
This project is the final submission for our Data Encoding course, where we learned the fundamentals of Machine Learning. For this project, we were required to use only numerical features, meaning all training data for our Machine Learning model had to be in numerical form. This involved encoding architectural and spatial features into numbers.
“Daylight Factor Predictor” is an advanced analytical tool created to develop a predictive model for daylight factors using the XGBoost algorithm. We used relevant Python libraries such as Pandas, Numpy, Matplotlib, Seaborn, and others required for data handling and visualization. We then loaded and explored the data, performing essential preprocessing steps to clean and prepare it for modelling. We trained and tuned the model, including hyperparameter optimization, to enhance its predictive performance. We evaluated the model’s accuracy and effectiveness in predicting daylight factors using detailed visualizations and performance metrics. To conclude, we provide insights and potential implications of the predictive model, emphasizing its applicability in real-world scenarios related to architectural design and energy efficiency.
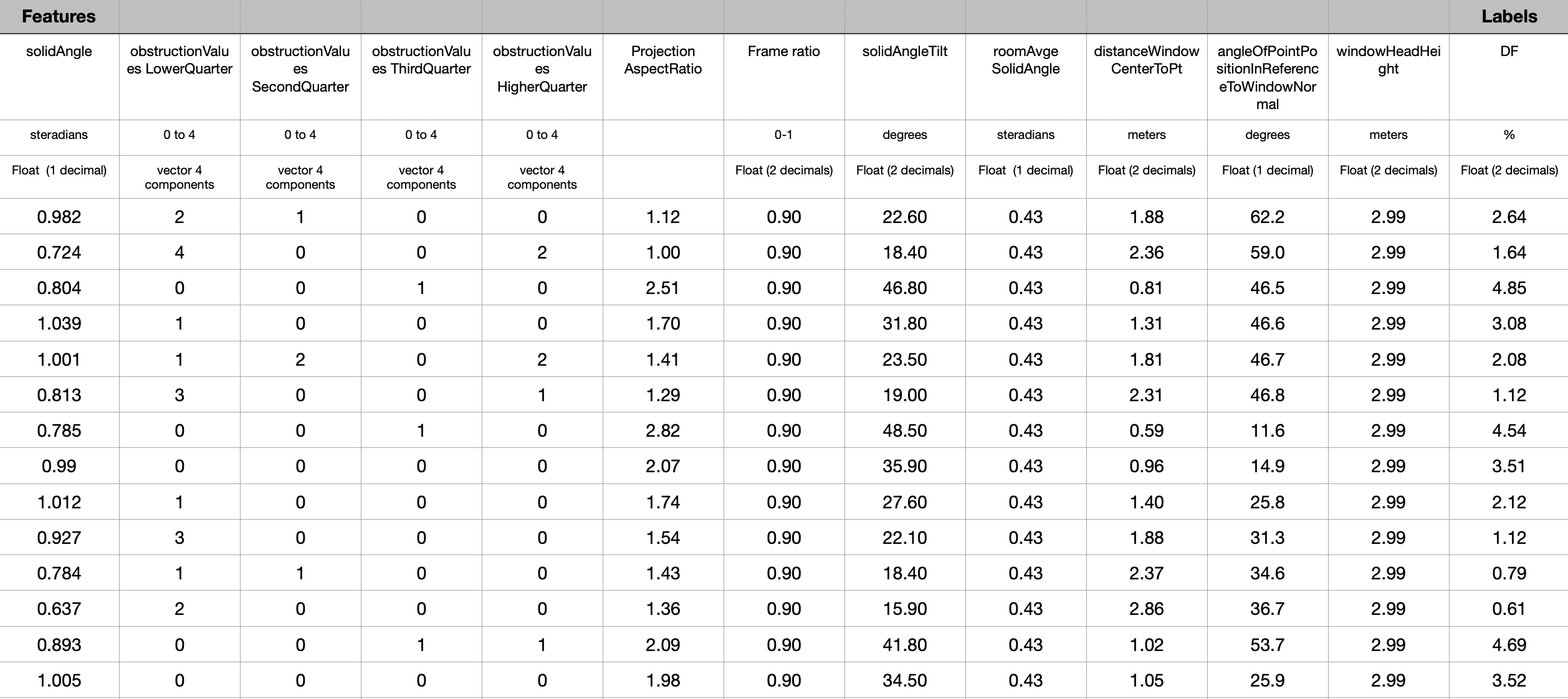
Due to its simplicity, we developed a model to predict the daylight factor instead of other daylight metrics. It ignores direct sunlight and factors like latitude, orientation, or climate. It represents a worst-case scenario under completely cloudy skies, making it suitable for evaluating daylighting in countries lacking daylighting in winter, focusing on the health and well-being aspects, such as Nordic countries and the UK, which have high latitudes.
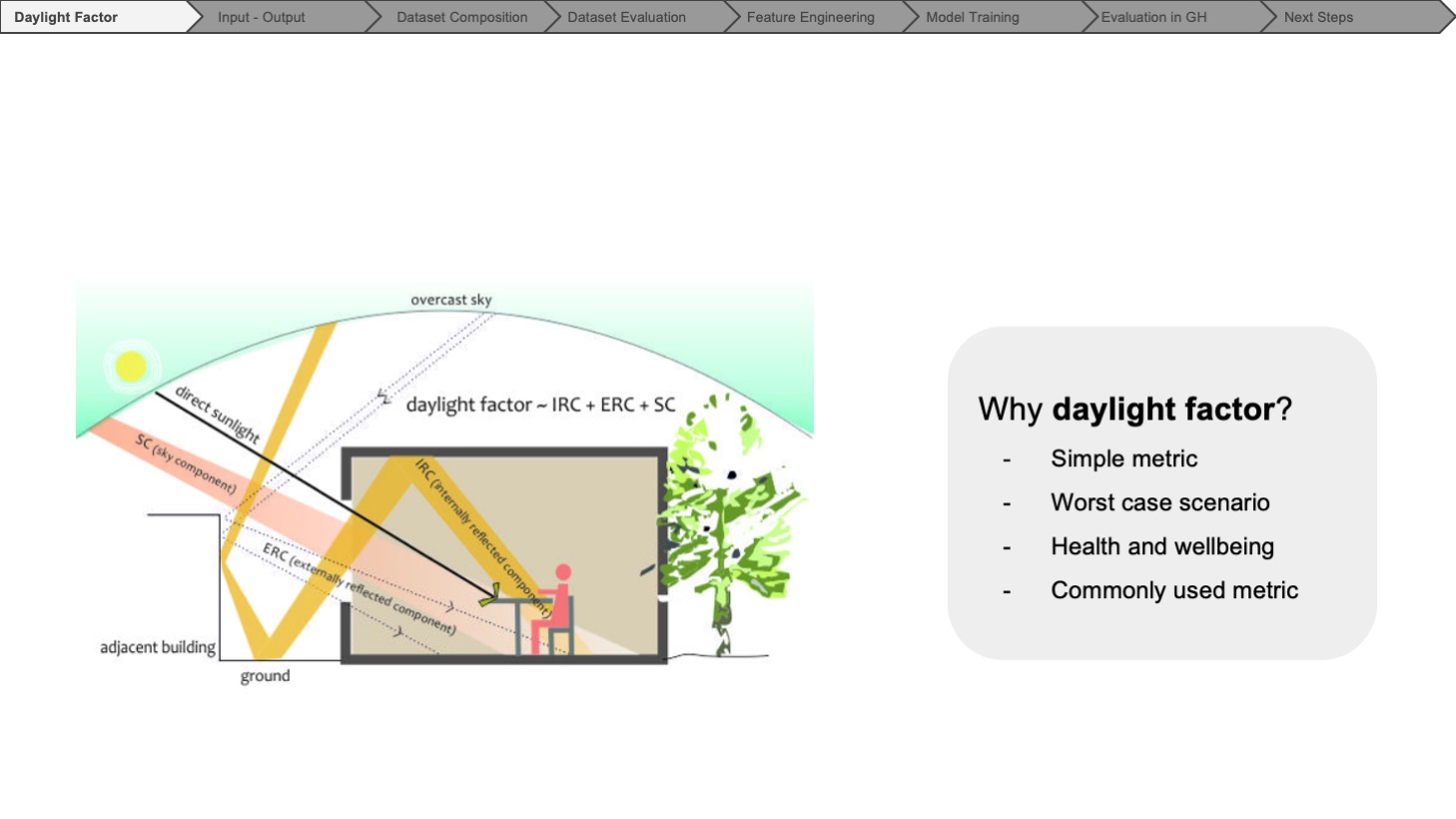
In Sweden, rooms must meet a minimum 1% median daylight factor. This diagram compares compliance across different building typologies from various decades, revealing that denser urban planning results in fewer rooms meeting this requirement in recent years. Since 2016, compliance with this standard has been mandatory, leading to challenges as specialists and architects collaborate to ensure compliance, which could be more efficient and require many cumbersome iterations. There is a need for integration into architects’ design software to provide real-time feedback on daylight compliance.
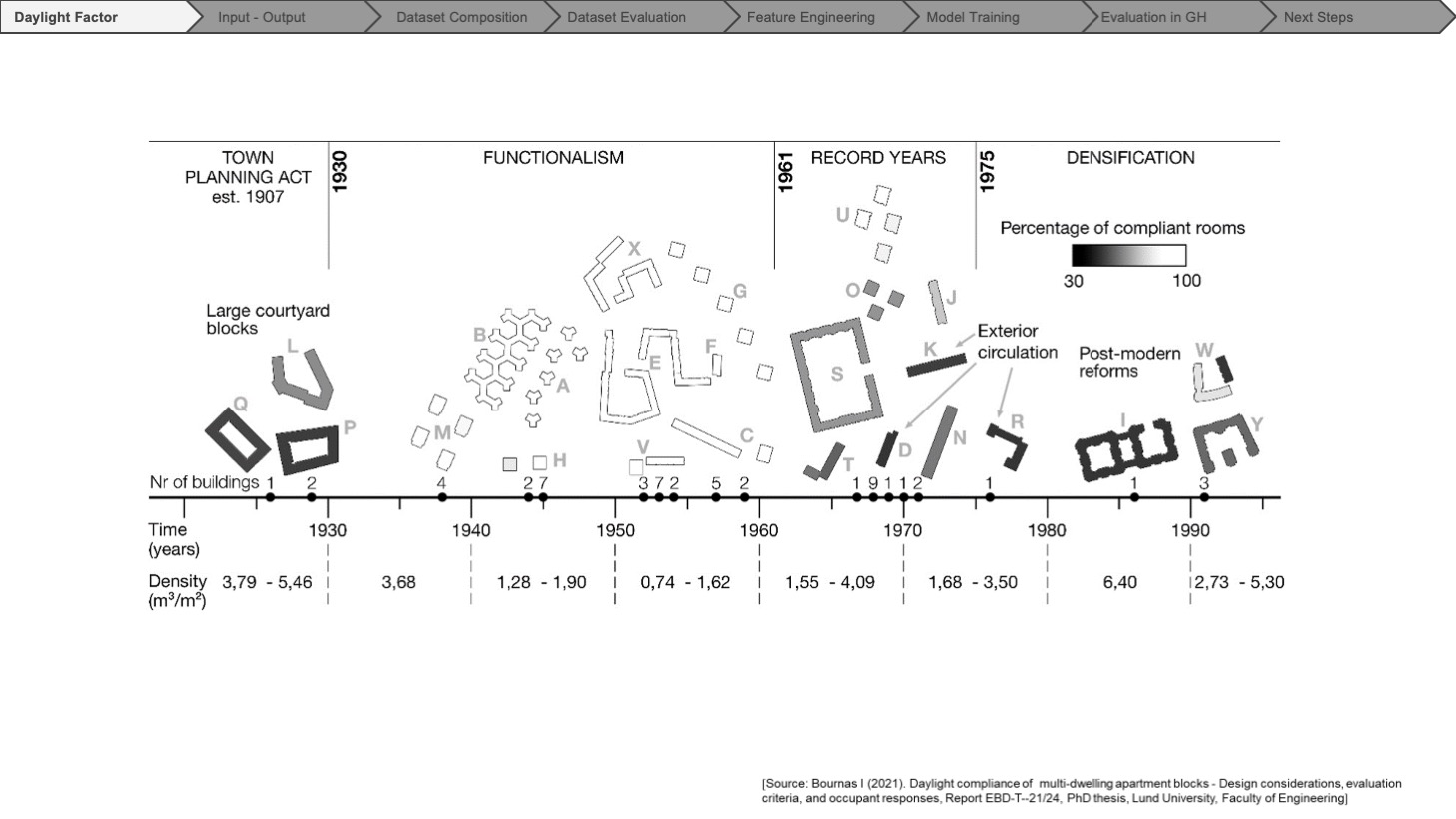
INPUT-OUTPUT
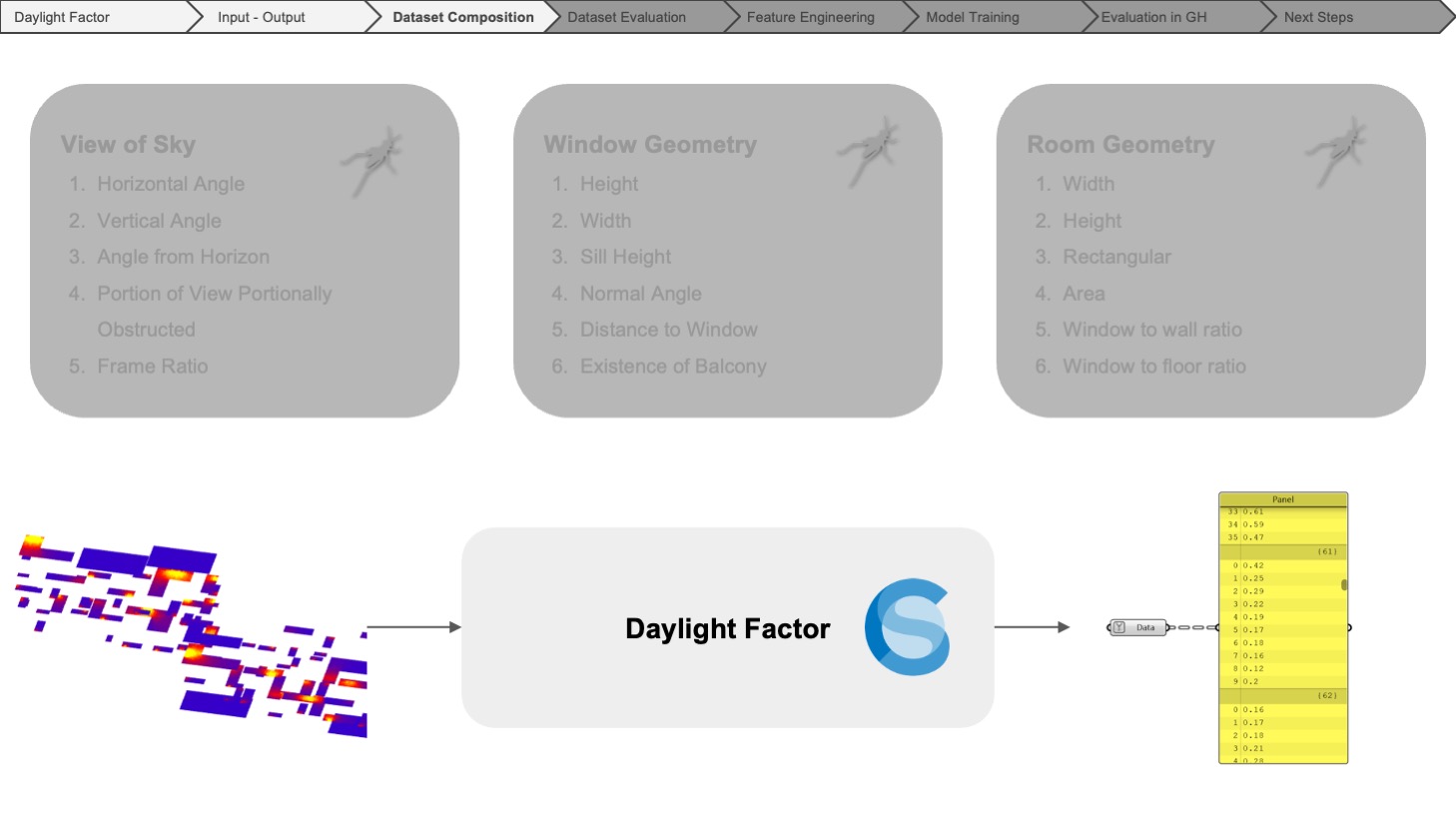
We started by identifying all the possible parameters that could be used for the prediction and categorized them into three groups: view of sky, window geometry, and room geometry.
DATA COMPOSITION
Then, we started the process of dataset composition with the Climate Studio analysis files that we obtained as a courtesy of White Arkitekter.
