
Toward Net-Positive Architecture
MASTER IN ADVANCED COMPUTATION FOR ARCHITECTURE & DESIGN
2024/2025
Anji, Christina & Will
Thesis – Supervisor: Gabriella Rossi

We are facing an urgent climate crisis, one that demands architecture to move beyond conventional sustainability toward regenerative, net-positive approaches. Current design practices often struggle to integrate environmental and context-aware analysis seamlessly because they rely on computationally expensive simulations that are difficult to run during the early design stages.
ABSTRACT
A.I. Morphogenesis: Toward Net-Positive Architecture
In response to the growing urgency of the climate crisis, architecture must move beyond conventional sustainability and toward regenerative design strategies. This thesis explores the potential of A.I.-driven morphogenesis to generate building forms that are not only environmentally responsive but also contribute positively to their surroundings producing more energy than they consume, reusing water, and supporting ecological systems.
Reinforcement Learning (RL) is used to train a voxel building agent to grow and adapt. Multiple performance metrics serve as reward functions, including energy balance, deflection, thermal comfort, and material efficiency.
This methodology aligns with the goals of the Living Building Challenge (LBC), aiming to create architecture that is self-sufficient, ecologically integrated, and regenerative. Ultimately, the thesis presents a new design approach in which building form emerges through continuous interaction between intelligent agents and environmental feedback offering an adaptive, performance-driven framework for future architectural practice.
Research Question
How can AI morphogenesis through reinforcement learning become a design tool for net-positive architecture?
Research Hypothesis
AI morphogenesis, when implemented through a Grasshopper-based reinforcement learning workflow, can generate context-aware voxel forms by integrating performance metrics, modeling approaches, and design processes, demonstrating potential as a design tool for net-positive architecture, while remaining constrained by computational cost and resolution.
Concept // Morphogenesis
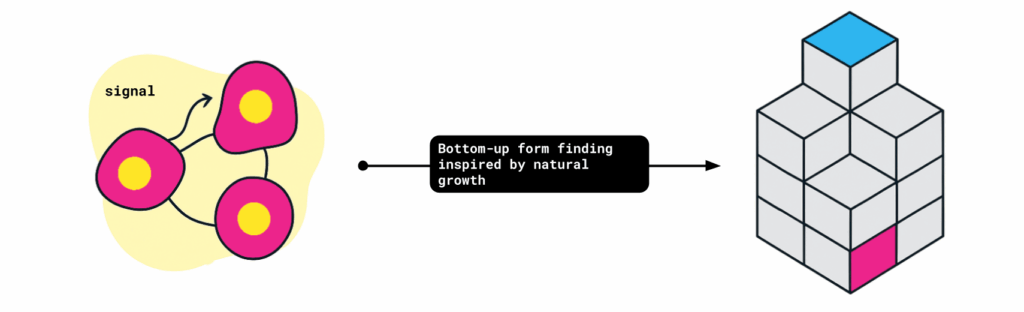
In nature, living organisms develop their forms through a process called morphogenesis. Cells respond to chemical and physical signals and self organise in ways that make efficient use of limited resources.
In architecture, we adopt this principle as a bottom-up process of form-finding. Instead of prescribing the final shape, form emerges through interactions between the agent and the environment.
In our research, we translate this idea into reinforcement learning. We train a voxel building agent to grow and adapt based on environmental and structural feedback. The agent learns through multiple performance metrics, such as energy balance, structural deflection, thermal comfort, and material efficiency, which act as reward signals.
This allows us to investigate whether morphogenetic reinforcement learning can be integrated within grasshopper workflows to guide architecture toward adaptive design. The use of reinforcement learning has been found to exceed human performance in studies such as AlphaGo Zero by Silver et al.
Background // Reinforcement Learning (RL)
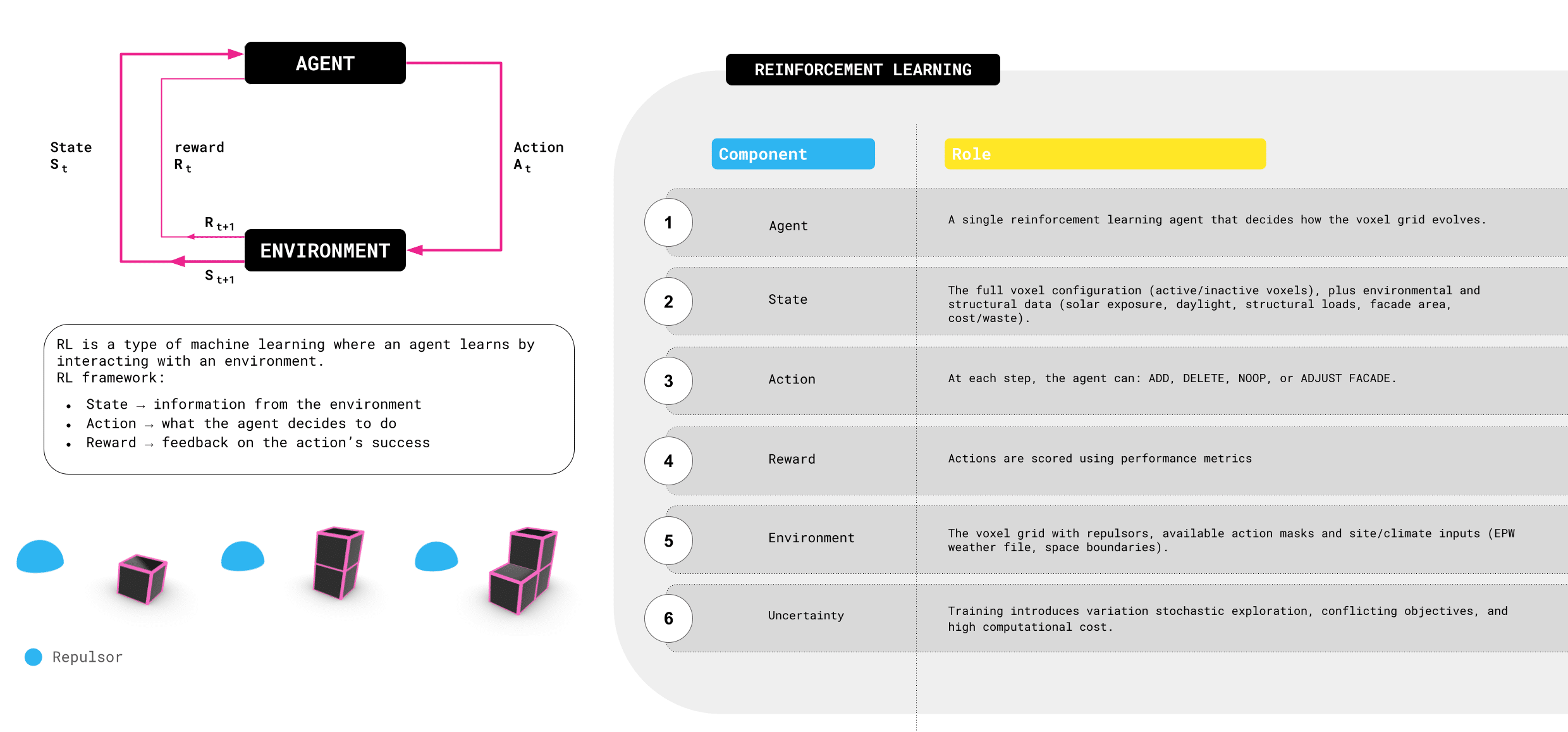
Reinforcement Learning (or RL) is a type of machine learning where an agent learns by trial and error through interacting with its environment. The framework is relatively simple – the agent observes a state, takes an action, and then receives a reward, which tells it how successful that action was. Think of it like the agent is playing a video game – over time, the agent learns strategies that maximize its rewards.
In our project, the agent is a voxel-based builder of a user-specified grid size. The state includes a voxel grid along with environmental and structural data, things like solar exposure, daylight, deflection, and material cost. The actions are to add, delete, modify the facade, or take no action for one step. Each action is evaluated through performance metrics, which serve as rewards.
The environment also includes constraints such as site boundaries, climate data from different locations, and repulsors that penalise unwanted growth. This setup allows the agent to explore many possibilities but it also introduces uncertainty, conflicting objectives, and significant computational training cost. Through this framework, we investigate how reinforcement learning can drive architectural form-finding in a way that balances multiple performance goals.
State of the Art
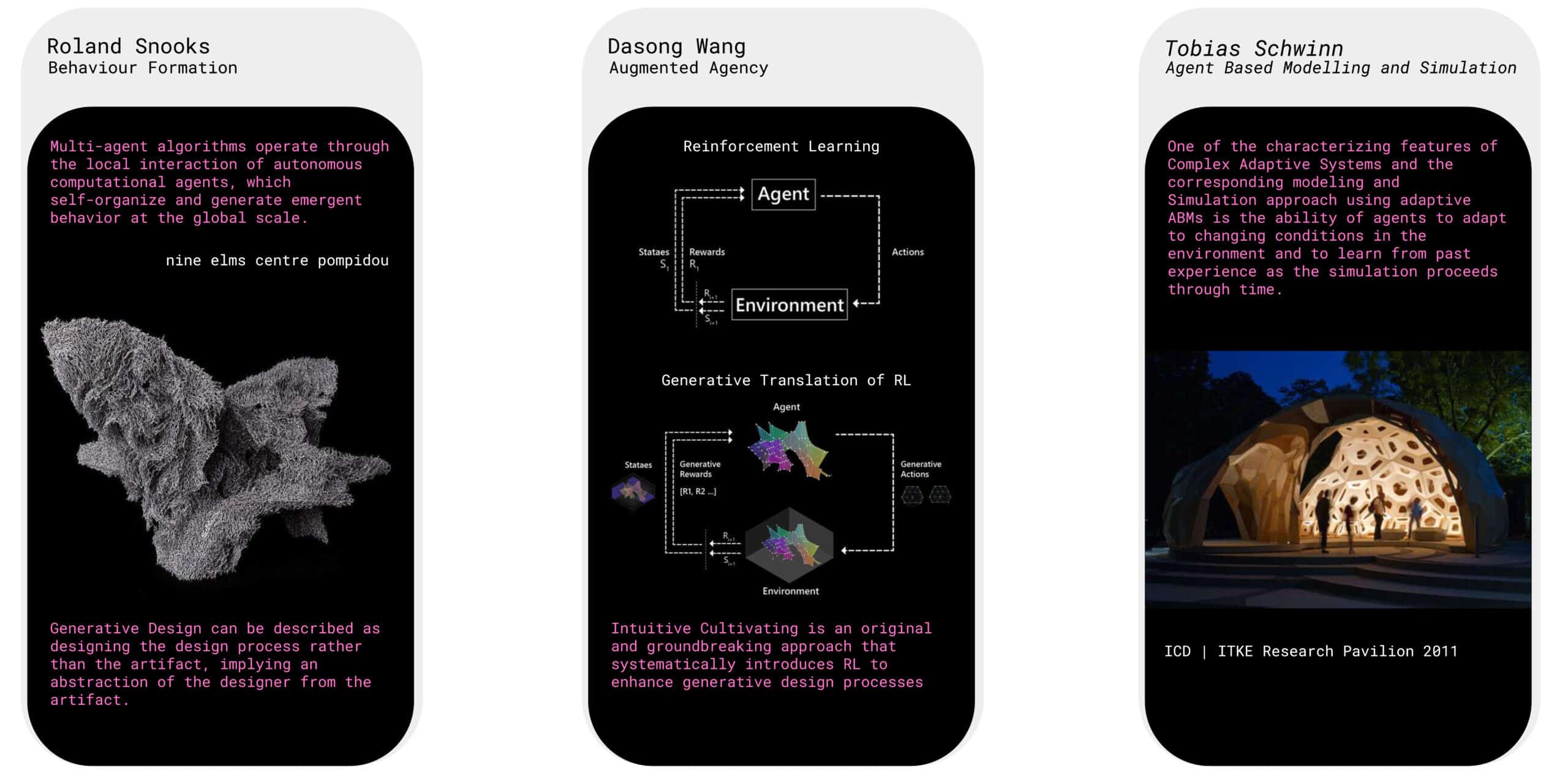
When we look at the state of the art, we see different approaches to generative and agent-based design. Notably, Roland Snooks explores behavioural formations through multi-agent systems. Here, autonomous agents interact locally, producing emergent and highly complex forms at a global scale. While the results are visually striking, they often lack architectural usability since the agents don’t directly respond to environmental context.
