
Project goal
For our graph Machine Learning project we chose to work with the city of Copenhagen. Our goal was to predict the Road Noise in the city.
Dataset and data preparation
From the KOBENHAVNS OPEN DATASET, we obtained a dataset detailing road noise levels across Copenhagen. To fill in the gaps where data was missing, we used two additional datasets for a more comprehensive prediction of road noise.
- Traffic Speed dataset as feature,
- Green Spaces as feature
- Road Noise dataset as classes
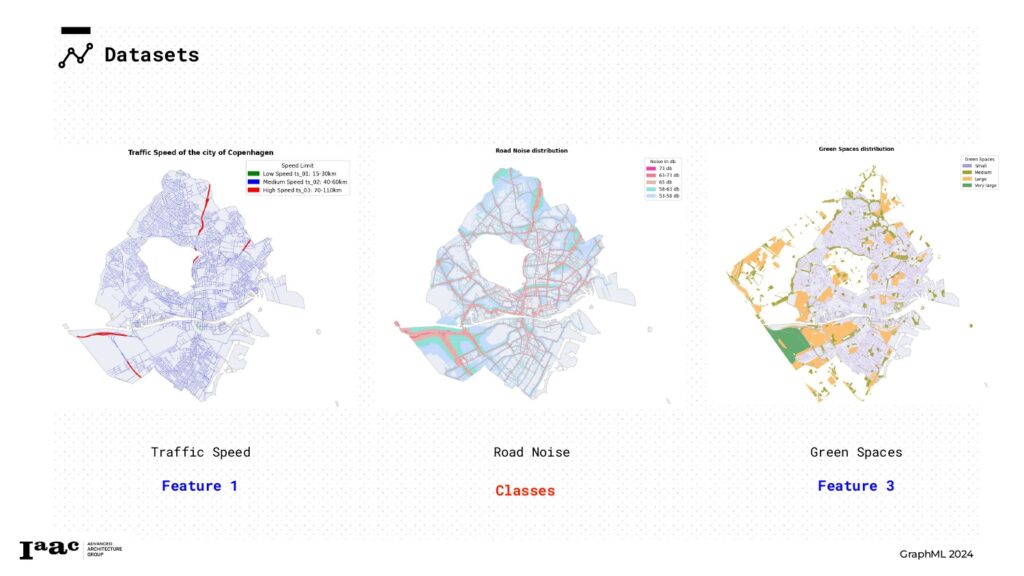
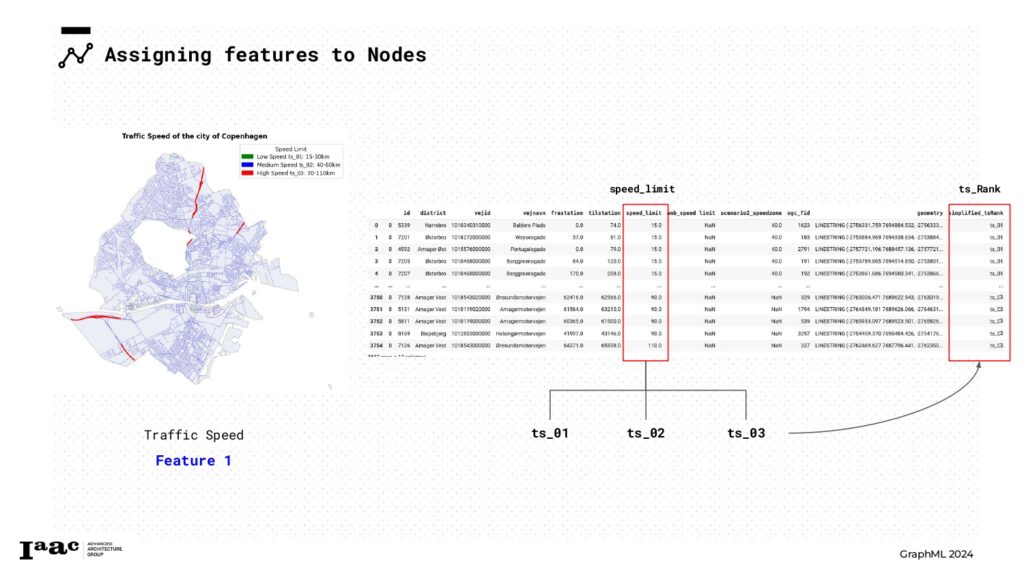
For the Traffic Speed dataset, we utilized the “speed_limit” feature to establish a ranking of three categories. These categories were then used to assign the Traffic Speed feature to our graph as node attributes.
