
Why “Faster” Matters
A single photorealistic render can quickly be very expensive and take days to produce, locking design changes behind hefty bills and long waits for architects. Generative AI, through models like Stable Diffusion and custom LoRAs, slashes both cost and time, turning sketches into near-final visuals in seconds. By democratizing high-fidelity imagery, it empowers every team member to iterate rapidly and collaborate more creatively.
Introduction & Context
Pain Points in Architectural Visualization
Traditional pipelines demand specialized software and skilled operators, driving up costs for each image and stretching delivery times. Iterations are cumbersome, each revision means reconfiguring lighting, materials, and camera setups, locking out non-experts and slowing design dialogues.
Primer on Generative AI in Creative Fields
Generative AI uses deep learning models to synthesize or transform images based on text prompts or reference inputs. Closed platforms like Midjourney and DALL·E offer polished, user-friendly interfaces but can be restrictive and limited in customization. Open-source engines such as Stable Diffusion enable full control over model weights, fine-tuning (e.g. training custom Low-Rank Adaptation (LoRAs)), and local deployment, ideal for integrating bespoke studio workflows.
This term and project explored AI image generation testing SDXL by Stability.ai first and finally jumped to Flux.1-Dev by Black Forest Lab, all with a ComfyUI and Google Colab worflow experimentation.
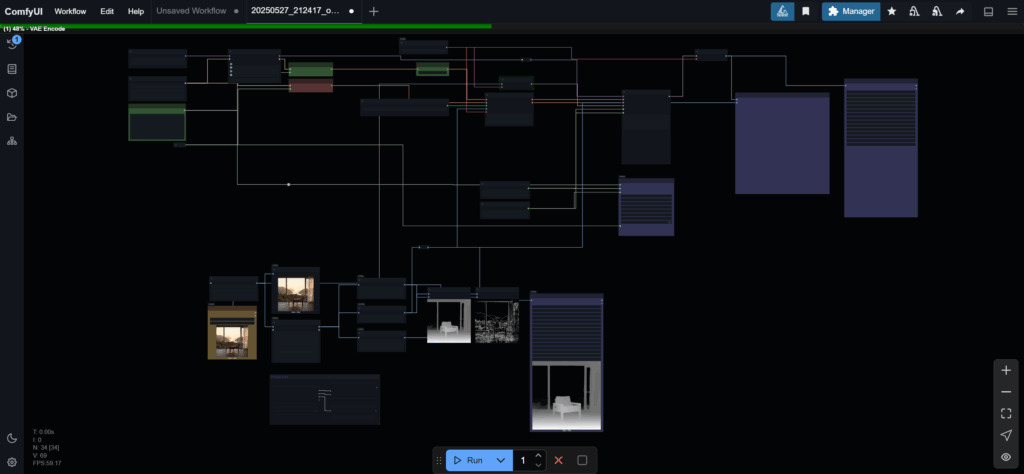
Core Techniques in Action
Text-to-Image (using Flux.1-Dev)
Text-to-Image lets you go from a simple prompt, “ring-shaped house perched on a forested mountain island”, to a high-fidelity concept render in seconds. Just by writing the description, maybe applying a LoRA, and AI interprets your vision with realistic lighting, materials, and mood without any other inputs.
















Image to Image (using Flux.1-Dev)
With Image-to-Image, you transform a rough sketch, model screenshot, or photo into a polished visualization in seconds. By leveraging Canny edge or Depth-map conditioning, just optimizing the threshold, and applying your chosen LoRA, you retain your original composition while instantly boosting detail, lighting, and style.

