the machine’s microphone in order to interpret what the user has spoken, and then translate that to a coded variable. The classes even offer options to update User Experience (UI) prompts such as: “Recording… Speak now” and “Recording Stopped”.
Once the two classes are defined, the user is able to proceed with speaking there prompt for their Revit command. After being activated, the code prompts the user to be silent to account for ambient noise before allowing the recording to begin. The model is also trained to know when the user has stopped speaking according to comparison with the measured ambient noise. Finally, the variable “prompt” is displayed and cached in the code, ready to be referenced.
After the variable is created, the tokenized values are compared to the variable to identify the parameters that need to be adjusted, as well as their corresponding values. Finally, all of this information is organized and cached within a JSON dictionary that is readable by Revit.
Variable Identification

Because the approach uses ‘token’ words to identify variables and their values, those variables need to be identified. The Python code above shows the defined token words to identify whether an item is to be Created or Modified. However, in order to expand the capabilities of the code, additional token words are included for each of the two options. This ensures that users do not have to adhere to the same prompt each time a command is spoken. Of course, these values are able to be updated for further expansion. Once the code identifies whether or not elements are to be created or modified, the variables themselves are identified. Similarly to the action keywords, parameter keywords are defined as well as their possible synonyms. Once identified with their values, Parameters are organized in an easy to understand format, both for humans and Revit.

Once all the information is collected and ready, the Python code is then trained to organize and export the information in a Revit friendly dictionary. This ensures that the commands within Revit will successfully receive the information necessary to make updates based on the Spoken Prompt.
LLM / RAG
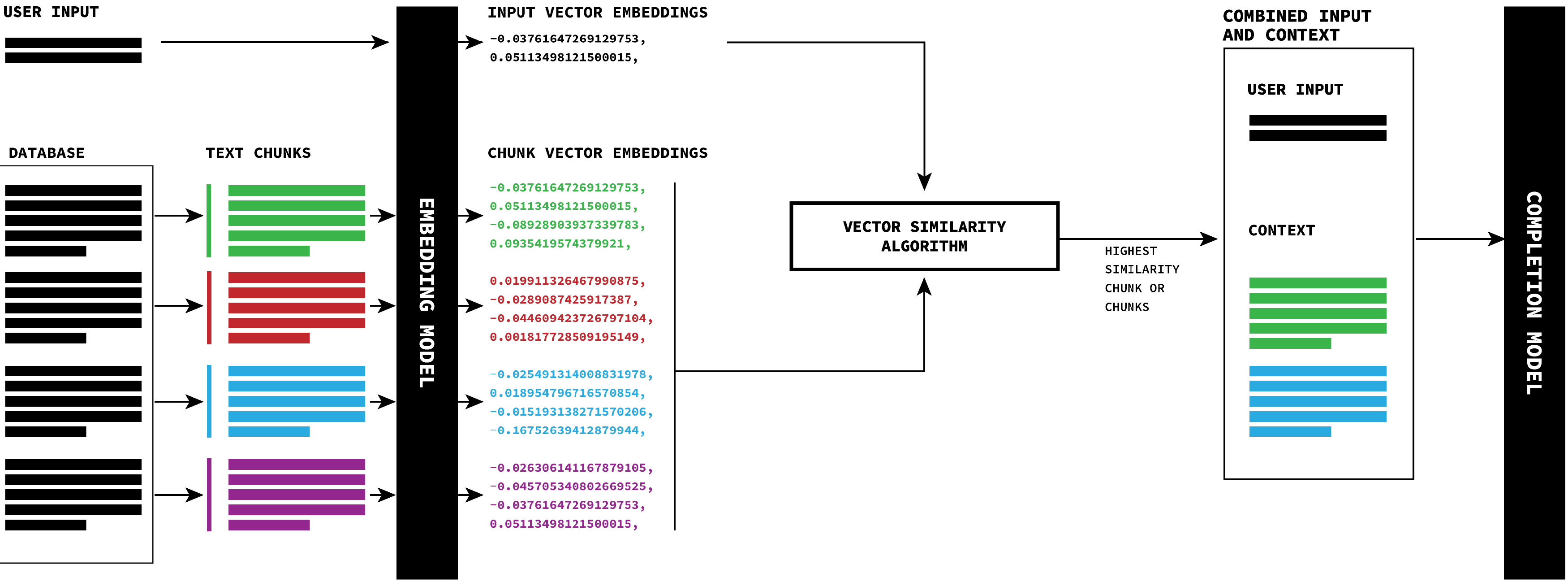
RAG (Retrieval Augmented Generation) is a enhancing an LLM’s response and accuracy by connecting it to a external database. The first step in the process is to break the data base into different chunks of text, so specific information is discernable to the LLM model. Next, an embedding model is used to get the vector representations of the text chunks and are stored as a separate file. Simultaneously, the embedding model retrieves the vector embedding of the user’s input.