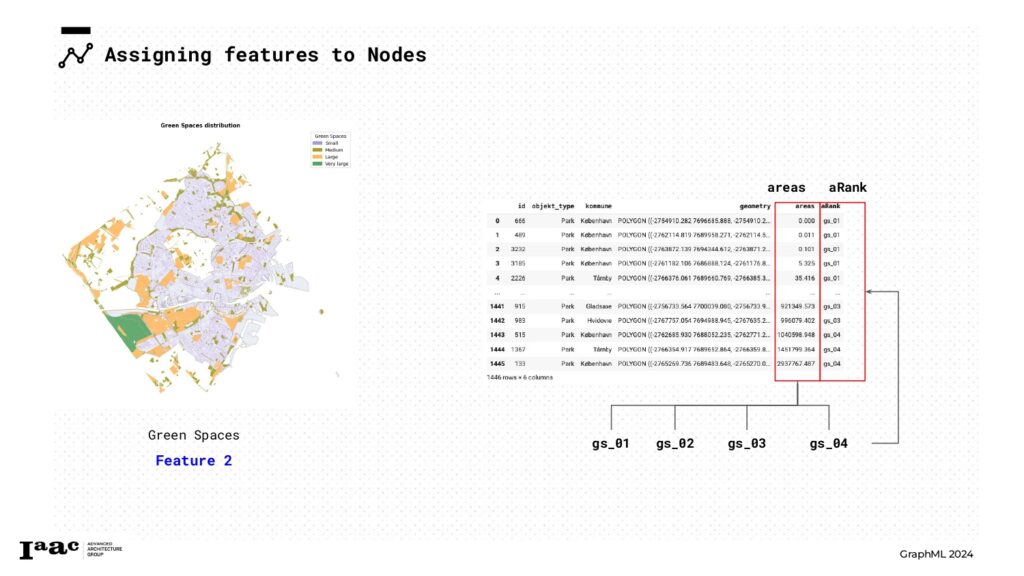
For the Green Spaces dataset, we employed the “Polygon” geometry of each park to measure its area. We then classified the green spaces into four categories based on the area of each geometry. This ranking was subsequently used to assign Green Spaces features to our graphs as node attributes.
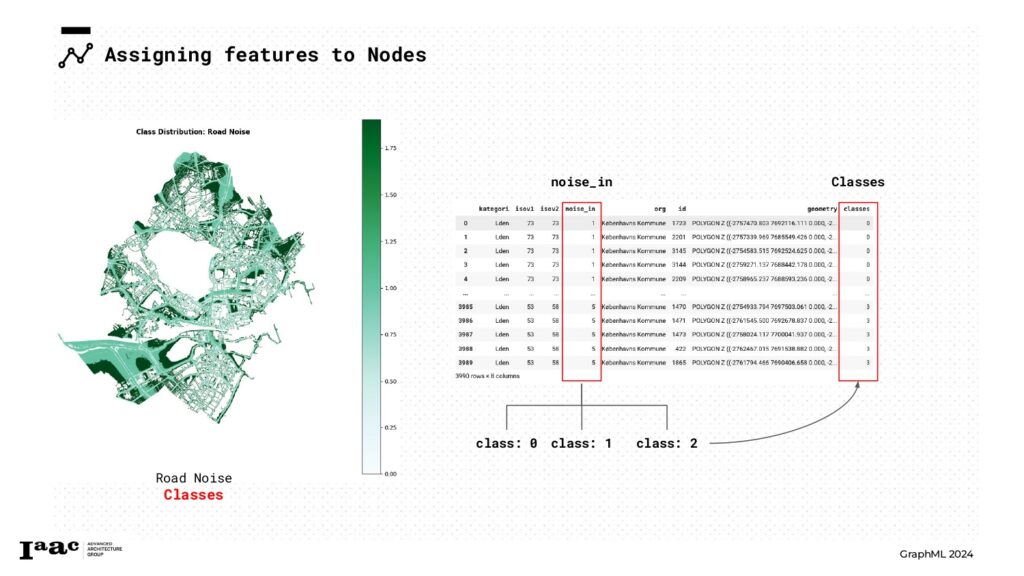
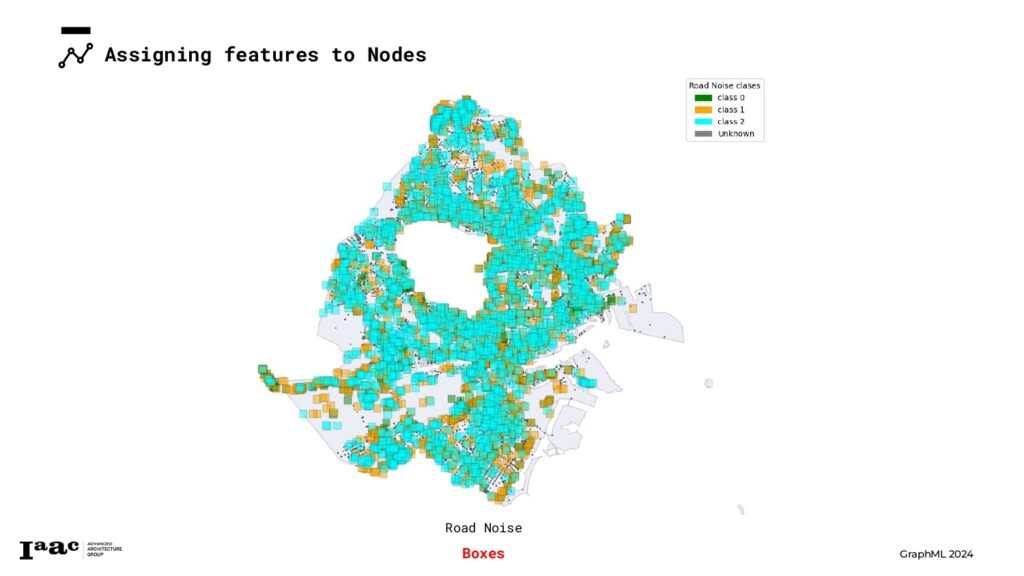
For the Road Noise dataset, we utilized the initial feature, “noise_in,” to create three distinct classes. These classes were then used to classify each node in the graph.