Dasong Wang introduces Augmented Agency, where reinforcement learning is applied to guide generative processes. This approach systematically integrates performance feedback to make the design more adaptive and intentional.
Tobias Schwinn explores agent-based modeling and simulation, focusing on structural optimisation. Agents are tasked with achieving segmentation and planarization of a shell for structural stability and cost efficiency, but have no input from the context beyond the shell.
Together, these projects demonstrate the potential of agent-based and reinforcement learning methods, but also reveal a gap: a lack of integration between emergent form-finding and contextual environmental performance goals, which is where our research positions itself.
Environmental Goals // LBC
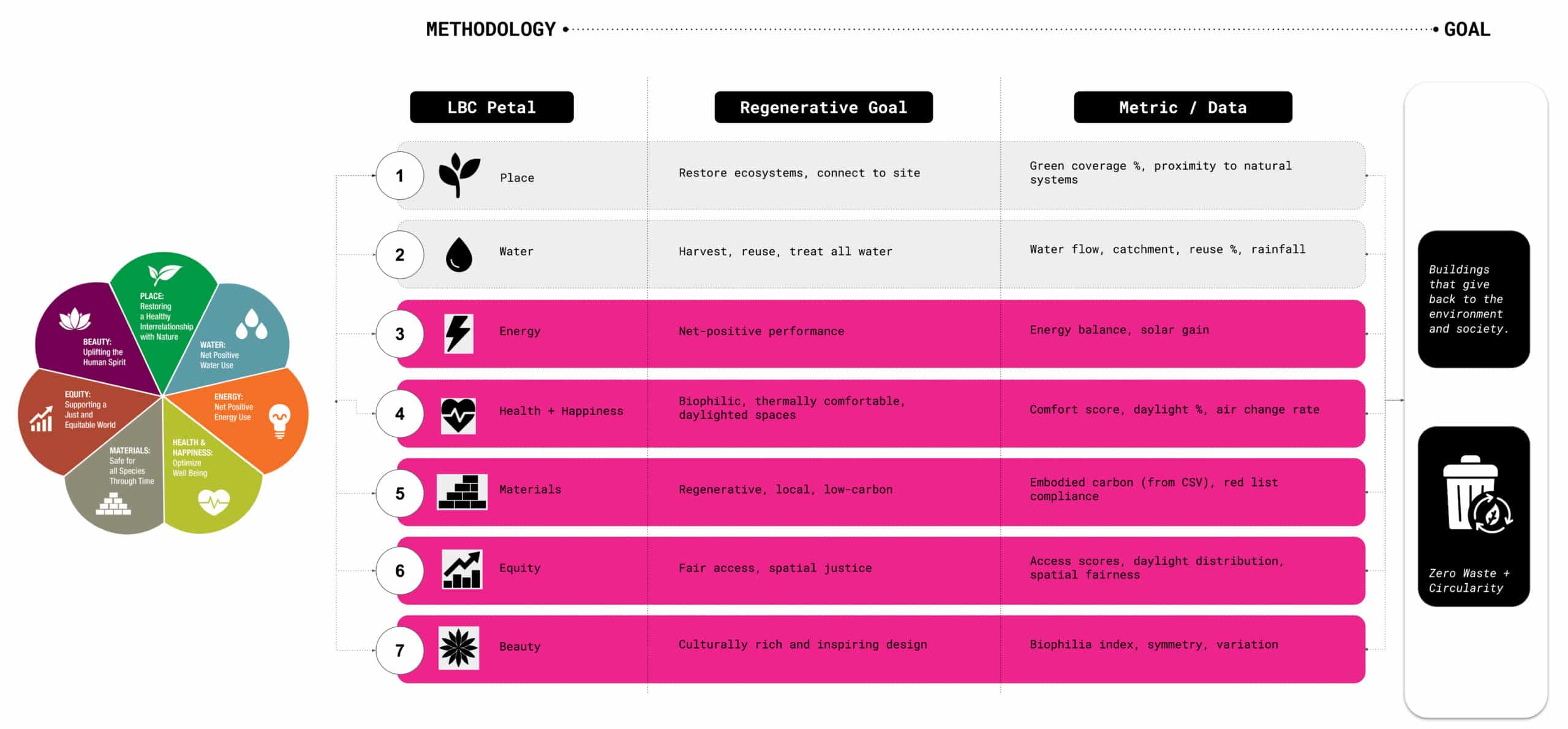
For our environmental goals we looked to The Living Building Challenge which sets out seven regenerative goals, or petals, from water and materials to equity and beauty. It’s a framework for architecture intended to give back more than it takes.
In our project, we focused mainly on energy and daylight performance, since these can be directly measured and embedded into reinforcement learning as reward signals using GPU accelerated methods. By training the agent on solar gain and daylight autonomy, we guide form finding toward buildings that are responsive to their context.
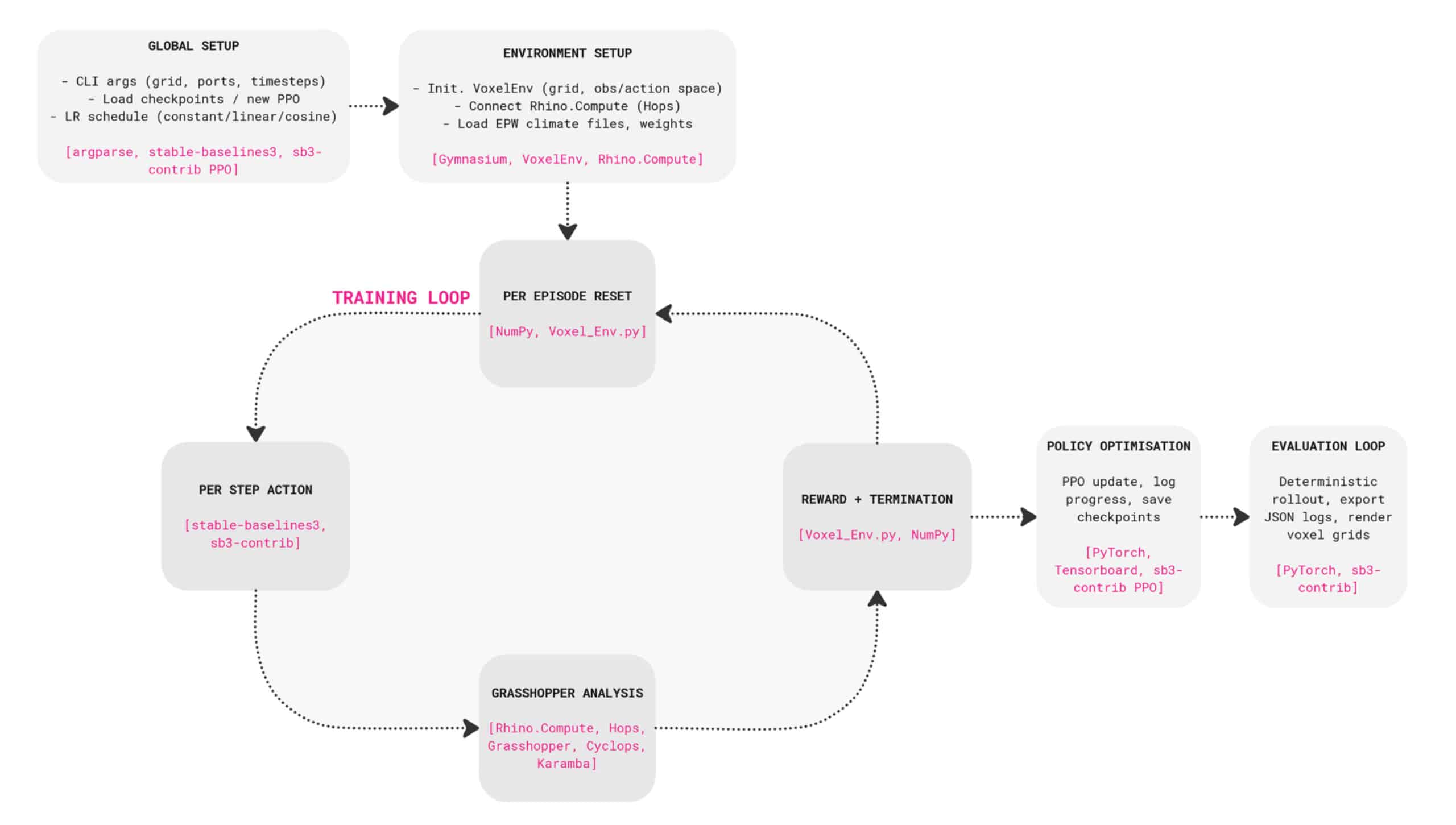
Methodology // Workflow
Here’s an overview of our workflow. We start by setting up the voxel environment and connecting it to Rhino and Grasshopper headlessly through Rhino.Compute and Hops, with climate data from EPW files.
