
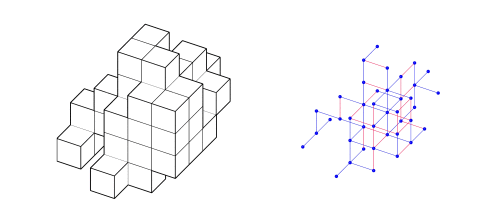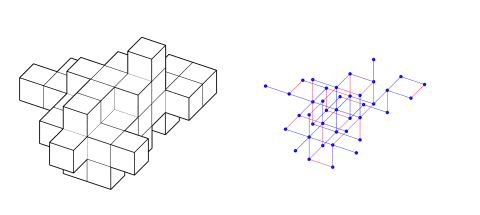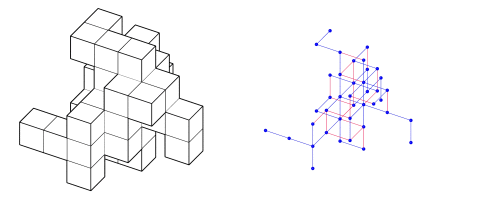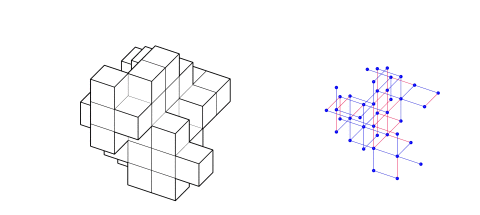
In a world driven by digital transformation, the realm of architecture and design faces new challenges in achieving flexibility, scalability, and efficiency. One of the most pressing issues is modular determination—how do we ensure that modular structures fit together seamlessly, across various design patterns? Design as Grammar addresses this by leveraging Graph Machine Learning (Graph ML), not just to replicate known patterns, but to understand and apply the design grammar that dictates their formation.
Our research explores the boundaries of Graph ML, pushing it beyond conventional use to teach a machine the rules of design grammar, and applying these rules to predict, generate, and optimize new modular patterns. This approach enables us to scale our designs across different contexts, opening new possibilities for automated modular design in architecture, construction, and product design.
The Drive: The Problem Space Behind the Project
The core challenge we face is that traditional geometric approaches to modular design are limited—they require each new design pattern to be manually created, adjusted, and tested. For large-scale projects, this approach is impractical. Inspired by biological systems and urban planning, where small rules can generate complex structures, we sought to teach machines the underlying design grammar that drives pattern formation.
By automating pattern recognition and modular determination, we aim to streamline processes in architecture, allowing for adaptable designs that can dynamically respond to real-world constraints.
Thesis Question: Can Graph ML Learn Design Grammar?
Our central thesis question explores whether Graph ML can generalize beyond learning specific patterns and instead understand the grammar behind those patterns. If successful, this approach would enable us to automatically generate modular designs that adapt to any given environment, without the need for extensive manual intervention.
This question addresses a crucial gap in the field of computational design, where much of the focus has traditionally been on geometry rather than the rules that govern modularity.
Dataset Creation: Constructing Design Data for Machines
The core of our project starts with creating a rich dataset that teaches the machine about modularity. Using a grid populated with modular components (such as LEGO bricks), we built 2000 distinct patterns. Each brick became a node, while the relationships between them were represented as edges in a graph. These relationships were key to teaching the machine how to replicate, predict, and extend patterns.

The dataset involved randomizing important factors such as:
- Insertion points: Which nodes should initialize the pattern.
- Brick types: The various sizes and shapes of bricks.
- Primary brick locations: Controlling key patterns in the grid.
- Distribution of filler bricks: Ensuring efficient space coverage.
This approach provided a diverse set of design patterns, each structured in a way that enabled the machine to learn about modular consistency and pattern formation across different grids.

Feature Extraction: Embedding Key Design Properties into Graphs
Once the dataset was created, the next step was feature extraction. Every node and edge was assigned specific features, which the model could use to learn both local and global properties of the patterns.
We extracted features at multiple levels:
- Node-level features:
- Position (X, Y): The spatial location of the brick.
- Brick Type: Information about the size and orientation of the brick.
- Eigenvector centrality: A measure of the node’s influence in the graph.
- Occupied/Unoccupied status

- Edge-level features:
- Connectivity: How bricks are connected.
- Orientation match: Whether the bricks align in the same orientation.

- Subgraph-level features:
- Completeness: Whether the subgraph fills a given space.
- Number of cells: The number of bricks involved.

- Graph-level features:
- Completeness score: A measure of how complete the grid is.
- Modularity: The design’s structural consistency.

Model Setup: Custom GraphSAGE Hybrid Model
The core of our project was training a GraphSAGE hybrid model to predict modular patterns based on the input features of graph nodes and edges. This model aggregates information from neighboring nodes to learn better node representations, capturing both local and global structural patterns of the dataset.
Feature Embedding
Our feature embedding process was structured across multiple levels, each capturing different aspects of the modular grid:
- Node-level: Position, orientation, brick type, occupation, and eigenvector centrality.
- Edge-level: Connectivity between nodes and orientation matching.
- Subgraph-level: Number of cells, brick type, and completeness of sub-patterns.
- Graph-level: Available pattern space, completeness score, and modularity.

This multilayered approach allowed us to ensure that the model captured not only the local context (node interactions) but also the global structure of patterns. The GraphSAGE model’s architecture took these features as input and aggregated them to make predictions at multiple levels.

GraphSAGE (Graph Sample and Aggregation) aggregates information from neighboring nodes to learn better node representations.
For each node, features are learned not only from its own attributes but also from the attributes of its neighboring nodes in the graph. This enables the model to capture local context (how nodes interact with nearby nodes) and global structural patterns.
Training the Model: Self-Supervised Learning
We used self-supervised learning, where partially labeled graphs served as inputs, and the model learned by comparing the predictions of unlabeled nodes with the ground truth provided by fully labeled twin graphs. These twin graphs represent the ideal final pattern, allowing the model to gradually learn the rules of pattern formation through backpropagation.

