
Introduction
BIM and Cloud Adoption
The construction industry is still experiencing a digital revolution led by the widespread adoption of Building Information Modeling (BIM) and cloud computing technologies. BIM has established itself as the central tool for the digital planning, construction and management of buildings, while cloud computing is transforming collaboration and data access.
Studies show the spread of these technologies: 70% of companies in the construction industry have already implemented BIM, while 80% use cloud computing solutions. These high adoption rates underline the growing awareness of the benefits of digital technologies in the construction industry.
The correlation between company size and technology adoption is particularly noteworthy. For companies with more than 25 employees, the adoption rate of BIM and cloud technologies is at 77%. This illustrates that larger organizations often have the resources and the need to invest in advanced digital solutions.
Despite these high adoption rates, many organizations face significant challenges in using these technologies effectively. The complexity of BIM models and the difficulty of extracting and interpreting relevant information remain substantial hurdles. Many users struggle to exploit their digital tools’ full potential, especially when extracting data, information and knowledge from their models.
This discrepancy between high adoption and effective use underscores the need for more intuitive, user-friendly data extraction and analysis solutions in BIM environments.
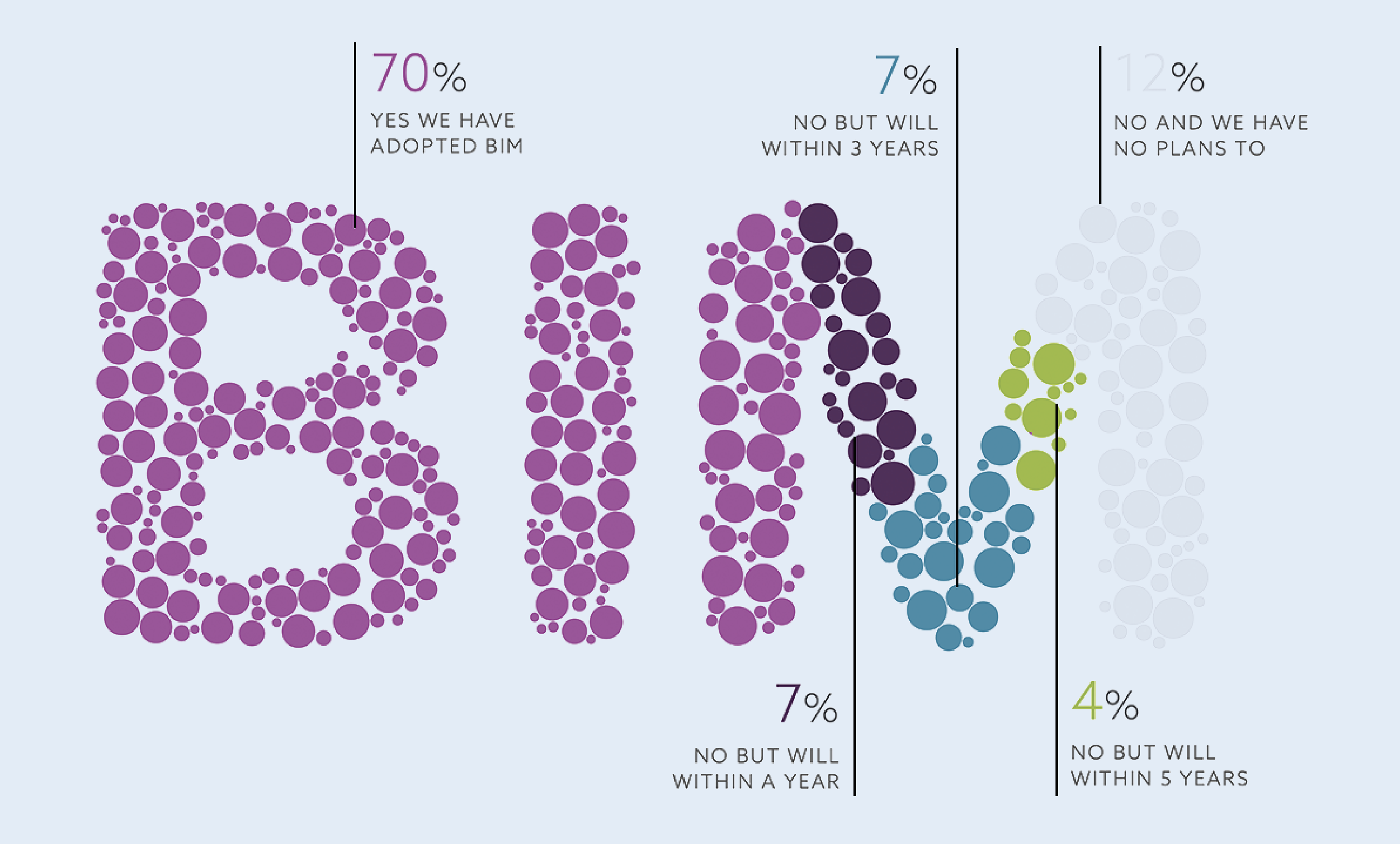

Design Intelligence