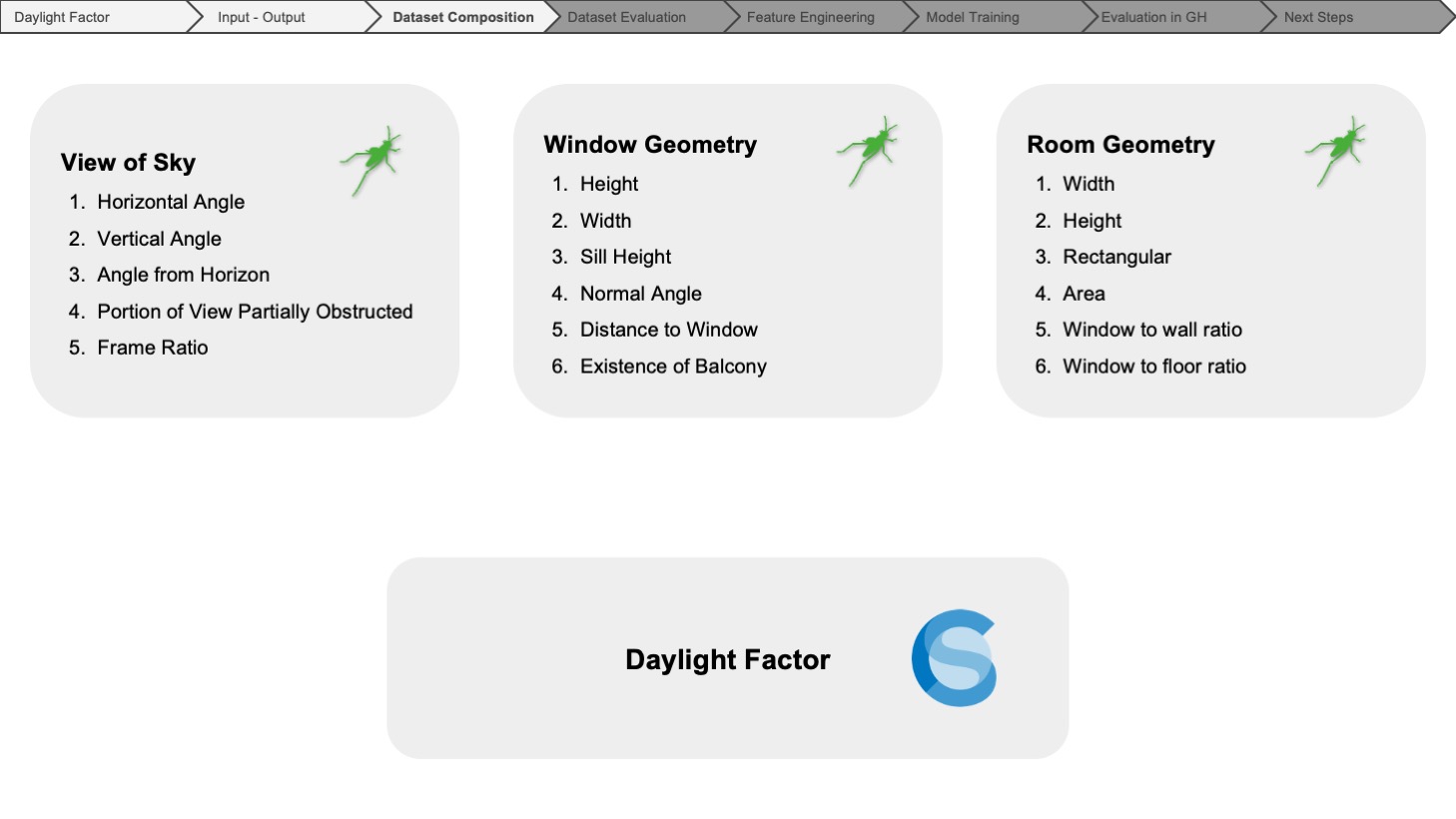
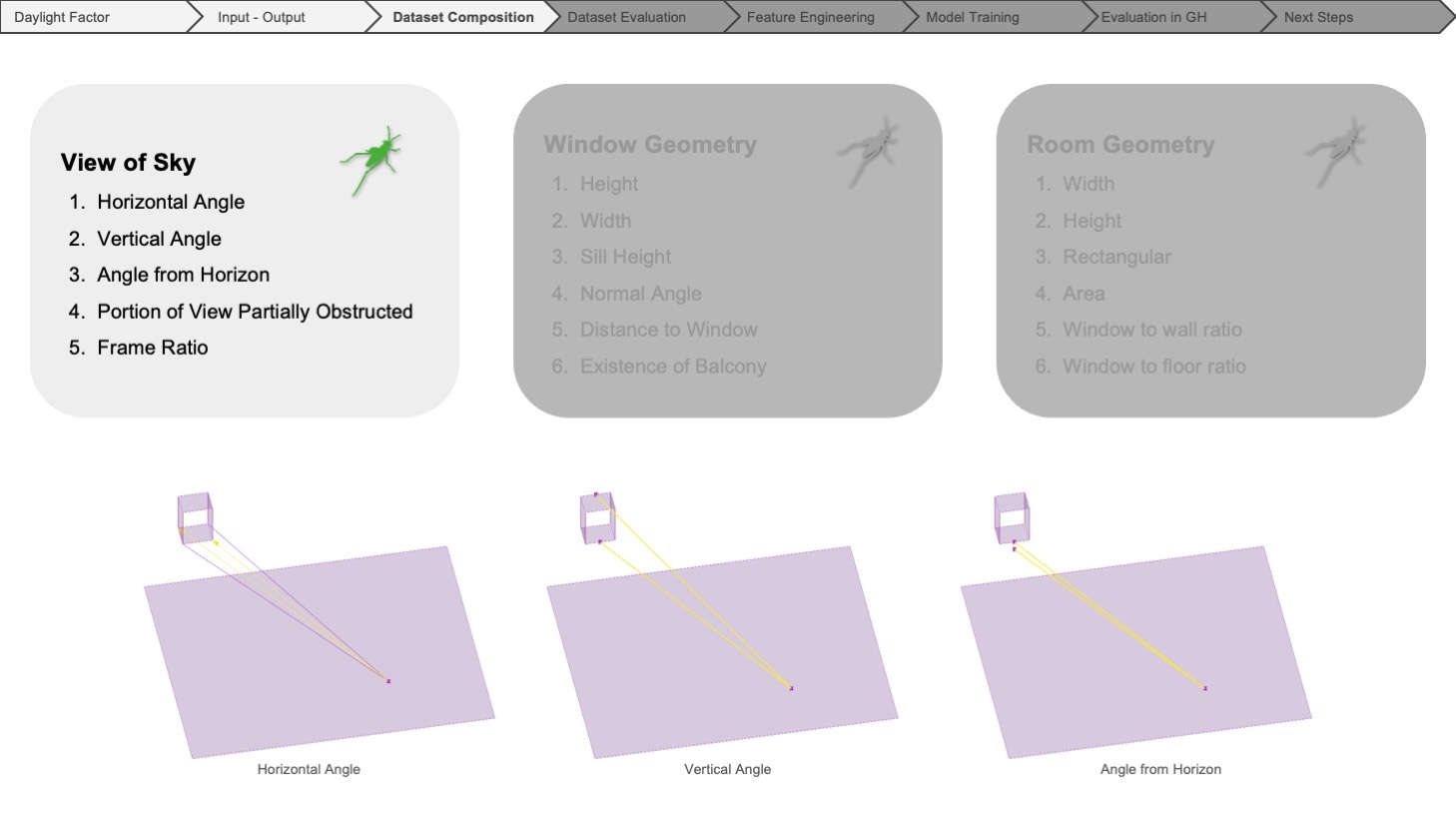
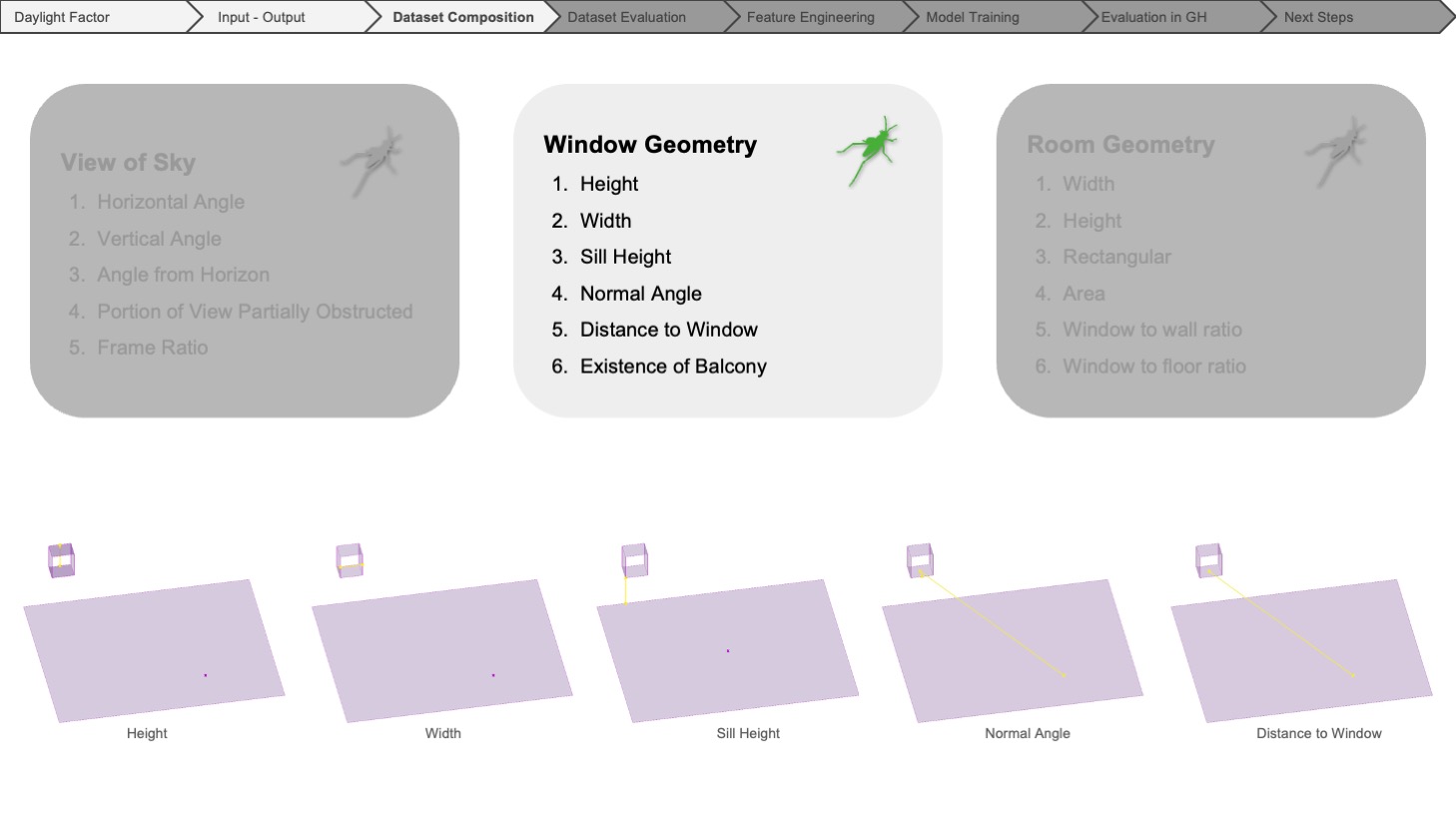
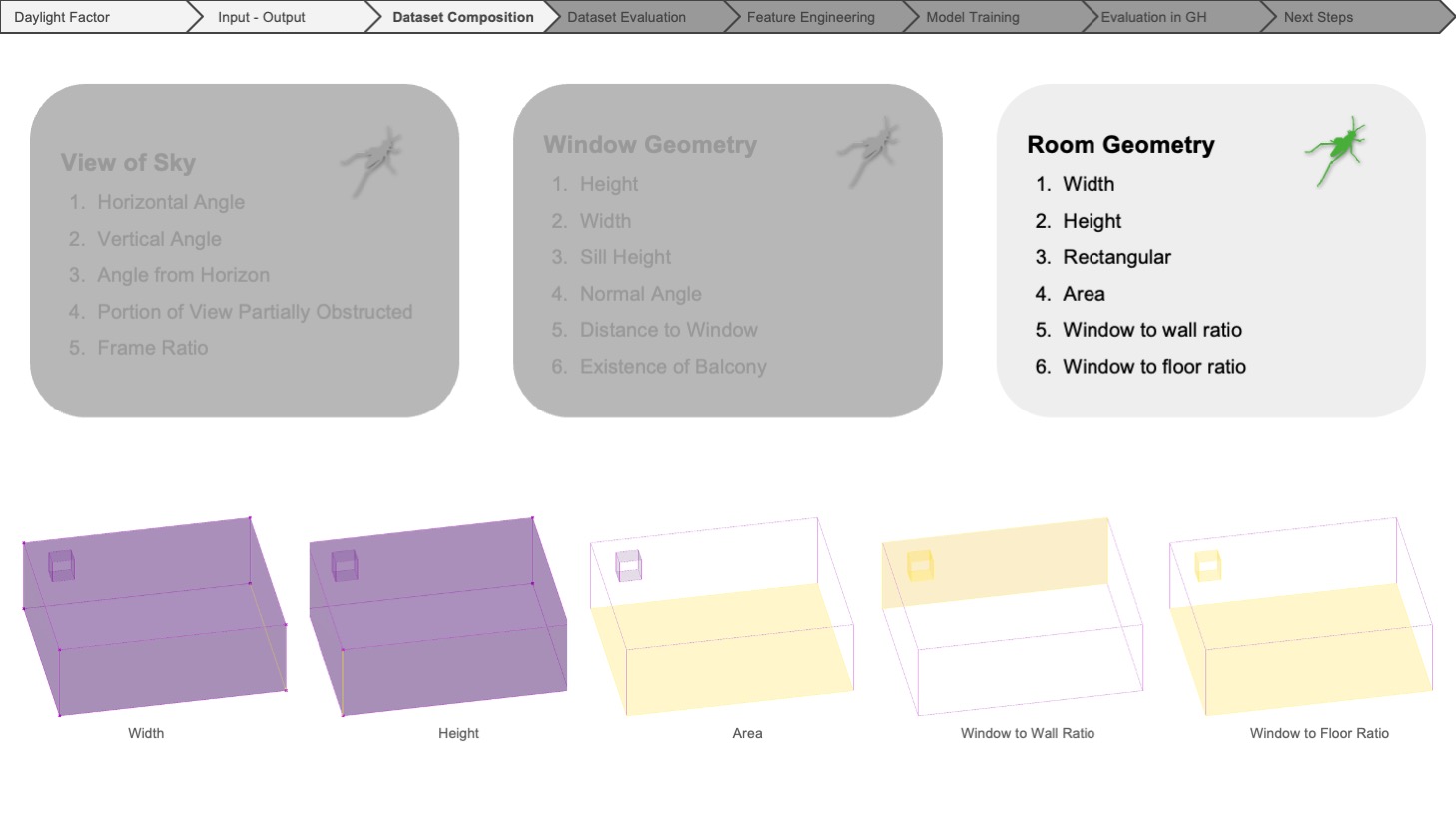
For all the input features, we utilized Grasshopper to measure the angular and vectorial information regarding the view of the sky to get the basic measurements of the window geometry, also the properties relative to the specific simulation point belonging to the grid and finally, the dimensions of the room and the ratio of the window geometry to the room geometry.
For the output, which is the daylight factor, we leveraged ClimateStudio in Rhino.