The agent is trained using Stable Baselines 3, with sb3-contrib to create action masks using a MaskablePPO policy. This ensures the agent only takes valid moves without wasting steps.
During training, the agent takes actions – adding or removing voxels, or adjusting the facade. Each step is analysed in Grasshopper for sunlight, daylight, structure, and facade material cost and waste. These results are returned as rewards to guide agent learning.
At the end of training, the policy is optimised and evaluated, producing voxel-based building forms.
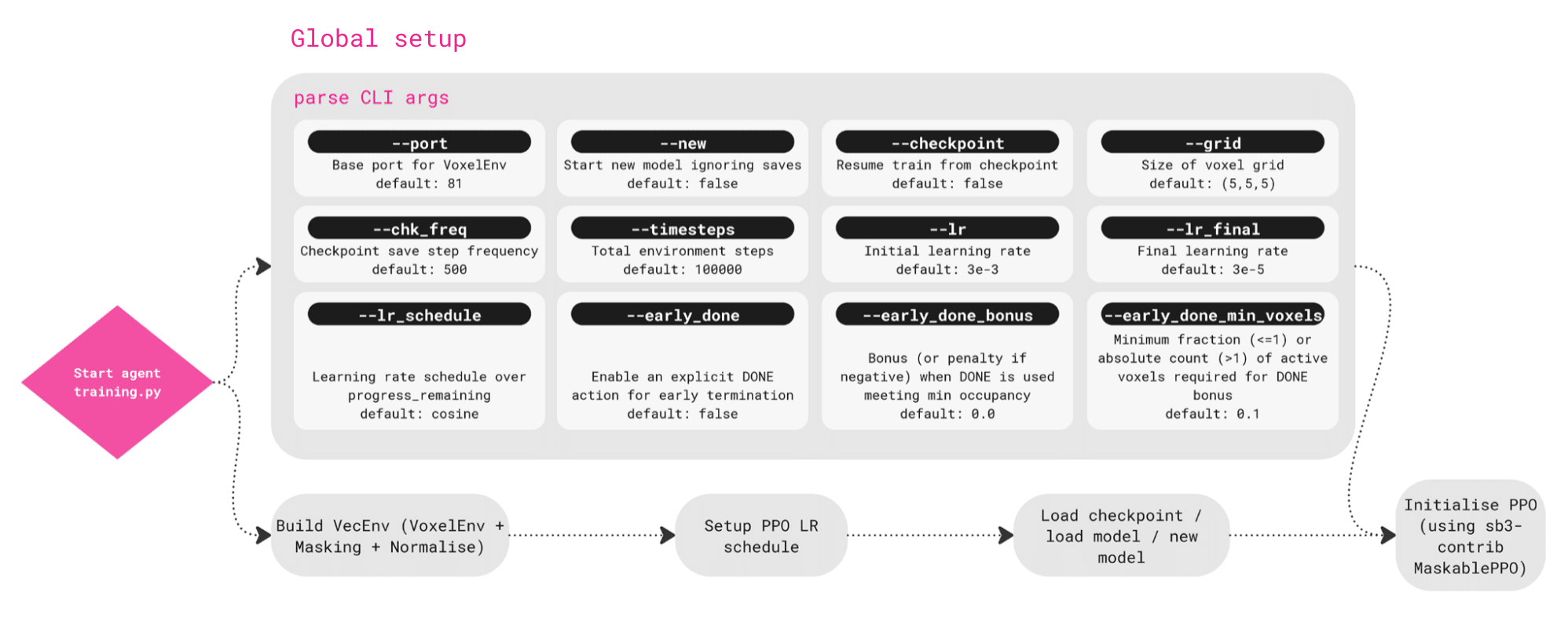
We’ll briefly discuss our detailed workflow – we begin with the global setup which defines the overall training configuration. This is where we set parameters like the voxel grid size, learning rates, and checkpoint frequency.
It also allows us to resume training from a saved model or start fresh with a new one.
In short this stage prepares the environment and initializes the agent before learning begins.
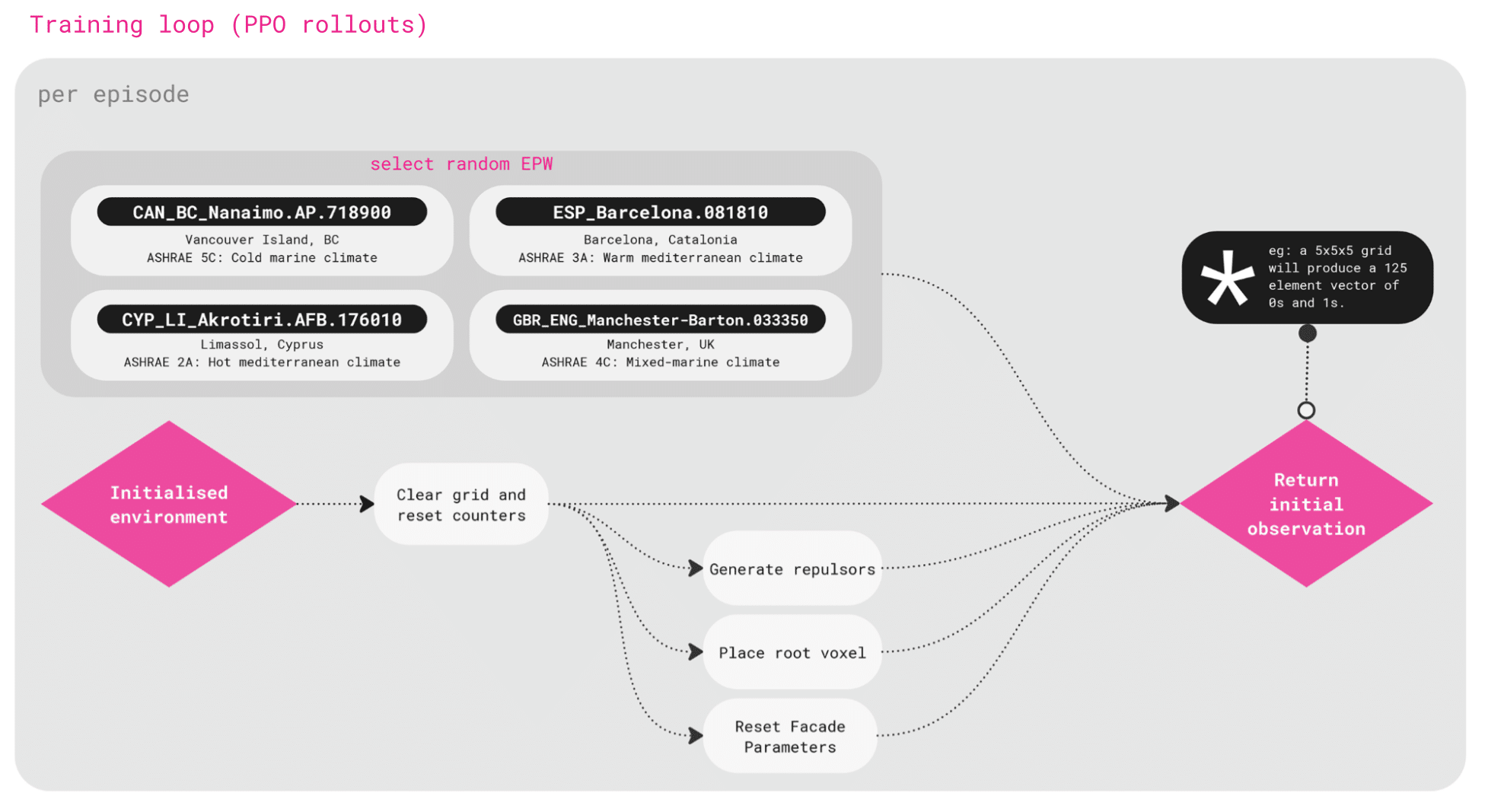
Once training begins, each episode starts by selecting a random climate file. This exposes the agent to different conditions, from cold marine climates in Canada to hot mediterranean climates in Cyprus.
The initialised environment places a root voxel that cannot be removed, and repulsors are places to mimic site constraints which penalise the agent if it builds too close.
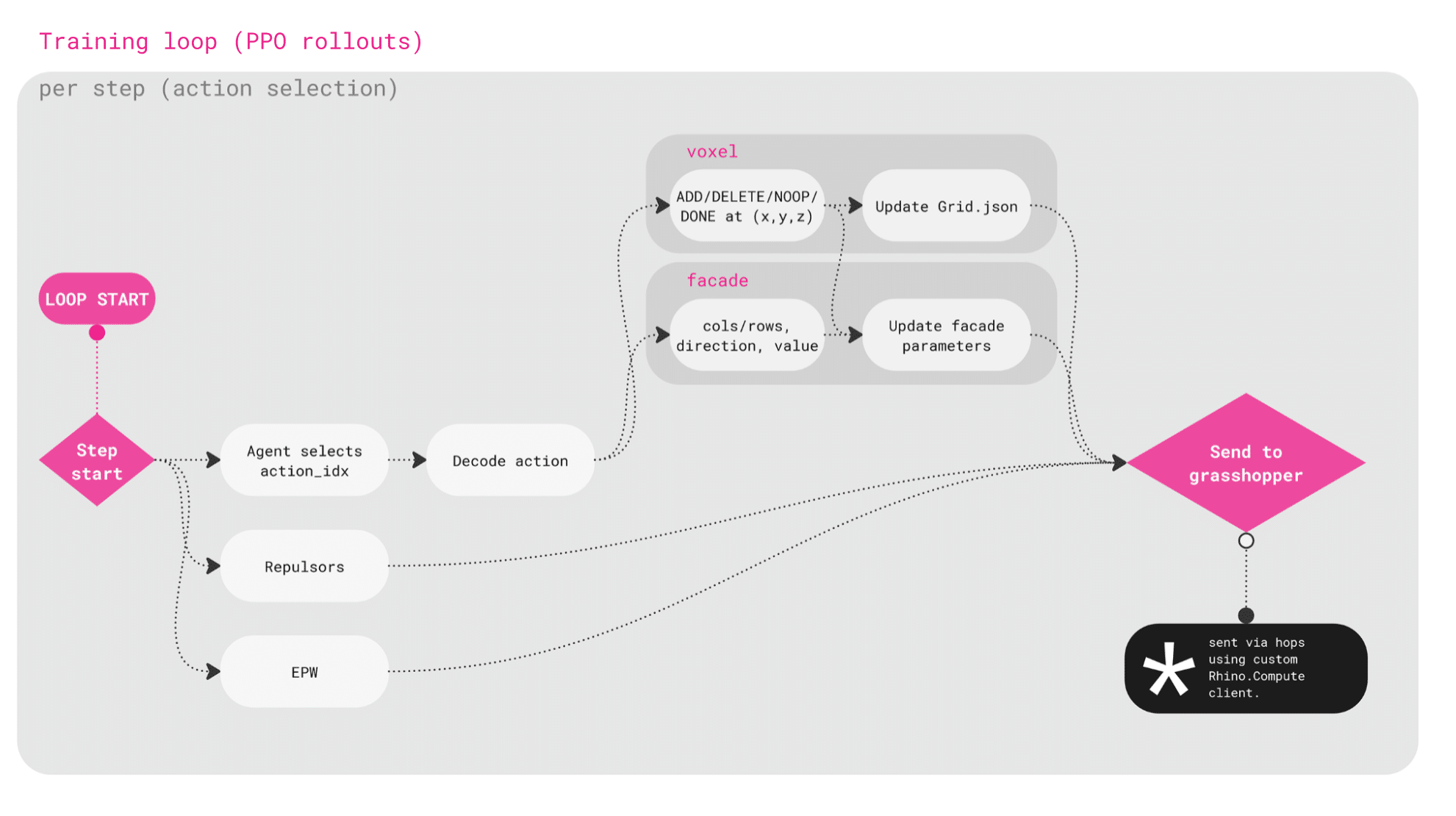
At the start of each step, the agent selects an action from its policy. This is a list of valid actions which can be taken that might be to add or delete a voxel, do nothing, or adjust facade parameters.
