
Semiocity — Semiotic-Aware Urban Image Generation
This is part of the Academic work at Iaac Barcelona for the Master’s Program im Advance Computation for Architecture and Design 2024-2025
Repository for the Master Thesis “Semiocity: Generating Semiotic‑Enriched 3D Models from Text Inputs”
Degree: Master in Advanced Computation for Architecture and Design (MaCAD), Institute for Advanced Architecture of Catalonia (IaaC)
Primary authors: Jose Lazokafatty (https://github.com/DrArc/semiotic_world_agent), Francesco Visconti Prasca (https://github.com/fviscontiprasca/semiotic_labelling.git), and Paul Suarez Fuenmayor
Thesis Adviser: David Andrés León
Abstract
This repository implements a modular, reproducible pipeline for producing semiotic‑aware architectural images from textual prompts and for preparing semiotic conditioning information for downstream 3D generation. The approach combines multi‑modal feature extraction (captioning, segmentation, semantic embeddings), curated real and synthetic datasets, and fine‑tuning of diffusion models (Flux.1dev through both LoRa adapters and full model fine-tuning approaches.
The codebase supports: dataset preparation and unification, BLIP‑2 captioning, segmentation with SAM (and optional YOLO variants), comprehensive semiotic feature extraction with architectural style and urban mood analysis, Flux.1d data preparation with both LoRa and full fine‑tuning variants, evaluation, and inference
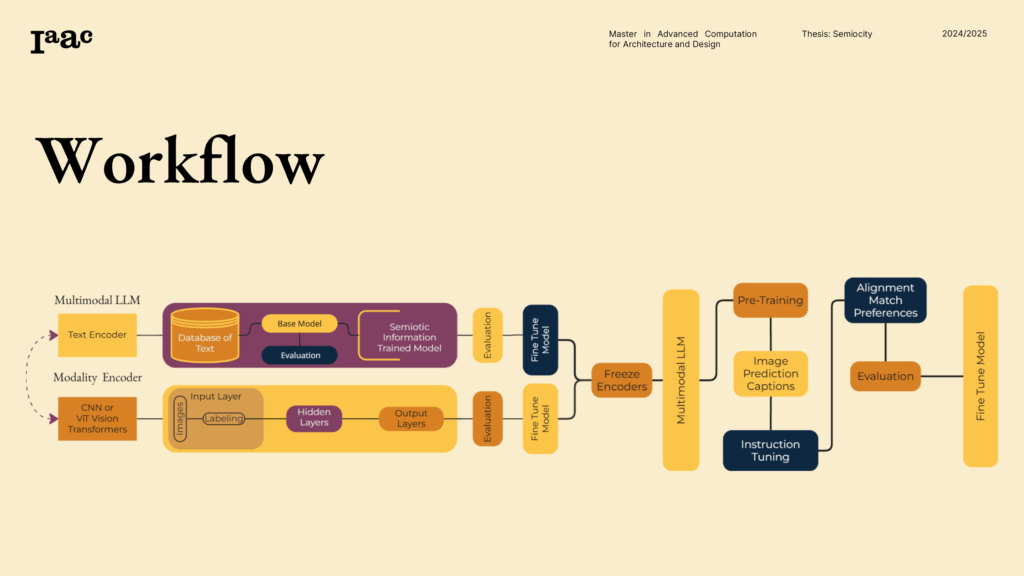
The Image-Encoder Journey: Teaching a Model to “Read” the City
Why this matters
Cities aren’t just concrete; they’re languages. Our image encoder learns that language. It doesn’t just see “a building”; it recognizes mood, style, materials, and the social signals baked into form. That understanding becomes the bedrock for everything downstream—better prompts, smarter training data, and images that carry meaning, not just pixels.
Step 1 — Curate the urban library
We start by blending real streets (from Open Images) with a purpose-built synthetic set called Imaginary Cities. The goal isn’t volume for its own sake; it’s a balanced diet—historic corners next to glass boxes, plazas next to megastructures—so the encoder hears many “dialects” of the urban language.