DATA EVALUATION
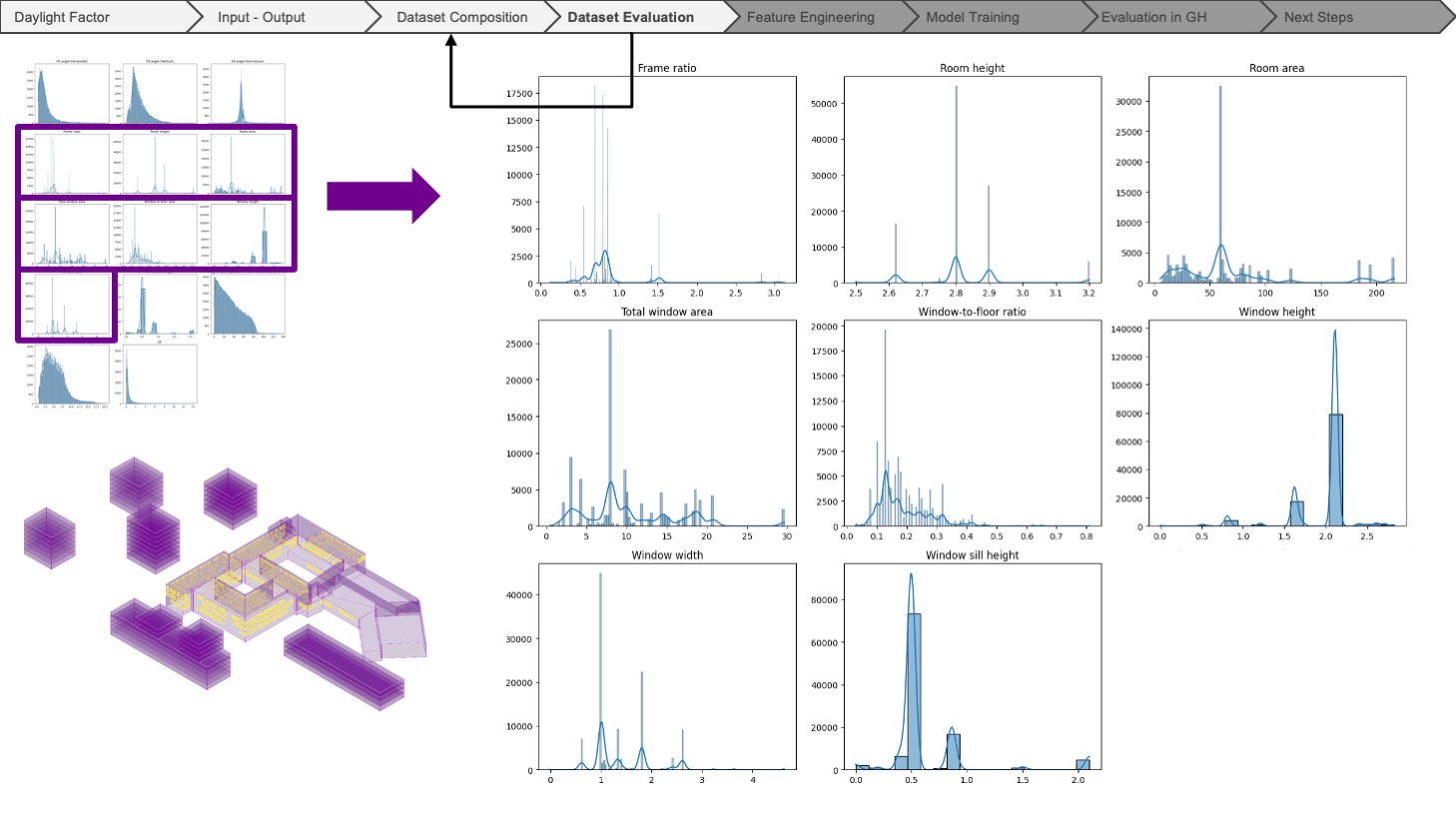
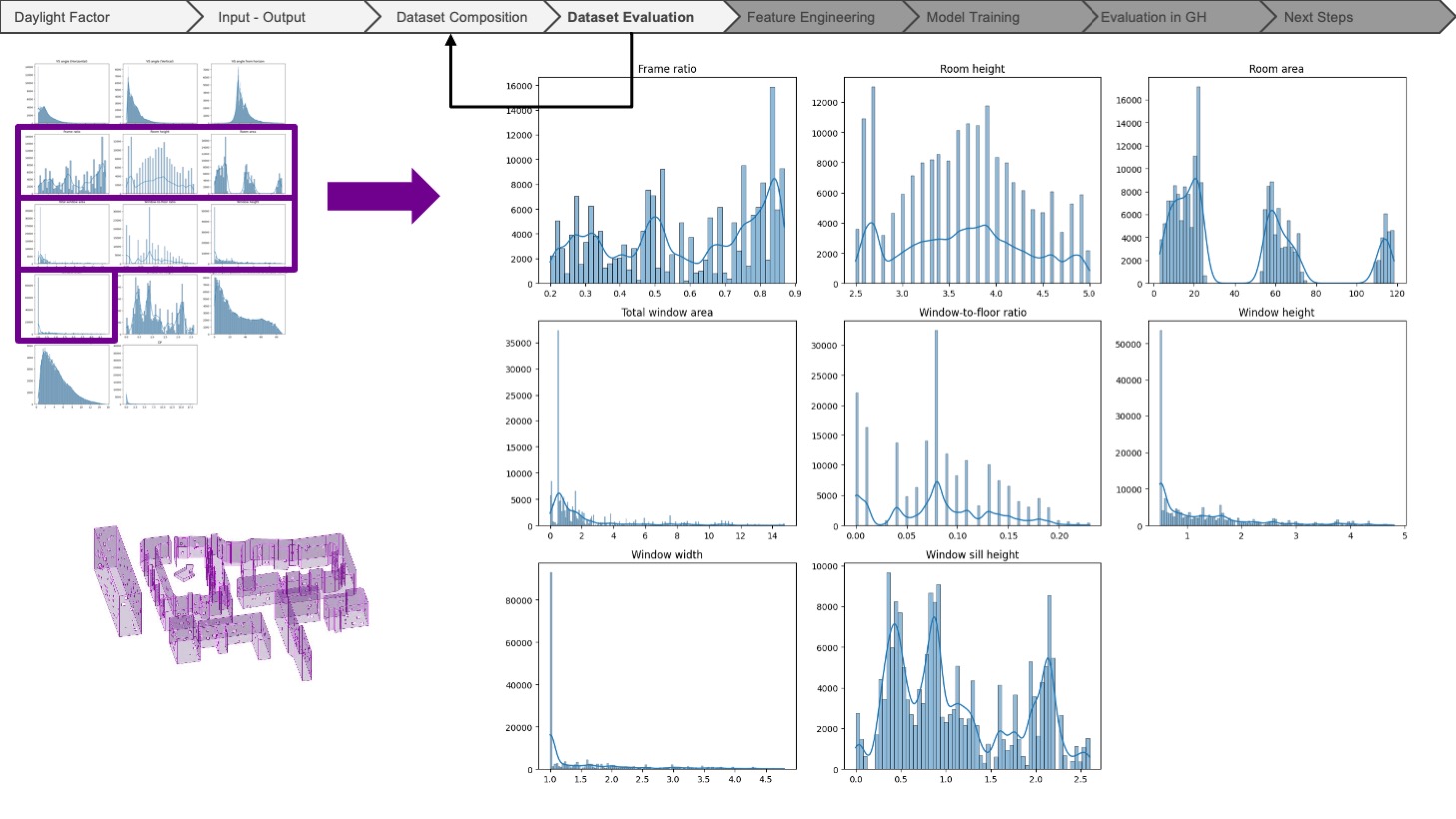
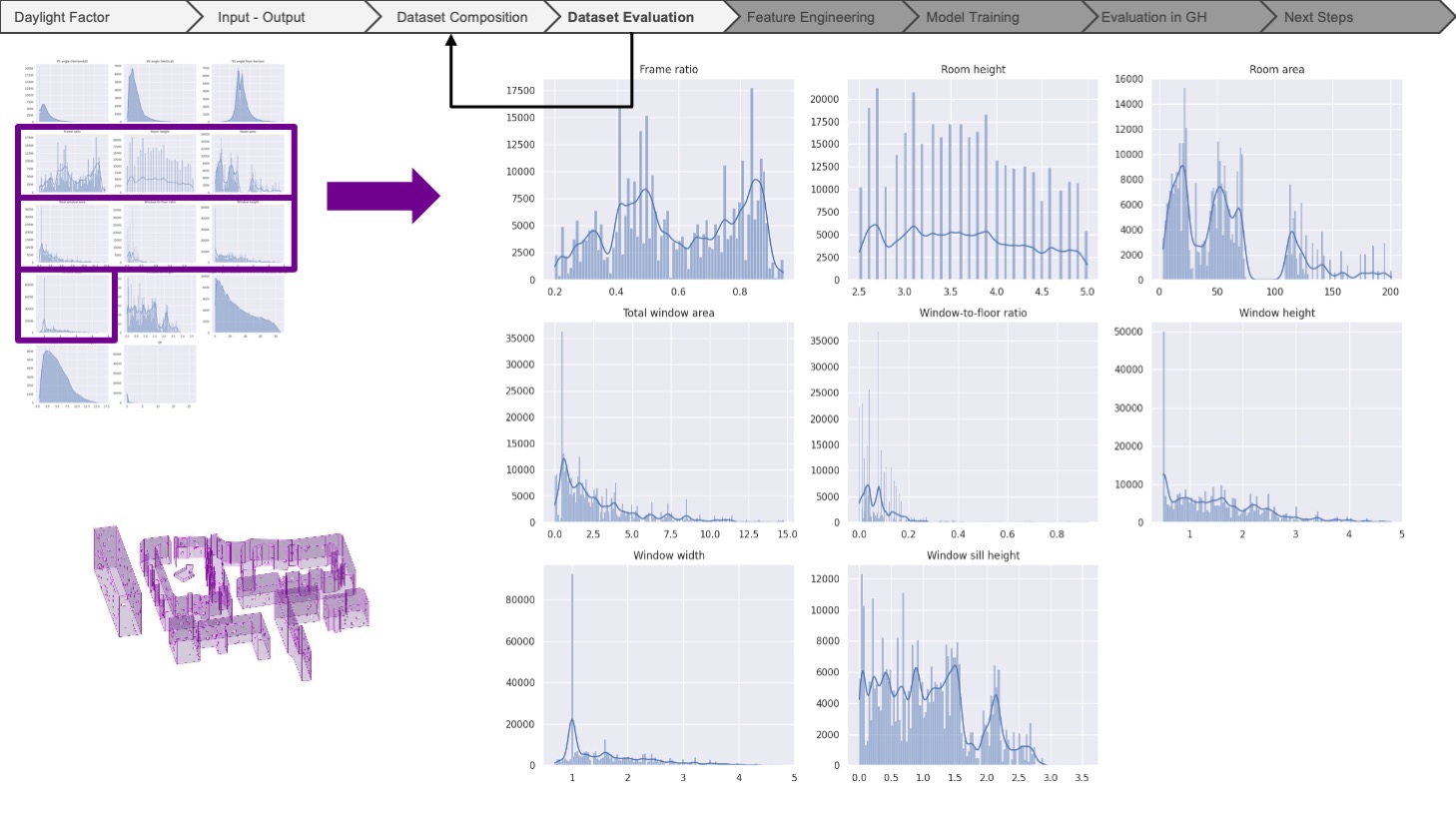
After completing the dataset, we evaluated the data by plotting the histograms for each feature. Unfortunately, we could not find enough variety in the geometrical features. At this step, we went back to the previous stage of dataset composition and concluded that the real models do not provide enough variety for the model to understand how each feature affects the output. Then, we changed our dataset by using synthetic models, in which we tried to achieve randomness and variety throughout the features. Again, we compensated for these slight imbalances by adding more synthetic models with the geometrical features we wanted.

FEATURE ENGINEERING
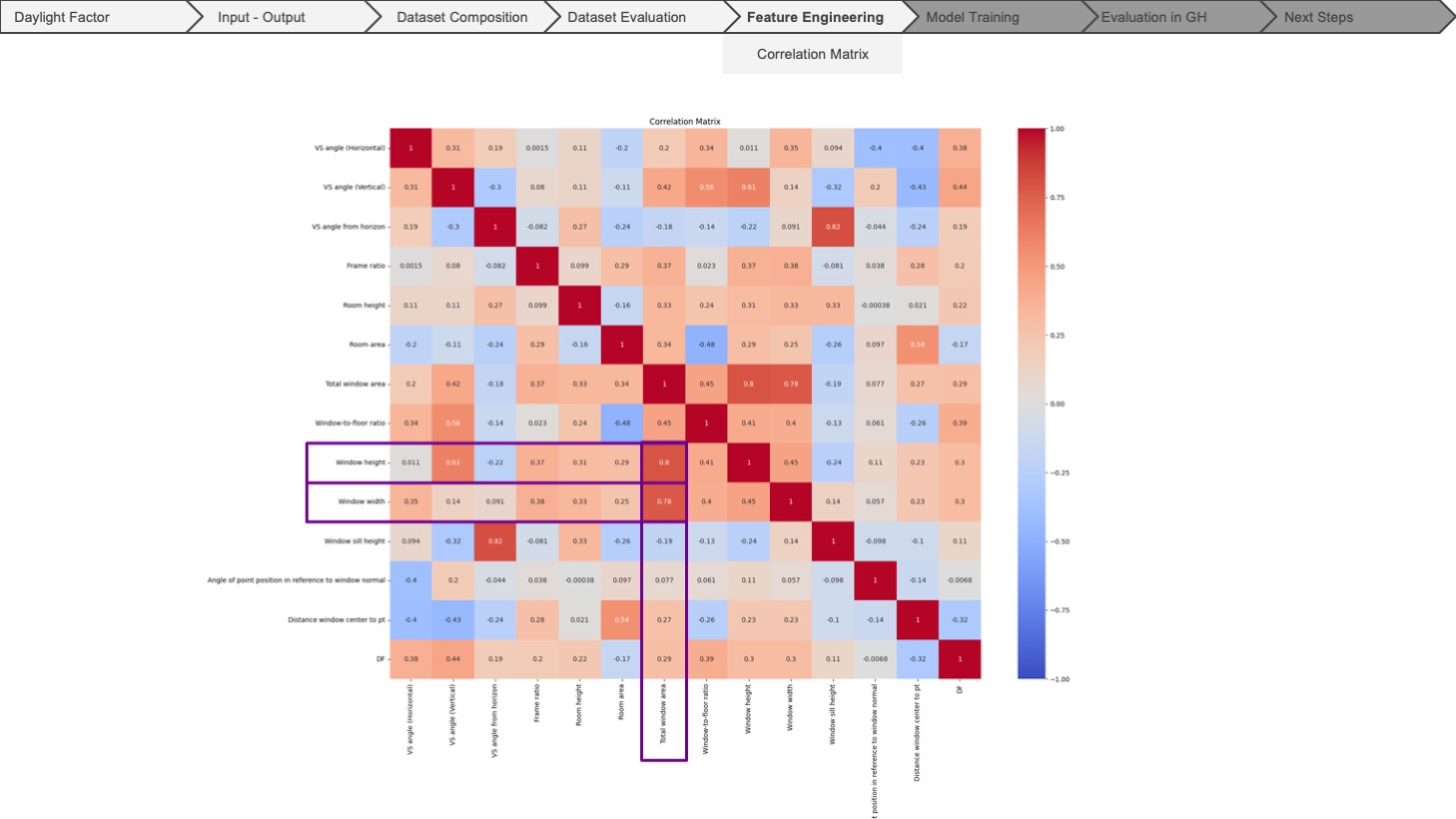
Next, we moved on to analysing our features to see the correlations between them. After generating the correlation matrix, we ran into only a few very high correlation values, which are obviously the dependent features, such as the window height, width and the total window area.