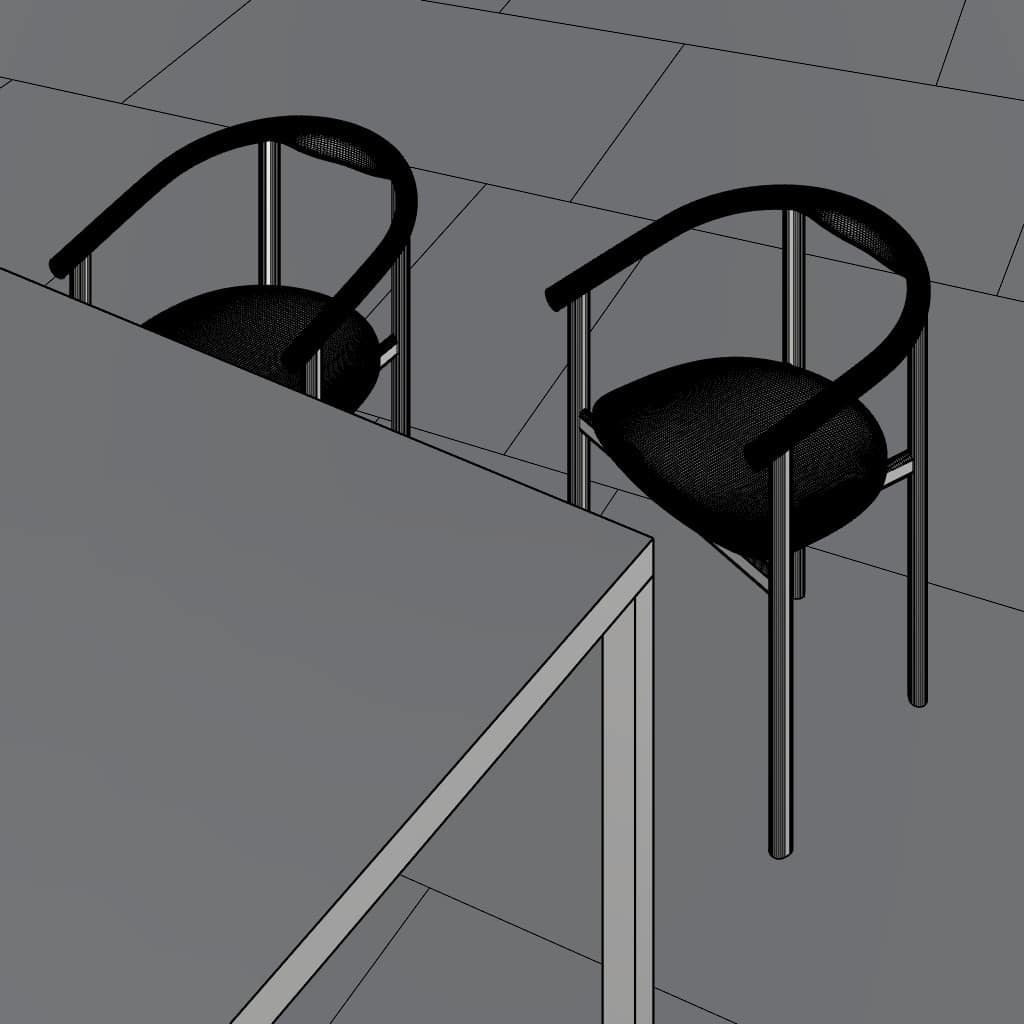


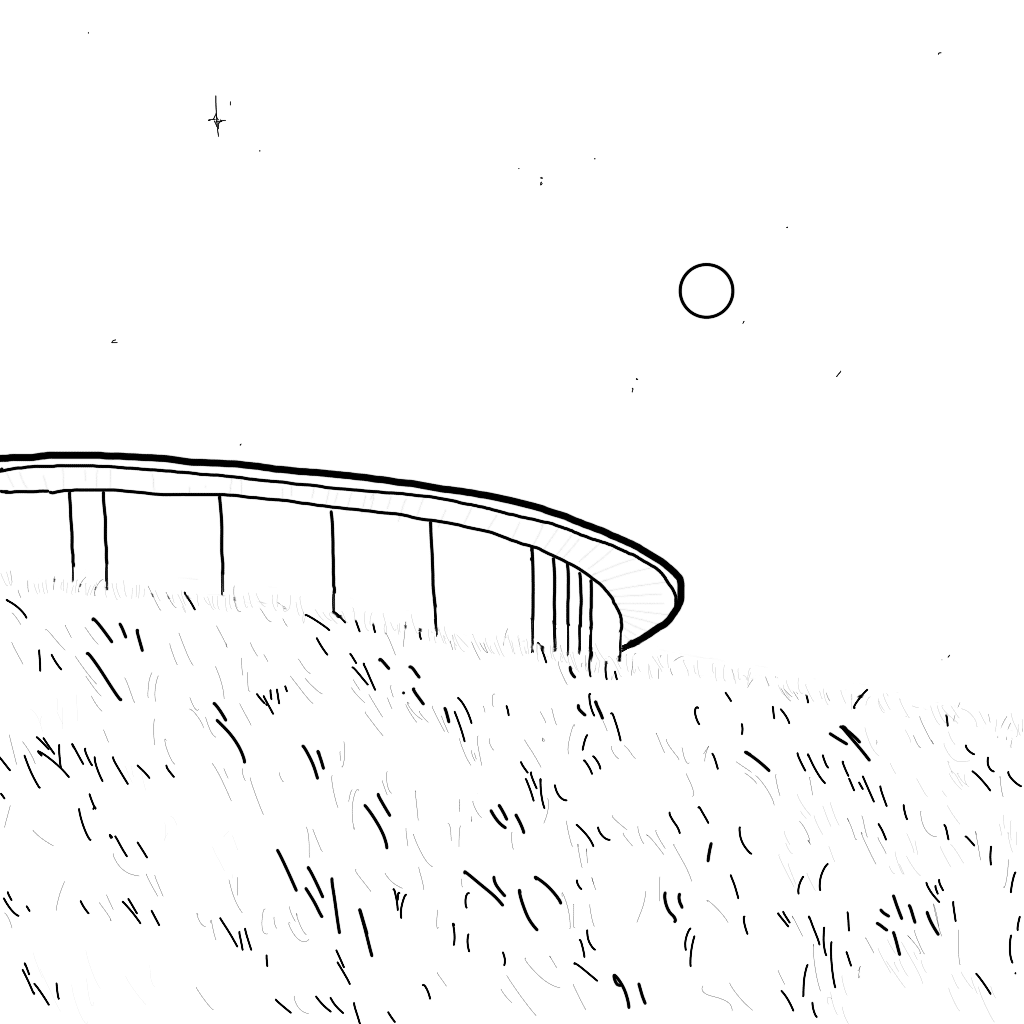

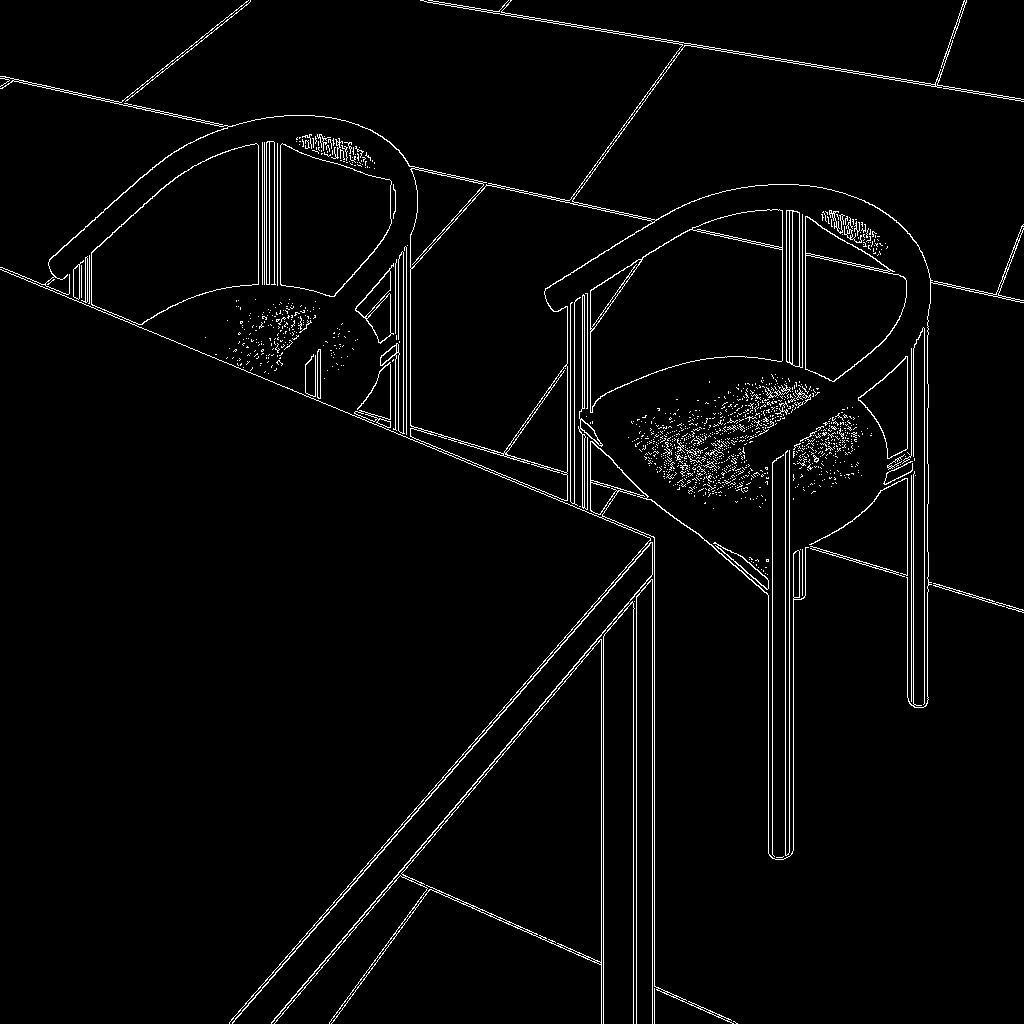







Finetuning LoRA
After experimenting with the basics of AI image generation, we moved on to the next step with finetuning our custom LoRAs. For this, we firstly gathered a dataset of 60 images from top-edge architecture visualisation offices and wrote the caption for each. We trained a first LoRA with Dreambooth unsuccesfully. Going through the literature and published papers again helped us realized that much less images are required. Thus, we trained two LoRAs, one with 5 images, the Sunset Golden Hour, and one with 9 images, the Sunset Contrast.