Step 2 — Let captions tell the story
With BLIP-2, each image gets a layered description: not only “what” is there (facades, canopies, setbacks) but “how it feels” (serene, monumental, vibrant) and “what it implies” (public vs. private, procession vs. shortcut). These captions act like museum labels for the model, guiding attention toward semiotic clues rather than just textures
Step 3 — Map the parts that matter
Using SAM, we segment the scene into meaningful chunks—street, tower, base, roofline, void—so the encoder learns that a plaza isn’t a leftover; it’s a stage. By pairing masks with the captions, we connect “this mood” to “that geometry,” which is where semantics meets structure
Step 4 — Distill the semiotics
Now we fuse it all: text embeddings from the captions, segmentation stats, visual cues like composition and symmetry. Out comes a compact “conditioning vector” that carries style labels (brutalist, classical, modern), urban mood (calm, energetic, contemplative), materials, and cultural context. It’s like turning a messy sketchbook into a sharp index card the model can act on.
Step 5 — Hand it to the generator
Finally, we package images plus their semiotic vectors for training. Whether we fine-tune light adapters (LoRa) or the full diffusion model, the encoder’s work ensures the generator isn’t guessing. When it invents a street, it’s not just “plausible”—it’s legible. That’s the difference between eye candy and urban thinking
Semiocity in Practice: From Text to a Walkable Idea (UI-Driven Pipeline)
A single door into the whole workshop
Open one app and run the entire trip from sentence to scene. The PyQt interface is the conductor: type a prompt, choose how bold or restrained you want the output, and watch the pieces line up—image generation, cleanup, 3D, and viewing. It’s deliberately simple on the surface, because the complexity underneath is already doing the heavy lifting.
Write it, see it
You start with a text prompt. The system spins up a Flux model—fast for drafts, higher-quality for hero shots—and gives you an image that understands urban tone as much as outline. Think “sun-bleached social housing with generous stair landings” instead of “generic block with windows.”
Clean the canvas
Background removal with the flux-Kontext-dev variant trims away visual noise so forms read cleanly. This is not a gimmick; it’s stagecraft. Strip the set and the story reads louder—edges, thresholds, circulation moves.
Push into space
Next, Hunyuan3D takes the 2D frame and extrapolates volume, producing a mesh you can orbit and interrogate. It’s the moment a still becomes a place. The default format is GLB for painless sharing, because nobody should need a PhD to open a model.
Walk the result
The viewer loads inside the app, so your feedback loop is tight: rotate, zoom, sense proportion, then tweak your prompt or run the full pipeline again. You can keep it playful (quick drafts) or meticulous (dial steps, lock seeds, compare variants) depending on where you are in the design sprint.
Quality without the drama
GPU acceleration is baked in, errors are caught and explained, and models cache so you’re not redownloading the universe. If you want speed, you use the schnell preset; if you want craft, you climb the steps. Either way, the UI keeps you focused on spatial decisions, not dependency wrestling.
Where the tech meets the thesis
Under the hood, this workflow connects back to the semiotic encoder: captions, segmentation, and style-mood conditioning inform the generator, so outputs feel about cities, not just of cities. That through-line—from meaning to mesh—is the whole point
User Interface
What it is
This is a local AI agent running entirely in LM Studio, fine-tuned from google/gemma-3n-e4b with vision enabled. In plain English: it’s a small, sharp multimodal model that lives on your machine, reads images as well as text, and speaks architecture
What it actually does for you
The agent is the connective tissue of the Semiocity flow. It helps generate prompts, read images to describe them, do basic analyzing of the generation refinement the semiotic tokens. It also narrates why—“ramp = procession,” “grid = bureaucratic clarity,” “cantilever = structural bravado”—so the next iteration isn’t just prettier; it’s more legible.