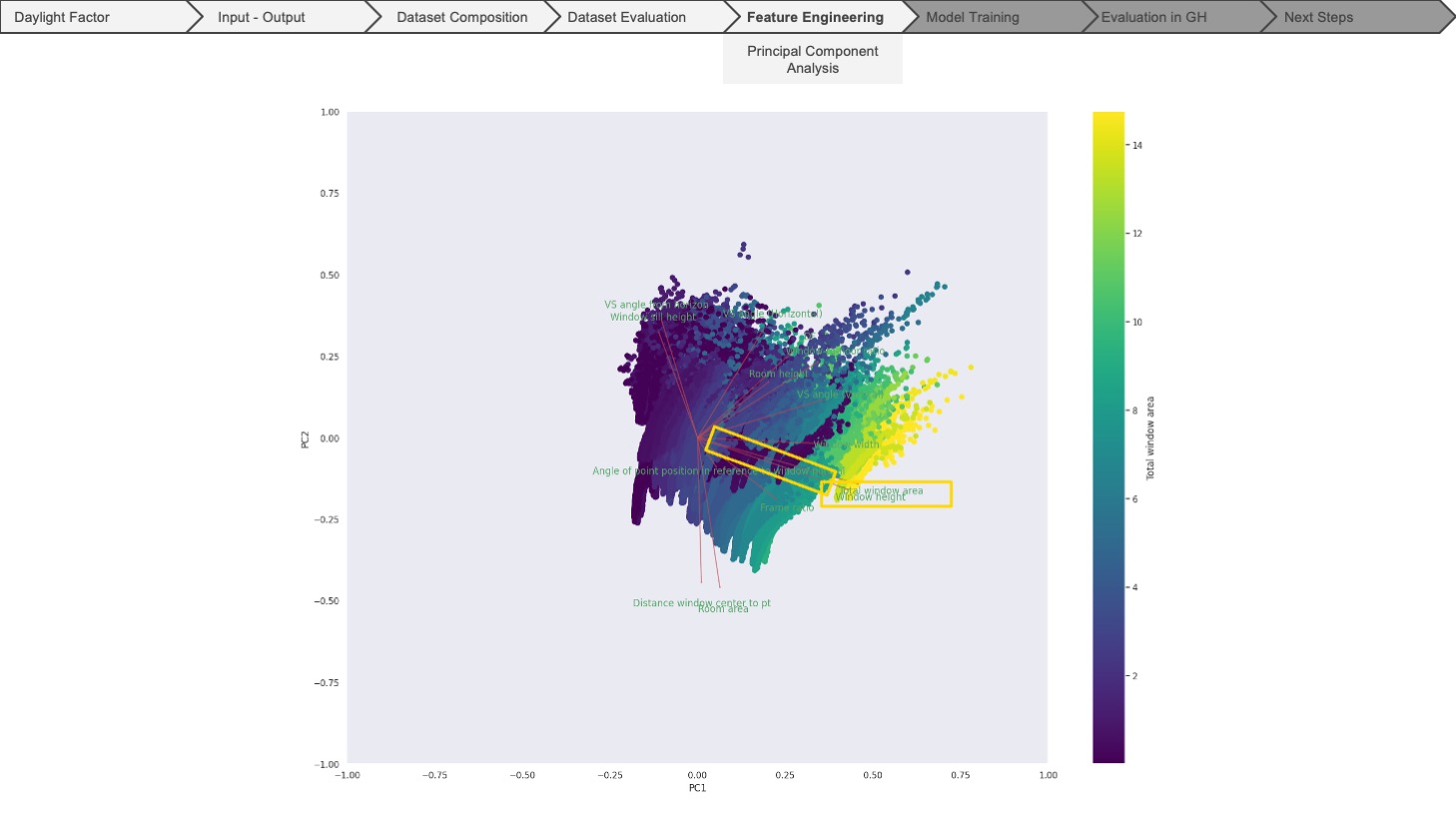
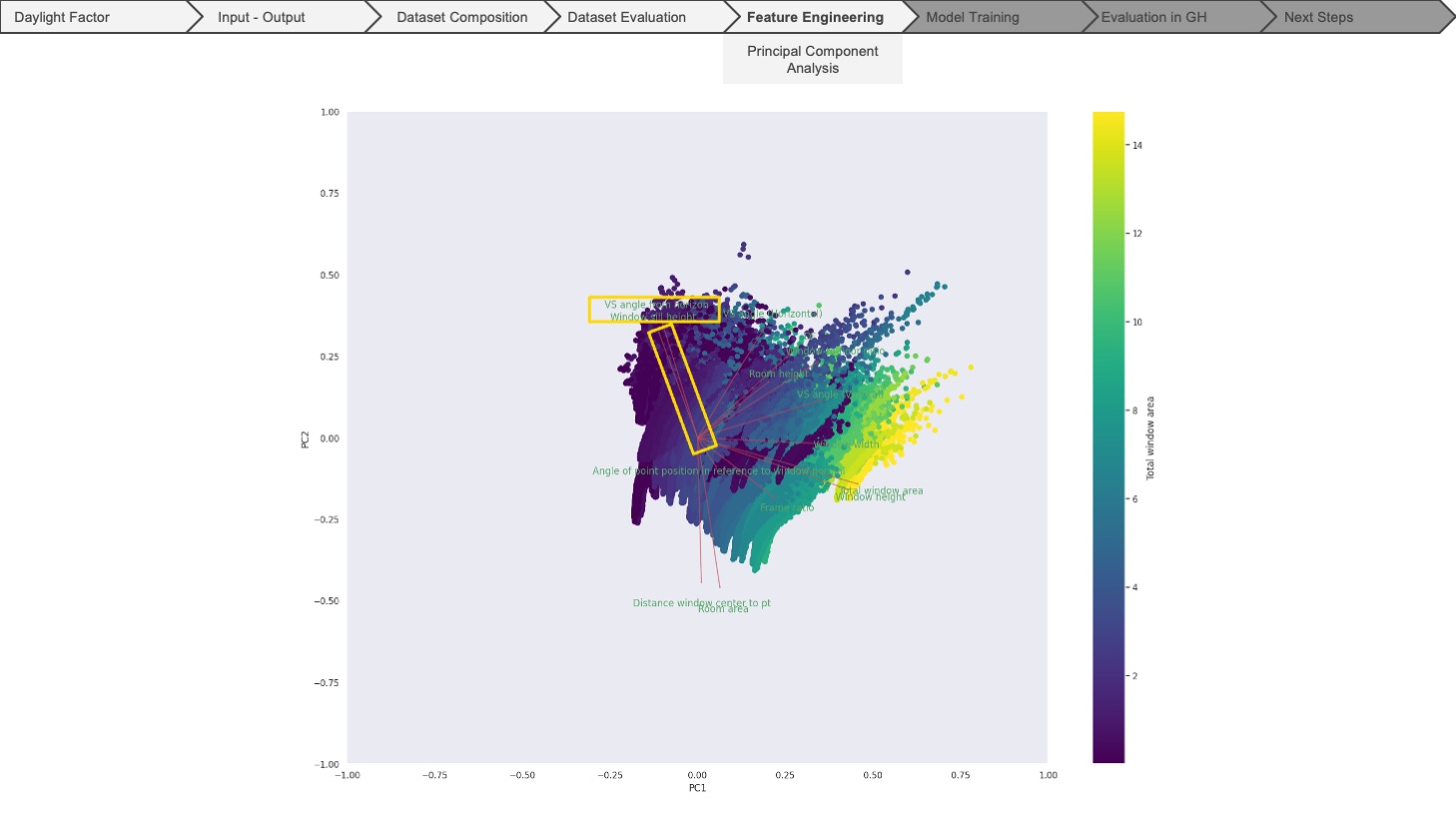
At this stage, we also ran the principal component analysis to see the directions in which our data varies. Looking at the PCA plot, we can again see the dependent features, which are very much related to each other, giving us an idea about which features to include or omit for the model training.
MODEL TRAINING
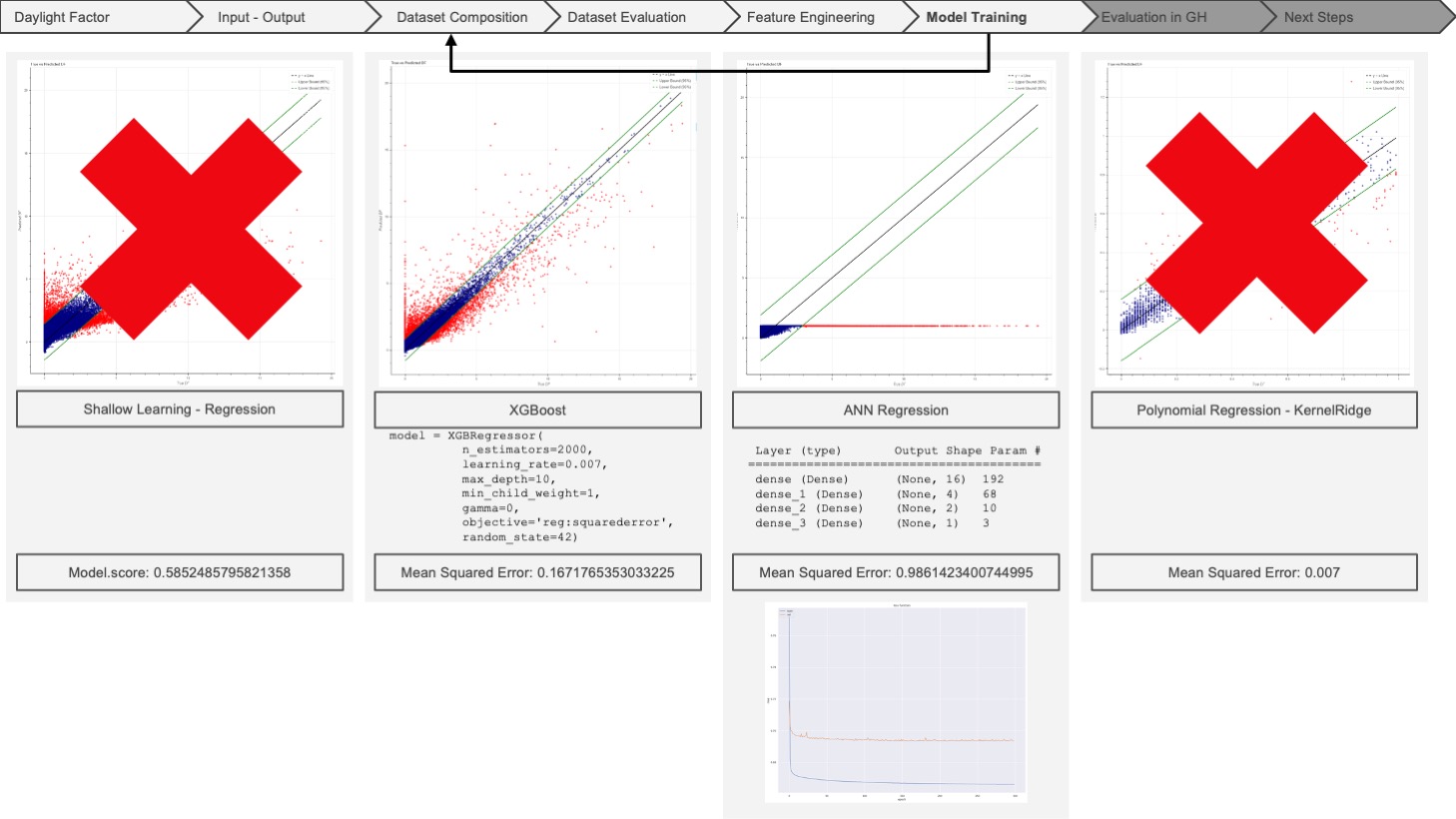
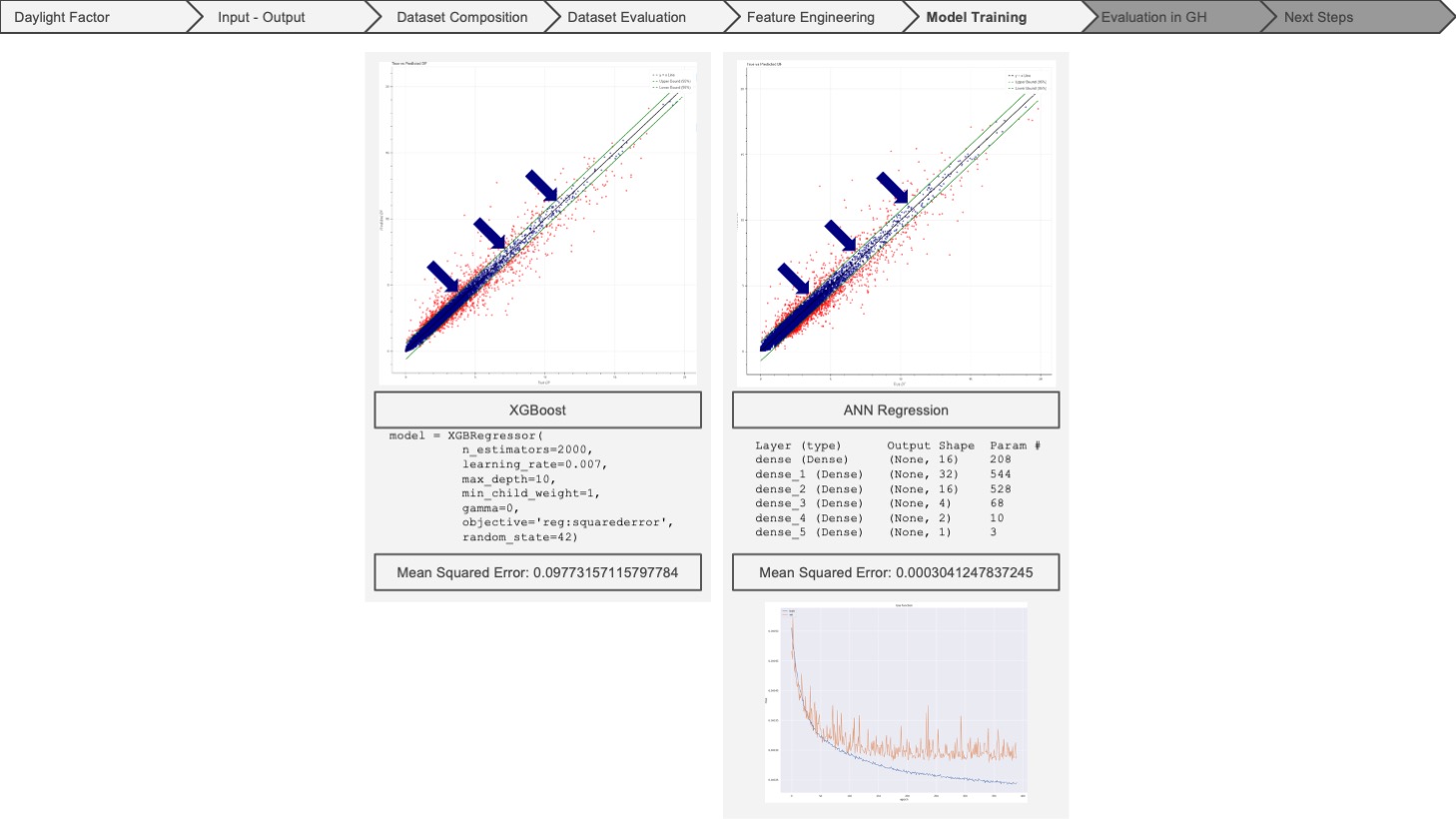
After training four types of models for learning, we had the chance to compare their accuracy and eligibility to our dataset. Apparently, the shallow learning model did not comprehend the complex relationships between the features. XGBoost gave us a diagonal trend in the y_truth-y_predicted graph but still lacked accuracy. ANN regression could not be predicted within the proper scope, and finally, polynomial regression seemed to understand the complex relations. However, it could not handle the vast amount of data. Even though we eliminated shallow learning and polynomial regression models, we were still not satisfied with the results of XGBoost and ANN. So, we took a few steps back to question our dataset composition at this stage.
Here, we focused on reducing the number of features and refining them so that they would better express the effect on the output, which is the daylight factor. For this reason, we eliminated features regarding the room and window geometry and focused on the view of the sky and the exact relationship of the point with the surroundings.
The view through the window is the most critical feature, as it is quantified by its solid angle. It is measured by projecting the visible glass area onto a sphere.