Once both the database and user input is converted to a vector similarity algorithm is used to determine which chunks from the data base are most relevant to the user input. These chunks are combined then combined with the user input and sent to the completion LLM, which returns a response.
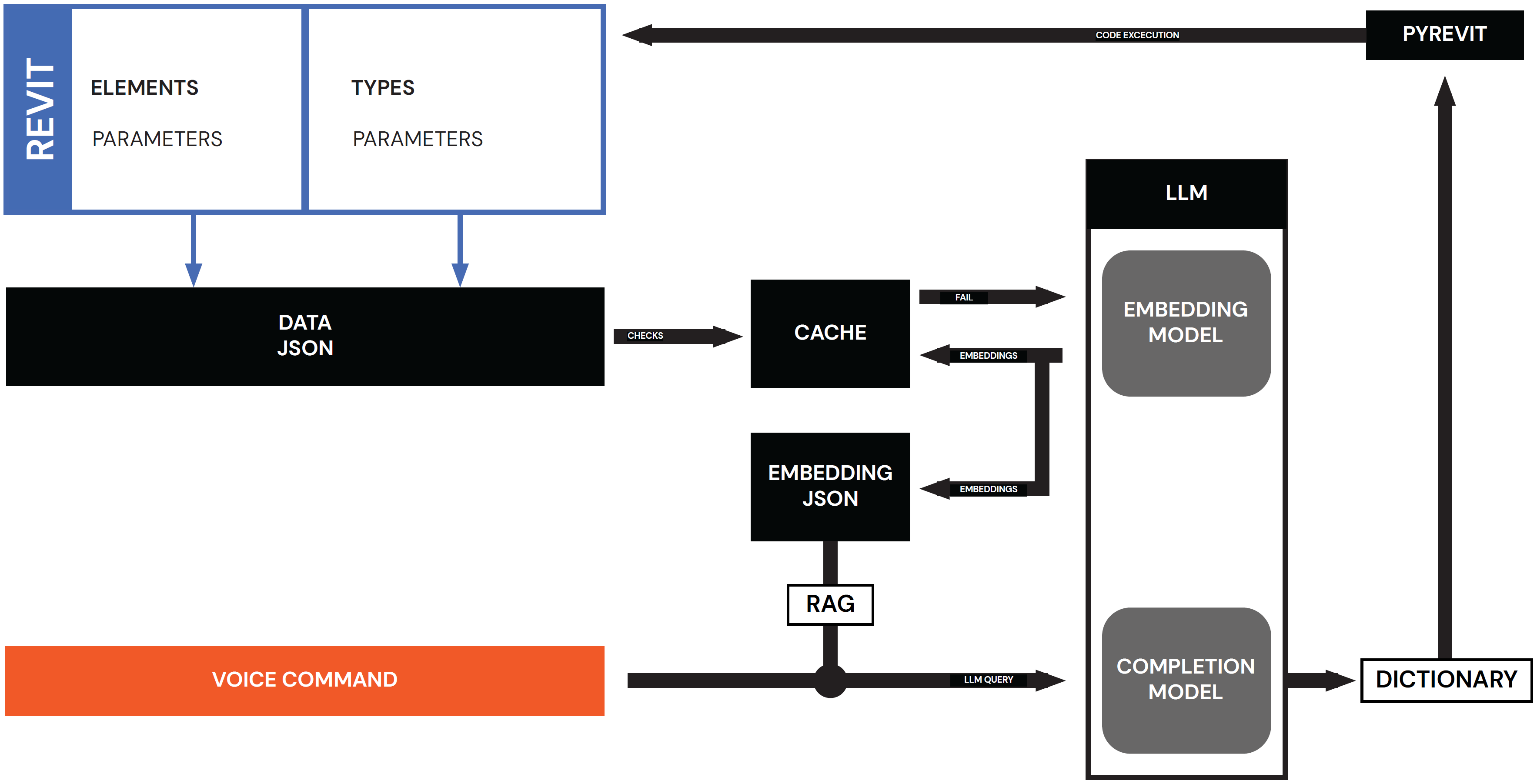
An alternative to using a tokenizer to identify variables, we can also use a Large Language Model (LLM). Rather than manually specifying keywords and actions, we can utilize an LLM such as Ollama or Mistral with Retrieval Augmented Generation (RAG) to identify and or key words within the Spoken Prompt.