These updates are applied to the voxel grid, and the geometry is sent to Grasshopper through Rhino.Compute for the reward evaluation.
Once inside Grasshopper, the design is analysed across three areas:
With Cyclops, we calculate sunlight and daylight performance of the voxel grid and the facade configuration.
With Karamba3D, we run a structural analysis to determine the maximum displacement of structural elements assuming a uniform material buildup.
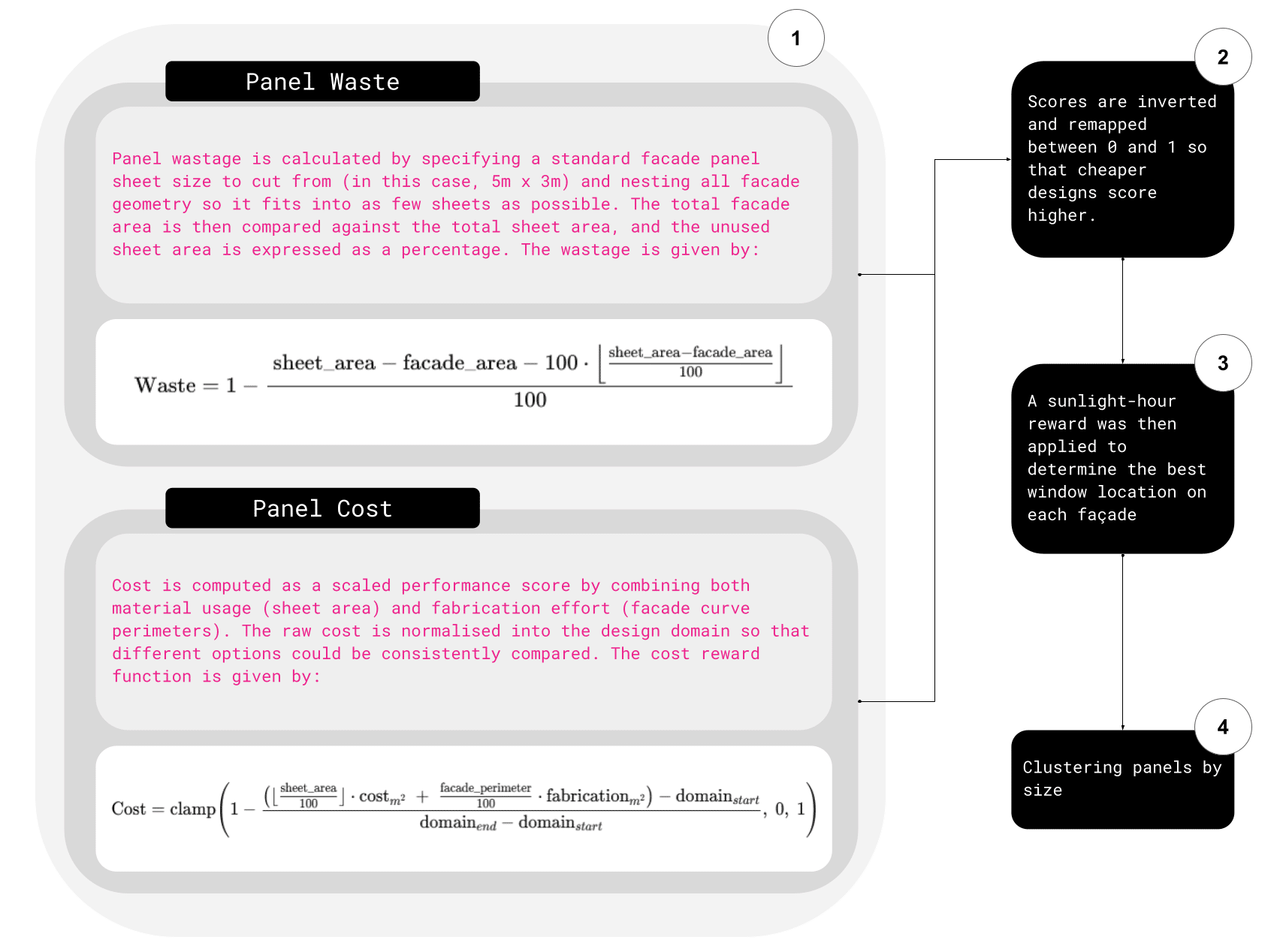
And with custom scripts, we measure facade panel cost and material waste by nesting facade geometry into standardised facade panel sheet sizes and making area calculations.
All of these results are turned into reward values and combined into a weighted score, which is sent back to the agent, guiding its next move. The weights of each reward are editable within the agent training script, so the user could tailor their solution based on their priorities.
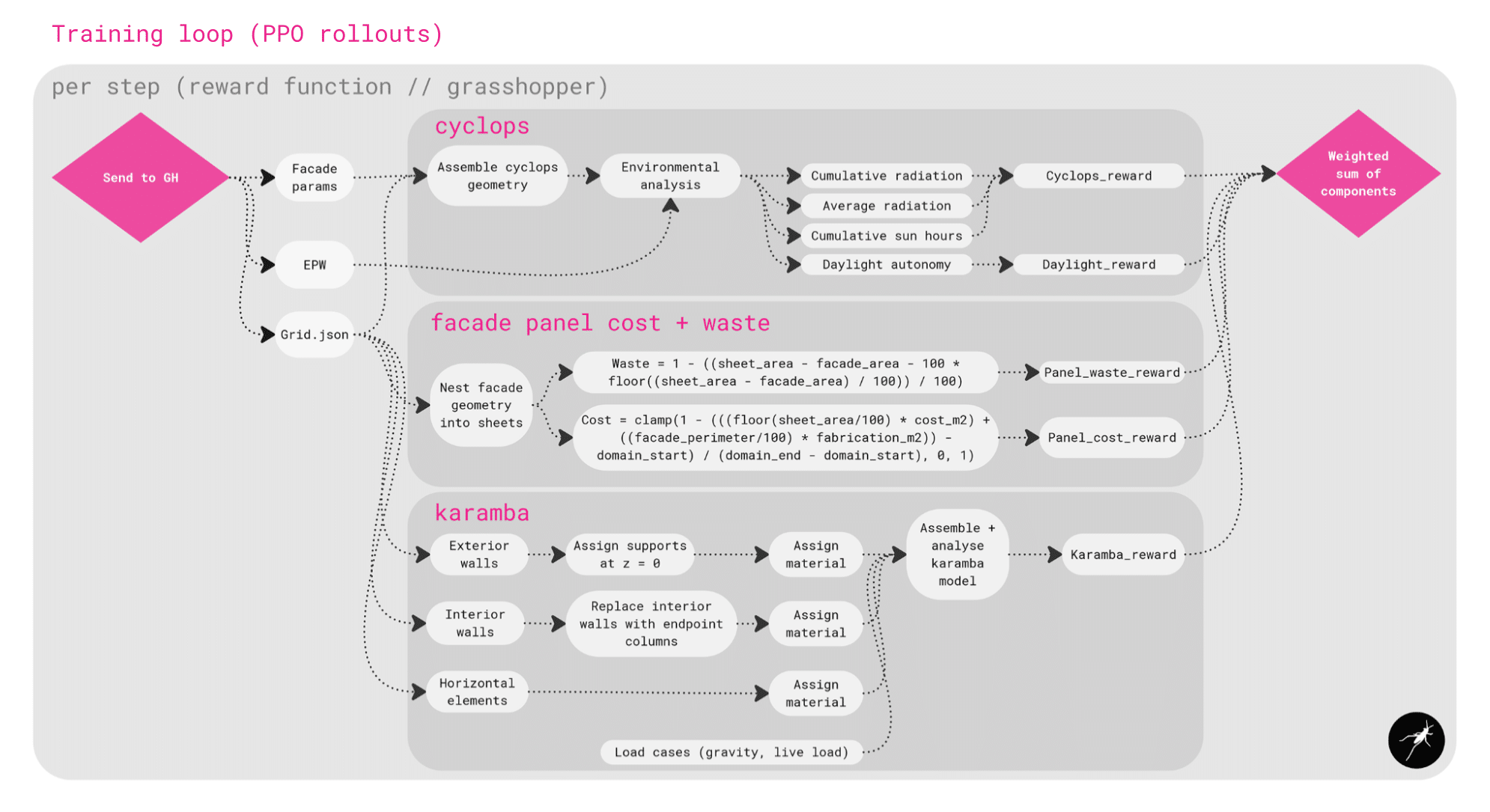
The weighted sum is received back to the script from Grasshopper, and rewards are summed and penalties applied for things like clashing with repulsors. The system then checks whether the episode should end, for example, if the grid is full, the step limit is reached, or no valid actions remain.
Once an episode ends, the rollouts are collected and the policy is optimised, and then the progress is saved.