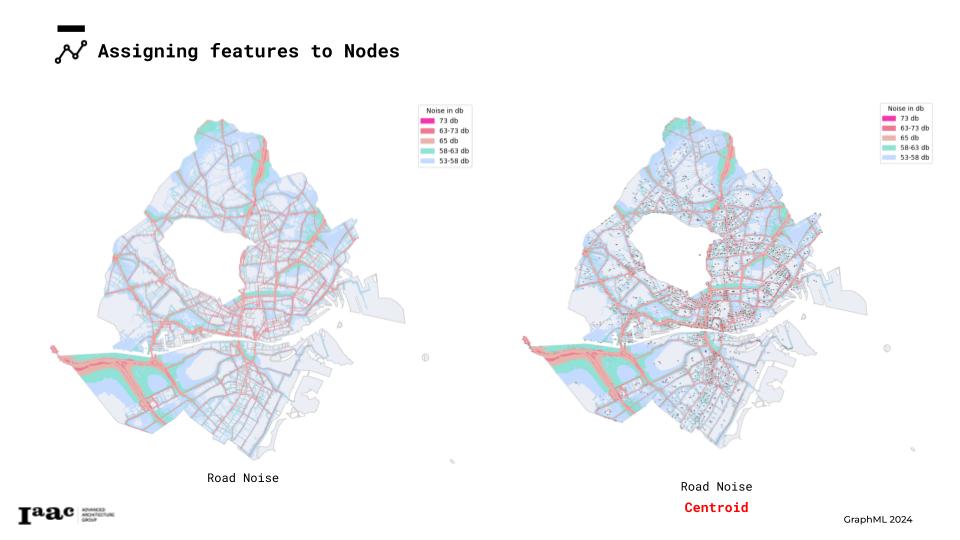
To classify the graph nodes into classes, we first identified the centerpoints for each road noise geometry. Next, we applied boxes to these centerpoints and classified the nodes based on the location within each box.
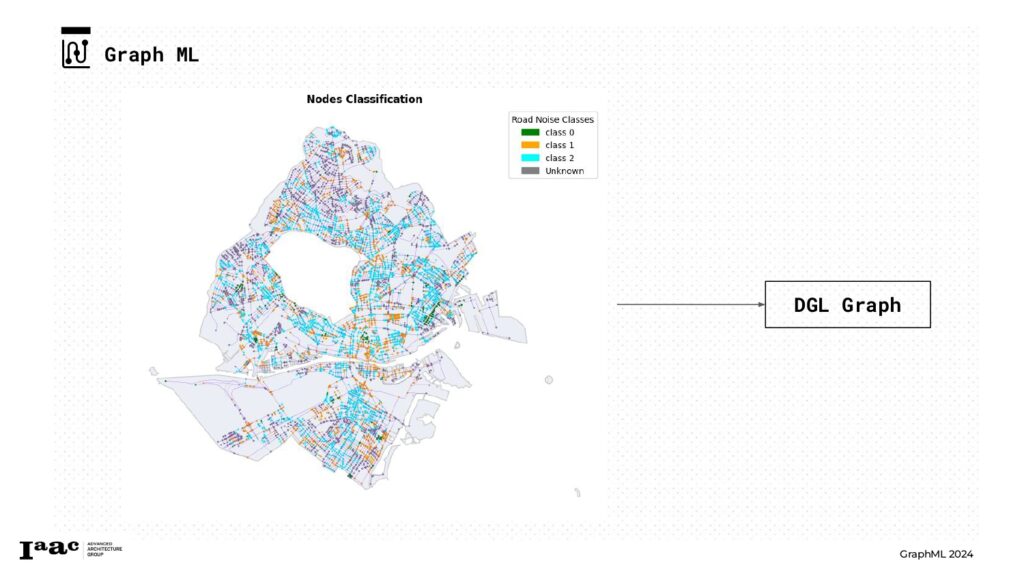
DGL Graph
With the graph now populated with attributes and classes, we proceeded to create a DGL (Deep Graph Library) graph. This enabled us to initiate training and predict the class of the unknown nodes.