Agent Interface
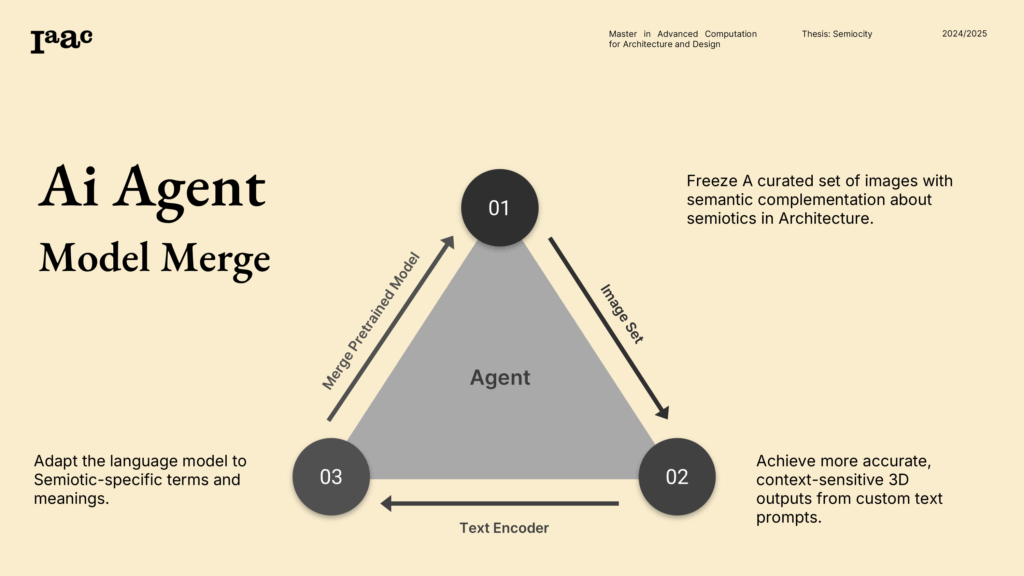
Why the Gemma fine-tuning?
Base Gemma knows language. Your fine-tuned Gemma knows architectural language. It maps images and text to a shared semiotic space:
Action proposals: not just “describe,” but “do”—export tokens, nudge prompts, pick training cuts, or flag low-coherence outputs.
Style awareness: brutalist, classical, modern, parametric—recognized from both geometry and cues like rhythm and massing.
Mood inference: contemplative vs. vibrant vs. monumental, tied to lighting, openness, and procession.
How it coordinates the pipeline (function calling, simply put)
The agent exposes a few tool endpoints inside LM Studio:
generate_flux_image(prompt, steps, seed)remove_background(path)image_to_3d(path, quality)open viewer(path)
You talk; it chooses tools; the UI shows progress. No command-line calisthenics, just one conversation that drives the whole rig.
Limitations
Poor, low-contrast references lead to mushy semiotic reads.
It won’t replace a structural engineer. Cantilever bravado still needs physics.
Extremely niche styles outside the fine-tuning set may require a reference image or a few-shot prompt.
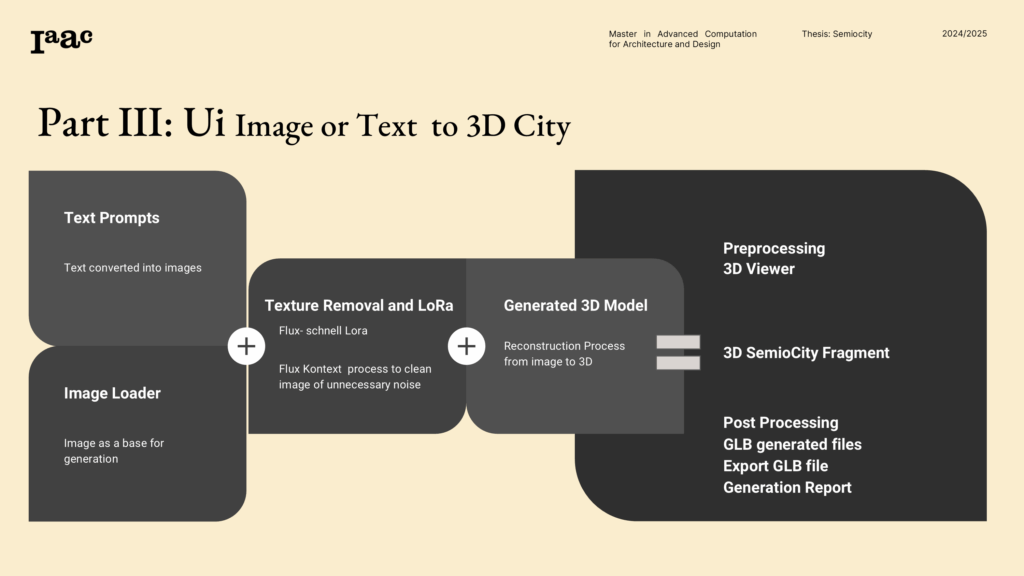
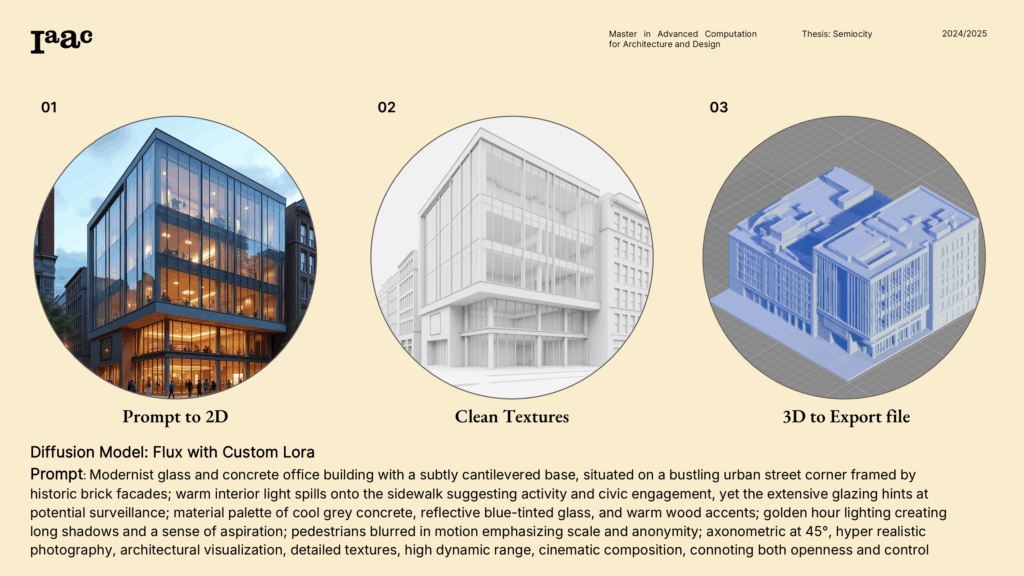
Generate the 2D Concept (Flux)
Start with a clear prompt that mixes form + mood + use: e.g., “civic hall on a plinth, ceremonial ramp, calm morning light.” Use FLUX.1-schnell for fast drafts, FLUX.1-dev when you care about edges and detail. Aim for readable silhouette and clean foreground/background separation—you’re feeding a 3D engine next, not a mood board.