For the Revit file to be used as a RAG database, relevant element data is extracted and stored in a JSON file. Each element is treated as a chunk of text in for the RAG. These chunks are then processed by the embedding model and stored in memory cache. This caching system prevents repeated texts chunks from being sent to the embedding model. Finally, the LLM uses RAG to create the dictionary used to edit the Revit elements.
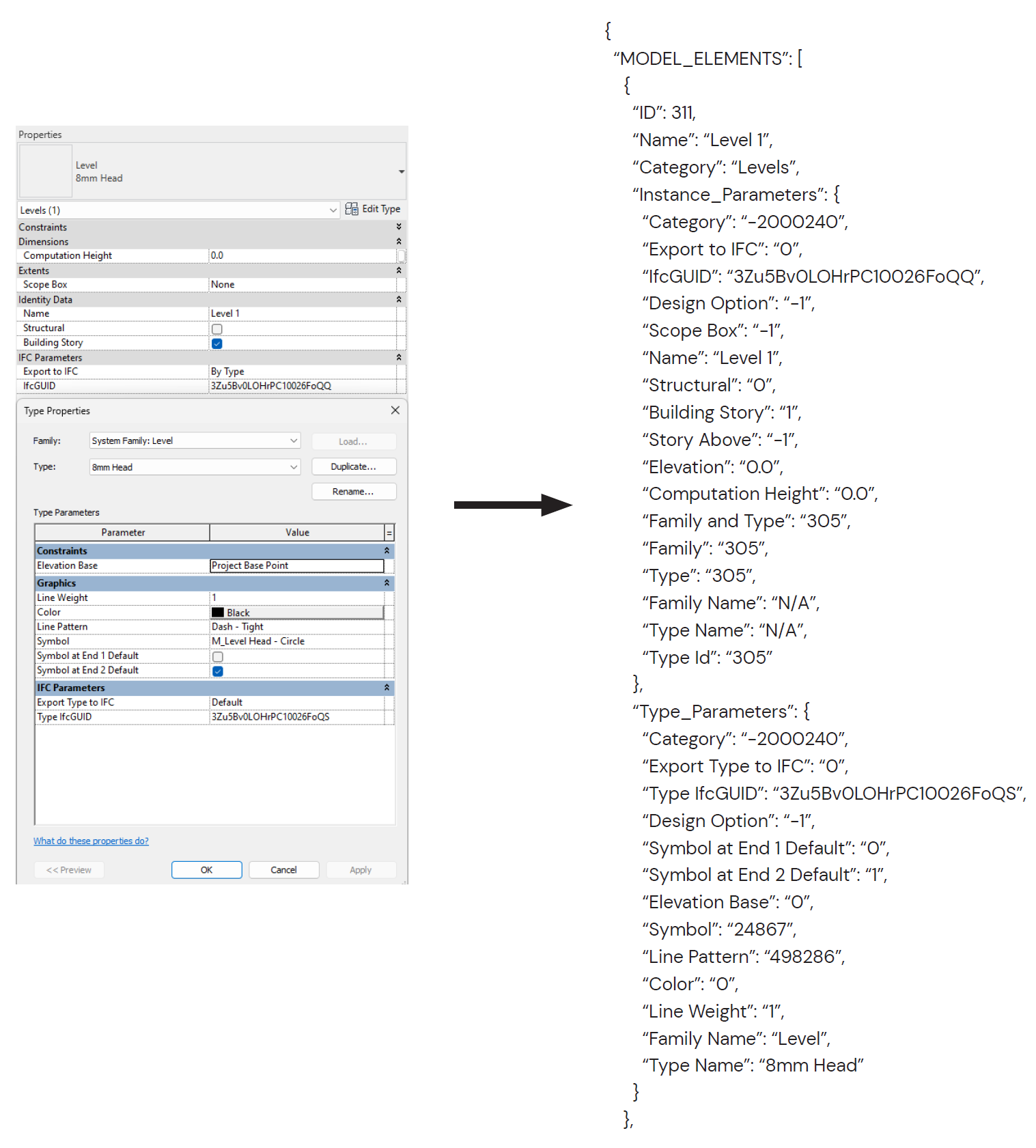
When exporting elements into JSON format, the script extracts all of the element’s instance and type parameters as well as important identifiers such as it’s ID and Name. This allows for easy retrieval of data later.