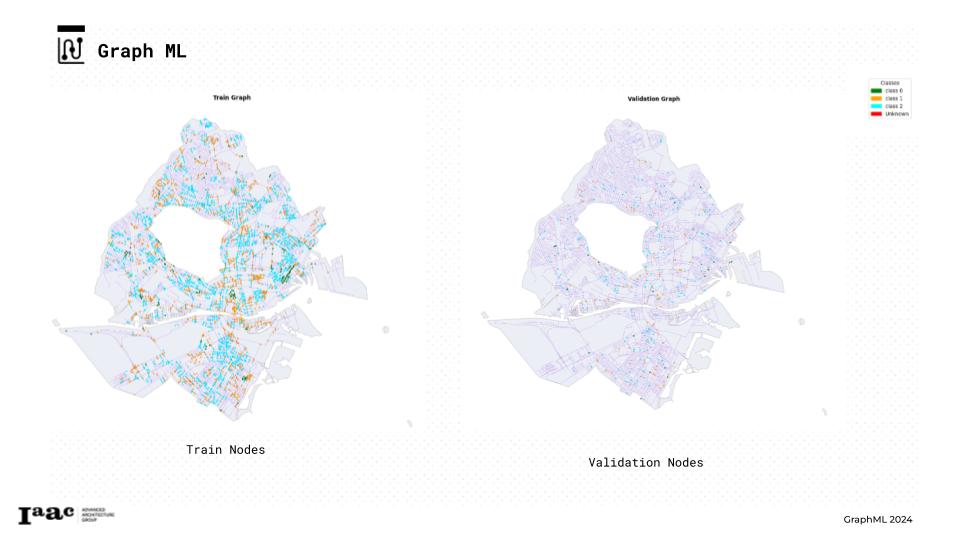
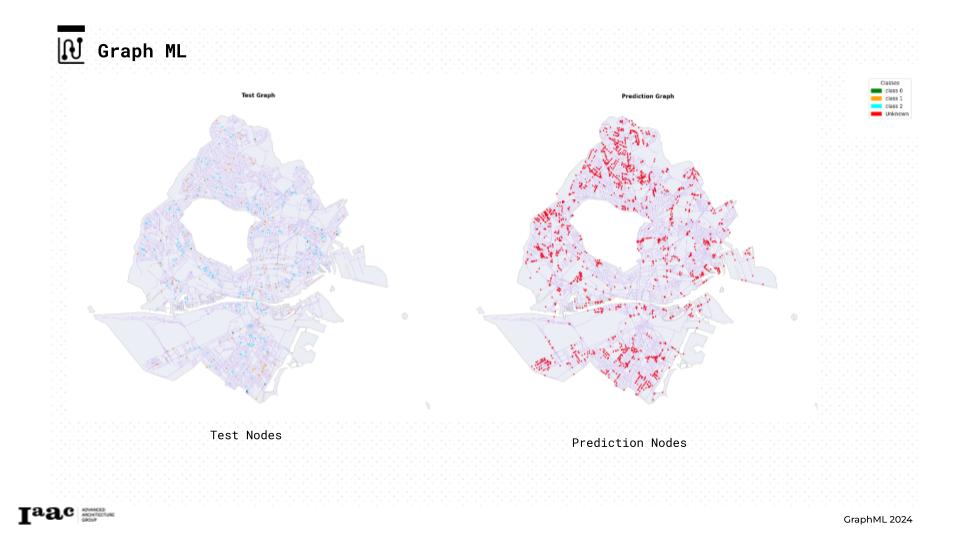
Training
For node classification, we prepared the nodes by splitting the dataset into the following categories:
- Train Nodes
- Validation Nodes
- Test Nodes