Pro tip: Keep horizon straight, avoid extreme lens warps, and center the hero mass. Garbage perspective in = rubbery mesh out.

2) Clean the Image (Kontext Background Removal)
Run background removal to isolate the architecture. This isn’t cosmetic—it gives the 3D stage a clean cutout so volumes solve correctly. Check for missing edges (stairs, railings) and wispy sky holes; patch obvious gaps before moving on.
Pro tip: If the subject melts into the sky, add a faint backdrop or color plate before removal. Contrast is preferred.

3) Lift to 3D (Base Hunyuan3D)
Send the cleaned image to an edited Hunyuan3D pipeline for image-to-mesh generations. The model infers depth, closes volumes, and spits out a GLB. Expect a concept-accurate massing, not BIM. You’re validating space, proportions, and key moves (plinth, ramp, setbacks), not counting rebar. This opens the doors for conceptual explorations, where a rapid 3d mass can help at the beginning of the design process.
Pro tip: If the mesh looks “puffed,” reduce texture influence and rerun at a smaller resolution.
Generation Interface
Review, Iterate, Export (Built-in Viewer)
Opens the GLB in the 3D integrated viewer. Orbit, zoom, check approach sequences and sectional reads. If the story’s off—plinth too timid, ramp too steep—tweak the prompt and loop. When it sings, export the GLB for handoff or quick lighting tests elsewhere. as Rhino3d or directly open from the open mesh file in the viewer to connect to the local windows 3d viewer, to observe the mesh with different attributes, mesh colors, and quick sun light rotations.