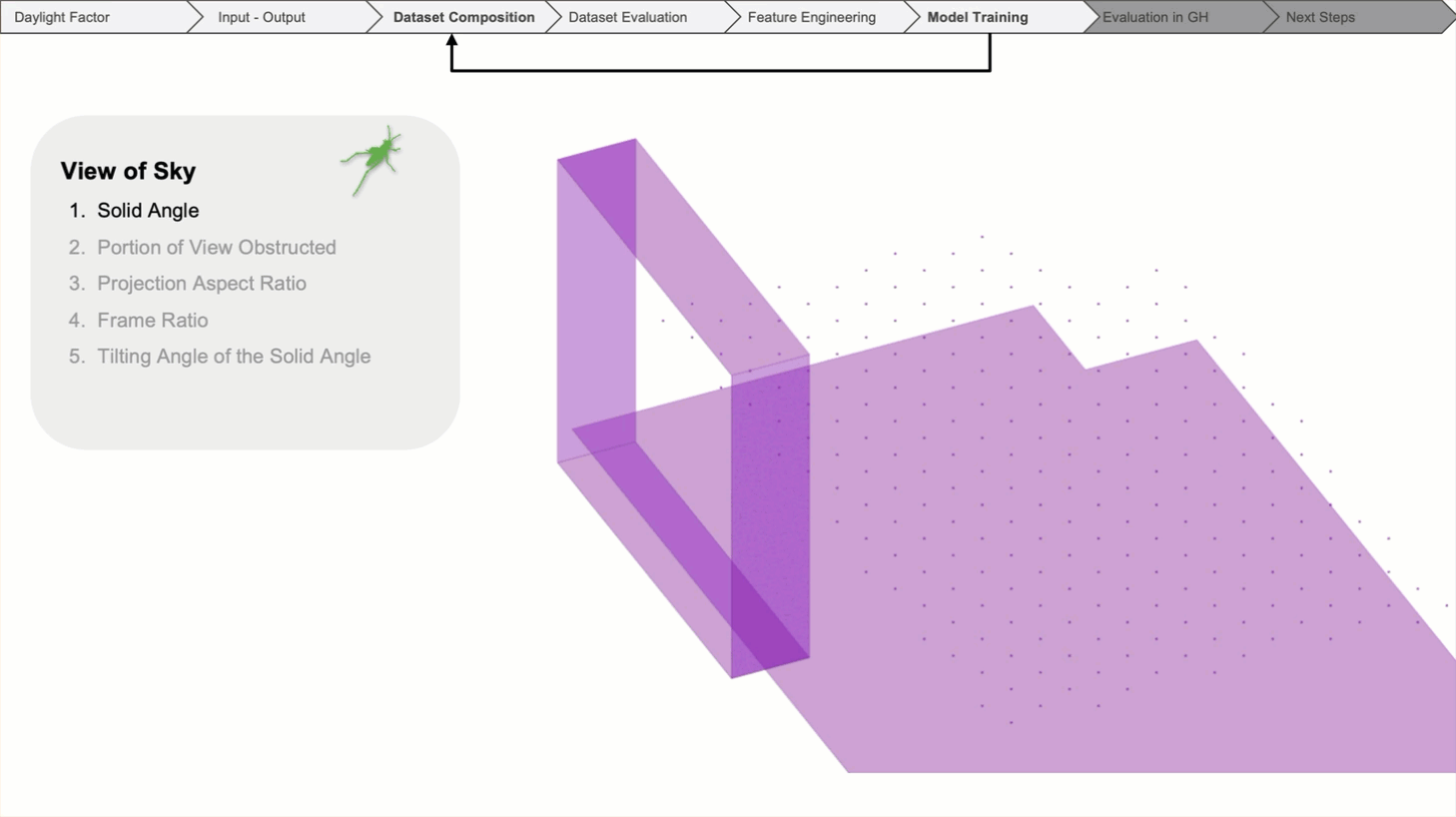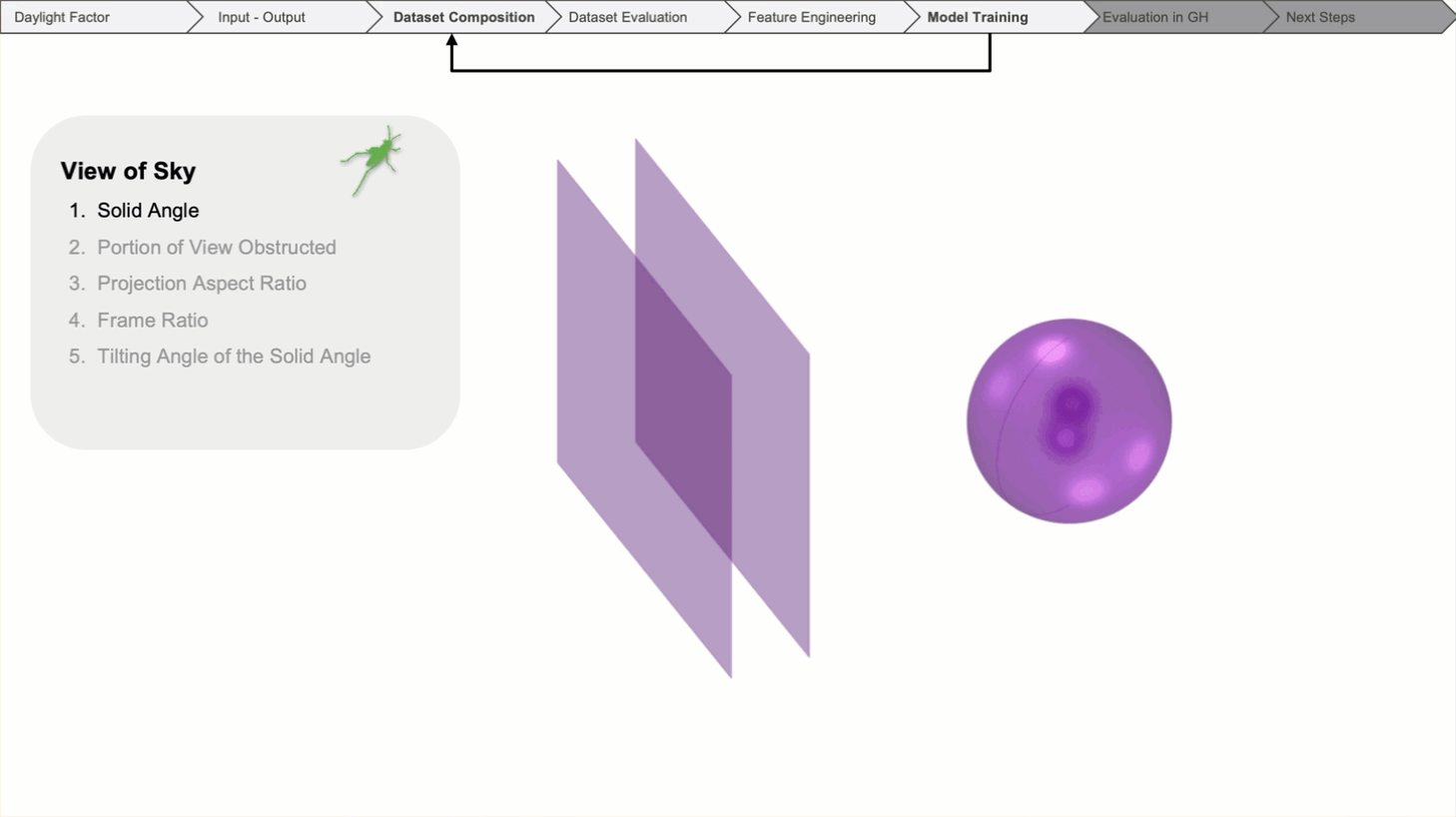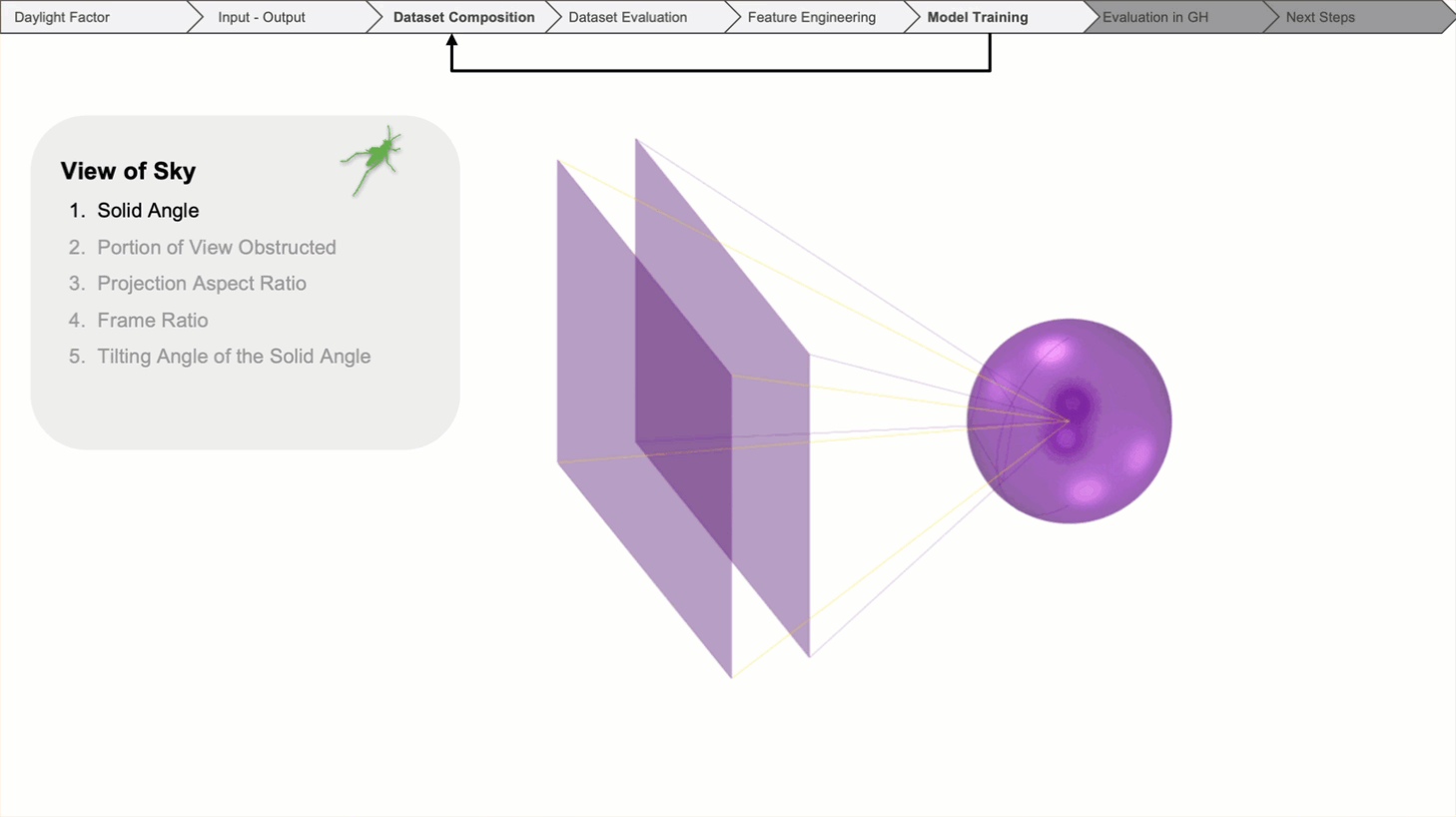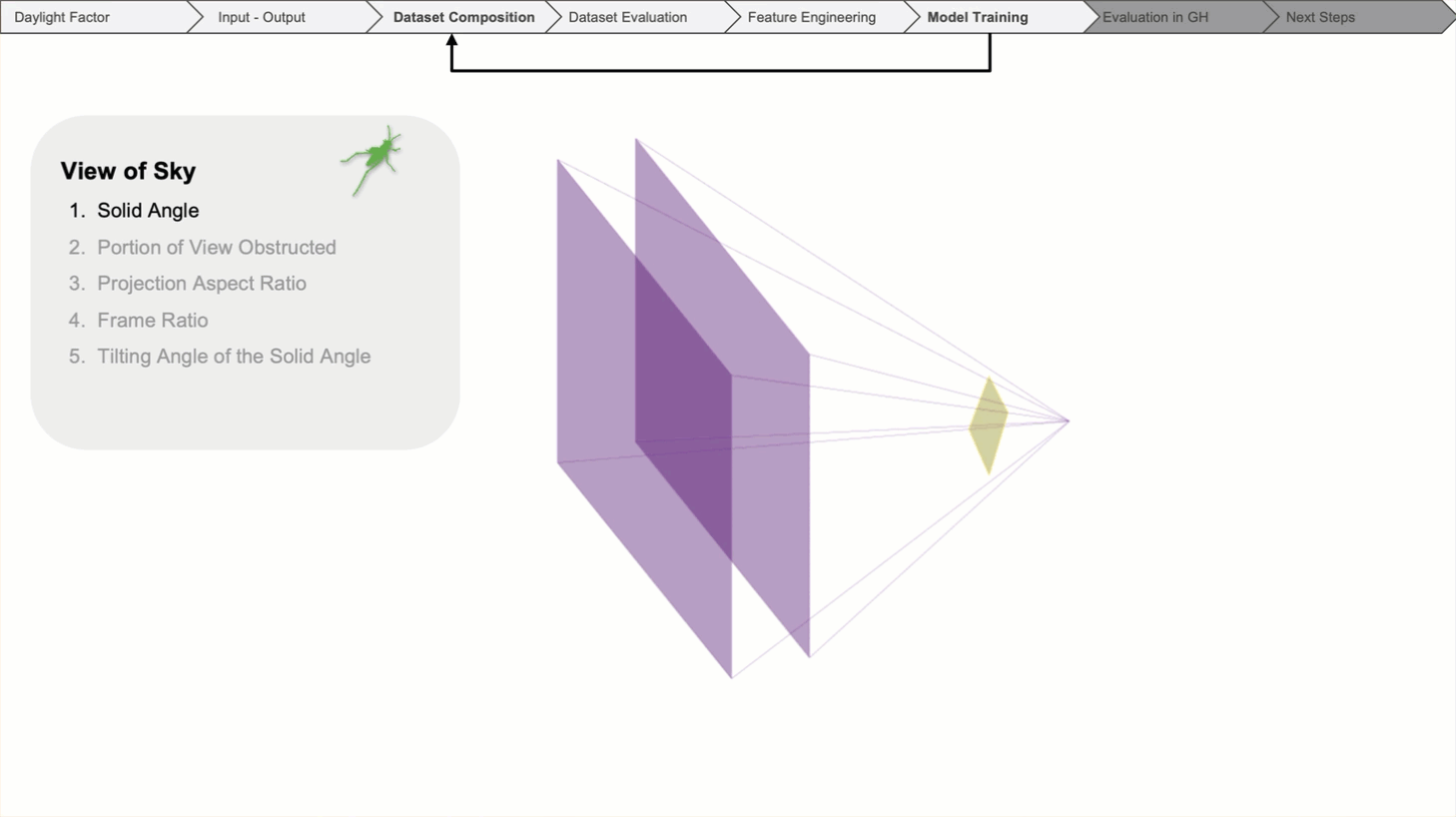
Next, we assessed the portion of the window view that was obstructed by exterior buildings or balconies. These obstruction indicators are categorized into horizontal stripes, reflecting changes in luminosity from the overcast sky at varying altitudes. The obstruction indicator is divided into four stripes, each representing a different horizontal level.