- And Prediction Nodes (the ones that are missing and we aim to predict)
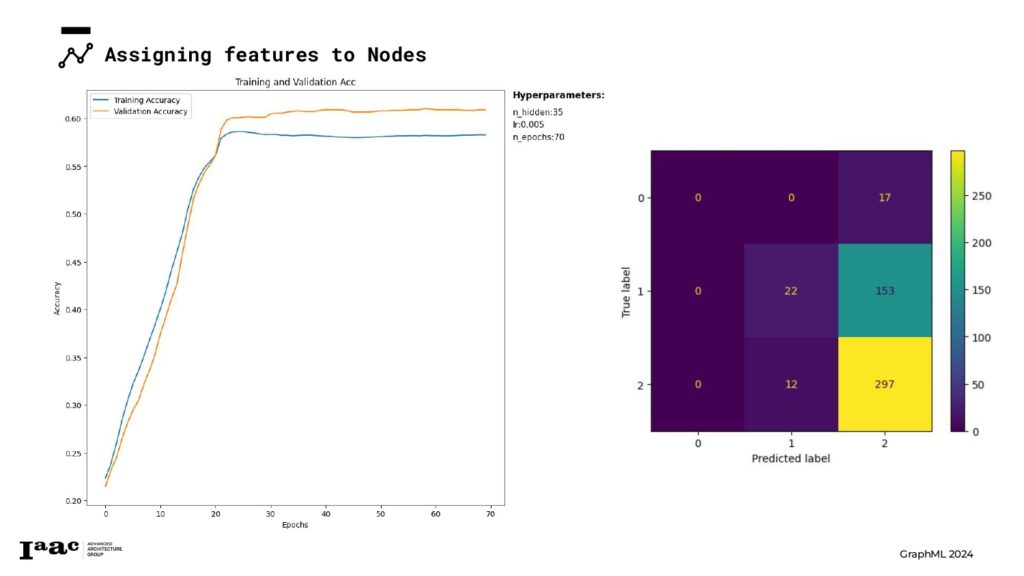
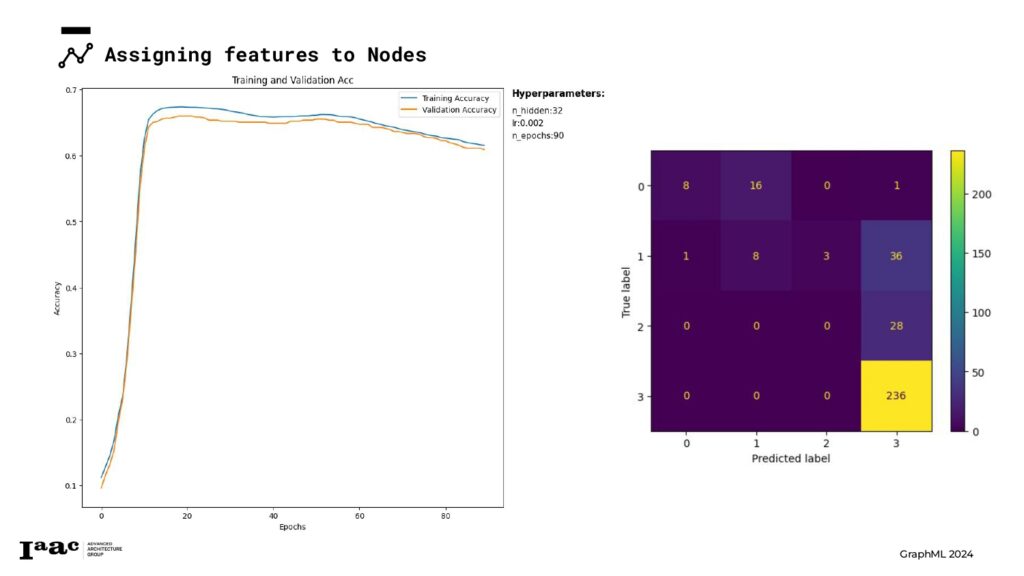
Next, we trained our model using various hyperparameters to determine the best fit for our data.