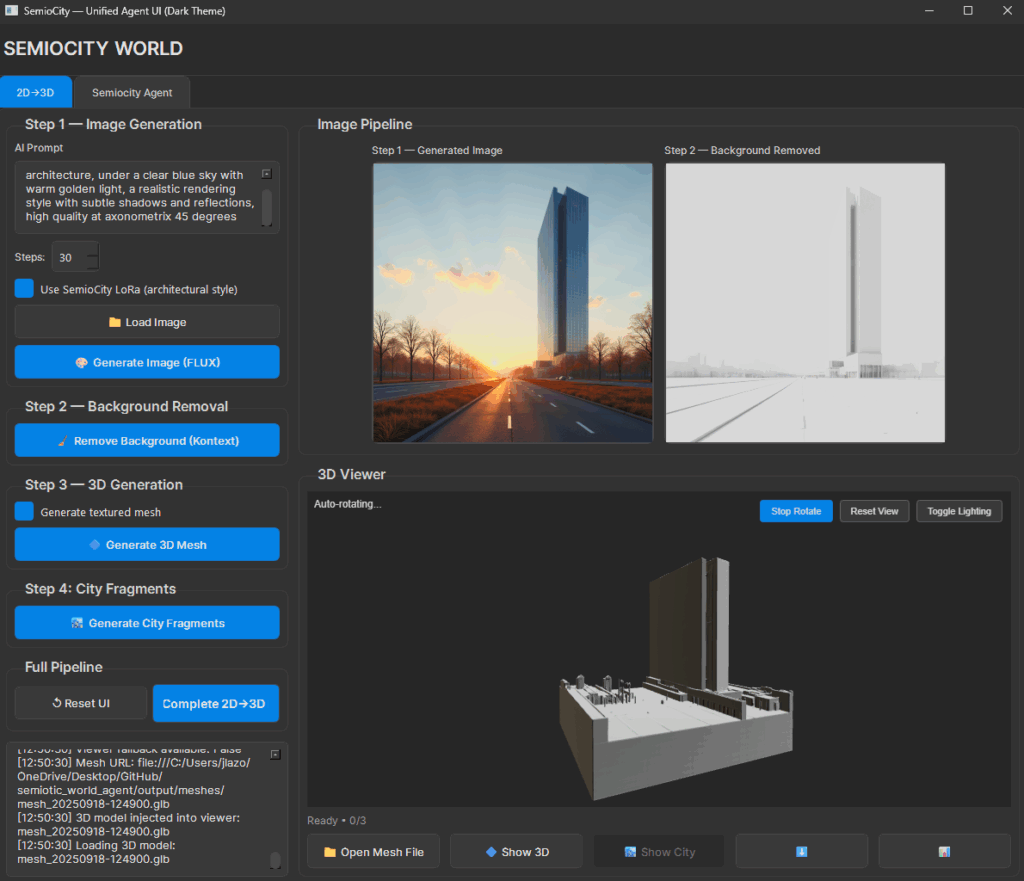
Pro tip: Keep a tight loop: (a) tweak prompt tokens, (b) regenerate image, (c) reuse the same background-removal settings, (d) re-mesh. Save versions.
Step 4, City Generation

City from generations
The goal
Give the agent a vision analysis capability to identify shapes and images to build the city fragment.
Imagine opening a drawer of little city pieces and pouring them onto a grid table.
Each GLB file is a piece within a neighborhood, each of it with its own temperament or semiotic Identity.
The grid becomes a stage where styles riff off each other. Start by treating the empty plane like a map you’re composing, not a warehouse floor. Give yourself “streets” of different moods: an avenue of civic confidence, a lane of experimental housing, a quiet mews of galleries and cultural odds-and-ends. Let contrast do the storytelling—brutalist weight beside a silky curve, a severe grid across from a playful prow—so the eye strolls, pauses, and forms opinions.