In the context of increasing digitalization, the concept of “design intelligence” is becoming increasingly important in the construction industry. Design intelligence is the ability to extract valuable insights from the vast amounts of data stored in BIM models and use them to make smarter, more efficient design decisions.
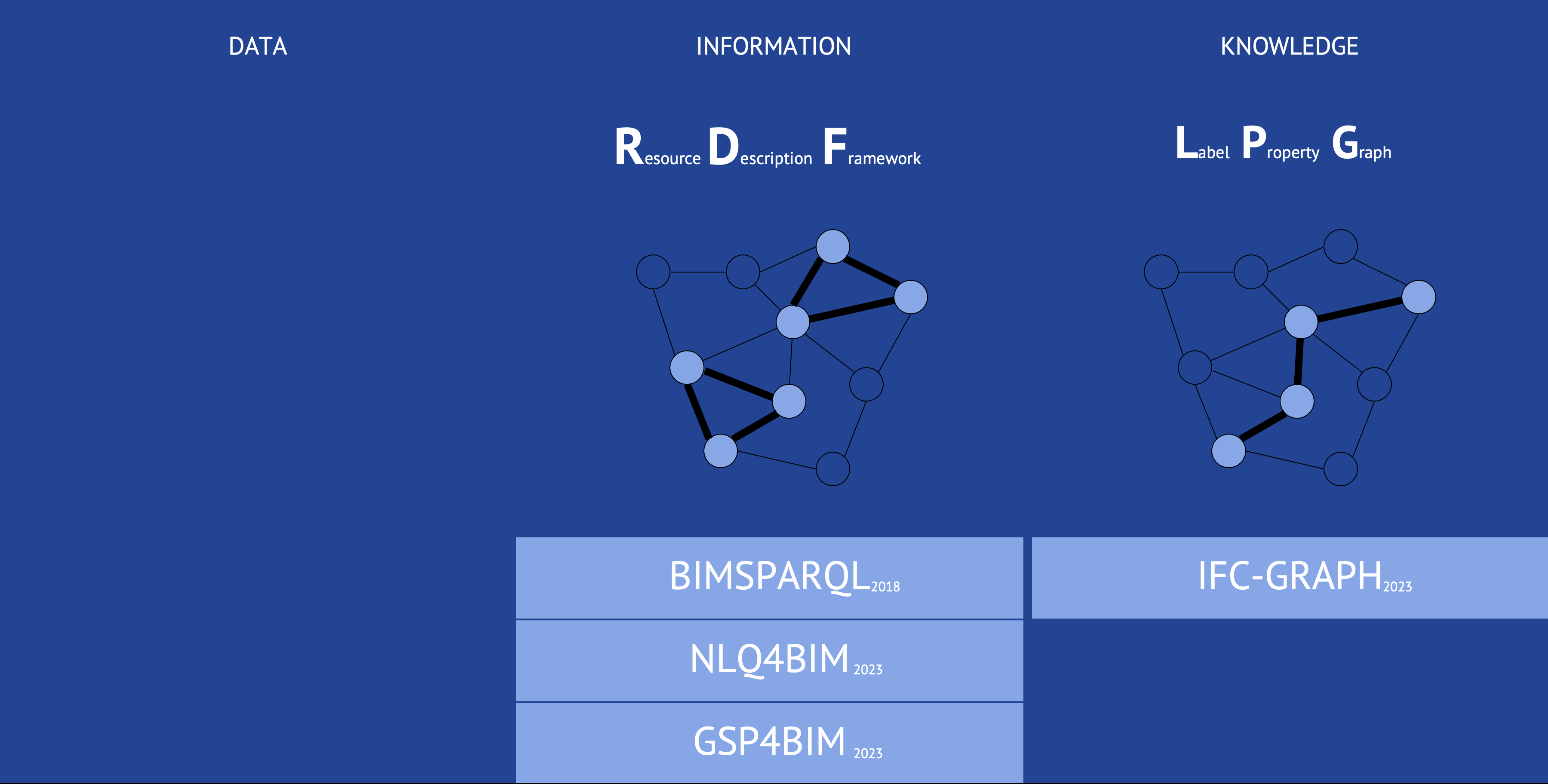
To understand the complexity and potential of design intelligence, it is helpful to consider the concept of Ackoff‘s knowledge pyramid:
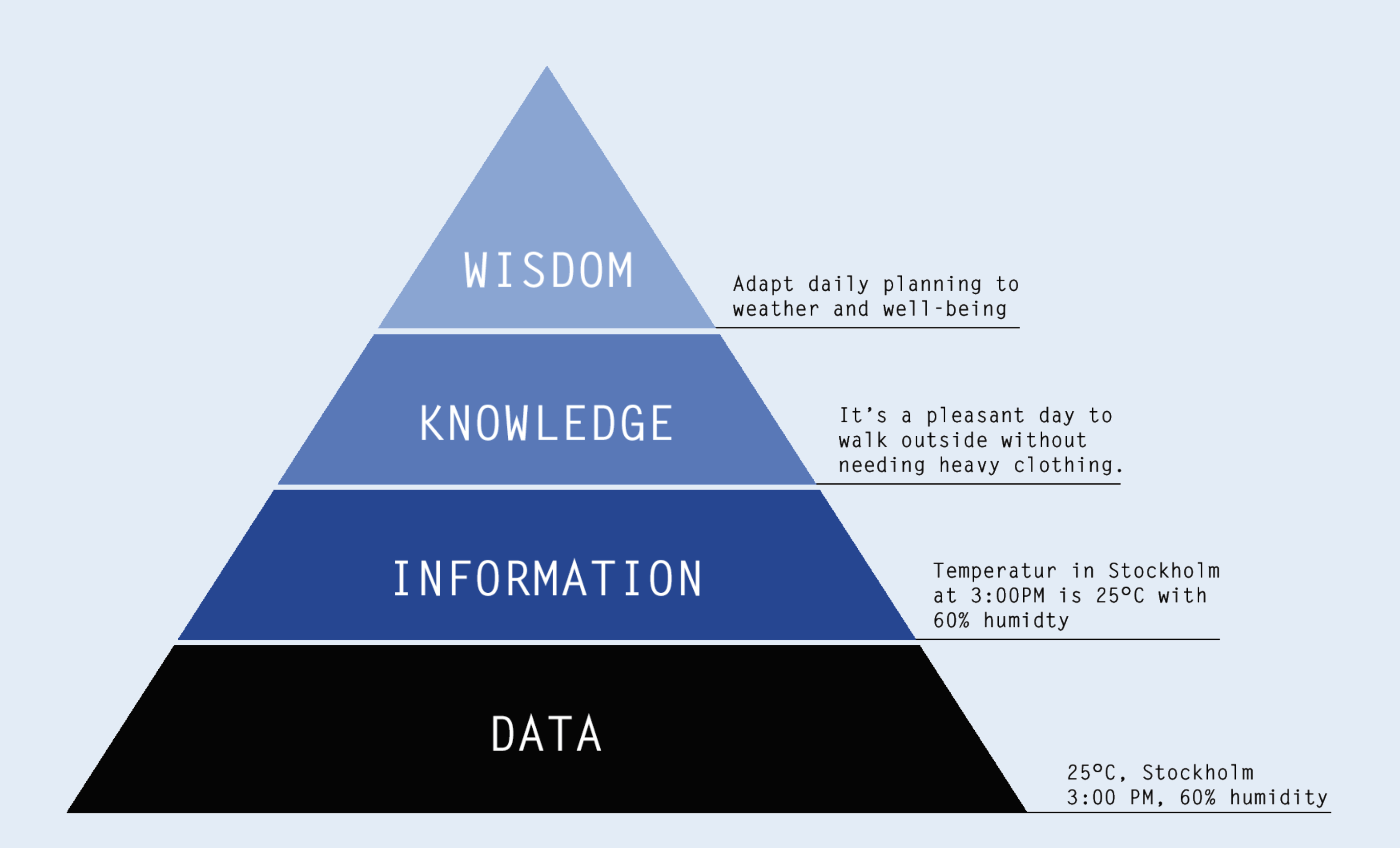
Data
At the base of the pyramid is raw, unstructured data—in BIM models, for example, the attributes of individual components, coordinates, or material properties.
Information
The next level is formed by structured and contextualized data. In the BIM context, this could be assigning components to rooms or classifying elements according to specific standards.
Knowledge
Knowledge is at the top—the ability to recognize patterns, derive rules and gain deeper insights from information. For design, this could mean identifying optimal room configurations or recognizing energy efficiency potential.
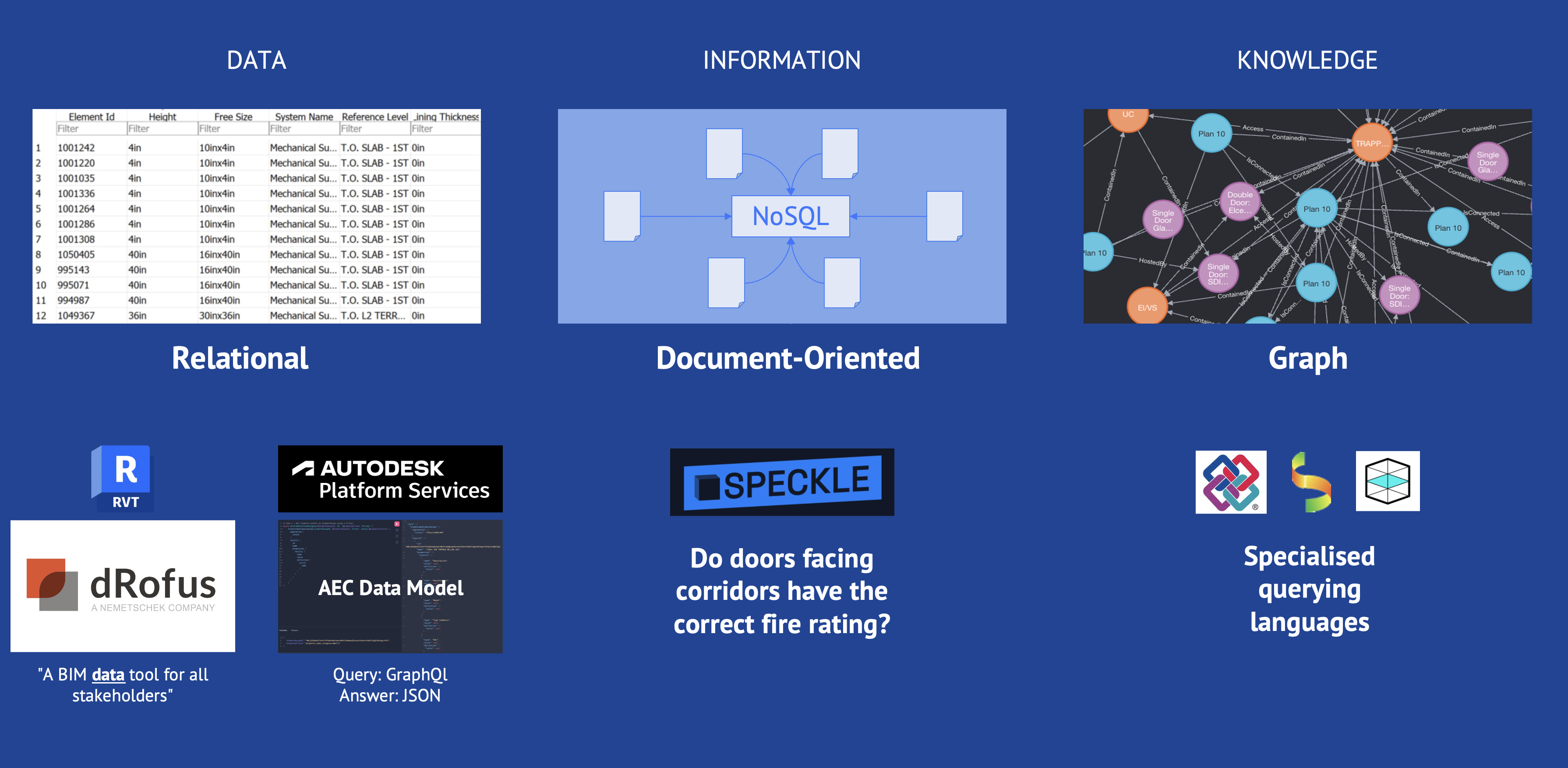
The challenge lies in climbing this pyramid – from raw data to applicable knowledge. Current database systems and query methods in the construction industry reflect these levels:
Relational databases are well-suited for structured data storage.
Document-oriented NoSQL databases offer flexibility for managing more complex information structures.
Graph databases enable the mapping and analysis of complex relationships, particularly relevant to the knowledge layer.