Twin Graphs:
- Partially labeled graphs: These graphs contained some labeled nodes and were partially filled with bricks.
- Fully labeled graphs: These served as the ground truth, showing where all the bricks should be placed.

The model was tasked with predicting the missing features (brick type, orientation, and occupation) for the unlabeled nodes, using the features from labeled nodes and edges. By training with these twin graphs, the model could effectively learn how to complete patterns.
Model Testing
Our initial attempt to embed all features into nodes and predict at the node-level, the brick_types at the nodes didn’t yield results. the model wasn’t able to understand the local and global features as they affect the pattern filling.

It is then that we apply our multi-level feature embeddings to aggregate features and pool them while learning on the node features. we tried different number of classes (brick types) to predict from.


We could see the model performing better at predicting only 02 labels (02 brick types) but it wasn’t able to “complete” the pattern as such.
Loss Function and Backpropagation
To guide the learning process, we employed a combined loss function that accounted for both node-level losses (brick type, orientation, and occupation) and graph-level losses (completeness score). This multi-level approach ensured that the model optimized not only individual node predictions but also the overall structural quality of the graph.

- Node-level loss: Compared predicted brick type, orientation, and occupation to ground truth labels.
- Graph-level loss: Measured the predicted graph’s completeness score against the true pattern’s completeness.
Through backpropagation, the model adjusted its weights to minimize both losses, learning to accurately predict not only the position of each brick but also how the entire grid should be filled for a complete and modular design.

Development
At this stage, our model is able to predict two labels effectively while maintaining the structural integrity of the bricks (i.e., preserving the number of nodes per brick). This achievement ensures that the model utilizes 2 out of 5 brick labels to fill the entire grid. However, there are several key areas for improvement and further development.
Throughout this incremental training process, we can apply a penalty mechanism to encourage the model to minimize the use of red bricks (1×1 filler modules). By incentivizing efficient use of space and brick types, the model will not only learn to place bricks accurately but also optimize for completeness and modularity.
- Addressing Potential Data Leakage
A critical aspect of enhancing model performance is ensuring that there is no data leakage between the twin graphs (the fully labeled graph and the partially filled graph). Specifically, features such as orientation and occupation (binary), which are present in the fully labeled graph, should not be inadvertently passed to the unlabeled or partially filled graph during training.
This potential leakage can lead to overfitting, where the model might rely on unintended hints to make predictions, rather than generalizing based on learned design rules. By eliminating any leakage, the model will better generalize to unseen patterns and configurations, improving the robustness of its predictions.
- Diversifying the Dataset
To further enhance the model’s generalization capabilities, we need to invest in creating a more diverse dataset with varying scales and pattern types. The current dataset, while effective for initial training, may limit the model’s ability to handle more complex or varied design challenges.
Expanding the dataset will provide the model with a broader range of examples from which to learn, ultimately allowing it to handle more diverse modular design tasks and predict more labels on new sample graphs.
- Progressive Learning: Incremental Complexity
Another promising approach is to train the model in increasing levels of difficulty. This would involve starting with the current two-label prediction task and progressively expanding the model’s capabilities to predict three, four, and finally five labels.
Future Vision
Expanding Logic with Diverse Pattern-Filling Techniques
Our goal is to push the boundaries of our core model’s understanding by incorporating various pattern-filling techniques. Initially, our model was trained using LEGO brick modularity as a proof of concept, but the next step involves integrating other pattern-filling logic like Tetris (pattern packing) and similar methods. By doing this, we can enhance the model’s capacity to recognize, predict, and generalize more complex and diverse modular patterns.

The diagram above represents the overall workflow. Here’s a breakdown of how we plan to expand the model’s logic and apply this enhanced understanding:
Decoding Pattern
This is the starting point where the model learns to decode a set of modular rules. In our case, it began with the LEGO modular design rules and ensures that patterns follow these rules while maintaining modular integrity.
Model Training
Currently, the model training phase involves learning from modular LEGO-like patterns and generalizing this understanding to predict new, unseen patterns. Through rigorous testing and validation, the model gains a deeper understanding of generalized graph features, including:
- Available pattern space
- Completeness score
- Modularity
- Selected indices count
Expanding Logic
As we expand beyond the initial proof of concept, we will introduce new pattern-filling techniques, such as Tetris-like modularity and others. These new logics will challenge the model to handle more varied and complex patterns beyond just grid-based LEGO bricks.
- Tetris modularity introduces complex shapes that require the model to optimize space usage in a different way, learning new geometric patterns and modular relationships.
- By incorporating various pattern-filling algorithms, the model will develop a broader design grammar. This means that its ability to generalize will improve, as it learns multiple ways of filling a given space with distinct modular strategies.
Fine-tuning with Specific User-Defined Patterns
Once the model has been trained on a wide range of generalized patterns, the next phase will involve fine-tuning the model. Here’s how:
- User-specific datasets: Users will be able to provide smaller, more specific datasets or patterns for the model to fine-tune its predictions. These datasets could include particular architectural designs, customized modular grids, or any other unique pattern that the user wishes to decode.
- Feature benchmarks: Using the generalized features we’ve established (like completeness score, modularity, and available pattern space), the model will understand and decode specific design grammars.
By fine-tuning with user-defined input, the model can be adapted to specific design challenges, making it capable of applying modular logic to more intricate or specialized patterns, like 3D meshes or architectural surfaces.

Github Repo: https://github.com/mohammadabid-macad/DesignGrammar_MA_SM_IAAC