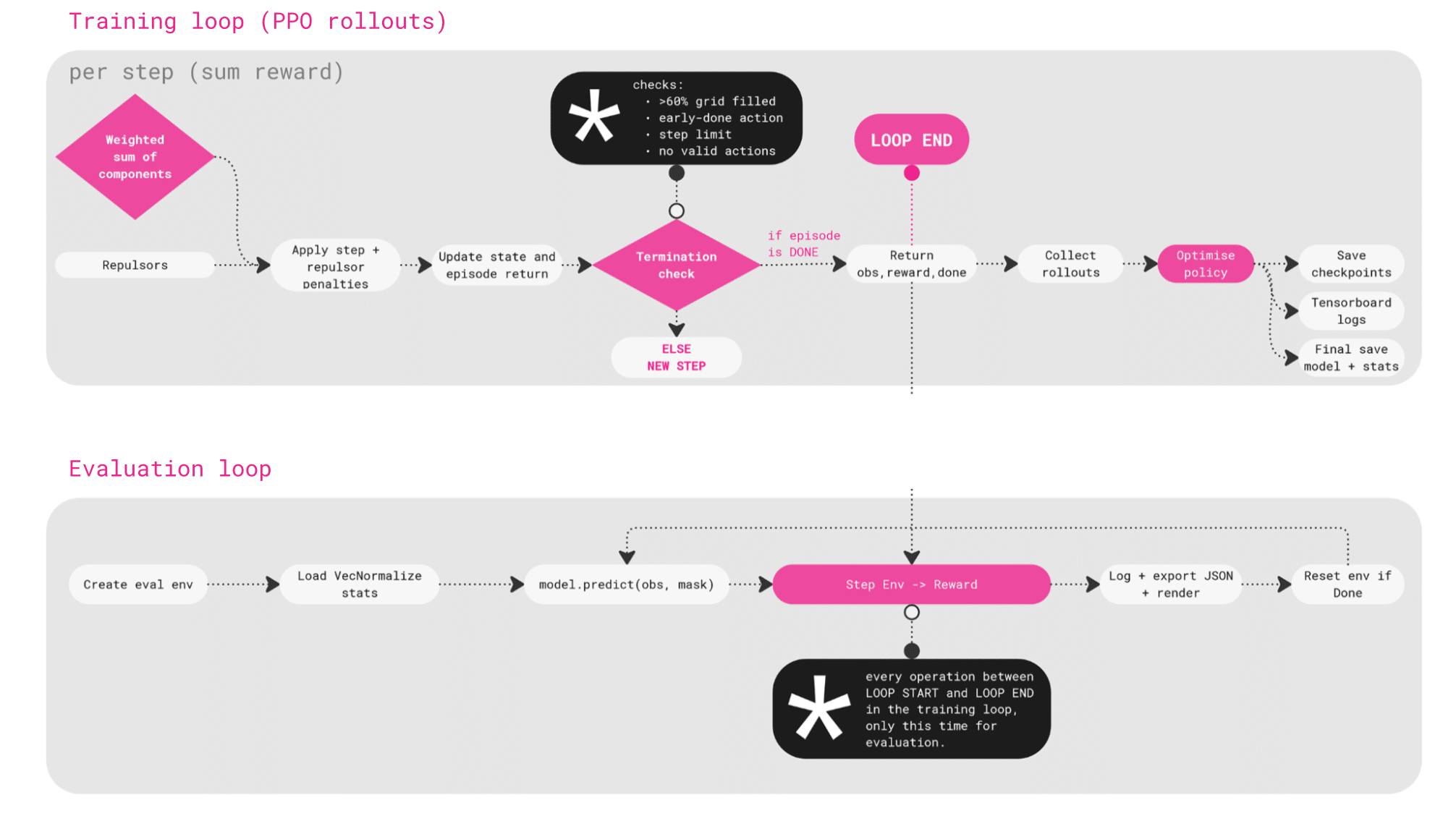
Training //

Here we can see how the training unfolded over 80 episodes, roughly 20,000 steps.
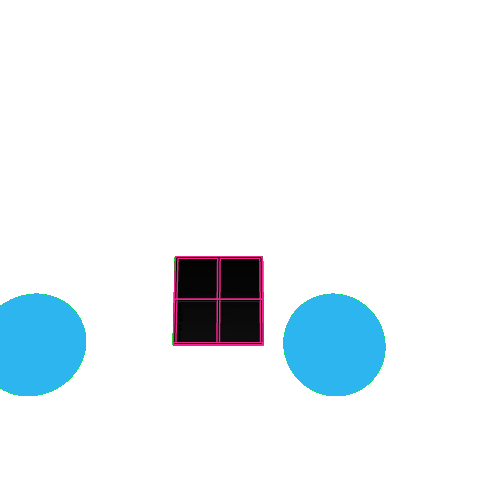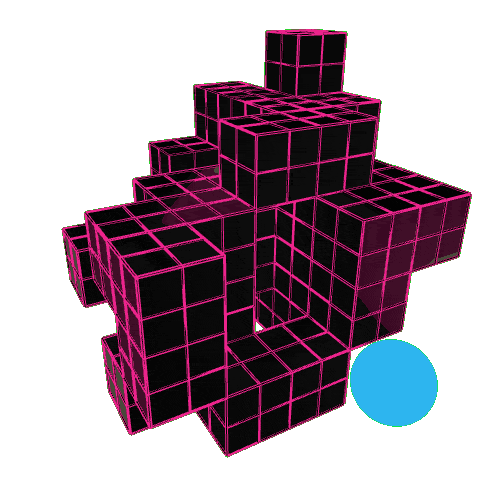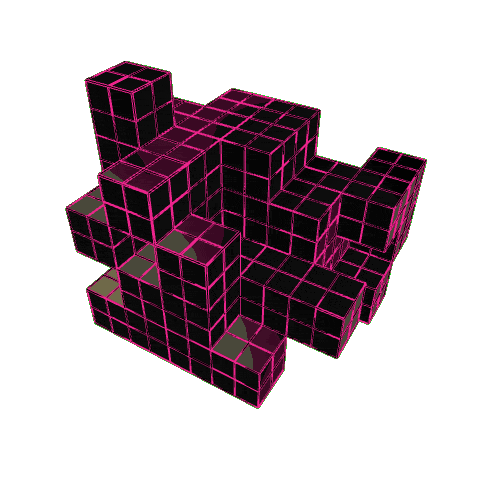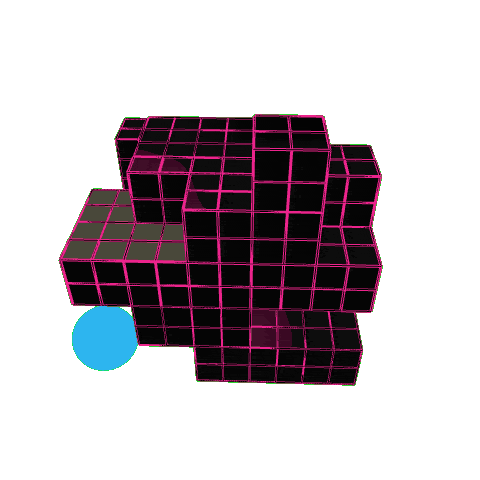
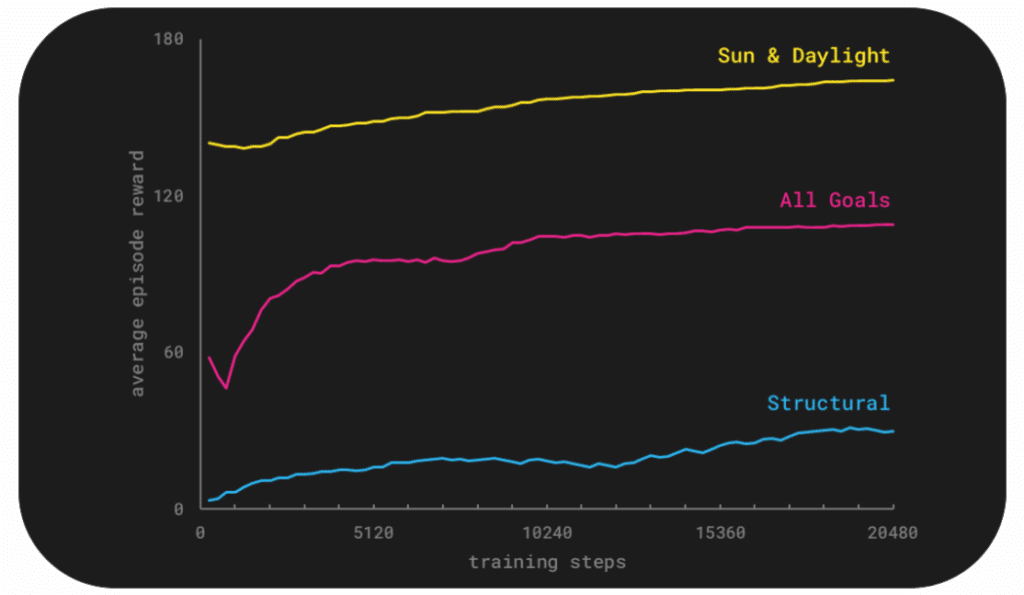
On the right, you can see the learning curves for different reward schemes. The sun and daylight model performs the strongest while the all goals model improves steadily, while the structural-only model struggles to learn.
Results // Sunlight & Daylight (Cyclops)
Here is an example of how the model behaves when only trained on sun and daylighting – what’s interesting is how the agent learns to carve holes into the building form. By doing this, it increases the surface area to volume ratio, exposing more faces to the sun.
On the right, you can see the performance maps. The irradiance shows strong solar gain, the daylight autonomy map shows deep light penetration to the interior. In other words, the agent learns a design strategy that maximises sunlight by hollowing out the form.