Despite advanced tools such as Revit, Autodesk Platform Services or Speckle, the effective extraction and use of knowledge from BIM models remains challenging. Many of these systems require specialized query languages or in-depth technical understanding, which limits their widespread use.
This leads to the central research question of this thesis: How can we make data, information and knowledge from BIM models accessible using natural language without the need for specialized programming skills?
Answering this question has the potential to fundamentally change the way we use design intelligence. A system that understands natural language queries and can extract relevant insights from complex BIM models would democratize access to valuable data and open up new opportunities for analysis, decision-making and innovation in the construction industry.
State of the Art
Graphs
Graphs are an effective tool for querying Industry Foundation Classes (IFC) files. IFC data consists of interconnected objects, but many relationships or adjacencies are not immediately visible. Graphs make these implicit connections explicit, improving the ability to retrieve and manipulate complex information, such as understanding spatial hierarchies or how building components are connected.
Traditional databases, whether relational (such as Revit) or Document-Oriented (such as Speckle), struggle with interconnected data and multiple layers of dependencies. In contrast, graphs can traverse connections easily, making it more straightforward to query nested structures in IFC files.
Recent studies have explored Resource Description Framework (RDF) and Labeled Property Graph (LPG), two graph types with advantages and history.
Resource Description Framework
The Resource Description Framework (RDF) has been widely adopted for querying IFC files and has been used since 2013 (REF). RDF is structured using subject-predicate-object triples, making it suitable for linking disparate datasets and facilitating logical inference. However, RDF’s reliance on triples limits it when navigating complex interdependencies between building elements. While RDF supports interoperability across domains, its standard query language, SPARQL, is not optimized for deep graph traversal, such as pathfinding. Queries such as “How many spaces are crossed to get from x to z” or “Rooms with no window but adjacent with direct connection to another room with a window” are impossible to execute.
In 2018, BIMSPARQL (REF) enhanced SPARQL by introducing domain-specific functions tailored for querying IFC data. This extension allows for more flexible and federated queries across datasets. Building on BIMSPARQL, NLQL4BIM (REF), introduced in 2023, incorporated natural language processing (NLP) to simplify user interaction with BIM models. By translating natural language queries into SPARQL through an ontology-based parser, NLQL4BIM enables complex queries without requiring users to know technical query languages. Later that year, GSP4BIM (REF) further advanced this by integrating graph neural networks (GNNs), enhancing query accuracy and allowing for multi-hop relational reasoning, enabling handling even more intricate queries within BIM systems.
Labeled Property Graph
The Labeled Property Graph (LPG) provides another approach to querying IFC files. Unlike RDF, LPG allows for the traversal of entire graphs, not just triads. A recent development in this area, published in 2023, is IFC-GRAPH (REF), which fully converts IFC data into an LPG structure. This model-driven approach ensures a complete, automatic conversion of IFC data into a graph-based format. IFC-GRAPH overcomes the limitations of earlier user-driven methods and provides a comprehensive solution for querying building data by storing information as nodes and edges with properties. To enable complex queries, IFC-GRAPH uses the graph traversal querying language Cypher.
Querying Languages Nonetheless
Despite efforts to make querying more accessible through natural language interfaces, all four methods—BIMSPARQL, NLQL4BIM, GSP4BIM, and IFC-GRAPH—ultimately generate technical querying languages rather than enabling proper natural language access to BIM files.
RAG and GraphRAG
Retrieval Augmented Generation (RAG) is a process that allows large language models (LLMs) to retrieve relevant information from external text sources, generating contextually accurate responses. The process goes like this: the external text is divided into chunks, and each chunk is represented as a vector (text embedding) (REF). In parallel, the prompt the user provides to the LLM is also defined as a vector (prompt embedding). The prompt vector is compared to the text vectors to find which is more similar to the prompt vector. The topmost similar vector is retrieved, and the text chuck it represents is used to generate an answer to the user (REF).
Even though RAG can provide accurate results, its process of text embedding does not add relations or connections between similar meanings or concepts present in different text chunks. Because of this, RAG can ignore broader references or story arches present in a text. In lay terms, it has trouble „connecting the dots.“
In April 2024, Microsoft introduced GraphRAG (REF) to extend the RAG framework by incorporating graphs. Instead of treating each retrieved chunk of text independently, GraphRAG constructs a knowledge graph by extracting entities and relationships. This approach enables more sophisticated query-focused summarization using algorithms like Leiden to provide insights into individual data points and broader relationships between them.
Label Property Graphs (LPG) are preferred in GraphRAG as they afford pathway searches thanks to their labelled nodes and relationship schemas. LPGs are graph databases that use labels to categorize nodes and properties to describe relationships, making it easier to query and analyze complex data structures.
Given the preference for LPGs in GraphRAG, Neo4j, a leader in graph database technologies, has adopted this concept in NeoConverse by June 2024 (REF). This system integrates with commercial LLMs, such as ChatGPT, to translate natural language queries into Cypher, Neo4j‘s specialized query language for interacting with graph databases.
Although Microsoft initially designed GraphRAG for text, it can retrieve information from any Label Property Graph. The next chapter will describe how LPG is generated from IFC files and how to integrate them into the GraphRAG workflow.

Methodology
Graph
Our journey begins with pre-processing, where we convert Autodesk Revit models into the Industry Foundation Classes (IFC) format. We chose IFC for its standardization, pre-calculated relationships, and broad compatibility. This choice ensures consistency across the 60 real-world BIM projects we analyzed, providing a solid foundation for our graph creation process.
The heart of our methodology lies in the extraction and analysis of building data. We leverage two powerful tools: IfcOpenShell and TopologicPy. IfcOpenShell serves as our primary tool for parsing IFC files and extracting explicit data about building elements, their attributes, and relationships. TopologicPy, on the other hand, allows us to perform advanced topological and geometric analysis, uncovering implicit spatial relationships not directly stated in the IFC files.
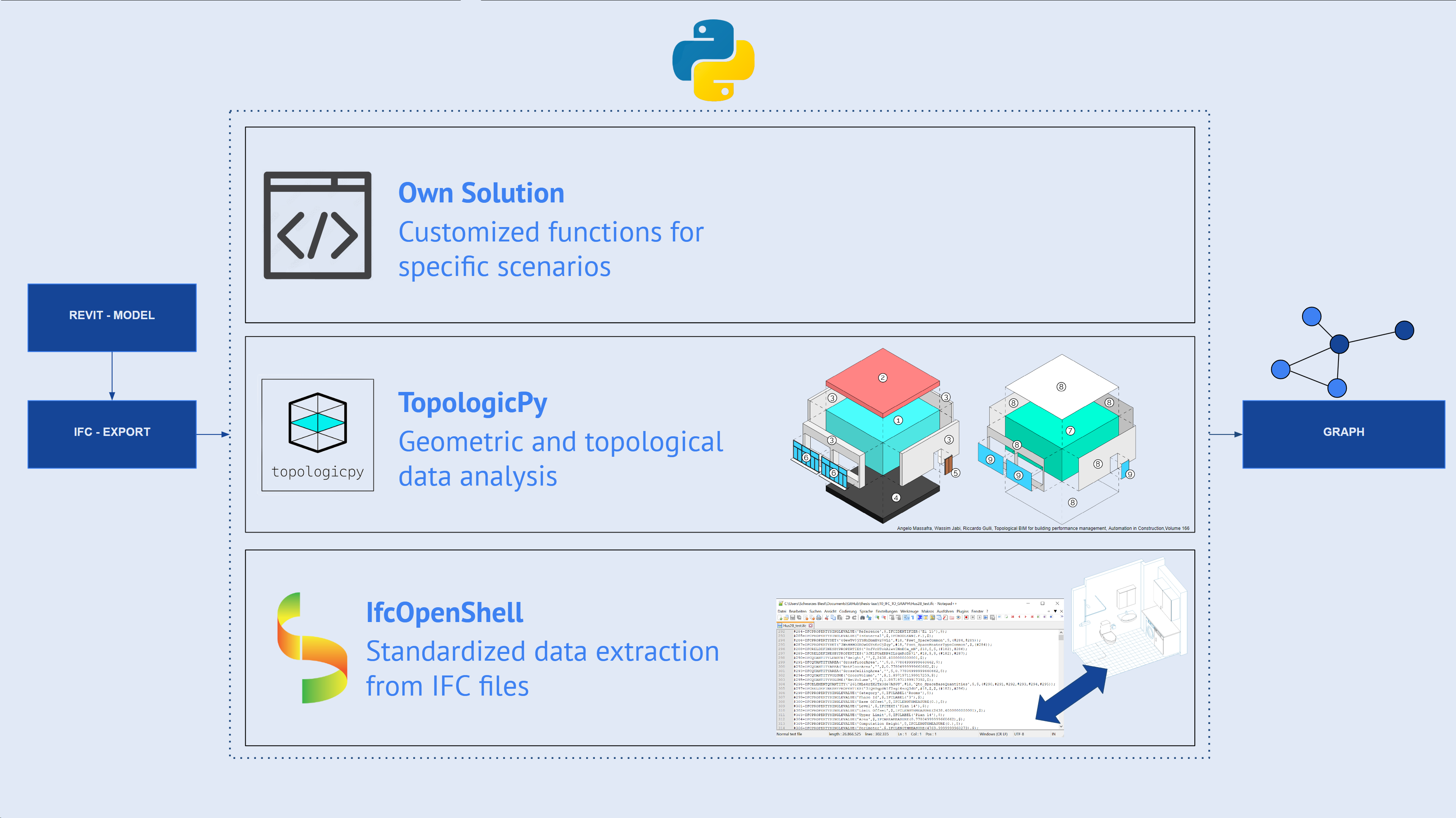
However, we realized that off-the-shelf solutions weren’t enough to handle all the complexities of BIM data. This led us to develop custom algorithms for scenarios that existing tools couldn’t adequately address. A example is our solution for mapping materials to individual wall layers taking into account their correct order, a challenge that required a combination of geometric reconstruction, IFC data extraction, and mapping algorithms.