Sunset Contrast LoRA scale 0-1






Sunset Golden Hour LoRA scale 0-1






Before / after Sunset Golden Hour LoRA




From image with LoRA to image with LoRA



Bringing It Into the Studio
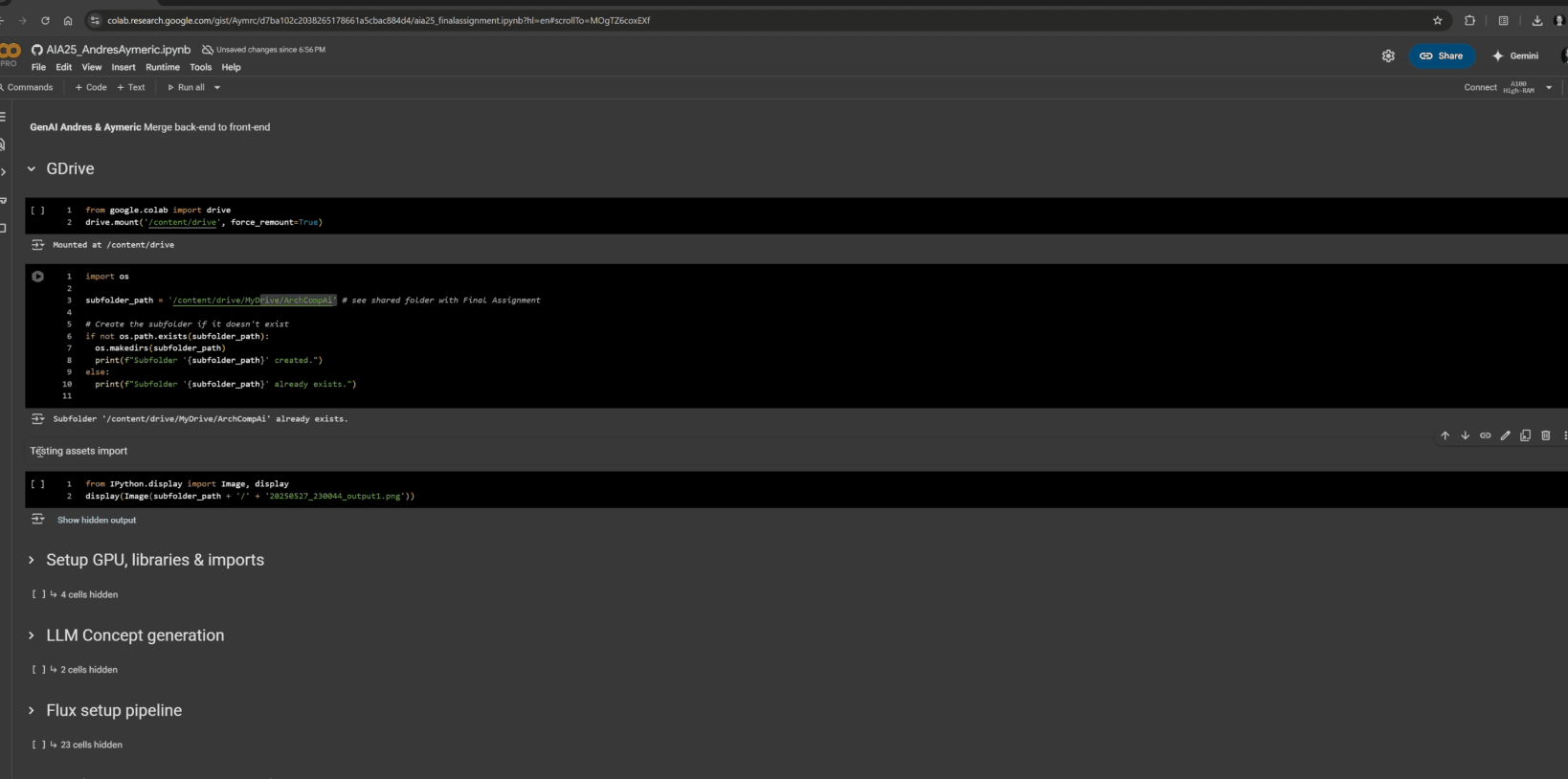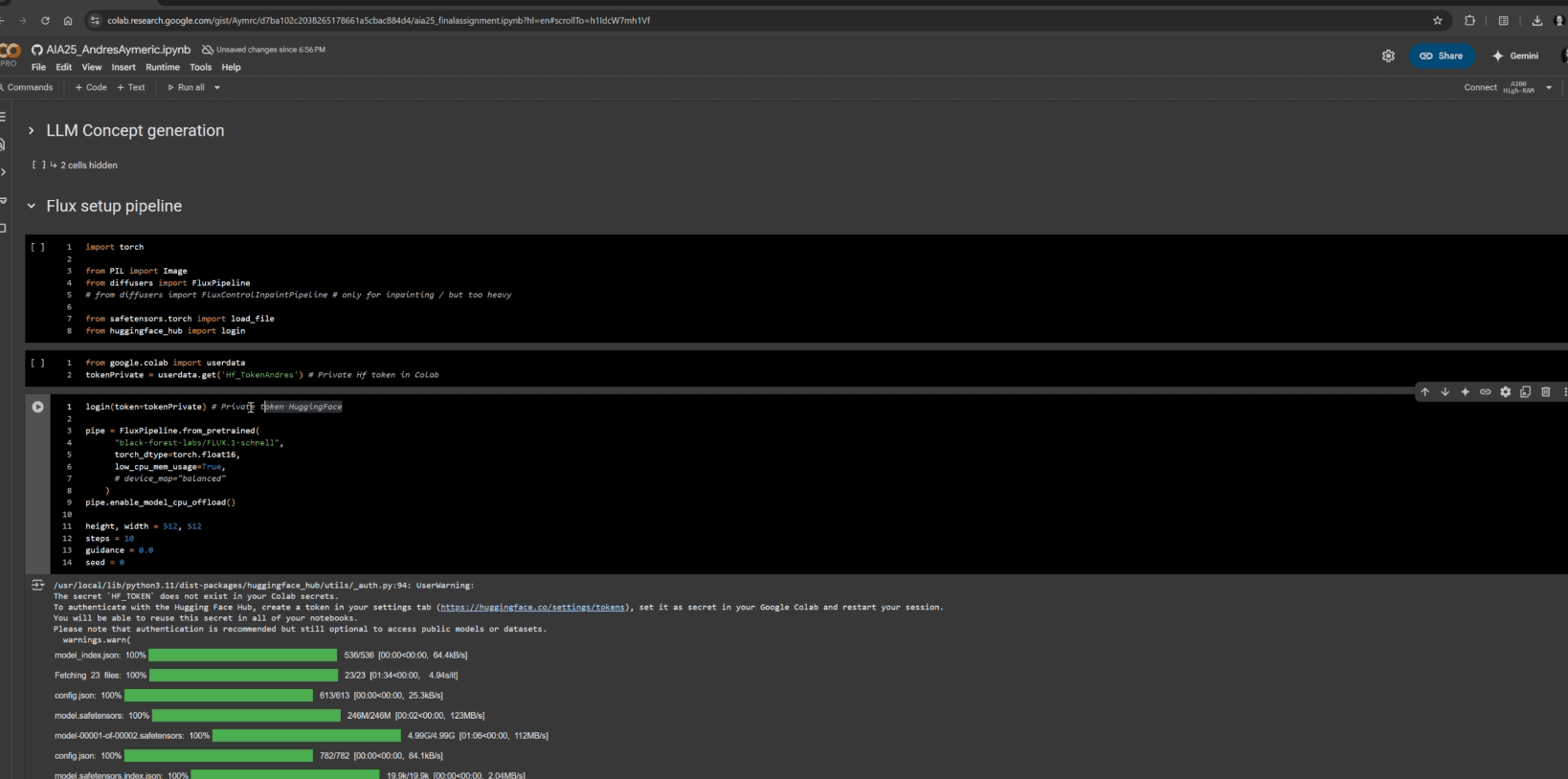