
AI for Robotic Fabrication

Real-time control in fabrication spaces is essential for enhancing operational efficiency, minimizing risks, and ensuring worker safety. In dynamic manufacturing environments, accurately locating and tracking elements—such as machinery, tools, materials, and personnel—can drastically reduce accidents, optimize workflows, and streamline resource management. Through this project, we aim to integrate advanced sensing technologies, including IoT sensors, RFID tags, machine vision systems, and spatial computing techniques, to provide continuous spatial awareness. By establishing precise, real-time monitoring and location identification, the goal is to create safer, smarter, and highly responsive fabrication environments.

Technical Overview of YOLO-3D.
Integrating YOLO 3D object detection with advanced computer vision techniques opens a new dimension in fabrication space control, enabling precise, real-time 3D segmentation and localization of agents, tools, and machinery. By leveraging YOLO 3D’s robust spatial recognition capabilities—built upon deep learning and convolutional neural networks—this system continuously identifies and tracks objects with high accuracy, providing dynamic insights into operational activities. The result is a safer and highly responsive fabrication environment, where spatial intelligence and computational vision intersect to streamline workflows, minimize accidents, and redefine safety protocols within complex industrial settings.

YOLO-3D is an advanced artificial intelligence model utilized for enhancing safety and efficiency in robotic fabrication environments through real-time object recognition and depth analysis. Technically, the process involves capturing and processing video streams frame by frame as 2D NumPy arrays using the Ultralytics YOLO architecture, rapidly detecting and classifying objects such as humans, robots, and fabrication equipment. Post-detection, these 2D arrays are further processed by a transformer-based depth estimation model called Depth Anything, which computes pixel-wise depth maps, represented as 2D NumPy arrays, indicating the distance of each object from the camera. By merging the detection results and corresponding depth maps, YOLO-3D constructs accurate 3D bounding boxes, stored and manipulated as 3D NumPy arrays, providing comprehensive spatial awareness within the environment. Continuous monitoring of spatial proximity and depth correlations among detected objects enables YOLO-3D to swiftly identify potential safety hazards—such as a person approaching a robot too closely—and promptly trigger alerts to mitigate risks. This sophisticated integration of computer vision, depth estimation, and numerical array processing provides a robust and dynamic safety system ideal for managing interactions in fabrication spaces.
Current Limitations and Potential Improvements.

While YOLO-3D demonstrates significant capabilities in real-time object recognition and depth analysis, it still faces notable challenges, especially regarding detection accuracy in complex fabrication environments. The current model sometimes misclassifies objects—for instance, identifying robotic arms or equipment incorrectly as everyday items like bottles, refrigerators, or sandwiches. Such inaccuracies highlight the significant scope for further refinement and optimization. To enhance detection accuracy, it is crucial to consider fine-tuning the YOLO-3D model using domain-specific datasets, potentially incorporating transfer learning from other well-established pre-trained models. Additionally, integrating advanced augmentation techniques and enriching the training dataset with diverse, realistic scenarios from fabrication spaces could substantially improve model performance, ultimately achieving more reliable and precise object recognition.

Technical Roadmap
Our current workflow begins with importing and processing video footage, which may either be real-time or pre-recorded. Each video is segmented into individual frames for detailed analysis. These frames undergo processing through the YOLO-3D model, producing three distinct outputs: depth maps, segmentation masks, and RGB visualizations. After initial detections, the next critical step is fine-tuning the model using specialized, pre-trained models like Roboflow to enhance recognition accuracy specifically for human and robotic elements within fabrication environments.
Detailed Working Mechanism of YOLO-3D