With all this data in hand, we move to the final phase: creating the knowledge graph in Neo4j. This process involves creating nodes for each building element – rooms, walls, doors, windows – and populating them with relevant attributes. We then establish relationships between these nodes based on both the extracted explicit data and the implicit relationships we’ve derived through our analysis.

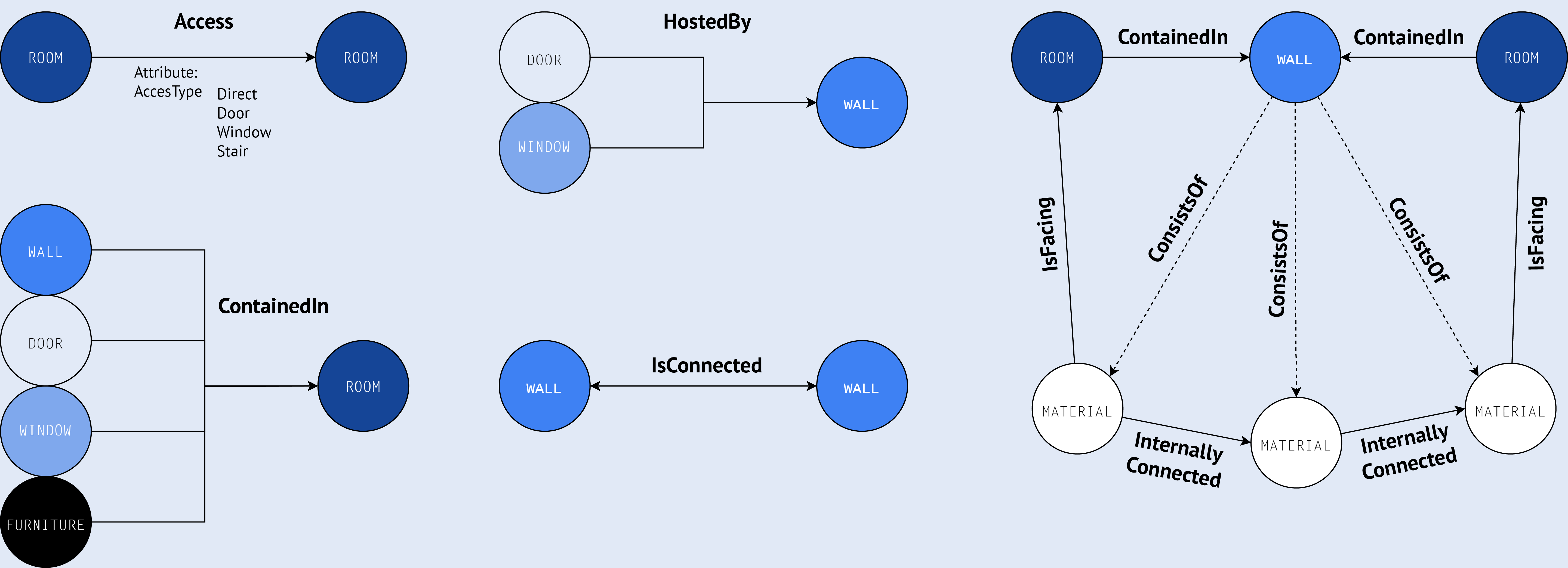
One of the most exciting aspects of this process is how it allows us to represent complex building structures in a more intuitive and queryable format. For instance, our graph can easily represent the layered structure of a wall, including materials for each layer, while also showing how this wall relates to adjacent rooms and other building elements.
Throughout the graph creation process, we pay careful attention to data integrity and consistency. We implement uniqueness constraints for key attributes, validate relationships, and perform data cleansing to remove incomplete or inconsistent information. We also conduct thorough test runs to ensure all elements are correctly linked within the graph structure.
The resulting knowledge graph is more than just a digital representation of a building. It’s a rich, interconnected web of information that captures not only the physical structure of the building but also the complex relationships and properties of its components.
GraphRAG
BIMConverse Setup
Three main pieces need to be set up: BIMConverse, our user interface, which interacts with the graphic generated in the previous stage using natural language via a chat window.
The first piece is Neo4j Desktop. It is a client application provided by Neo4j to manage label-property graphs (LPG) locally on a personal computer. Once a project and database are created in this application, the user uploads the graph. Neo4j Desktop communicates via the Bolt protocol, which uses the local port 7687 by default.
The second piece is OpenAI GPT API. This Application Programming Interface allows us to make calls or requests directly to OpenAI‘s GPT models without needing a web app like ChatGPT or Co-Pilot. To access this API, we must sign up for a paid account and generate a key on OpenAI‘s platform website, where we originally signed up for an account.
Finally, the third piece is NeoConvese (Figure BB), a Single-Page Application running locally on HTTP port 3000. Neo4j provides the base code for this web app as a public repository on GitHub (REF). The front end uses Nextjs and React with Tailwind CSS forms. It is written in TypeScript and connected to Neo4j Desktop via a JavaScript driver.
NeoConverse Adjustments
We made several changes to NeoConverse‘s code. The most evident is its appearance in terms of colours, font styles, and sizes. The background colour of the body was changed in „globals.css.” Tailwind CSS is used extensively in the code, so we applied the inline style several times, significantly to change components.
Concerning the appearance, we turned off (commented out) several divs and components that were not necessary for our version, BIMConverse, such as welcoming messages or buttons to activate additional agents.
Lastly, we modified some functions that deal with generating, pre and post-processing the user questions and Neo4j Desktop‘s answers. For example, there was a hard coded value of 5 to limit how many items were delivered in the answer. Other changes were related to the agent‘s description.
The Question
Before the user can start writing questions in the chat window, she must provide four pieces of information. First, details regarding the connection of the app to the database, Neo4j Desktop:
- – Protocol: bolt
- – Hostname: localhost
- – Port: 7687
Second, details for our app to make requests to OpenAI API:
- – AI service: OpenAI
- – OpenAI key: —-
- – OpenAI model: gpt-4o
Third, details will be added later to the user‘s question (prompt). The graph schema includes node properties, relation properties and the relations between nodes. Here is an example:

Finally, the fourth piece the user provides is several few-shot Q&A to guide the agent to the type of answer we would like to receive at the end of the process.
The web app will save these four pieces of information for future access. In a sense, they are settings that the user only inputs once.