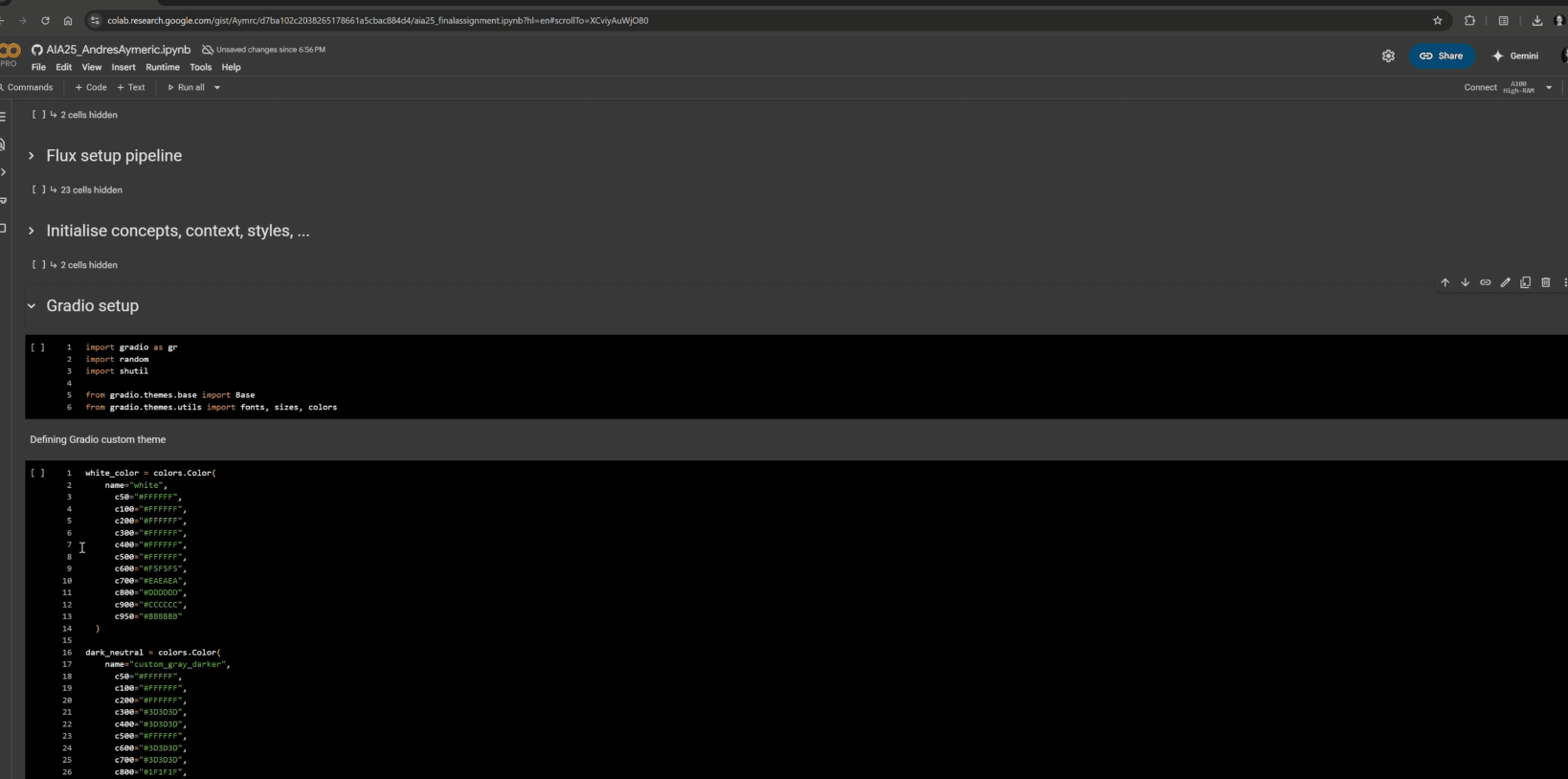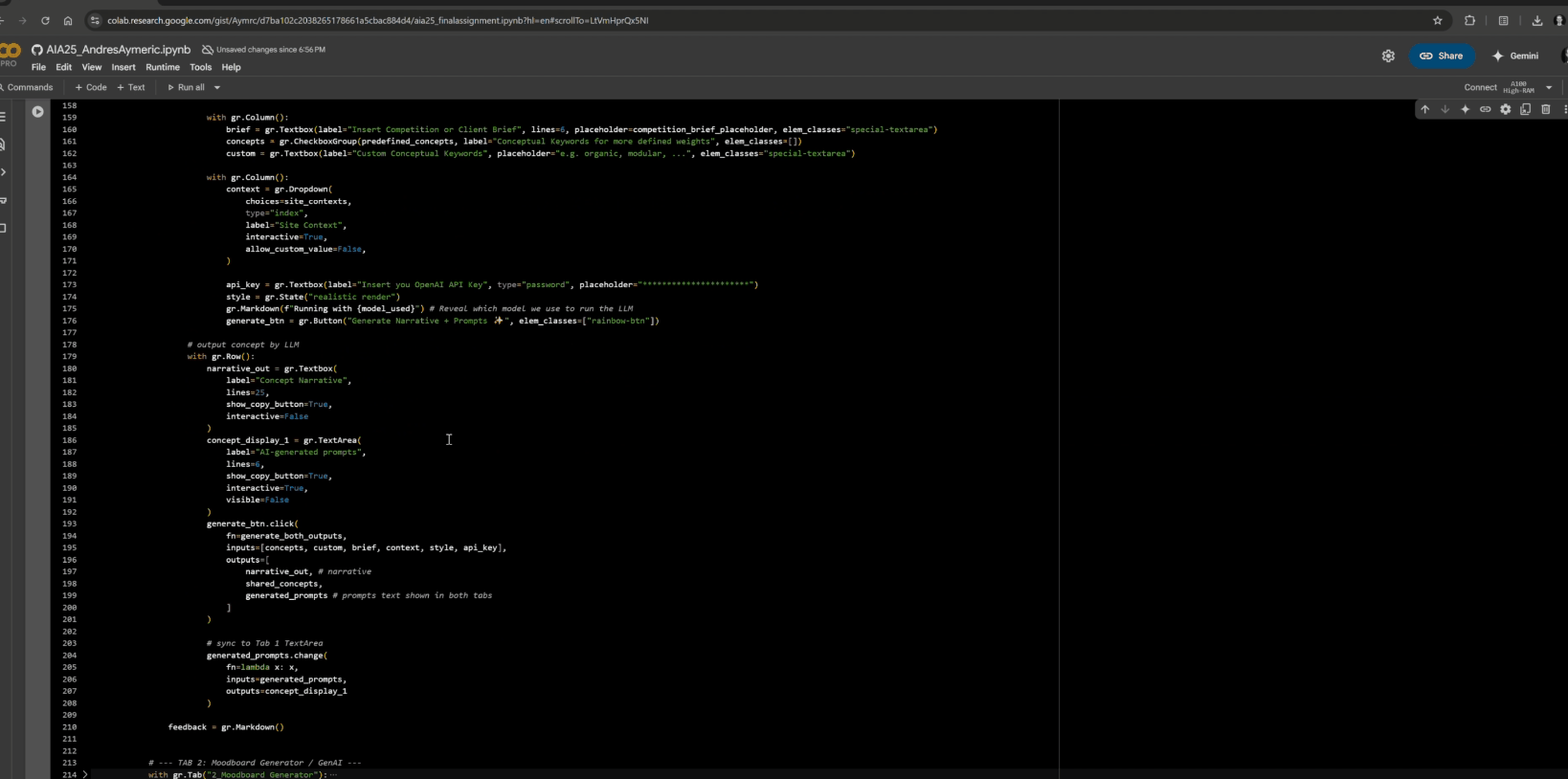
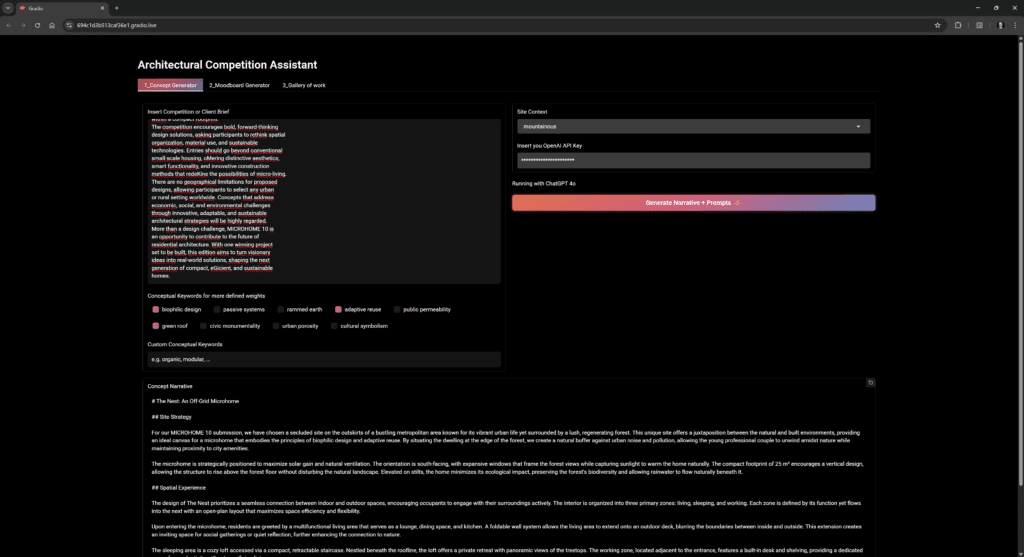
Gradio Deployement
With tight competition deadlines, every minute counts. To accelerate ideation and rapidly explore design directions, we wrapped everything into a Gradio app where you:
- Paste a brief for a Large Language Model (LLM) to generate five starter prompts
- Select keywords or type them to put more weight on your architectural priorities.
- Drawing to Render, upload sketches, model or 3D view, and adjust Canny / Depth thresholds to bring your concept to life.
- Select a LoRAs (or upload your own) by trigger word to apply custom styles.
- Browse a live gallery of all your work and results and download PNGs.
All in under a minute, no coding skills required, yet fully tunable for power users.

