
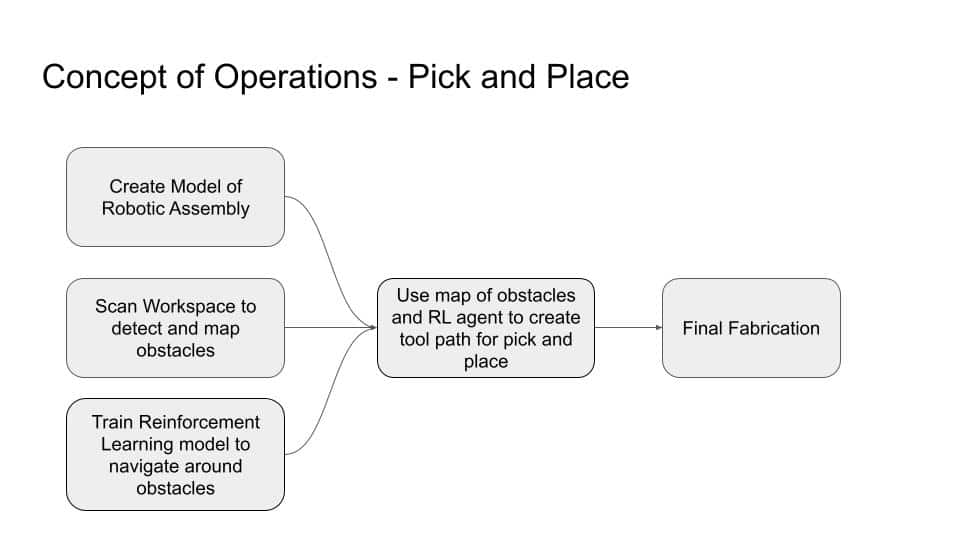
In pick-and-place robotics, a robotic arm must move from a start position to a target location (e.g., to pick or place an object) while safely navigating around obstacles. These obstacles may vary in size, severity, or risk — requiring the robot to adapt its path based on the workspace condition.
This project simulates the core decision-making process behind such motion using reinforcement learning (RL). We model the environment as a 2D grid world where the agent learns to move intelligently across the grid while avoiding high-risk zones.
🧠 What We Built
We created a custom Gymnasium environment where:
- The agent starts in a random position on the top row
- The goal is located on the bottom center (simulating the “place” zone)
- The grid contains randomly placed obstacles with varying risk levels:
- 🔵 Blue = low severity (passable)
- 🟨 Yellow = medium severity (avoid if possible)
- 🔴 Red = high severity (must avoid)
- The agent can move in 8 directions, mimicking flexible robotic motion
Using Q-learning, the agent is trained over hundreds of episodes to:
- Reach the goal efficiently
- Avoid obstacles
- Learn movement strategies that generalize to new layouts
🤖 Application to Robotics
This setup reflects a real robotic pick-and-place scenario where:
- A vision system maps the workspace and classifies obstacles
- The map is translated into a grid environment
- The RL model guides the robotic arm’s movement to:
- Pick up objects
- Place them in target zones
- Avoid dangerous or cluttered areas
This logic applies to:
- Robotic arms on fabrication lines
- Warehouse sorting robots
- Mobile manipulators navigating tight spaces

Where do we get the data?
This simulation doesn’t use external data — the training environment was synthetically generated using Gymnasium to model a robotic workspace.
In real applications, this data would come from a robotic perception system, such as cameras or depth sensors, which scan the environment and classify obstacles by size, shape, or risk level.
For future development, we can integrate this RL model with a real robot, using vision-based mapping to dynamically create the grid and train on real-world obstacle layouts.
Github repo to check the code: https://github.com/michelecobelli/Reinforcement-Learning-for-Robotic-Pick-and-Place
Future scopes
This reinforcement learning framework can be extended to mobile robotic platforms such as autonomous rovers.
By integrating with real-time mapping systems (e.g., LiDAR or depth cameras) and object detection pipelines like those used on TurtleBot, the RL agent could:
- Navigate unknown environments
- Dynamically avoid obstacles of varying severity
- Learn optimal paths for exploration or task completion