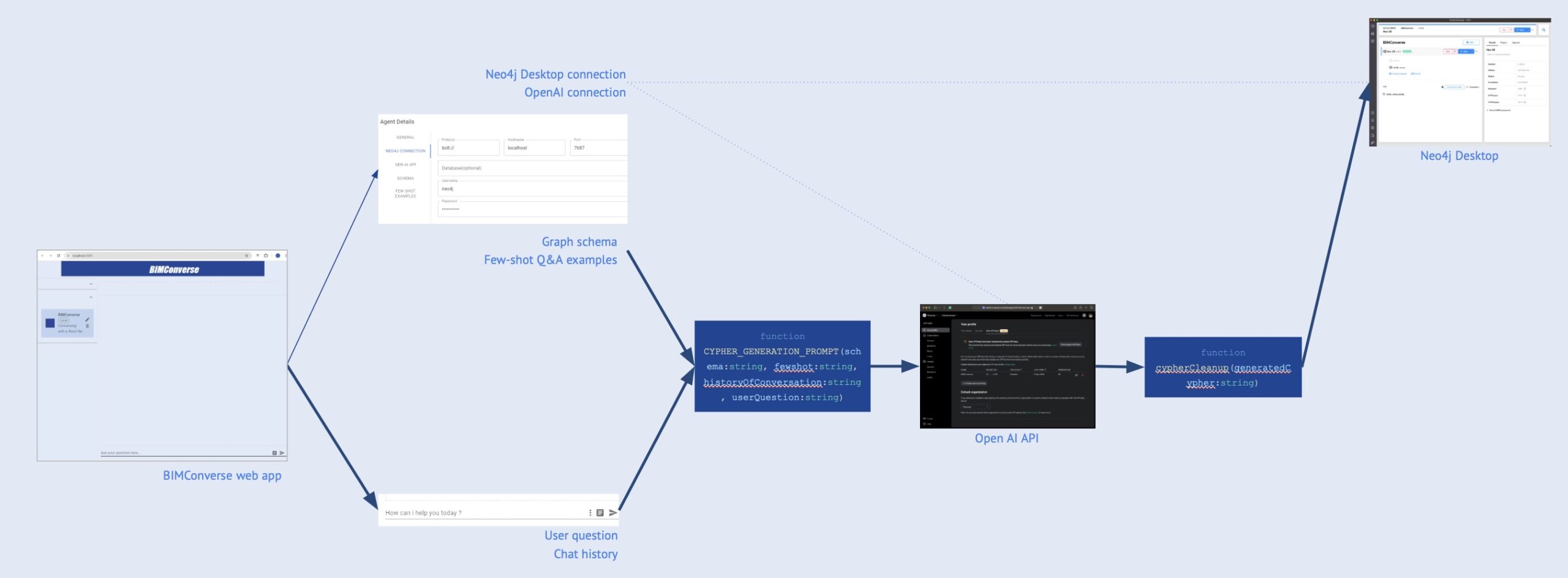
Now that everything is set up, the user writes her question in the chat window in our app. A function called “Cypher_Generation_Prompt” combines this question and the third and fourth pieces of information as a single prompt before sending it to the OpenAI API.
Open AI, using GPT-4o, which we chose as our GPT in the app settings, translates our prompt in English (natural language) to a Cypher query.

The query is post-processed by the function “cypherCleaning” to eliminate typos or formatting errors. Finally, the cleaned query is sent to and executed by Neo4j Desktop.
The Answer
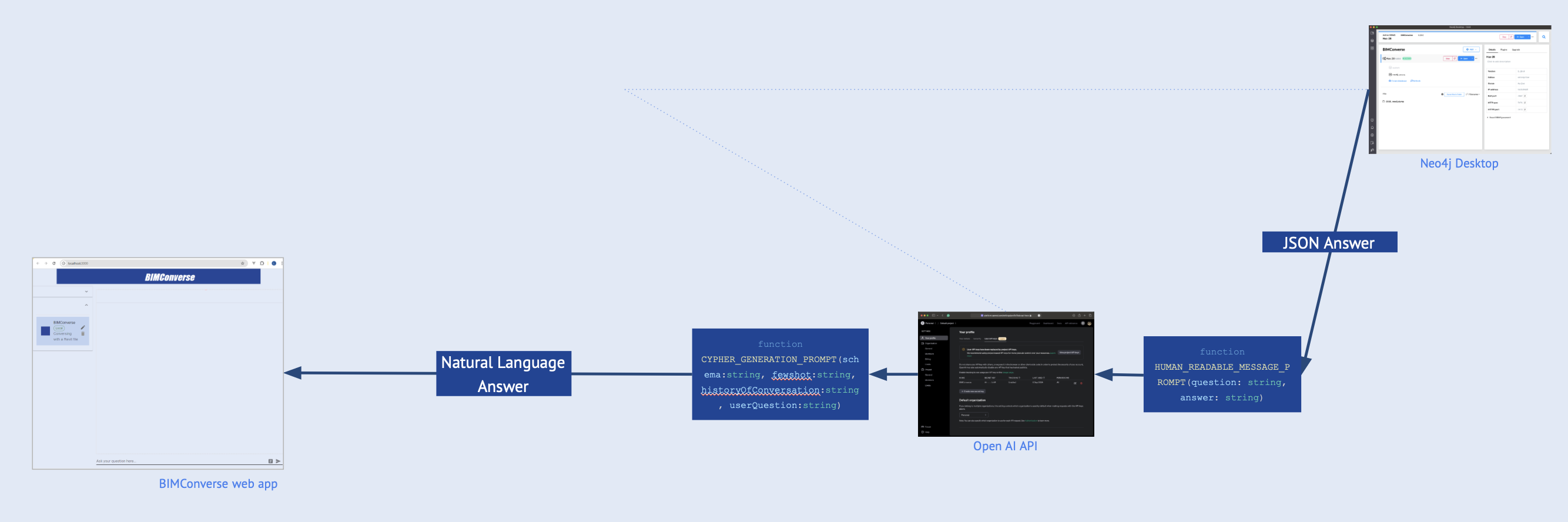
Data, information, or knowledge is extracted from the database as a JSON answer, which is post-processed by HUMAN_READALE_MESSAGE_PROMPT before passing it to OpenAI API. This function also adds to the JSON answer, a series of written instructions that will help gtp-4o translate or convert the JSON to natural language and do it in the desired format.
At this point, the natural language answer is passed through the CYHPER_GENERATION_PROMPT for further formatting before it is served to the user in the main web app.
Chat History
The questions and the answers received are saved and added to the prompts sent to OpenAI API. This is the mechanism by which the user can chat with less friction in our web app.
Back End
Given that we are running BIMConverse locally on a personal computer, the code behind our single-page application is run on Visual Studio Code by running a development environment (npm run dev). This allows us to render or activate the app in a web browser and see changes in real-time as we develop or modify the application.
Results
Pre-Processing: White Arkitekter Archive
The analyzed archive comprises approximately 60 BIM projects from White Architects, spanning from 2016 to 2022. This collection represents various residential projects, varying in size and complexity, all successfully passing the planning phase. The projects range from small multi-family houses to large residential complexes, providing a comprehensive basis for evaluating our conversion process‘s performance and scalability.
The Processing times of transforming Revit files into IFC format and subsequently into graph structures correlated strongly with project size. Smaller projects, such as a five-family residential building, were processed in under two minutes. In contrast, larger projects, like an 80-apartment complex, required up to 50 minutes per floor, resulting in several hours total conversion times for multi-story buildings.
While no complete conversion failures occurred, challenges arose in fully transferring data to the graph structure. These difficulties primarily stemmed from the heterogeneity of modelling practices in real-world projects, and they made iterative adjustments to our conversion code that were necessary to accommodate special cases.
A notable challenge was the inconsistent naming of parameters and parameter values, particularly in window and door families. For instance, window material parameters were named under two different names across projects. For this study, we addressed these variations by directly accounting for both naming approaches in our code. However, future expansions will require developing a more flexible method for parameter standardization.
Despite these challenges, the conversion process demonstrated robustness in handling complex, real-world BIM projects.