YOLO-3D operates through a systematic pipeline comprising three main stages: feature extraction, prediction, and processing plus projection. Initially, during feature extraction, the CNN backbone—commonly Darknet-53—analyzes video frames extracted individually, converting raw pixel data into rich feature maps. Libraries such as OpenCV and PyTorch facilitate this process by handling image processing and neural network computations, respectively. In the subsequent prediction stage, the model thoroughly scans these feature maps to predict multiple aspects of detected objects, including 2D bounding boxes, object class identification, essential 3D parameters, and orientation. Finally, the processing and projection stage refines these raw YOLO-3D outputs, ultimately producing detailed and accurate visualizations of objects within 3D bounding boxes, enhancing spatial awareness and ensuring effective real-time monitoring and control within the fabrication environment.
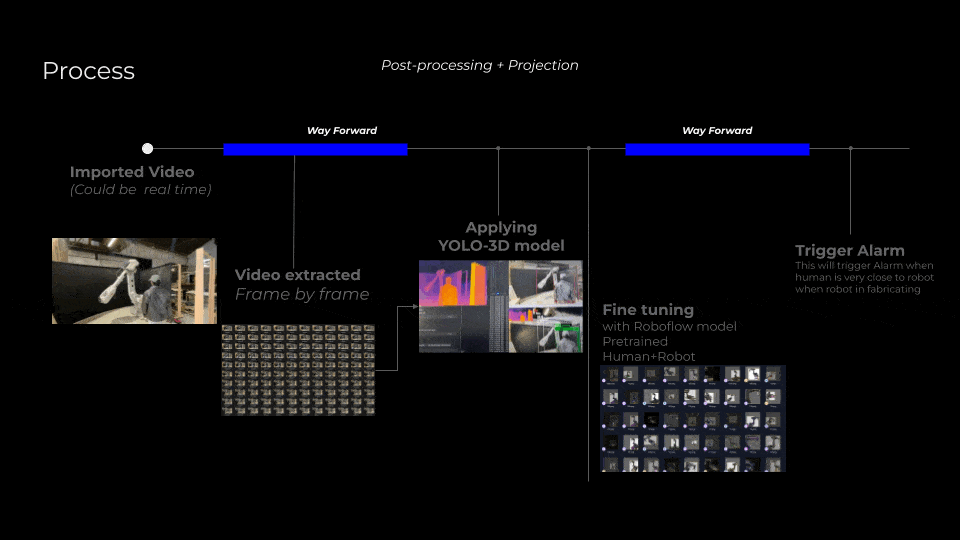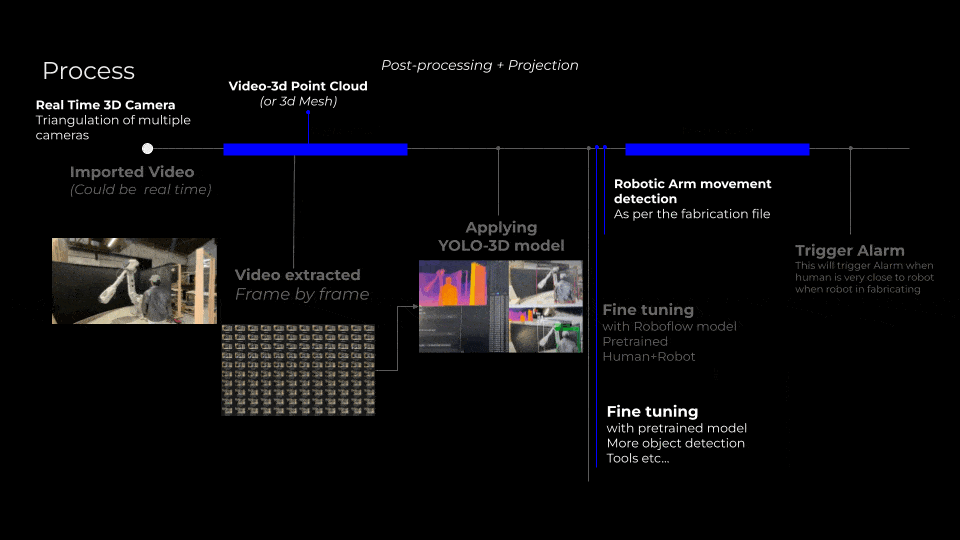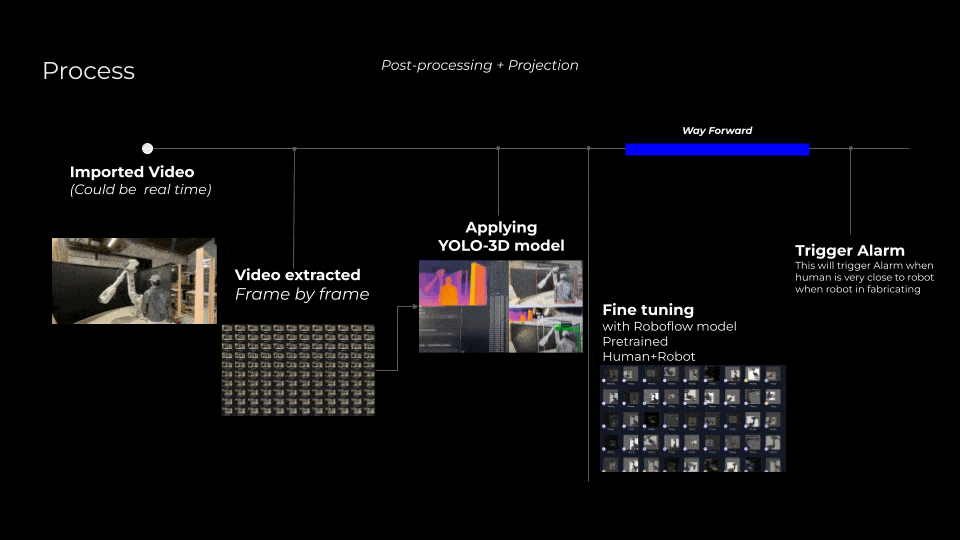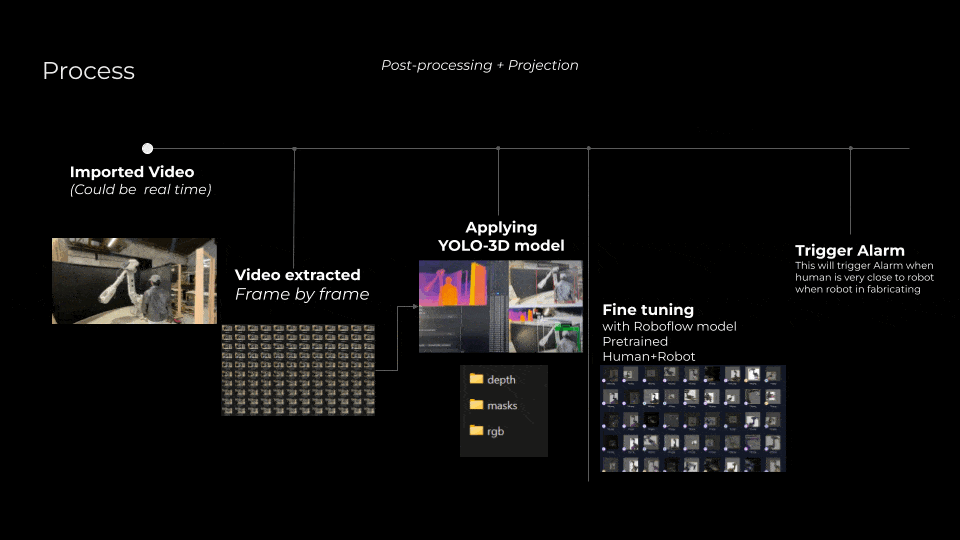
Way forward
Looking ahead, our next phase involves leveraging advanced techniques to further enhance spatial and temporal accuracy. We plan to integrate real-time 3D camera systems utilizing triangulation from multiple viewpoints to create highly detailed 3D point clouds or meshes, significantly boosting our model’s depth and spatial precision. Additionally, incorporating robotic arm movement detection aligned with specific fabrication files will enable a more accurate contextual understanding of operational dynamics. Finally, continuous fine-tuning with more comprehensive pre-trained datasets will allow for increasingly sophisticated object detection, recognizing an expanded variety of tools and equipment, thus ensuring the highest safety standards in robotic fabrication spaces.
https://github.com/samarth1864/AI_for_Robotic_Fabrication_3D_Segmentation.git