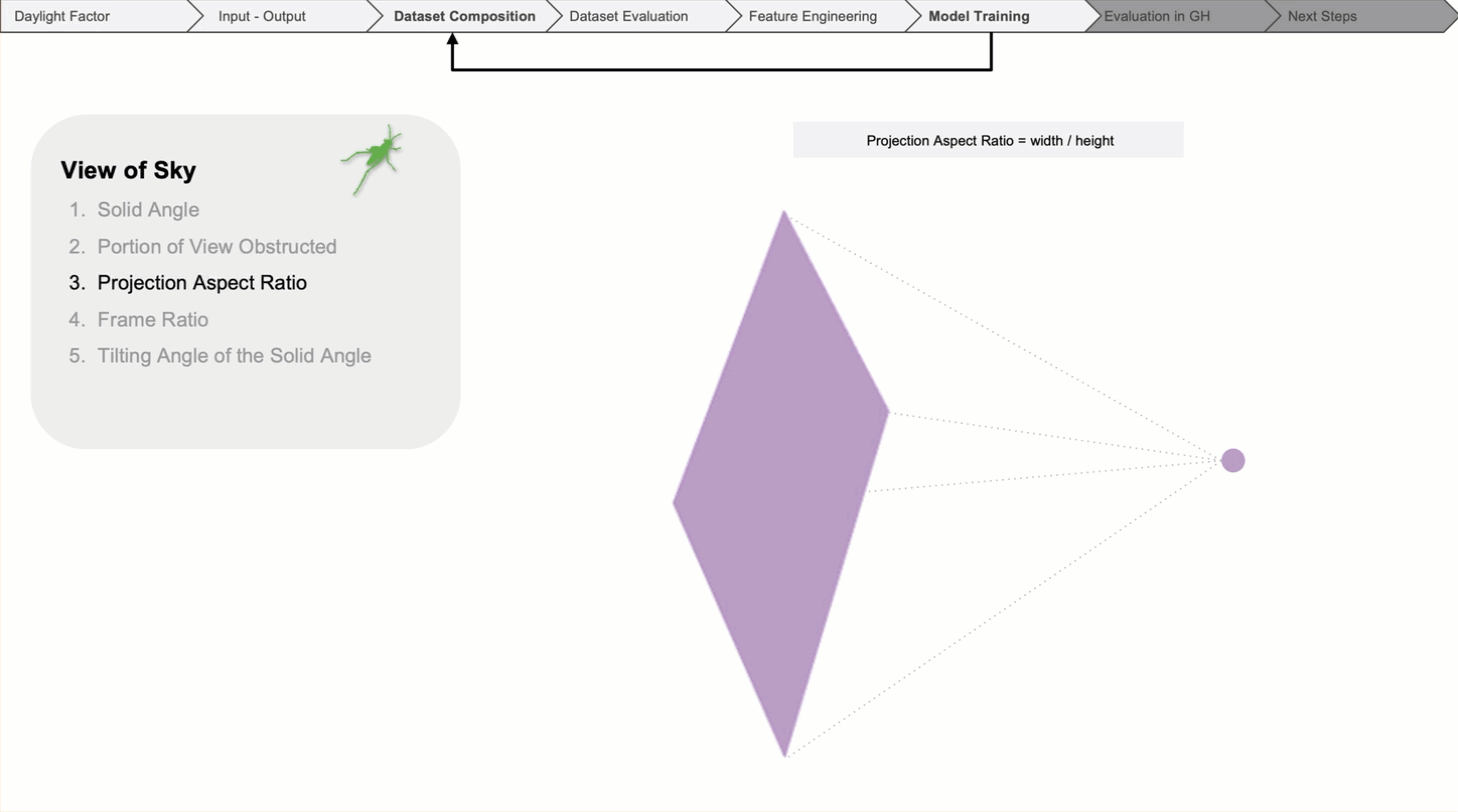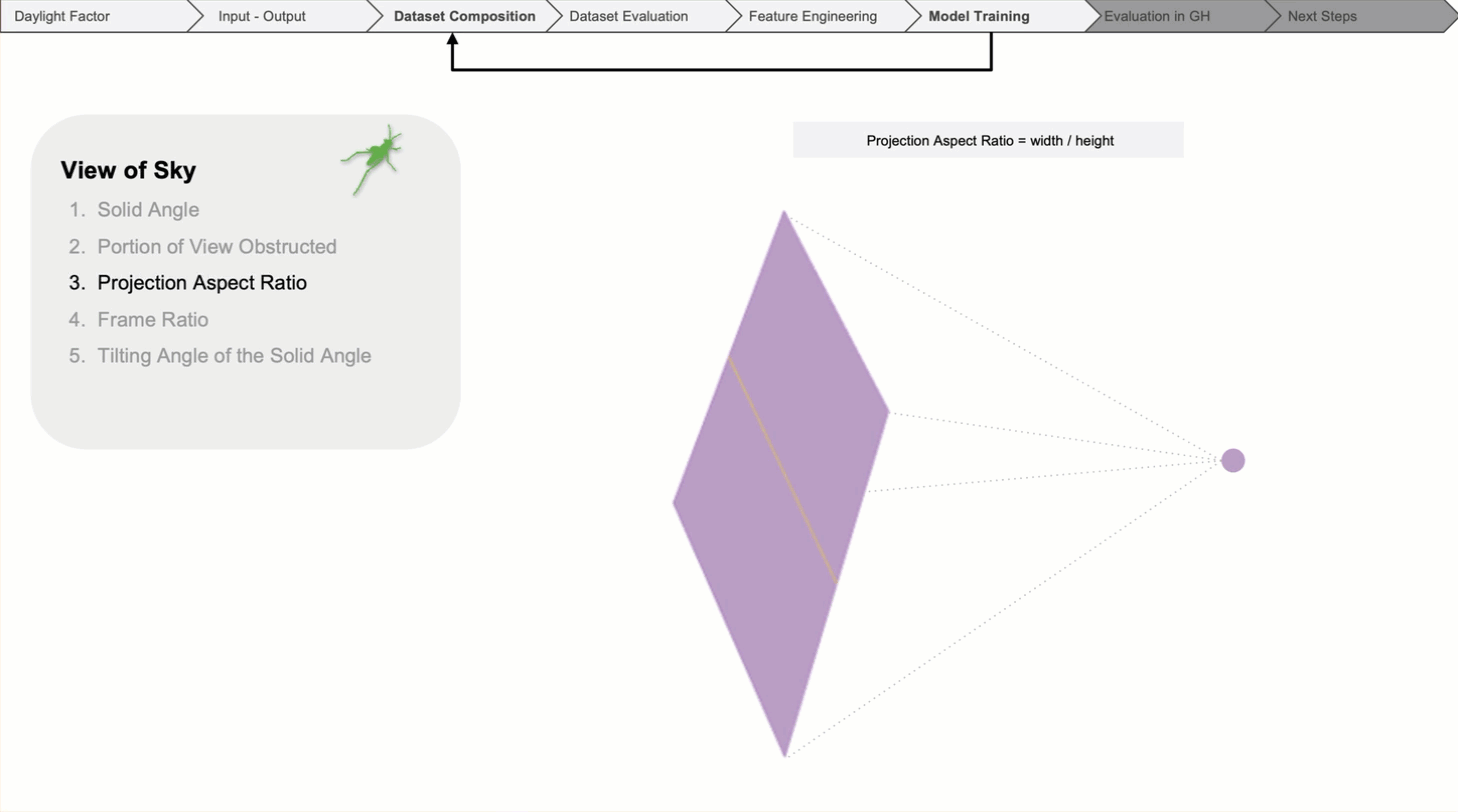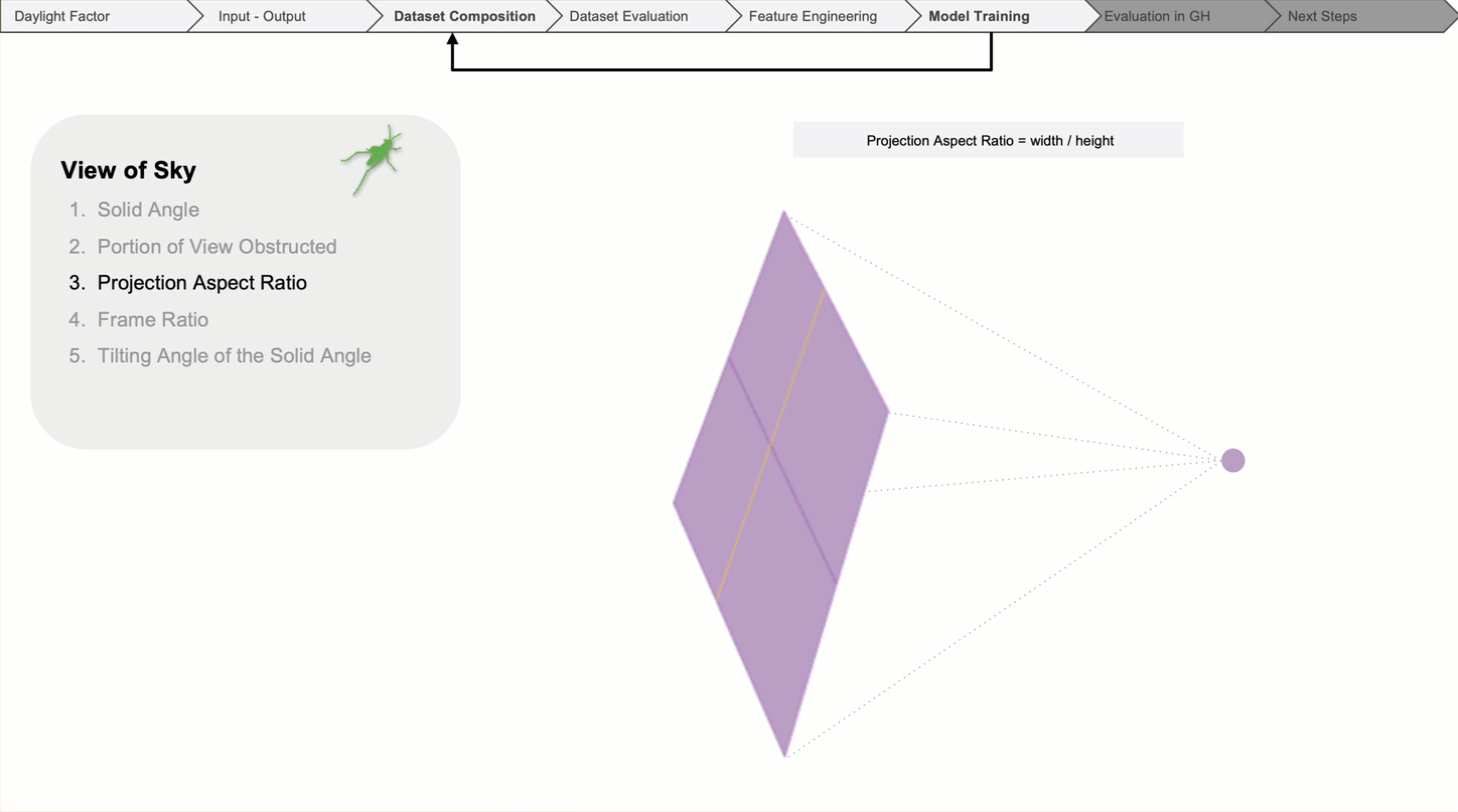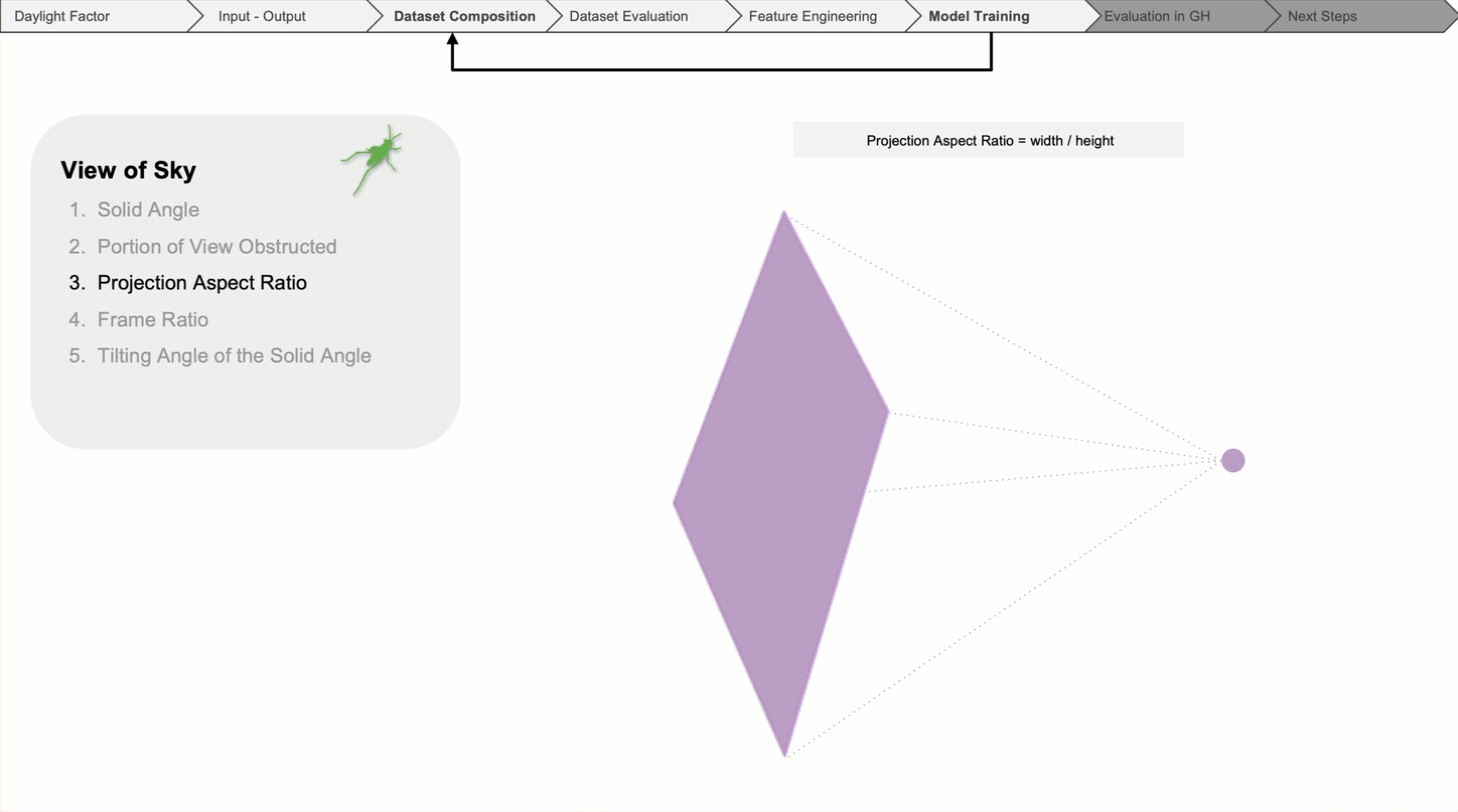
Then, the aspect ratio of the solid angle.
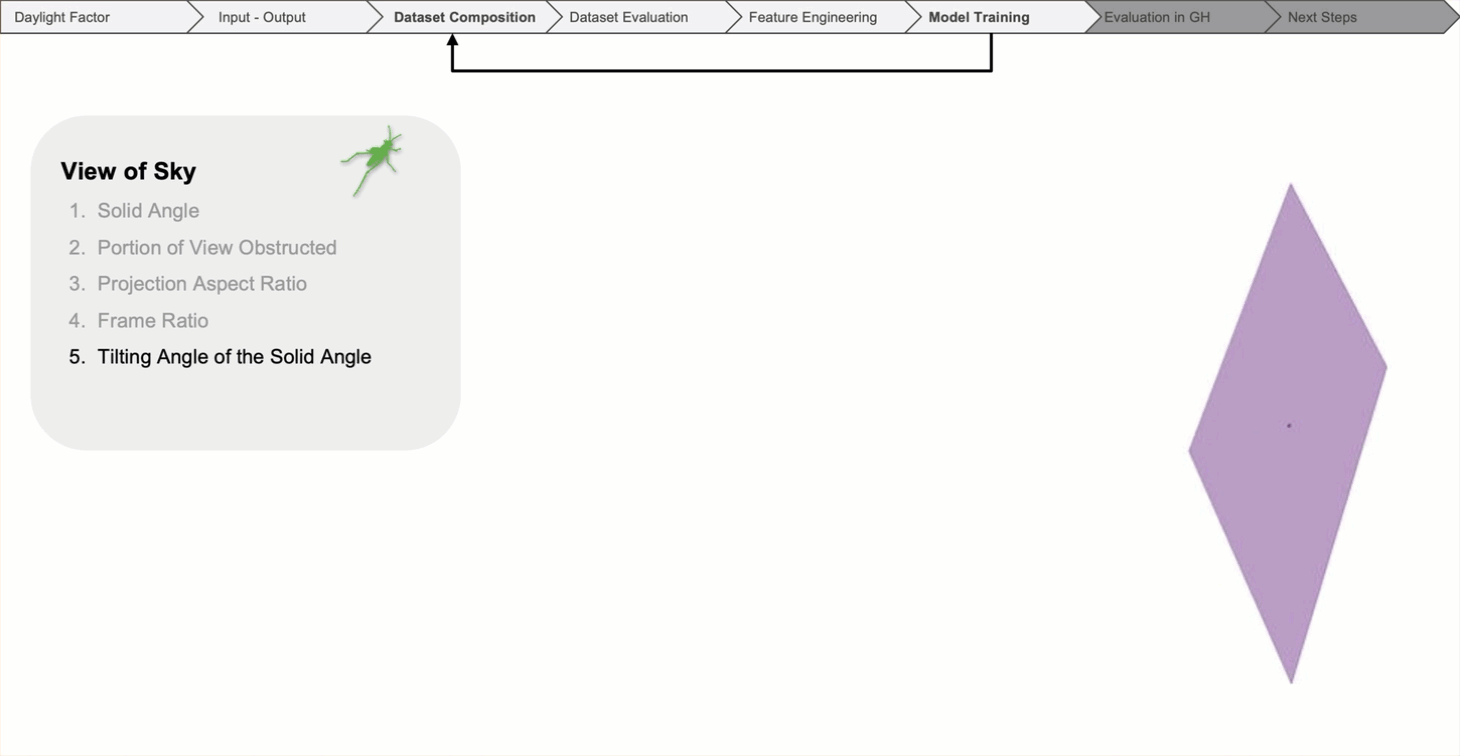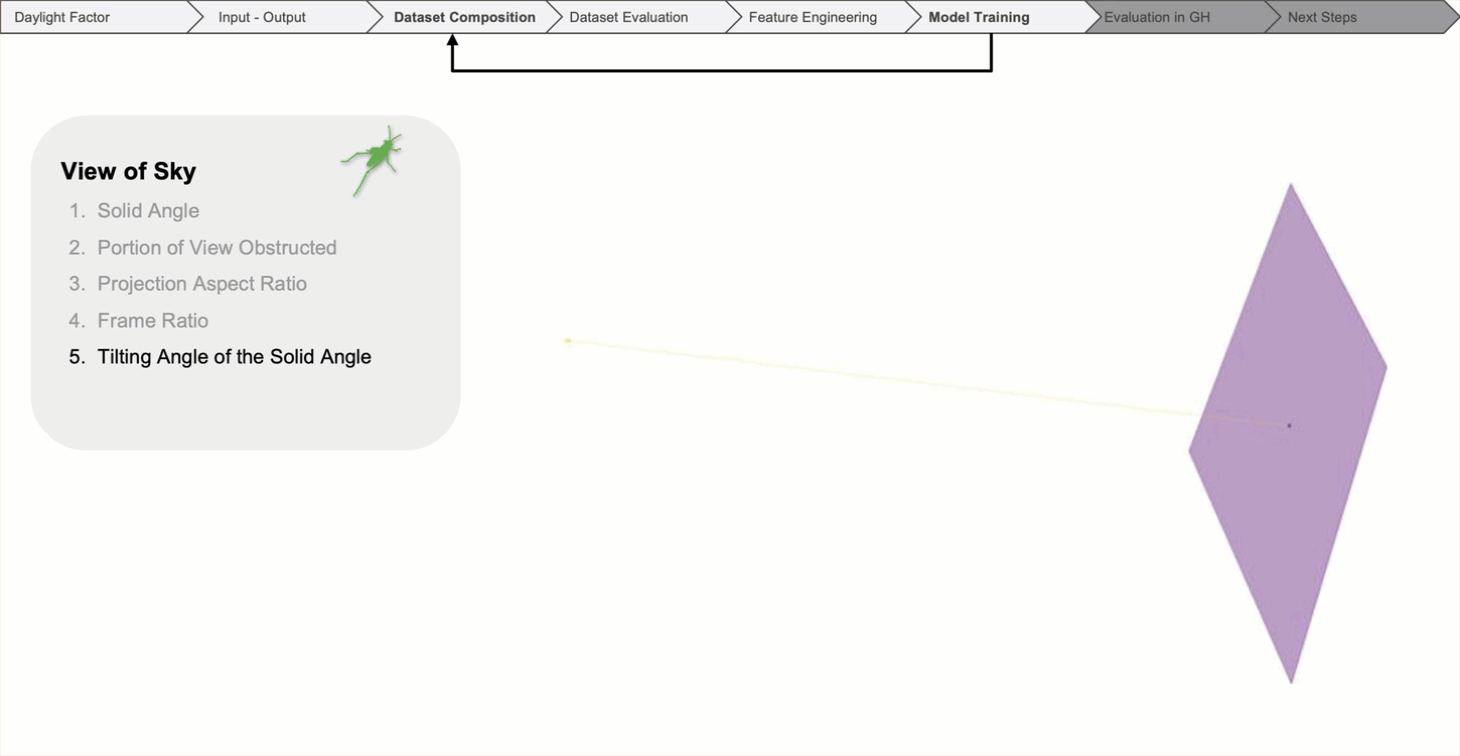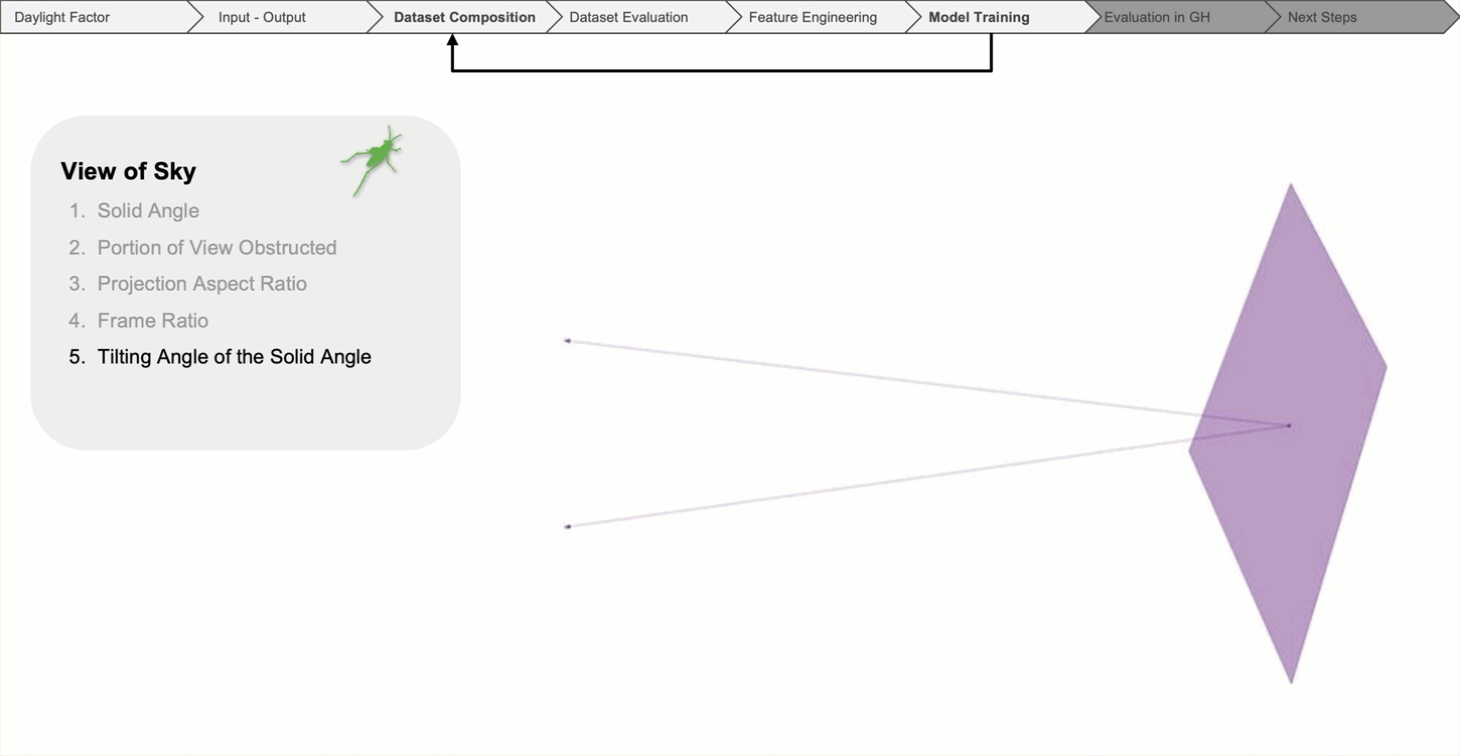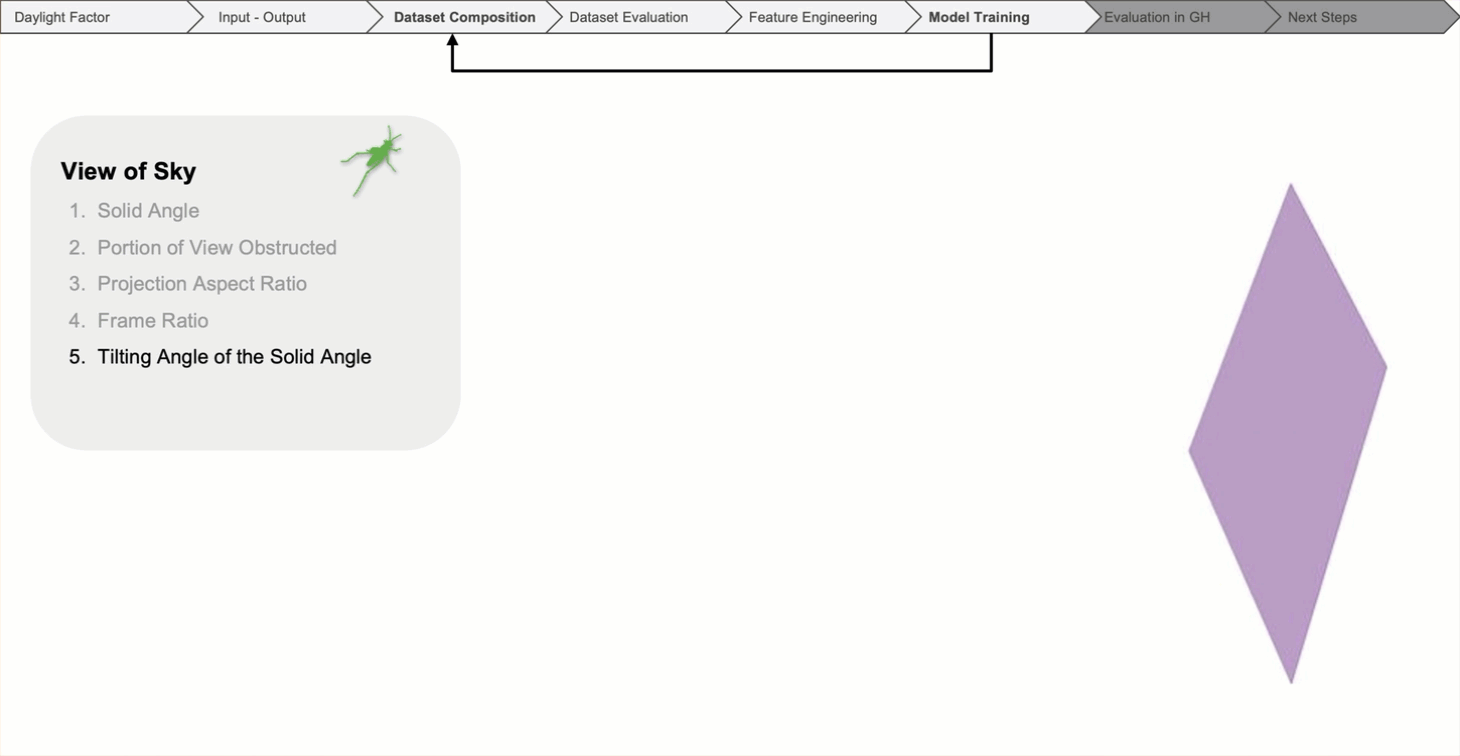
The tilt angle reflects what part of the sky is seen through the window from each individual point.
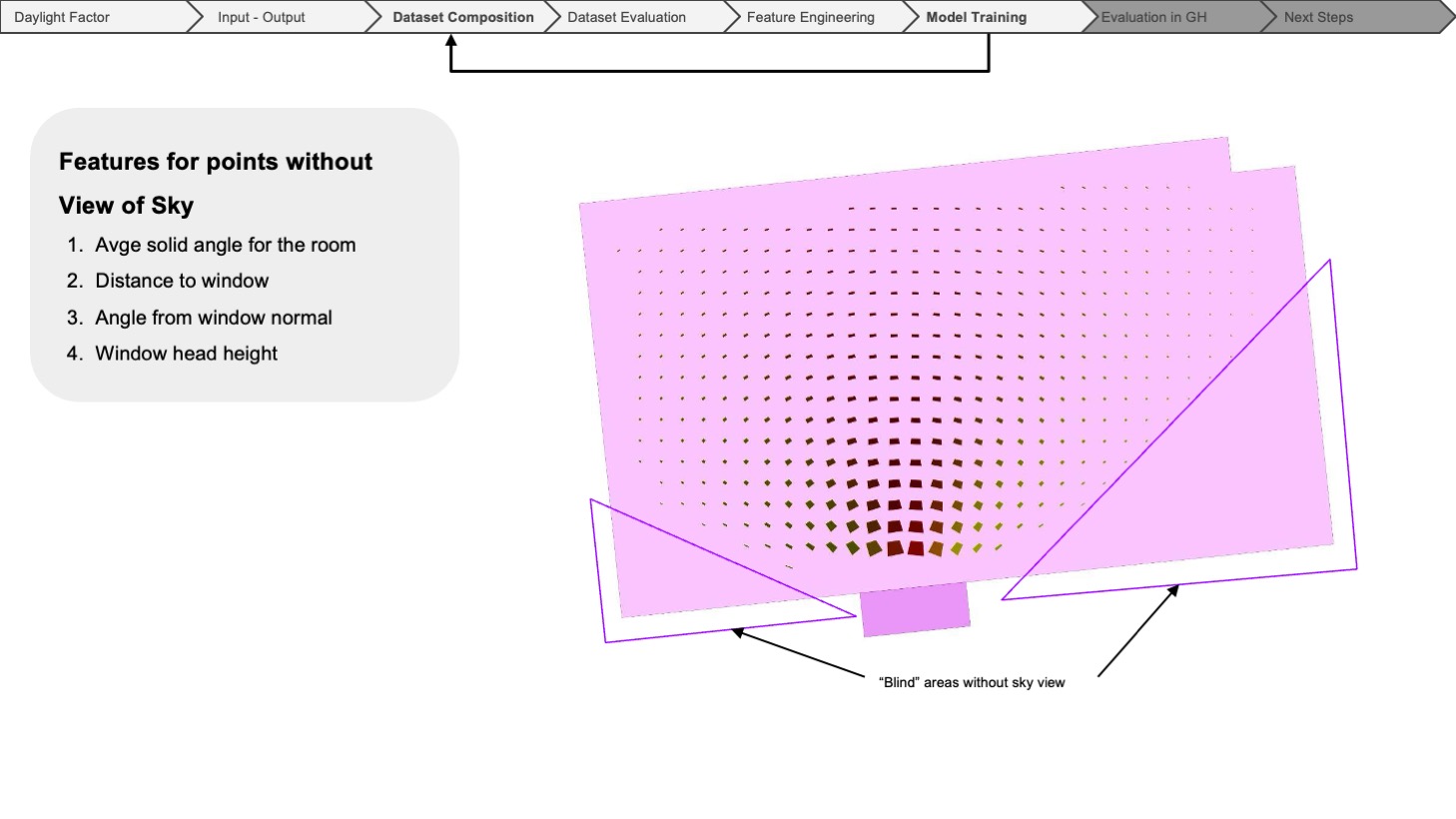
For points without a view of the sky, we incorporated additional parameters to enhance the model’s predictive