Data Querying
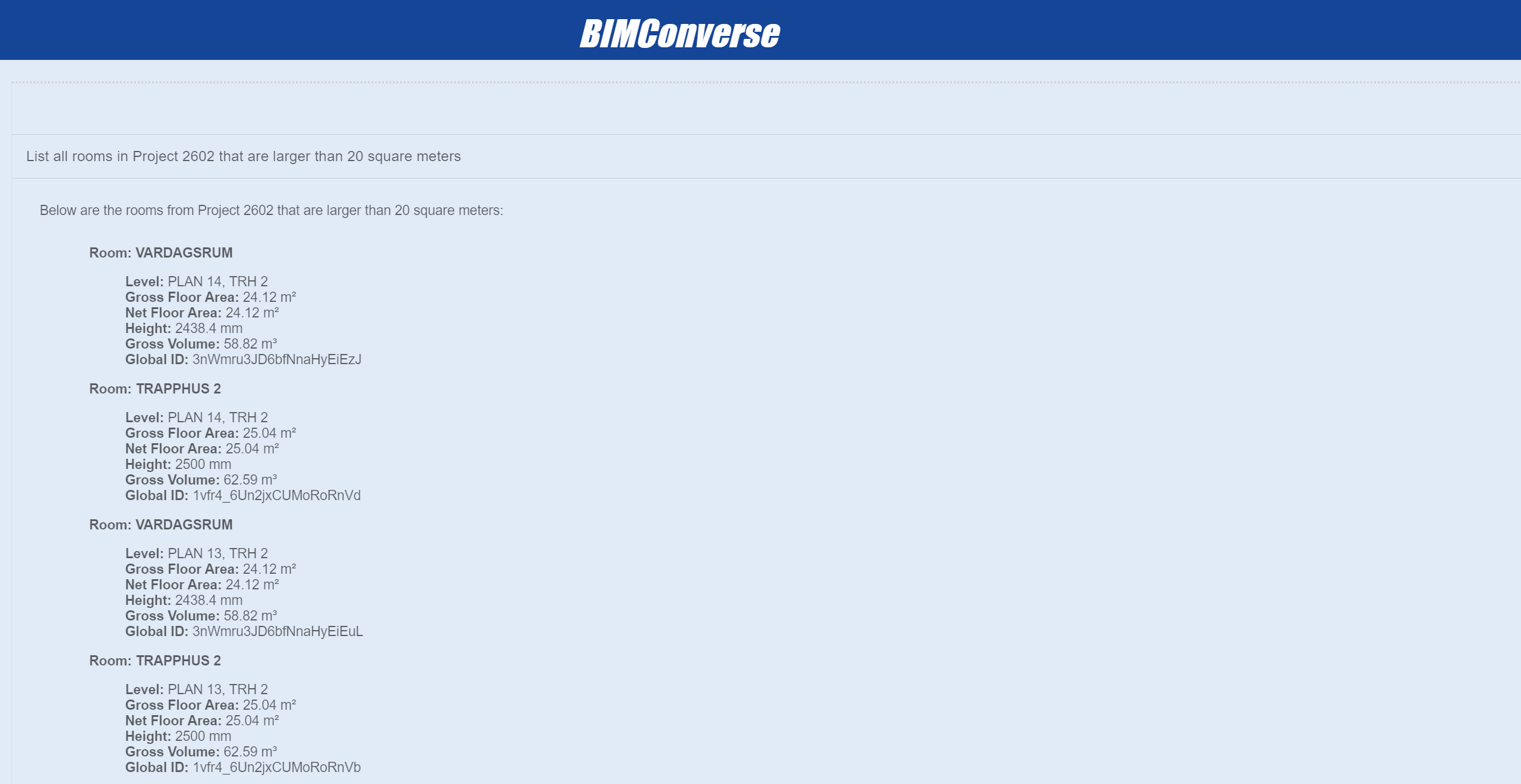
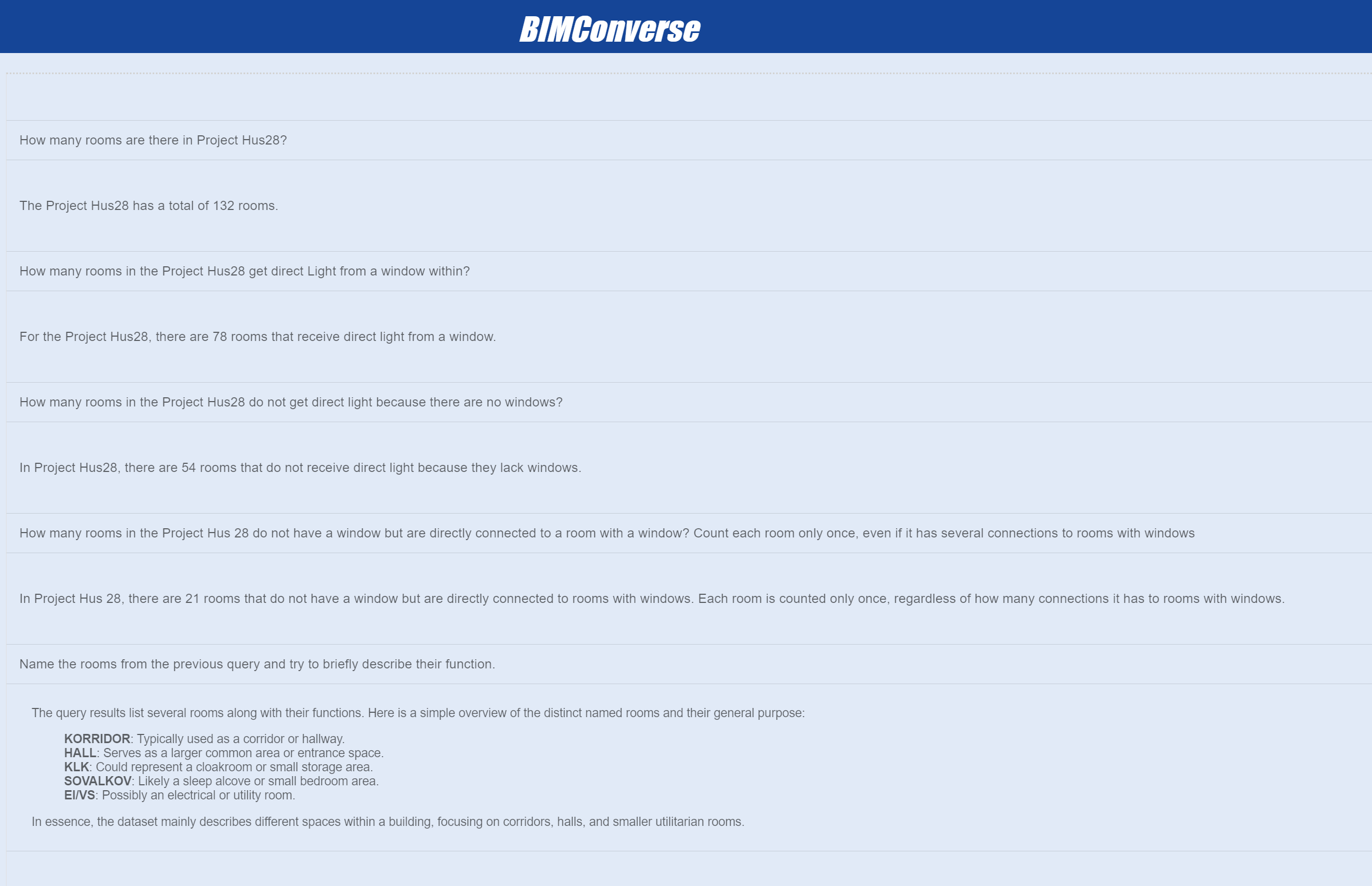
The developed system demonstrates excellent capabilities in data querying, enabling users to extract basic quantitative information from complex BIM models using natural language queries. This form of data retrieval primarily focuses on quantity counts and simple attribute queries without establishing complex links between different levels of information.
The system showed flexibility in handling various query types in the conducted tests. It successfully managed project-specific inquiries, such as counting windows in particular projects, and cross-project analyses, like determining the total number of kitchens across all projects. This versatility allows users to adjust the focus of their queries as needed.
The quality of the responses also proved to be very high. The system not only provided precise figures but also structured the information in an easily understandable and often tabular format. It presented the results clearly and enriched them with additional relevant details, making it easier for the user to quickly gain important insights from the data.
Another advantage of the system lies in its understanding of context. It demonstrated the ability to respond to follow-up questions and establish connections to previous queries. This enables a more natural and fluid interaction that aligns with the intuitive thought process of planners and architects.
The reliability and accuracy of the system are its significant strengths. Unlike traditional large language models, this system does not generate information independently but instead formulates database queries based on user prompts. This approach effectively eliminates the risk of hallucinations or fabricated information.
The system provides precise answers derived directly from the BIM database or explicitly states when it cannot process a query.
It‘s important to note that the accuracy of results is heavily dependent on the interpretation of user prompts when constructing database queries. If a user‘s prompt contains ambiguities or allows for multiple interpretations, the resulting query might not align perfectly with the user‘s intentions, potentially leading to unexpected but data-consistent results. This characteristic underscores the importance of clear and specific user inputs to ensure the generated database queries accurately reflect the intended information request. Regarding response time, the system performs comparably to conventional LLM applications, indicating efficient processing of queries despite the additional step of database interaction.
In summary, the system allows users to quickly and easily extract specific quantitative information from extensive models, thereby forming the basis for further, more complex analyses. Compared to traditional methods of data querying in BIM software like Revit, it lowers the entry barrier for data analysis and makes complex BIM information accessible even to users without extensive technical backgrounds.

Information Querying
Aligning with Ackoff‘s definition of information, our system enables the extraction of structured and contextualized data from BIM models. According to our tests, the system performs precise quantitative analyses, such as counting specific elements within a project. For instance, it can determine the total number of specified elements in a project and break them down by various criteria, such as levels or specific attributes. This process transforms raw counts into meaningful information by providing context and relationships.
The system demonstrates proficiency in performing operations between multiple queries. It successfully conducts operations such as comparing element quantities across different project sections, calculating ratios between various building components, and analyzing distributions of elements throughout the structure. These capabilities allow users to derive more nuanced insights from the raw data.