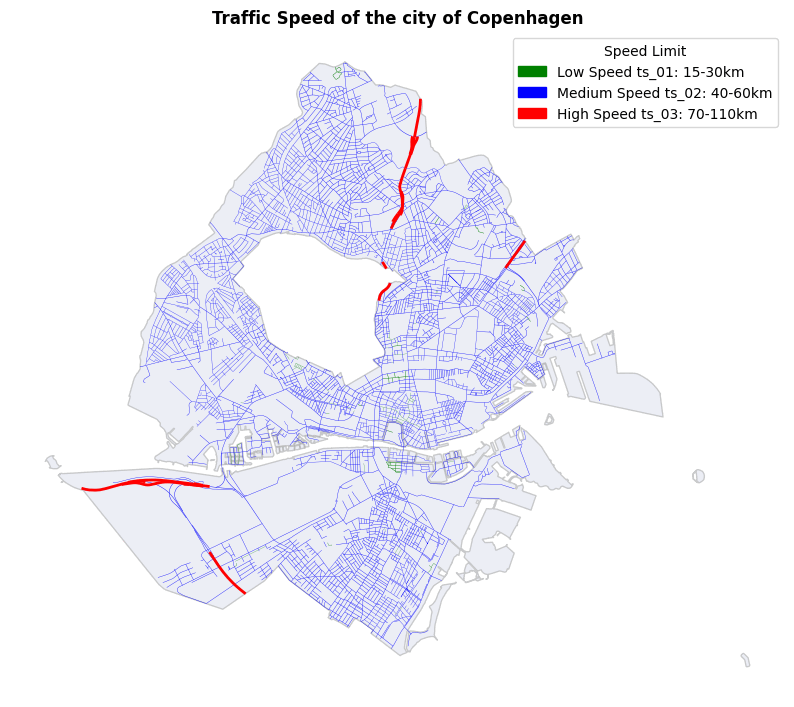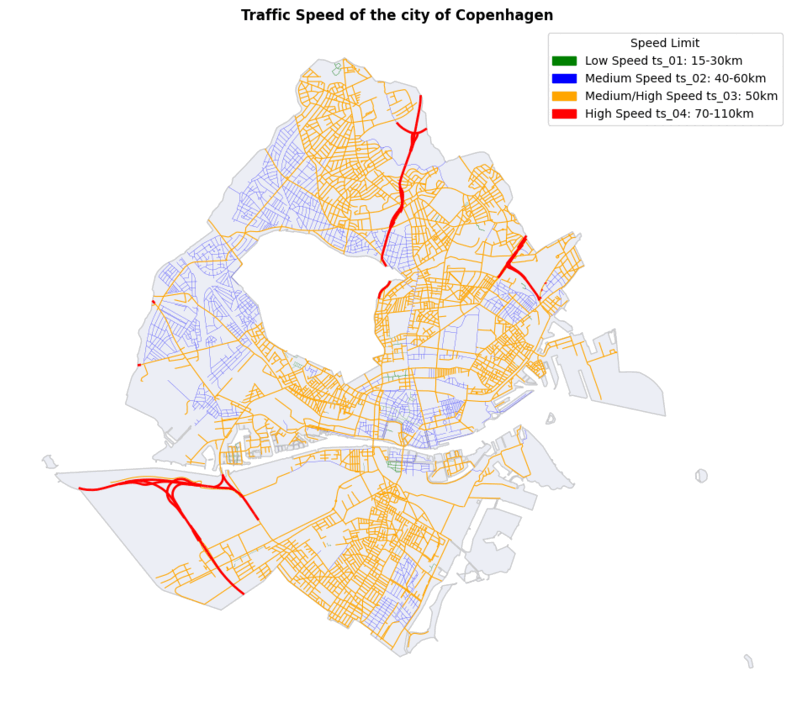
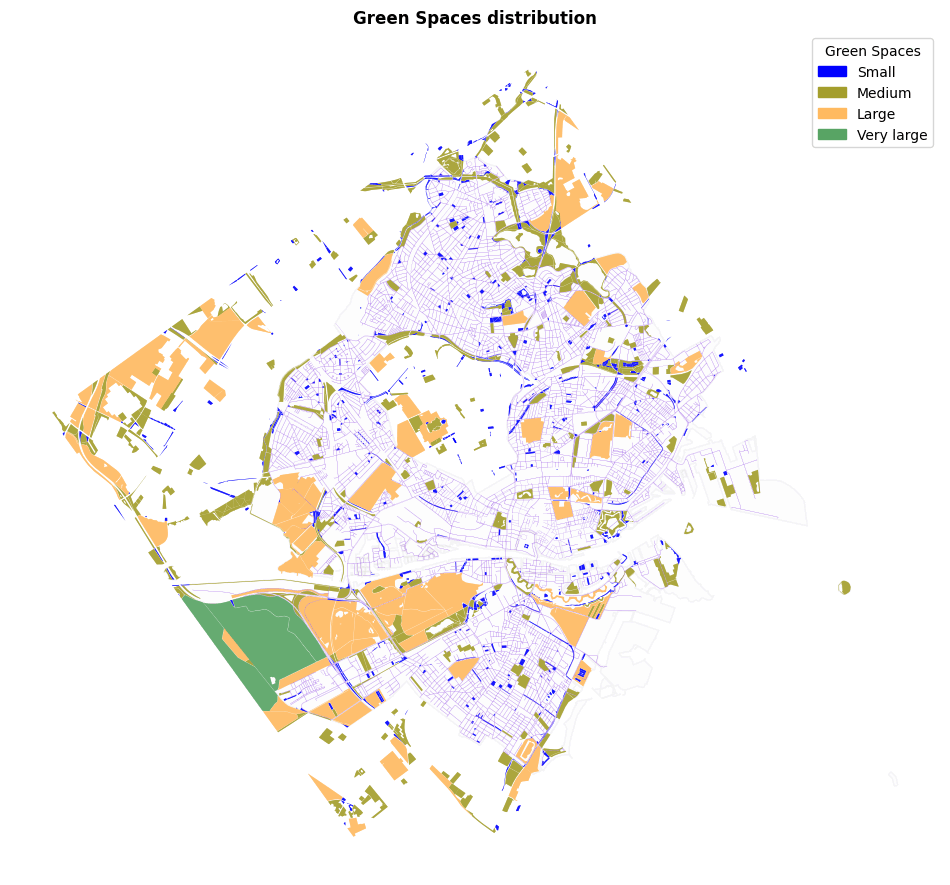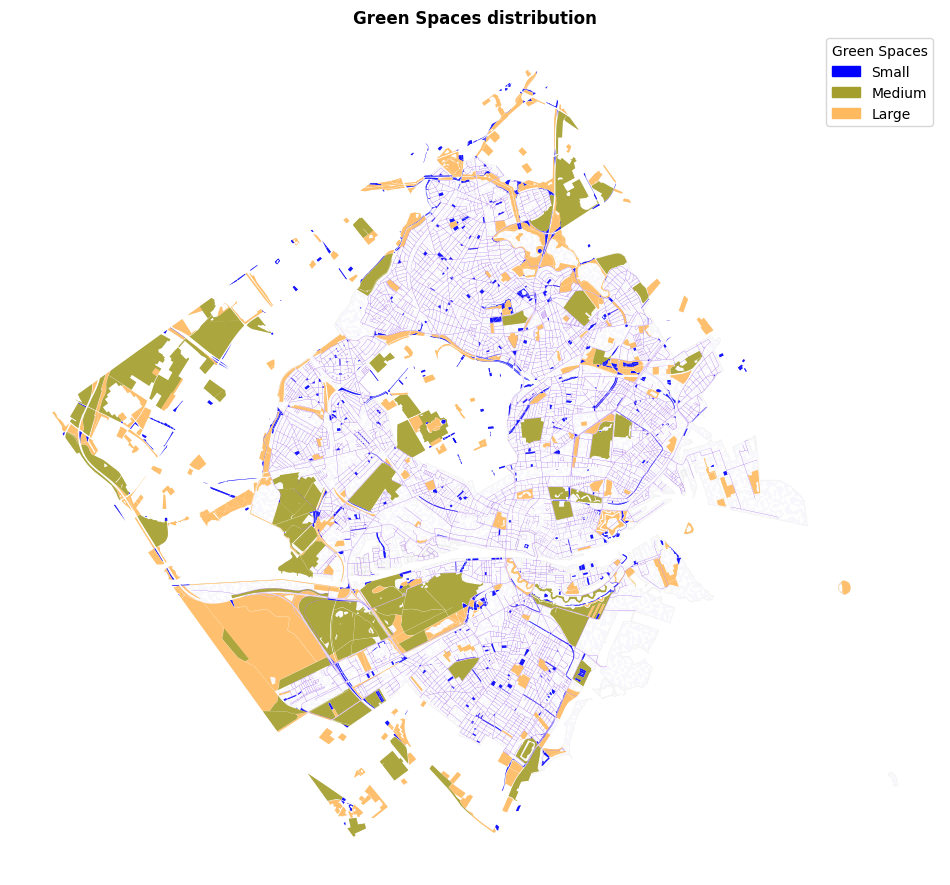
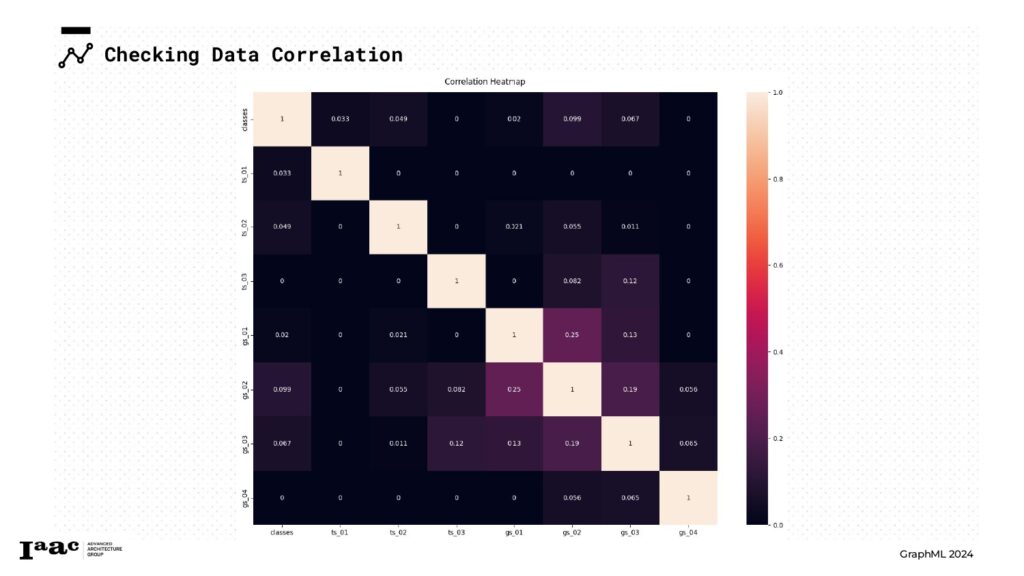
Since the model didn’t achieve good predictions, we decided to revise our categorization strategy for each feature. We explored adding an additional class and reclassified the feature attributes into different categories, applying the same adjustments to the classes.