capability. These parameters include the room’s average solid angle, distance to the window, angle from the window normal, and window head height.
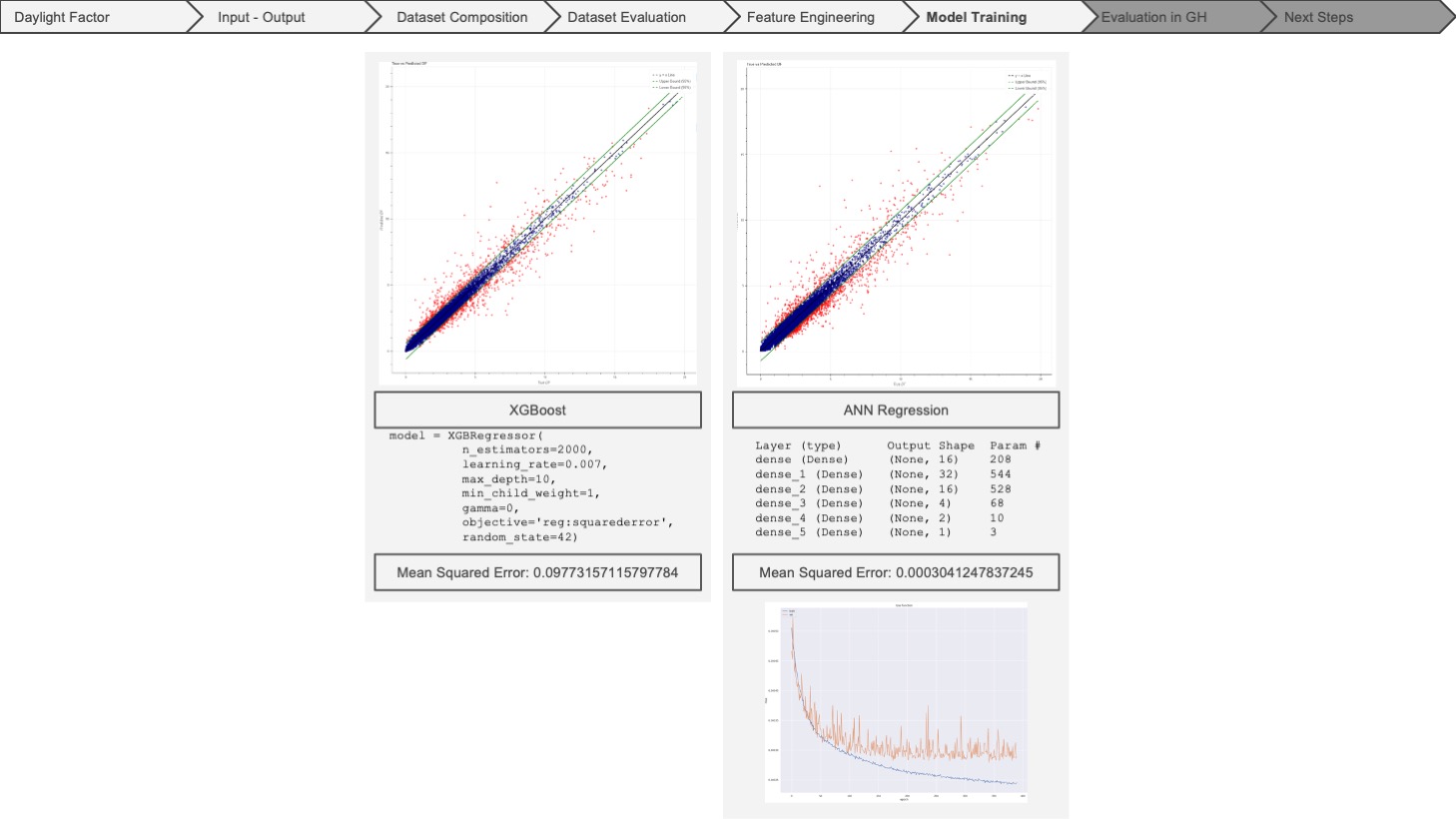
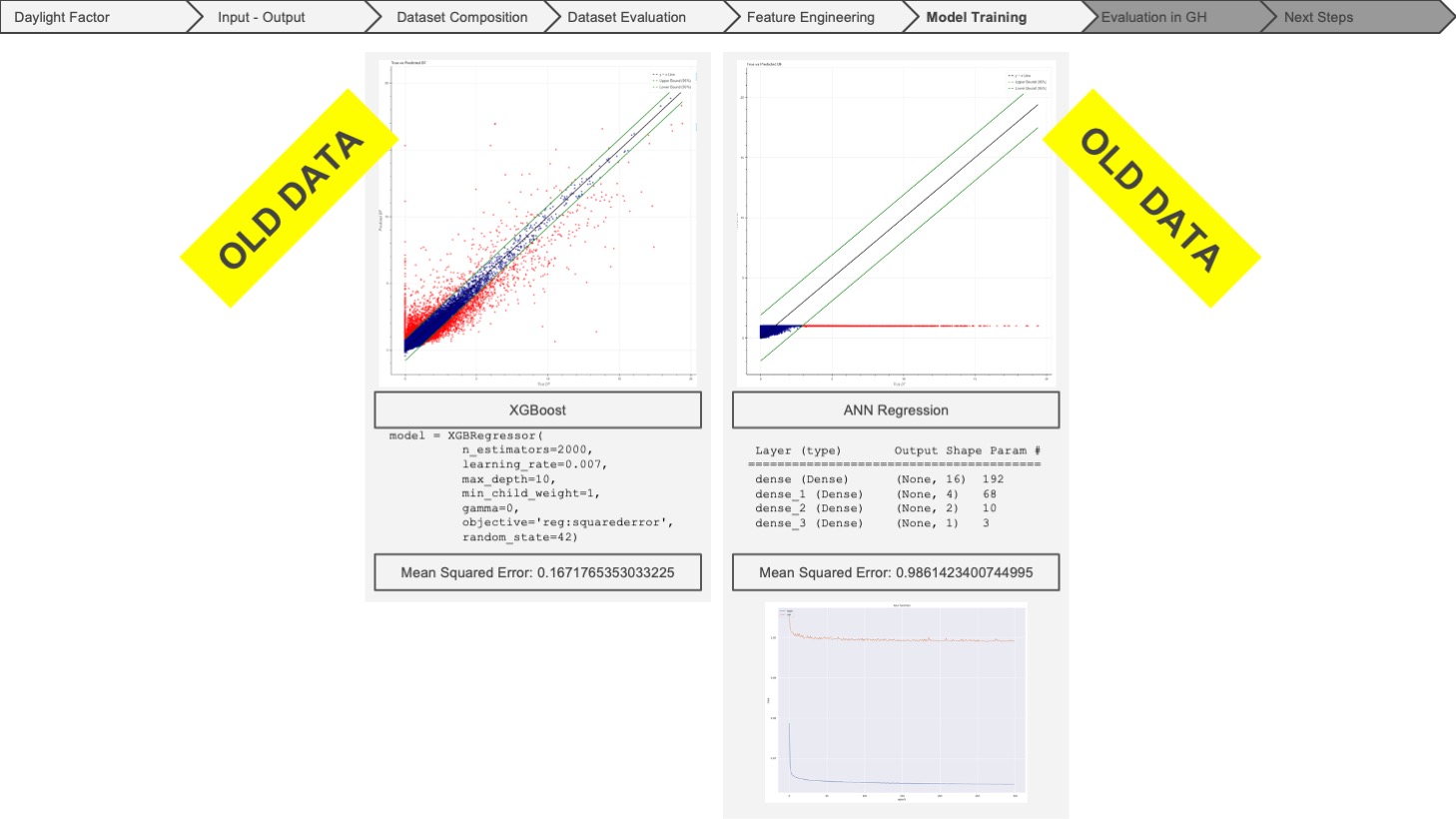
After running the selected models with our new dataset, composed of new features, we got much better predictions and much lower mean squared error values. If we have a quick glimpse at the models run with the old features, the accuracy is much lower, and the plots have much more noise. Also, we could not run the ANN model properly with our old data.