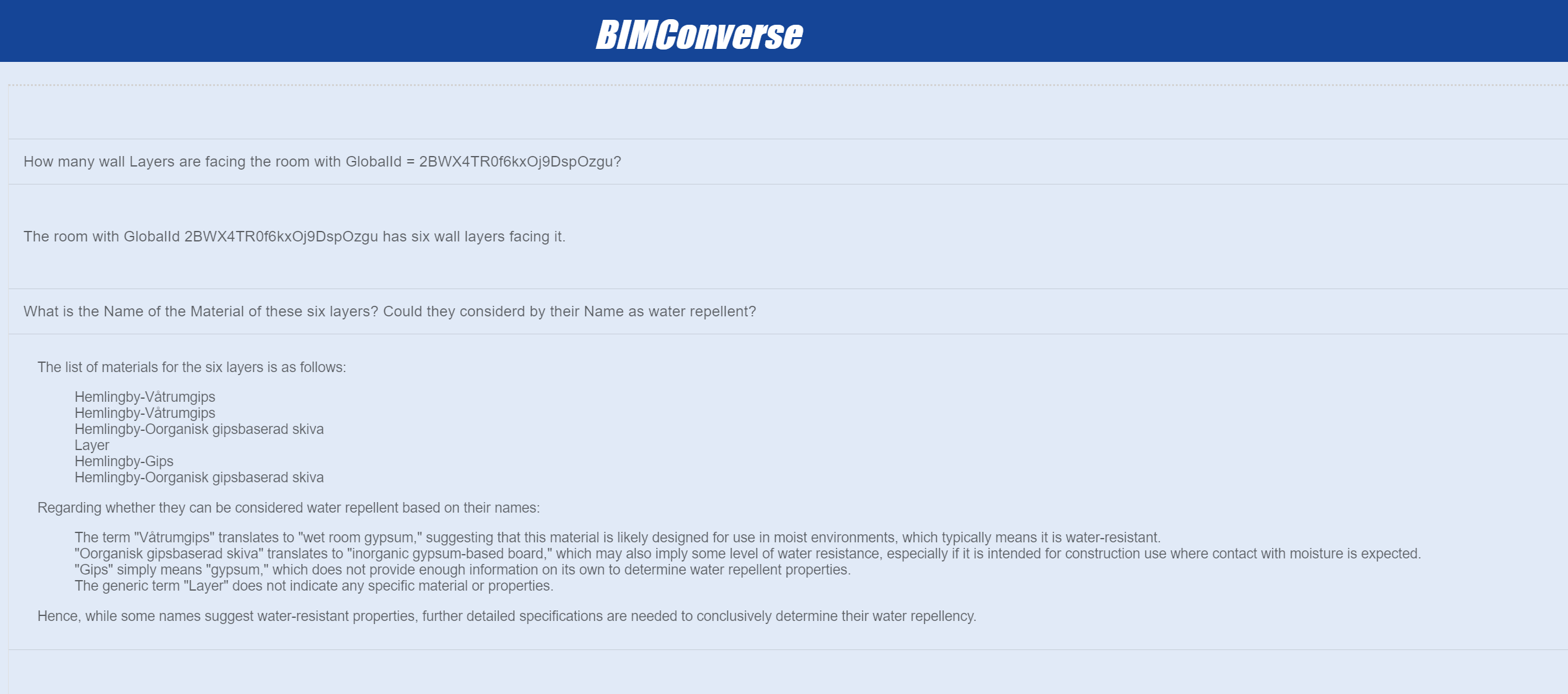
Relational Querying represents a key aspect of information creation in our system. By establishing relationships between different building elements, such as identifying wall layers facing particular rooms, the system generates new insights that are not apparent from the raw data alone. This relational information supports a more comprehensive understanding of the building‘s structure and systems.
The system also demonstrates Intelligent Interpretation capabilities. While providing detailed information, it shows the ability to interpret data within limitations. It can offer insights based on available information (such as suggesting potential material properties based on names) while clearly communicating the boundaries of these interpretations. This approach transforms raw data into actionable information while maintaining data integrity.
In conclusion, the system makes complex BIM data more accessible and valuable by contextualizing data, establishing relationships, and providing interpreted outputs. It demonstrates how connecting and contextualizing various data points can create a more informative picture of a building project. This aligns with the core principle of information as defined in Ackoff‘s hierarchy, where the value lies not just in the data itself but in the relationships and context that transform that data into meaningful information.
Knowledge Querying
In testing our system‘s Knowledge Querying capabilities, we aimed to assess its ability to recognize patterns, derive rules, and gain deeper insights from the available BIM data.
Our tests show the system can handle more straightforward knowledge-based queries, demonstrating capabilities beyond simple data retrieval. Key abilities observed include:
Comparative Analysis: The system demonstrated the ability to compare elements (e.g., room types and wall compositions) and highlight meaningful differences or similarities.
Information Synthesis: The system provided comprehensive overviews by combining data from various aspects of the BIM model, such as room types, spatial relationships, and material specifications.
While these results are promising, it‘s important to note that the depth of knowledge queries is currently limited by the scope of data transferred to the graph. More complex analyses would require additional building components, categories, and attributes to be incorporated into the database.
Despite these limitations, the tests indicate that the underlying graph structure and querying system are well-suited for knowledge extraction. The system‘s ability to connect pieces of information and draw meaningful conclusions, even with a limited dataset, suggests significant potential for more advanced knowledge querying as the data model expands.
The results suggest that with expanded data inputs, the system could offer sophisticated analyses, transforming complex BIM data into actionable insights.

Limitations
While our system demonstrates promising capabilities in querying BIM data, several limitations and areas for improvement were identified during testing:
Context Retention
The system maintains conversation history and context, allowing for progressive querying. Inconsistencies were observed where the system occasionally disregarded previously established contexts, such as project-specific queries. A potential short-term solution could be implementing a dedicated field for users to specify whether a query pertains to a specific project or the entire archive. However, this wouldn‘t address context retention issues for non-project-specific queries.
Query Precision
The system currently requires a high level of precision in query formulation. For instance, when searching for the „largest window,“ the system did not return results, while „highest window“ did. This strict interpretation of terms may limit user flexibility and intuitive querying.
Query Interpretation
While the system doesn‘t tend to hallucinate, users must formulate queries precisely to ensure the generated database query matches their intended result. Examples include explicitly instructing the system to ignore graph node connection directions or to avoid double-counting rooms in certain queries. Refinements in the system prompt could potentially address these issues.
Path Constraints
The system sometimes produces unrealistic results in spatial queries involving pathfinding, such as routes through private spaces in adjacent apartments. Implementing more sophisticated path constraints could improve the practicality of these queries.
Data Enrichment
There is significant potential for enhancing the system‘s capabilities by enriching it with additional data sources. This could include linking to material data sheets or calculations in tabular form, which wouldn‘t necessarily need to be integrated into the graph database structure.
We observed that the iterative filling of the Few-Shot example already had significant positive effects.
Future improvements could focus on:
- Enhancing context retention mechanisms to maintain query relevance across extended conversations.
- Implementing more flexible query interpretation to allow for natural language variations and synonyms.
- Refining the system prompts to better handle common query scenarios without explicit user instructions.
- Exploring integration with diverse data sources to enrich the knowledge base and querying capabilities.
These improvements could make the system more intuitive, flexible, and comprehensive.


Conclusions and Outlook
IFC files converted to Label Property Graphs and made accessible via natural language using GraphRAG proved surprisingly functional. Ackoff‘s hierarchy of data, information, and knowledge helped us structure the results we got from BIMConverse. Still, a more systematic analysis is needed to determine the system‘s capabilities and limitations.
Leveraging LLMs to translate text to Cypher and JSON to text is a solid process. The threat of hallucinations is reduced as the LLM does not create the answers from its training data but only does the translation of queries. NeoConverse offers buttons in its interface for the user to help fine-tune the agent by up or down-voting answers.
Graph Improvements
Our graph’s current schema includes rooms, walls, wall layers, doors, windows, and furniture. As a next step, IFC classes such as IfcBeam, IfcColumn, and IfcSlab could be added.
Currently, we build the graph one building at a time, one floor at a time. The only connection between floors is the room „traphus „or staircase. We can expand the vertical connections, such as walls on the facade or the load-bearing vertical circulation cores.
Adjacencies between walls (whether they touch or not) are computed with all walls simultaneously. We can reduce the cost of this operation by pre-filtering the walls in the room to which they are attached, for example.
GraphRAG Improvements
The queries we can make depend on what is allowed by the Cypher syntax and functionality. Currently, a single agent carries out the entire GraphRAG process. We could add conversational agents that can collaborate to enable more complex queries and calculations. Agentic AI is a field of high interest in this regard.
Adding code and regulation documents to the RAG process is a technical enhancement and a practical solution. It can significantly improve our ability to make queries related to design quality control and compliance, two crucial aspects of our work.
Beyond the Revit File
We aimed to make White Arkitekter‘s BIM archive of residential buildings (around 64 projects) accessible to GraphRAG. This proved challenging to achieve as each project has heterogeneous families; for example, windows are created in different ways that report their parameters differently, which makes it hard to automate the extraction of their properties. To solve this problem, we exported Revit files to IFC. While IFC standardizes file schemas, property inconsistencies remain. Developing IFC5 based on the Entity Component System could address this issue.
BTwin by Angelo Massafra (REF) uses JavaScript Object Notation for Linked Data (JSON-LD) to unify BIM, Building Performance Simulation, and IoT (meters and sensors) databases as a single RDF graph. Amazon Neptune supports openCypher queries over RDF graphs (REF). This is a venue worth exploring to move beyond the single BIM file.