Here is an example of the data before and after the vector embedding process.
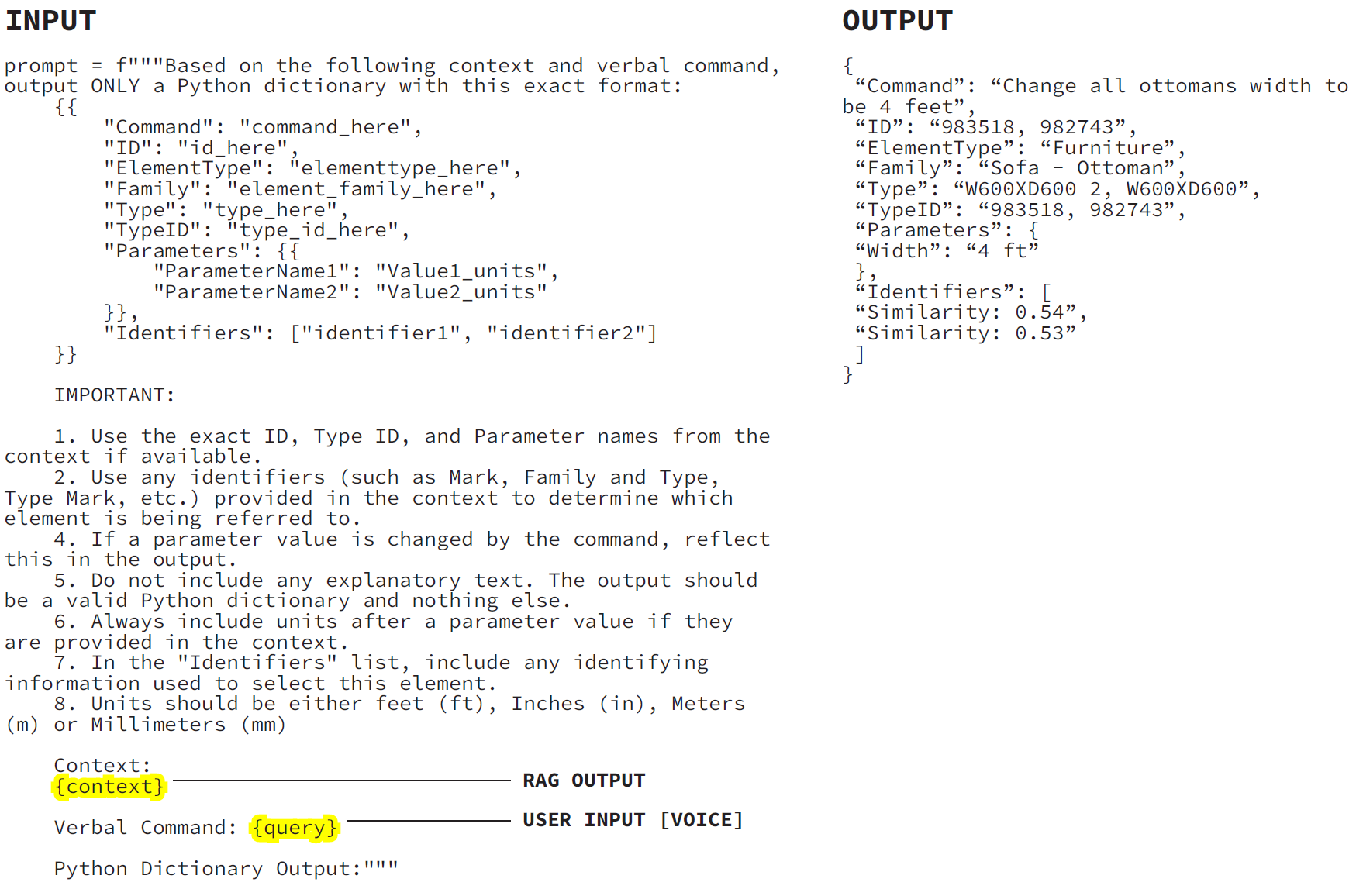
The prompt on the left is the current version that produces the required dictionary for editing Revit elements. It includes instructions on how the format the dictionary and what information to look for within the context. Above the an example of a dictionary output by the LLM.