The new features obviously changed the course of the training. When we compared the two new models, we can see that the 95 percentile of the predictions, the navy-coloured data points in the plots, are closer to the x=y line in XGBoost than the ANN model. However, we can also see that the mean squared error of the ANN model is much lower than that of XGBoost. Overall, the results of the two models are similar in accuracy. Now, it is time to examine this by deploying the models in Grasshopper.
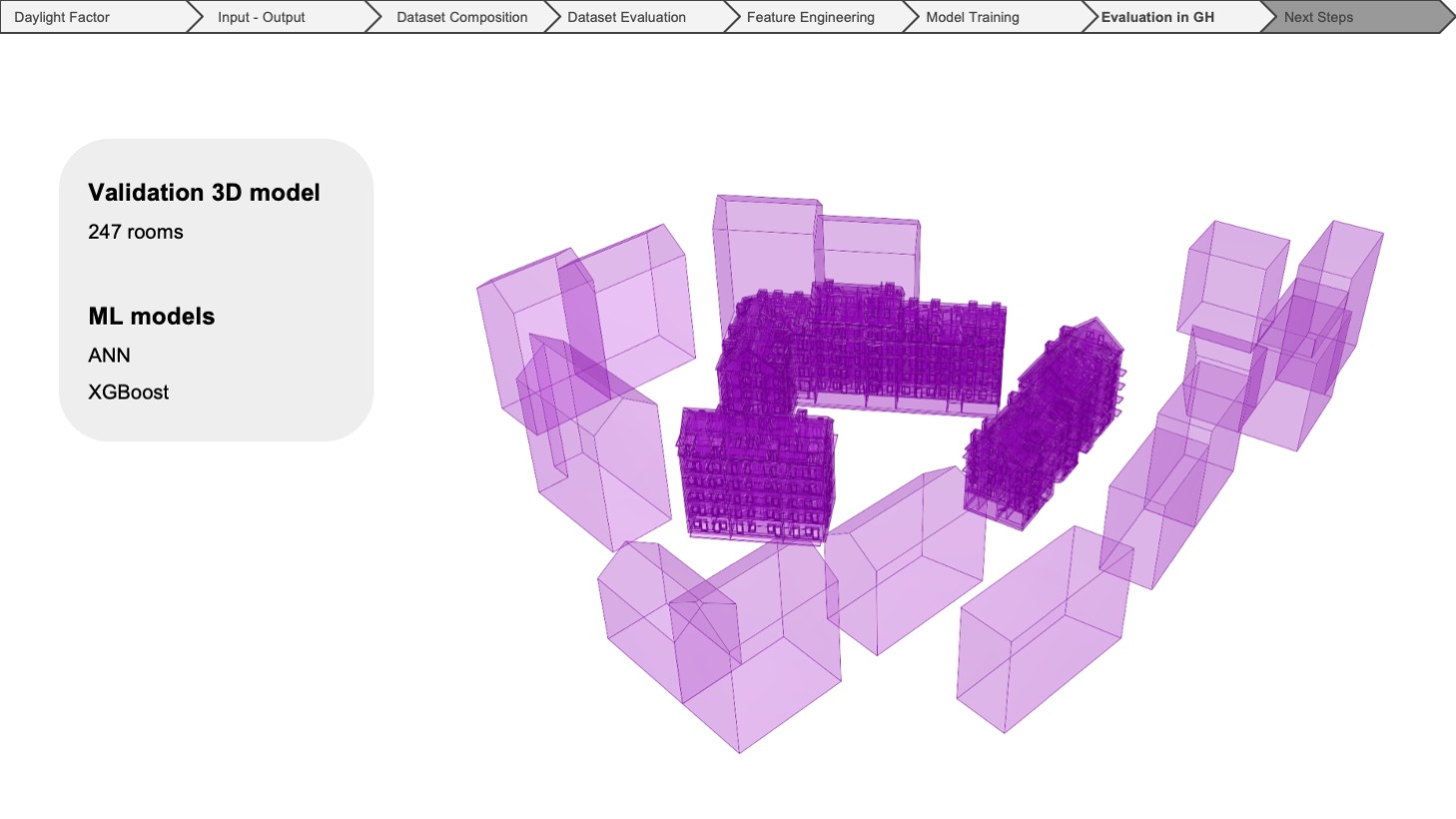
We successfully validated the machine learning models by testing them in a real building model containing 247 rooms.
MODEL VALIDATION
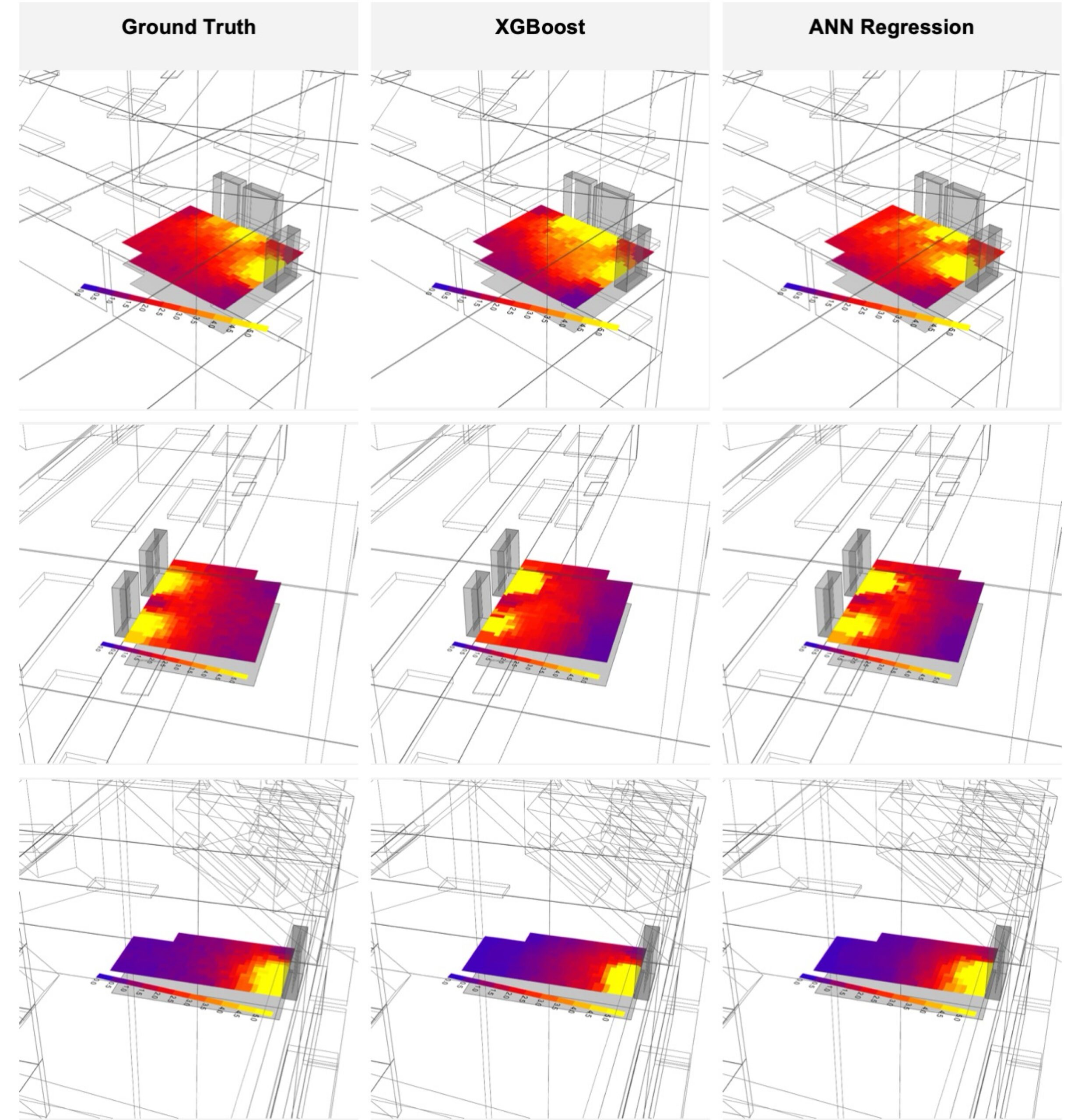
The results were highly satisfactory. The left image displays simulation results, while the other two images are predicted results.
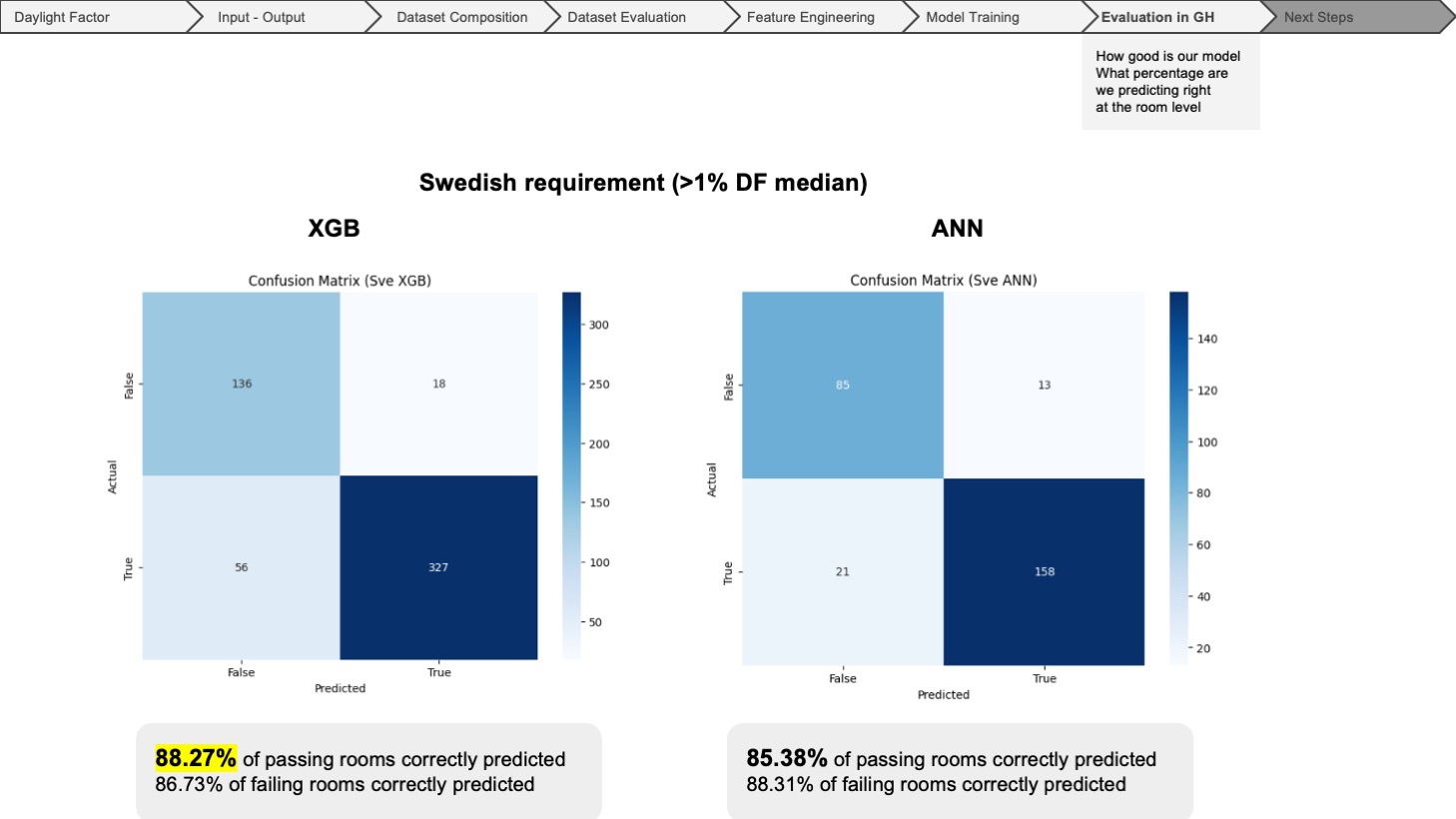
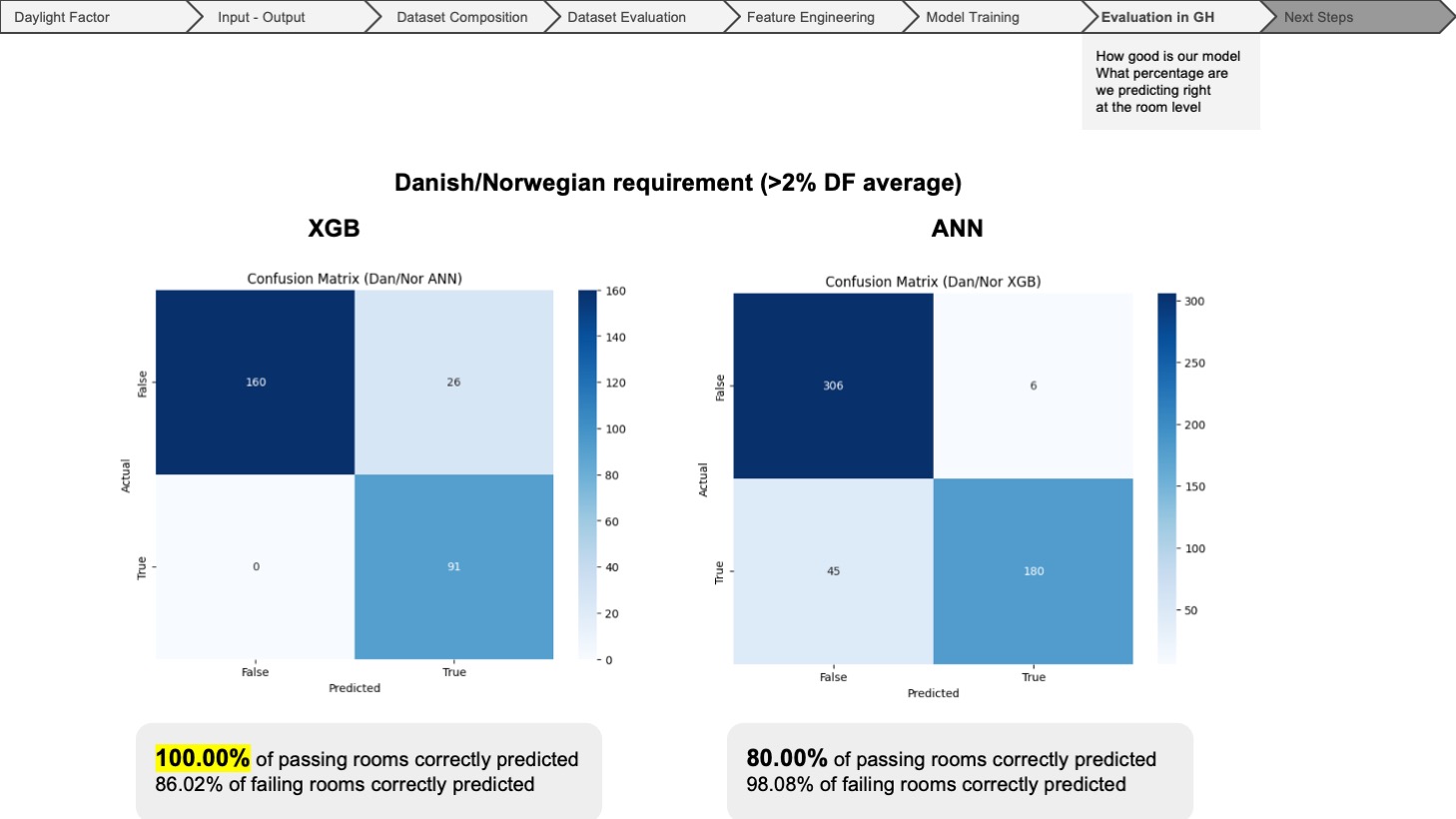
Both models are highly accurate in predicting compliance with the Swedish requirement (>1% median DF), ranging between 80% and 90%. The pass accuracy rate was the most decisive indicator, leading us to select XGBoost (XGB) for its slightly superior performance in this aspect. The results for the Norwegian/Danish requirement (>2% DF average) also show significant accuracy improvements with XGBoost (XGB) compared to other models.
NEXT STEPS
Based on the successful prediction method, we have initiated the development of a Rhino-integrated tool designed for architects as an early design support. This tool provides real-time predictions on daylight compliance as architects work on their designs. Using a simple 3D model, rooms are colour-coded green or red based on whether they are predicted to comply with daylighting requirements. This feedback system helps to efficiently and effectively ensure compliance from the initial stages of architectural design.