Frontend: Gradio UI
Backend: Google Collab script
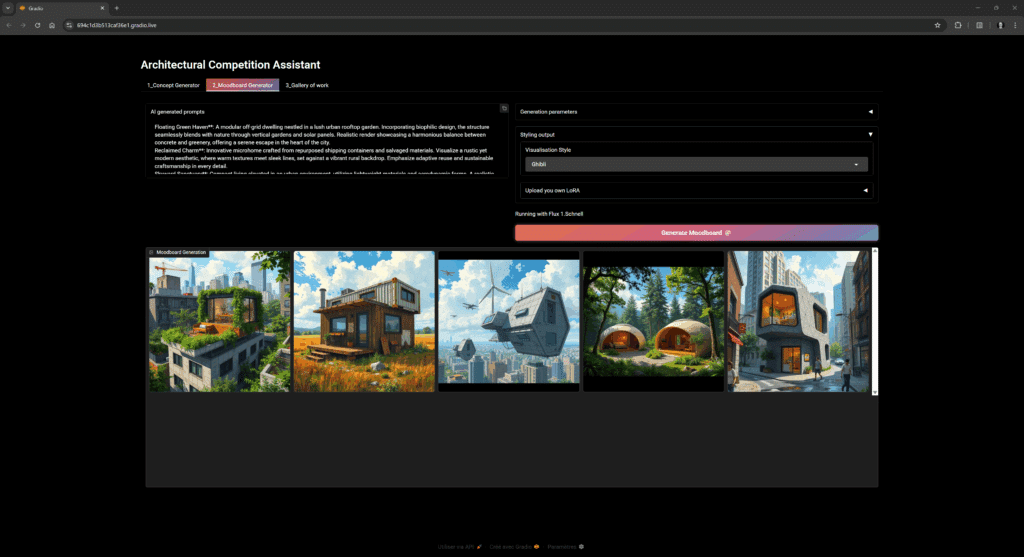
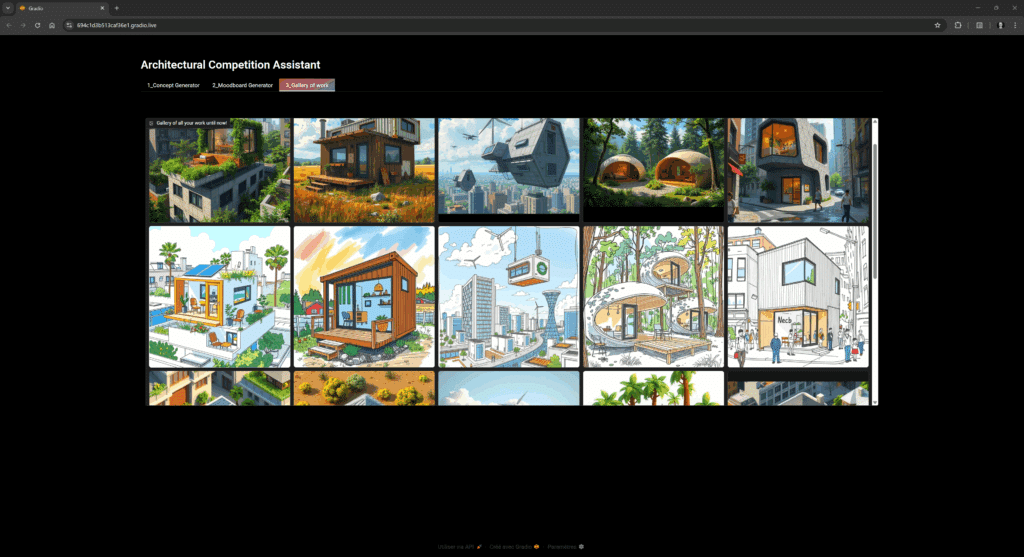
Workflow Gains
Iteration Speed What once took hours or days on a render farm now completes in seconds, letting teams test multiple design variants in a single meeting.
Democratization Junior designers, interns, and clients can generate and tweak visuals themselves, no specialized 3D or rendering expertise required.
Reflection on Process
We found that a tightly curated dataset of just 5–9 high-quality images outperforms larger, noisier collections, proof that “less is more” when training Flux LoRAs. Equally vital was dialing in Canny and Depth thresholds (even a 0.1 shift dramatically altered detail retention), refined through three rounds of fine-tuning feedback to lock in each model’s unique aesthetic.
Our pipeline still faces edge-artifact challenges around intricate geometry, a hard 1024×1024 px resolution cap (or 512×512 px when speed is paramount), and no built-in multi-view consistency for fully coherent 3D scenes. To bridge these gaps, we’re exploring direct integration with architectural software, building a shared repository of curated datasets for cross-studio collaboration, and running user studies to polish the interface and validate real-world design benefits.
On the economic side, replacing a €2.000 render with near-zero variable cost shifts the conversation from gate-kept visualization to architect-empowered ideation. While this raises complex questions about future skill sets and studio roles, it ultimately returns budget and creative control to architects, letting them invest in the ideas that matter most.