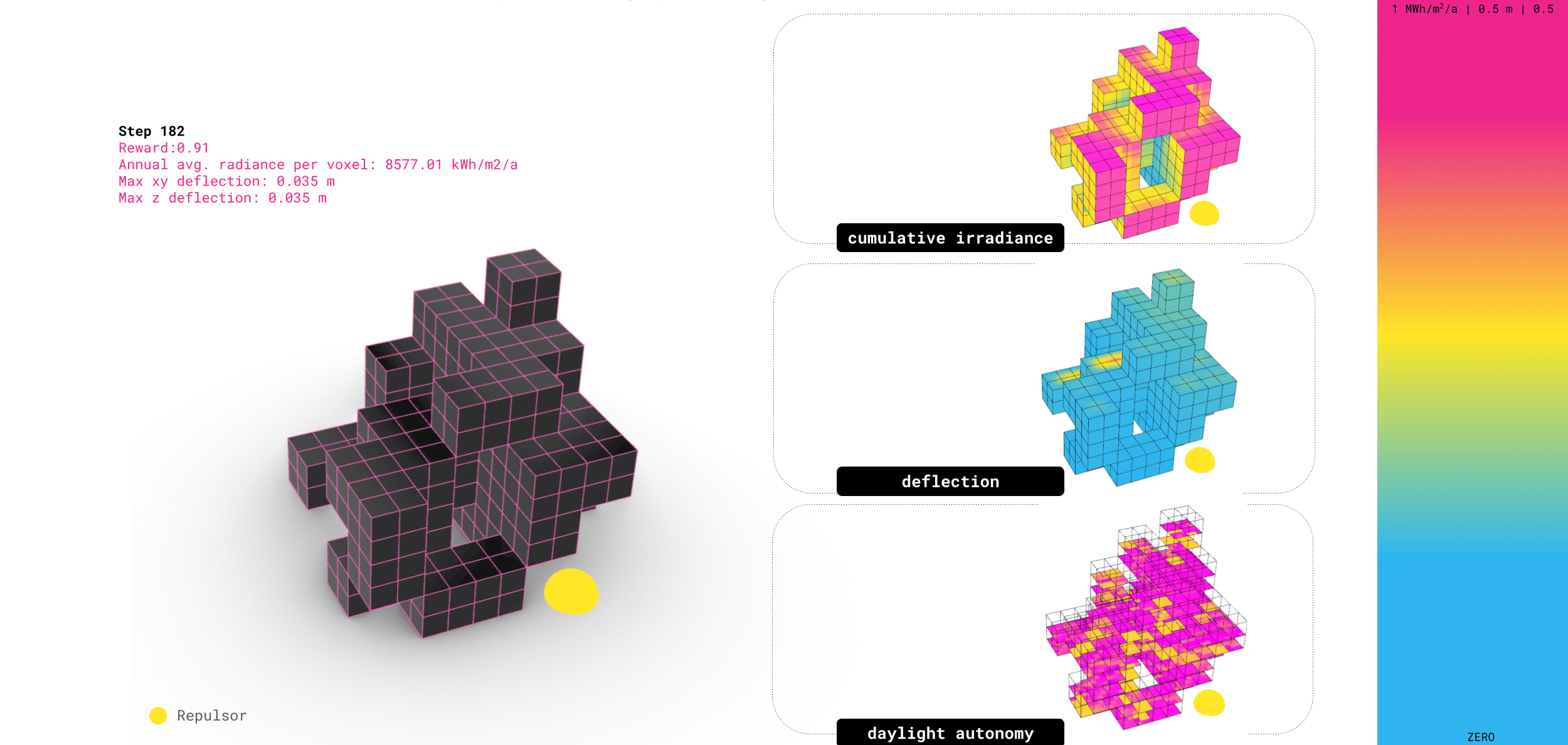
Results // Structure (Karamba3D)
As mentioned, the learning for the structural deflection was much less effective. It became clear early on that the feedback for structure would be much more complex – we only ended up training for about 20,000 steps, which took roughly 24 hours, when we should have trained to 100,000 steps or more to converge towards a stable structural strategy.
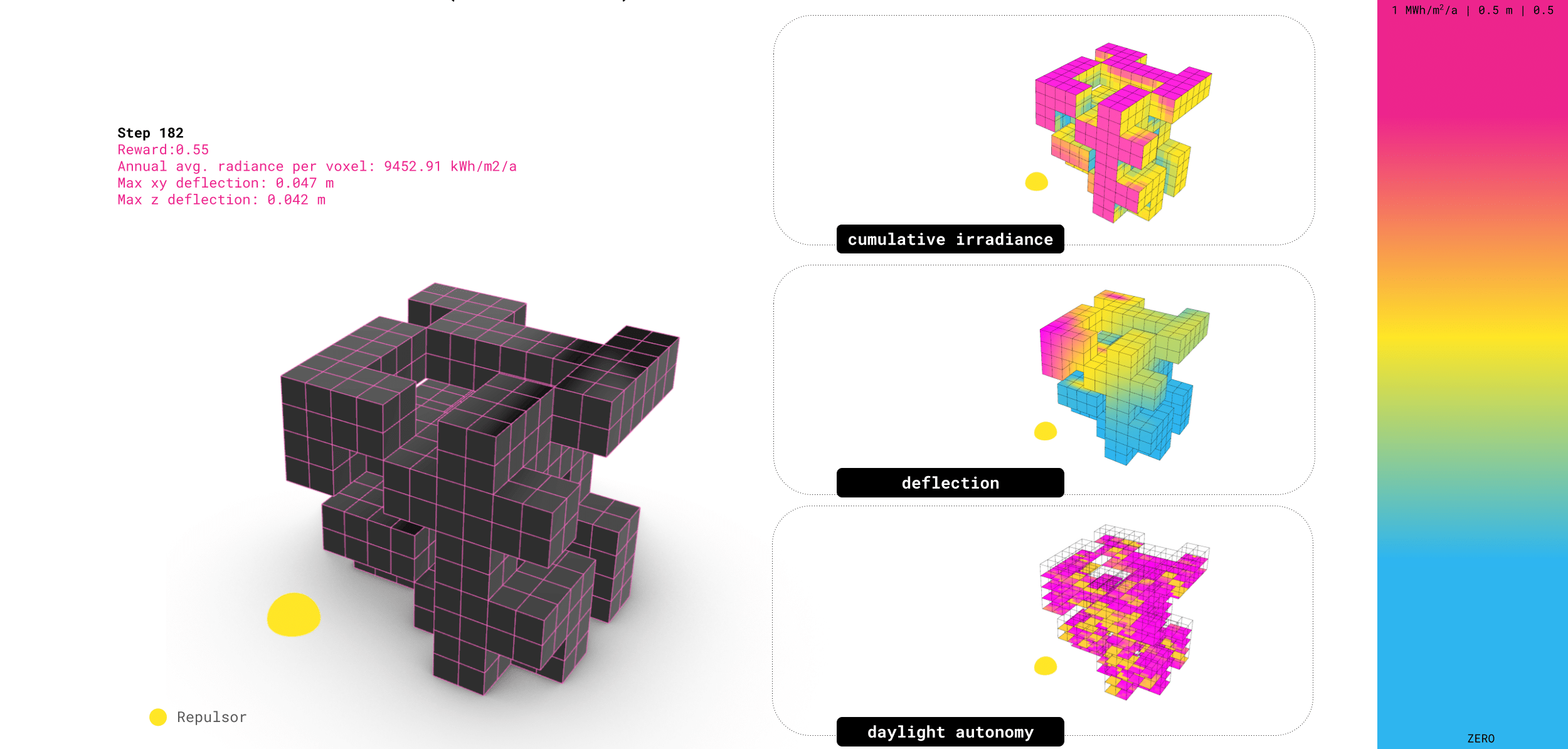
Results // All Goals
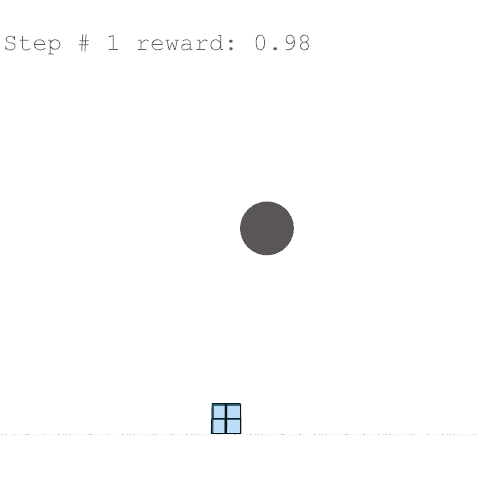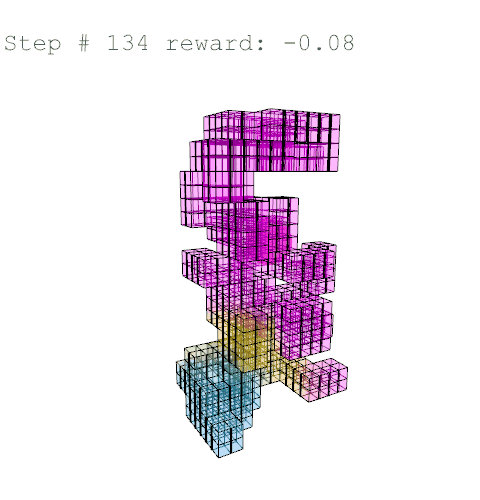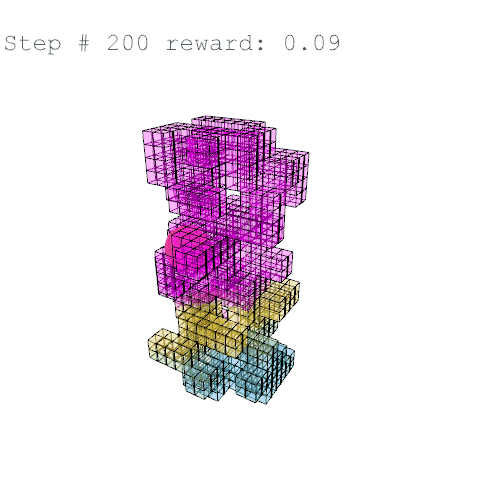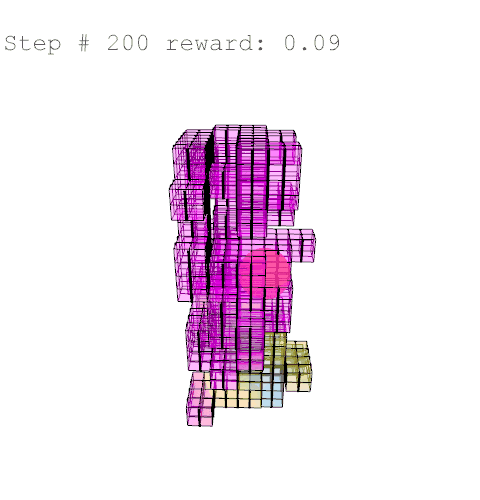
When we include all goals together, the results land somewhere between the environmental-focused and structure-focused models. We can see the beginnings of the agent learning to spread structural stress more evenly across the form, as the deflection is less concentrated than it was on the purely environmental model.