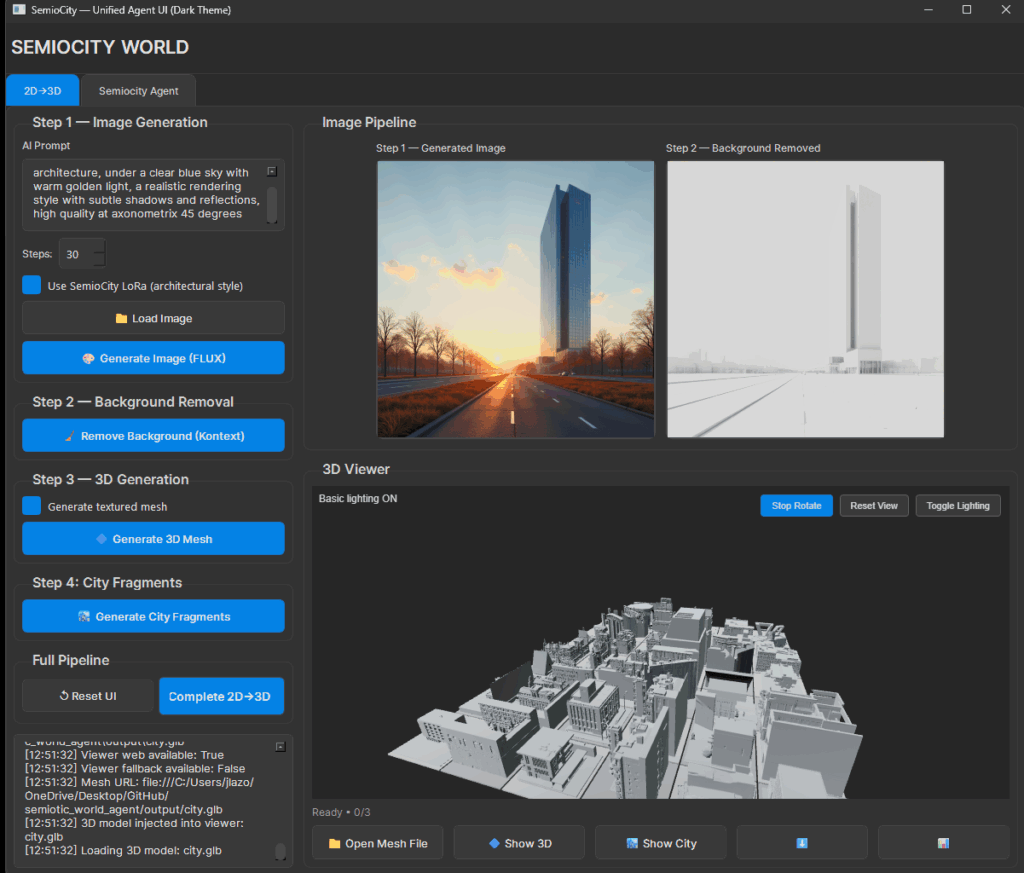
The inspiration came from the philosophical idea that the city is a playground of ideas, from each constructed building it is a unique source of inspiration while contributing or enhancing in the existing stylistic identity.
The integration of Ai vision capabilities to sort and classify the semiotic identity, is a future development work, as during experimentations there is not semiotic control about which GLB file is selected.
Pro Tip: Make sure have at least 42 different models to fill up the grip, in future work the corpus must me at least 3 times that in order to create better results
Acknowledgements and credits
3D Generation
hunyuan3d22025tencent, title={Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation},
Author={Tencent Hunyuan3D Team},
year={2025}, eprint={2501.12202}
Flux Dreambooth LoRA Train
Collab Book
“notebook uses Hugging Face Diffusers package to create image generation pipelines”
Authors: Nono Martínez Alonso, James McBennett & Michal Gryko
Flux Pipelines
https://huggingface.co/docs/diffusers/en/api/pipelines/flux https://huggingface.co/black-forest-labs/FLUX.1-Kontext-dev https://huggingface.co/black-forest-labs/FLUX.1-schnell
Author: Black Forest Labs
Year-2024
Removal of background Process
Michal Gryko’ ComfyUi- Flux-Kontext Workflow
Youtube.com/watch?v=wmrHeIvLLjM&t=29s
Text LLM Finetuning Agent Model Fine-tuning
Base Model google/gemma-3n-e4b vision enable
Literary resource Extraction of the description of cities from Academic and fantasy books- Complete list of titles in the acknowledgements read me page in GitHub