Revit

The process of running the dictionary within Revit relatively simple. It finds the right elements using the ID’s in the dictionary looks for and exchanges the parameters specified by the dictionary.
Comparisons
While both the Tokenizer and LLM /RAG methods of Voice-to-Command within Revit proved successful, they come with their own use cases, advantages, and disadvantages.
Python code utilizing NLPs such as nltk and spaCy are mainly beneficial for adjusting universal parameters such as: Width, Height, Length, Offset etc. More complex parameters with specialized characters and complex tasks often lead to errors. Starting with the first tested approach, the Python Tokenizer utilizing nltk; The primary benefit of this approach, was the fact that it performed significantly faster when executing a spoken command. However, while the Tokenizer performed actions with incredibly high speeds, it was heavily reliant on a high level of detail and precision when defining words to act as tokens within spoken prompts. In addition, the token method often struggled with specialized parameters; Because this method used patterns and token words, variations to these spoken prompts might cause incorrect commands to be executed.
When considering the LLM approach combined with RAG searches, this method is preferred for complex tasks that the Tokenizer cannot handle. This is due to the use of the LLM and its extensive knowledge of predefined language. The key two advantages of the use of LLM and RAG are flexibility and complexity; Because the LLM does not need to use token words defined in the code, it is far more capable in understanding drastically different spoken prompts. Not only is does the LLM provide a deeper understanding of language, it also is able to interpret mispronounced words as well as unexpected synonyms. These two advantages make the Speech Recognition within the LLM model far superior to the Tokenizer method.
Although the LLM / RAG combination offers more complex language understanding, it still comes with its own drawbacks. The main disadvantage being, it is often slower to execute commands than the Tokenizer. In addition to lack of speed, this model often struggles find highly specific data and element IDs, which can leading to inaccuracies and inconsistency.
Additionally, due to RAG’s chunk retrieval processing grabbing only a limited number of chunks, a limited number of elements can be edited at a time. While the number of chunks retrieved can be increased, this significantly slows the LLM’s response time.
Next Steps – Python
There are several steps that could to taken to continue this research thesis in a meaningful and productive process. First, to improve the functionality of the Python Tokenizer model, utilization of an updated NLP system instead of nltk or spaCy could improve the token creation process to allow for a deeper understanding of Spoken Prompts.
Next, the combination of an NLP system with a more limited version of an LLM, specific to construction focused language. This combination could benefit from the adaptability of an LLM, while maintaining its speed when executing spoken commands.
Next Steps – LLM
While the Python improvements are somewhat simple and straightforward, the LLM model will require more in depth exploration. First, the model simply needs to be fine tuned to improve the accuracy of the output. After model tuning, the LLM process could substantially benefit from improved prompt engineering. Tweaking the overall prompt that is fed into the LLM model may produce more consistently accurate results. The LLM process may also be improved upon by testing with different LLM models. Currently, Ollama and Mistral have been used to test as database models for the LLM. However, there may be models that are substantially better suited for the use case of Voice-to-Command within Revit. During the scope of the thesis, experimentation was greatly limited by computer speed and resources. In addition to a new model, improved machinery would enhance the capabilities and speed of the command execution.
Additionally, writing the code in C# rather than Python could speed up the process. Revit is built on the .NET framework, meaning the Python code needs to be run through an interpreter (IronPython). Translating the code from Python to C#, .NET’s native programming language, would result in faster run times.
Finally, the implementation of a multi-threading caching process would drastically reduce the required time to execute commands via the LLM model. Specifically, using multiple CPU threads to checked the cached vectors would likely decrease the required time to run.