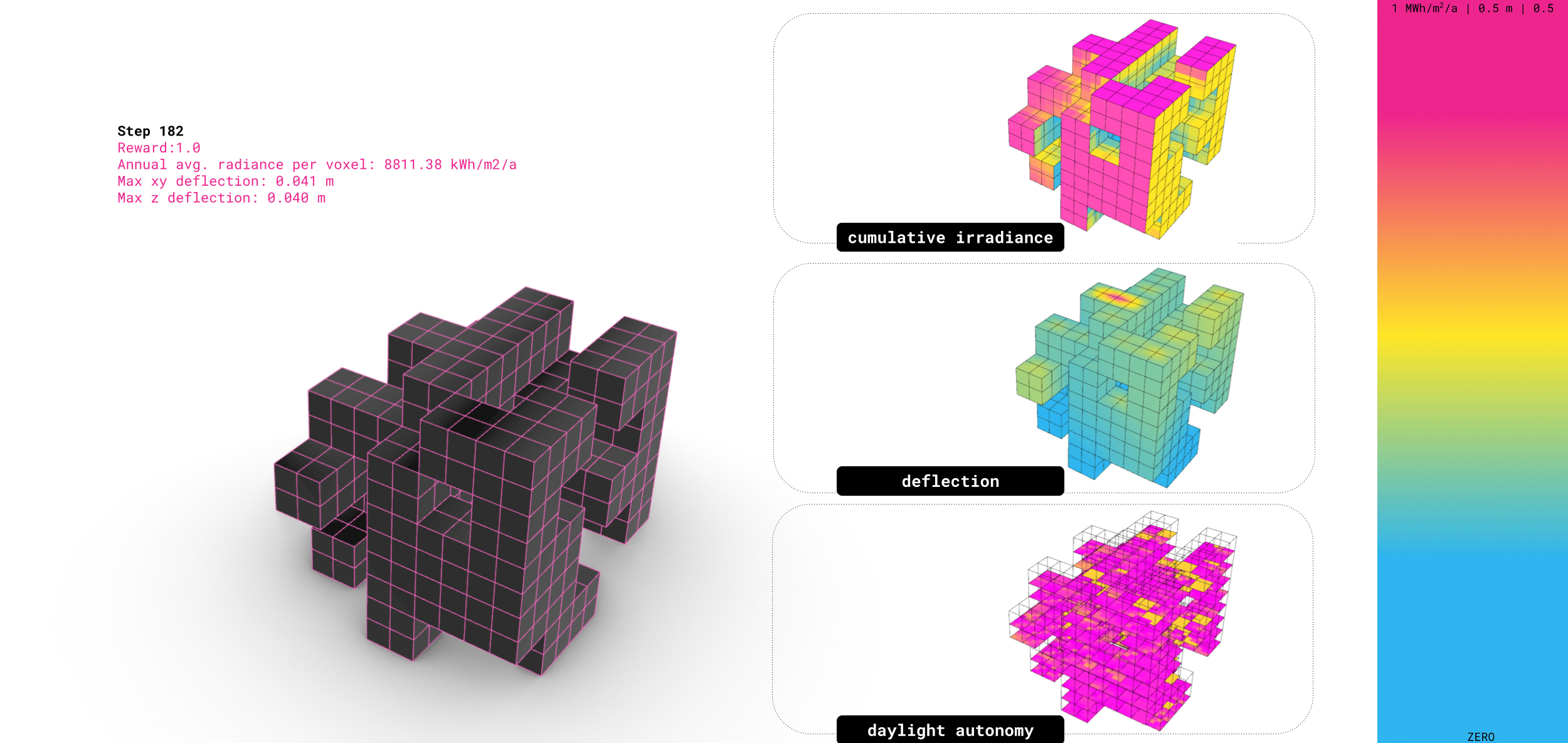
Results // Panel Cost + Waste reward
Here we look at facade panel cost and waste as part of the reward system, can see how waste is calculated by nesting facade panels into standard sheet sizes, the less leftover material, the better the score. Cost is then computed by combining material usage with fabrication effort, such as the length of the curve perimeters.
The agent learns to optimise these factors, clustering panels by size, and orienting windows toward areas with higher sunlight hours.
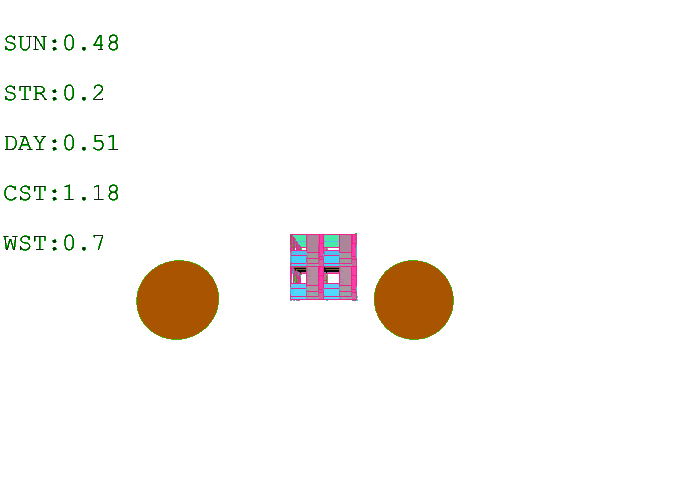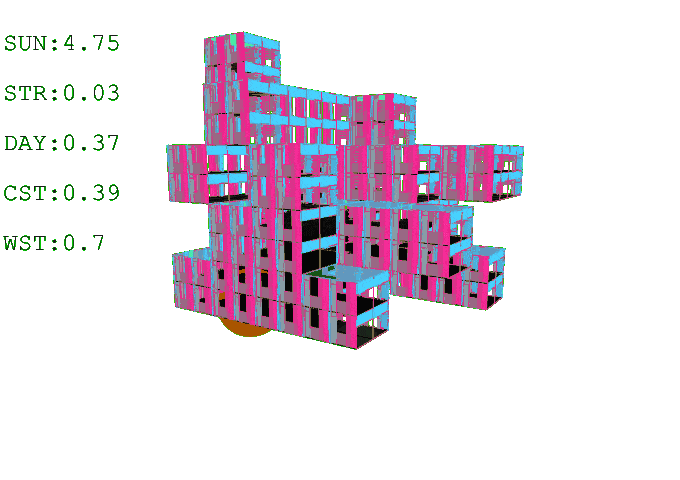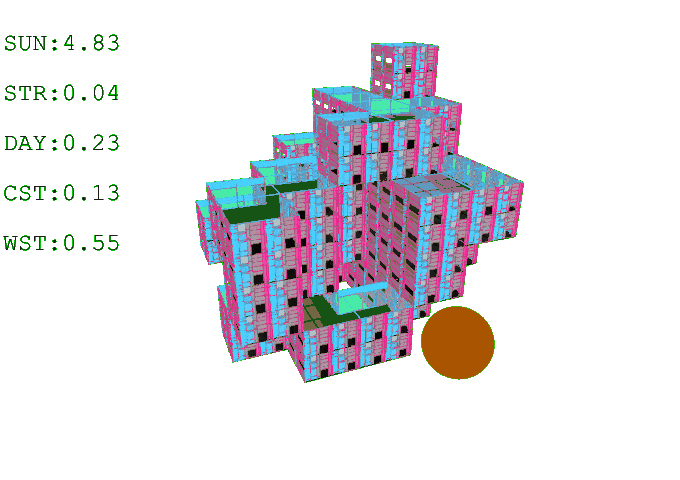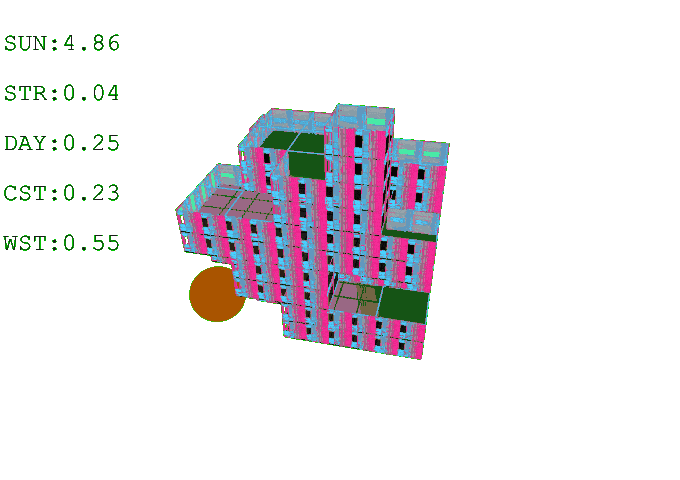
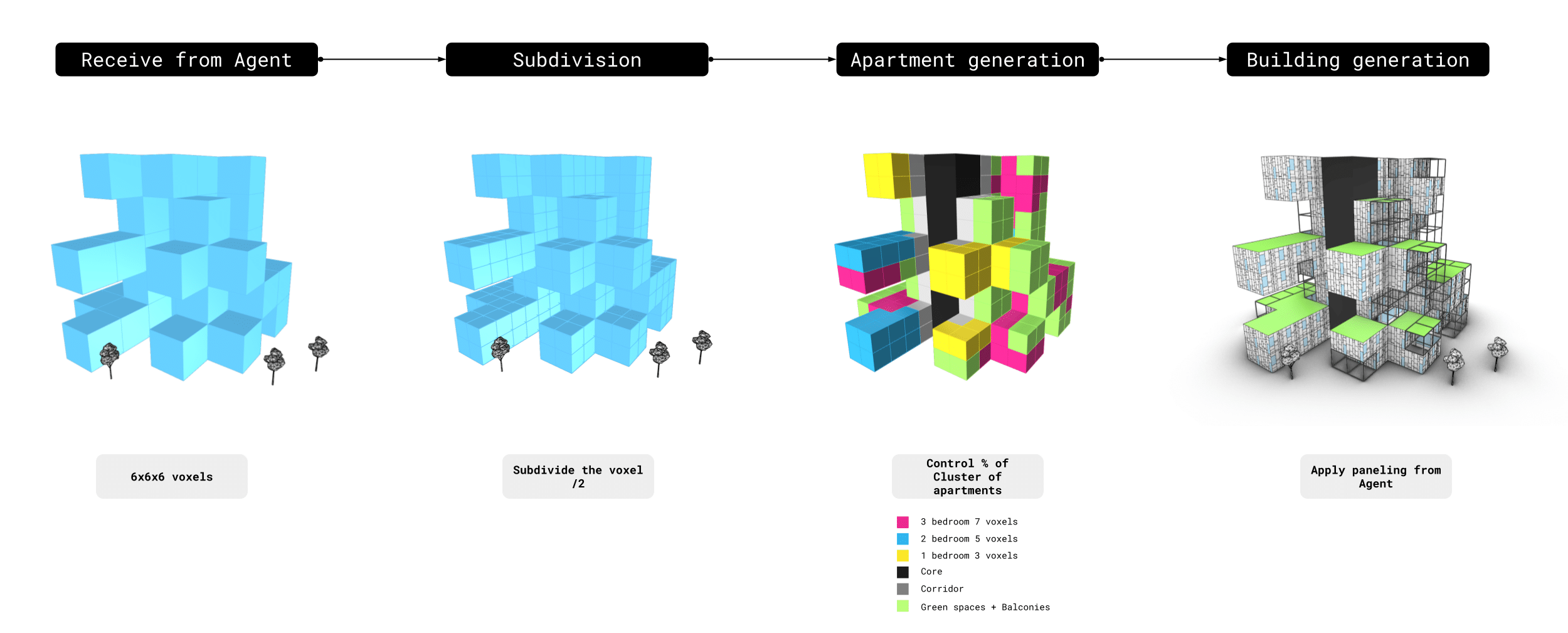
Results // Post Building Generation
A post-generation process is applied in Grasshopper after agent training. This step is necessary to transform the sculptural voxel formations into livable space. In this case, the outcome is a set of residential buildings composed of three-bedroom (7-voxel), two-bedroom (5-voxel), and one-bedroom (3-voxel) apartments. To accommodate for this typology, we trained the agent to always generate a central court, since initial experiments without a core resulted in missing or inconsistent central voxels across levels.