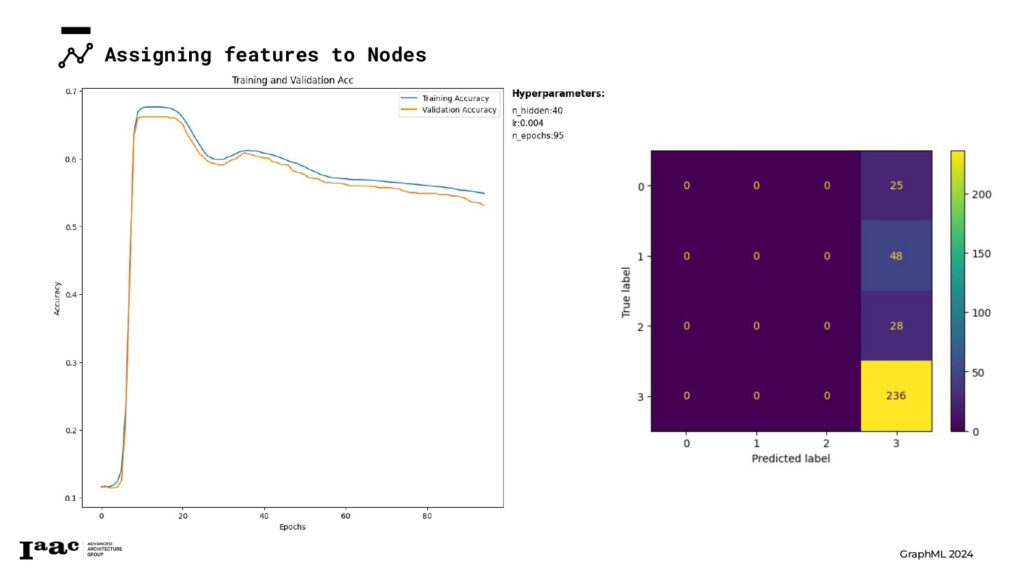
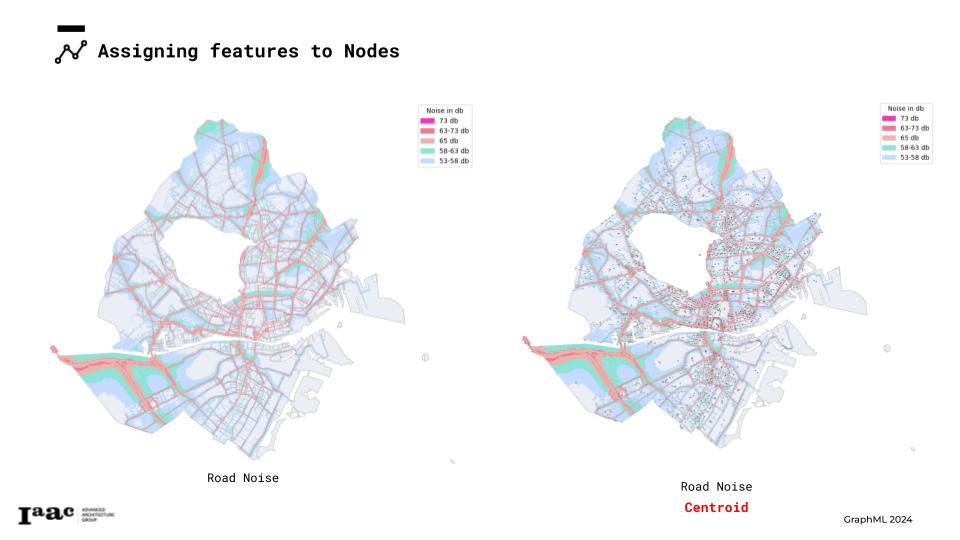
Since the model didn’t achieve good predictions, we decided to revise our categorization strategy for each feature. We explored adding an additional class and reclassified the feature attributes into different categories, applying the same adjustments to the classes. With the new setup, we trained the model again, but the prediction results were still not satisfactory. And finally, we achieved our completed graph on the right!