CI/CD Pipeline
A continuous integration / continuous development (CI/CD) pipeline would facilitate AEC companies‘ use of BIMConverse. The routine to generate a Label Property Graph on the fly could be triggered via webhooks for files hosted in APS or Speckle.
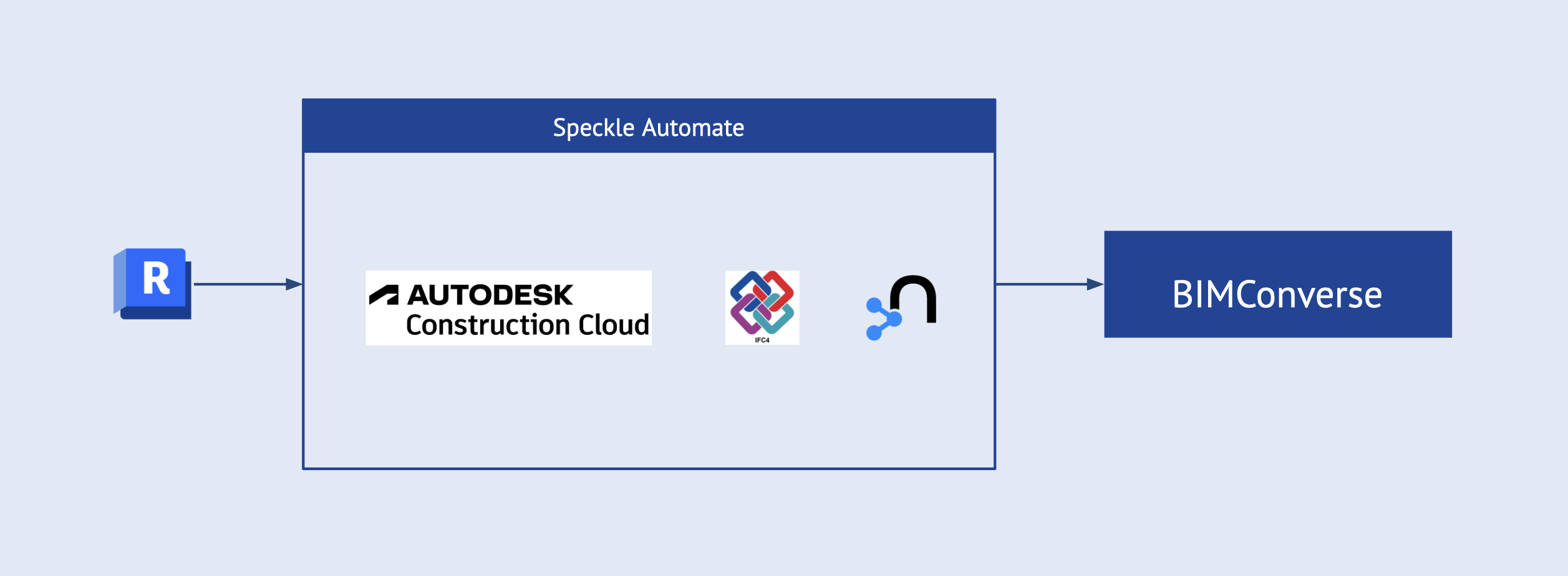
GQL: ISO Standard
In April 2024, the International Organization for Standardization (ISO) made graphs a first-class entity. GQL, now an international standard, establishes and secures graphs (REF). The base of GQL is OpenCypher, an open version of the same query language we used in this study.

Open Source
Even though we used open-source software such as ifcOpenShell or TopologicPy, our system depends on having access to Neo4j and OpenAI API, proprietary and paid systems. Finding open-source alternatives is a much-needed step.
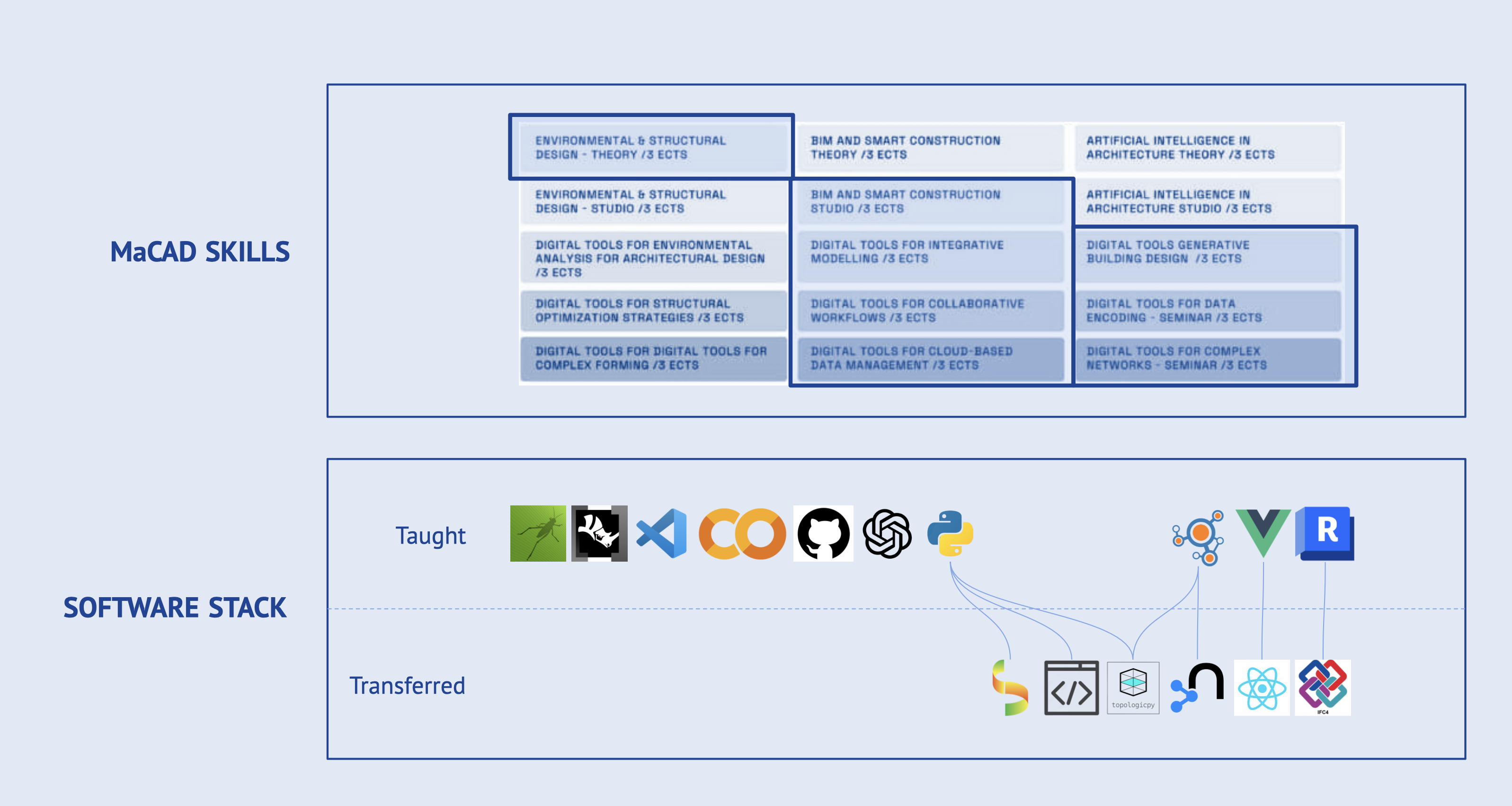
Thesis Skills and Software Stack
Revit, Grasshopper, Rhino.Inside.Revit, Visual Studio Code, Google Colaboratory, Github, OpenAI API, Python, and all the software we learned during the MaCAD were all used as part of this project. We didn‘t use NetworkX, Vue, JavaScript, HTML, and CSS directly. Still, it allowed us to understand and access new and critical software like ifcOpenShell, TopologicPy, Neo4j Database, Cypher, React, TypeScript and IFC.
Acknowledgements
We want to extend our gratitude:
To our thesis advisor, German Otto Bodenbender, for helping us communicate our ideas.
To David Leon, thank you for leading the MaCAD program with such a bold vision. The program‘s innovative approach has inspired us to embrace bravery, build confidence to tackle challenges and expand our skills in software and concepts as we return to work.
To Laura Ruggeri for making things work and putting a smile on our faces.
To Bao Trinh, thank you for sharing his passion and knowledge about graph machine learning.
To João Silva for encoraging us.
To Profesor Wasim Jabi, thank you for your time and knowledge about TopologicPy. We are truly thankful.
Thank you to White Arkitekter, Peter Lechouvious, Adalaura Diaz, Martin Johnson, John Nordman, and Zebastian Olsson for helping us locate and access your Revit archive.
To our partners, Martha and Freddie, for their unwavering, vital and loving support throughout the year.