The post-process proceeds as follows:
Voxels are first subdivided in Grasshopper, with each voxel split into eight smaller ones. This increases spatial resolution while reducing training complexity. Next, a one-voxel corridor is defined around the core, and apartment clusters are generated at each level according to the chosen mix of unit types, which can be adjusted through percentage parameters in the code. Inevitably, some voxels remain unused; these are repurposed in Grasshopper as green spaces or balconies, contributing to both livability and environmental quality.
Results //


Discussion //
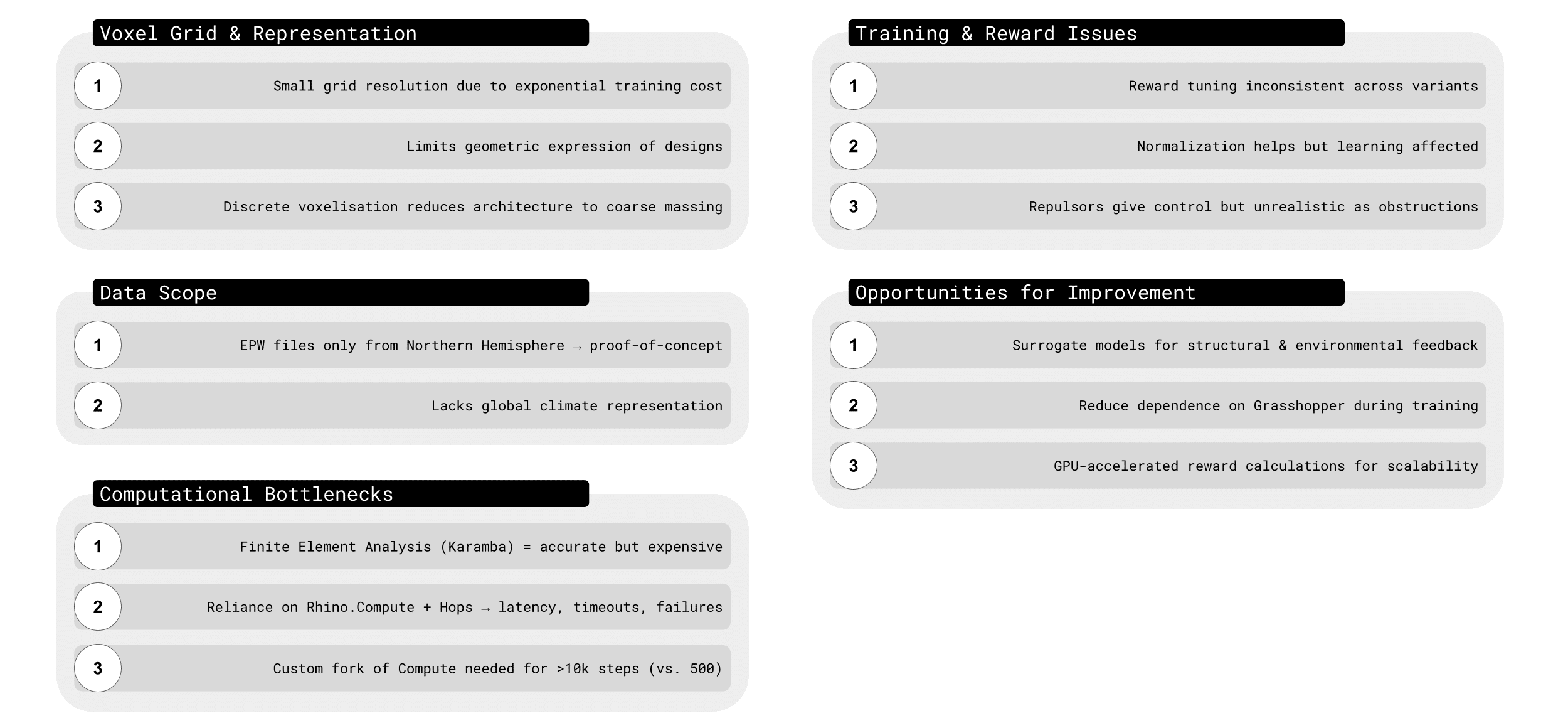
We ran into several key challenges while developing this proof of concept system. First, the voxel grid. Because of exponential training cost we had to keep it small, which limited geometric expression and reduced architecture to coarse massing.
Second, the training and rewards: sunlight and daylight produced strong signals, but structure struggled to learn. We suspect it’s at least partly because our action space to optimize structure was too limited – as the agent builds up it is penalized for the structural reward, without a daylight incentive it struggles to find a good strategy.
Third, computational bottlenecks: running Grasshopper analyses through Rhino.Compute introduced latency, timeouts, and required a custom fork of the rhino.compute client in order to get training running past a couple thousand steps without crashing due to memory strain. We could have benefitted from perhaps using physics informed machine learning or surrogate models, but we didn’t find the time to do so.
Conclusion //
Our work here is just an early step toward AI morphogenesis. With our proof-of-concept in Grasshopper, we showed how agents can adapt building forms based on environmental feedback, such as puncturing holes to maximise sunlight.
Looking ahead, surrogate models and GPU acceleration, could make the RL approach far more scalable.

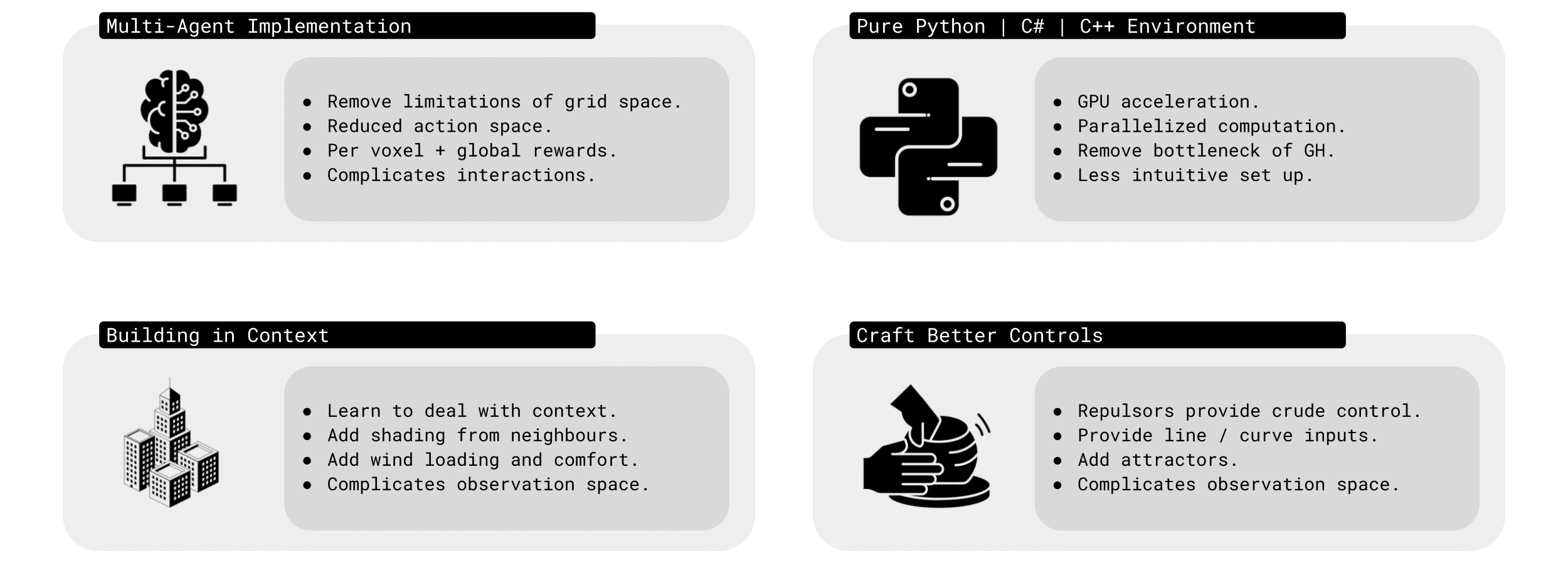
Future Work //
There are four main directions for future work – first, multi-agent implementation, where instead of a single agent, multiple agents could work together, removing grid limitations and reducing the action space.
Second, by moving to a pure Python or C++ environment we could unlock GPU acceleration and parallelised computation, removing Grasshopper as a bottleneck.
Third – building in context, teaching agents to consider neighbouring shading, wind loads, and site conditions.
And finally, better controls – instead of crude repulsors, giving designers line or curve-based inputs, or even attractors to guide form more intuitively.
Postscript //
Further training on a larger grid size of 6 x 6 x 12 voxels yielded the following results with reward weights set to: {str: 0.5; sun: 0.25; day: 0.25; wst: 0.05; cst: 0.05; rpl: 0.5}, animations are provided over the episode, with structural columns revealed. Color mapping is as above for structural deflection with a maximum value of 0.01 m.

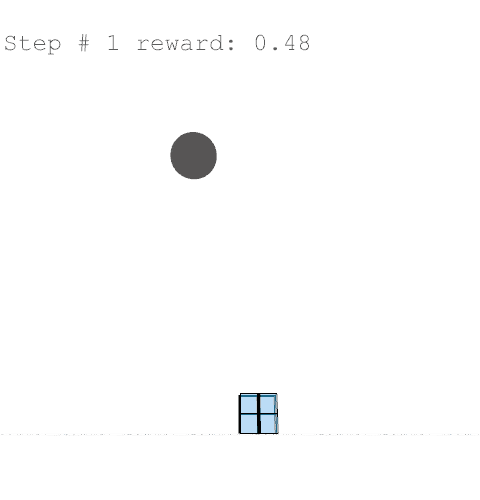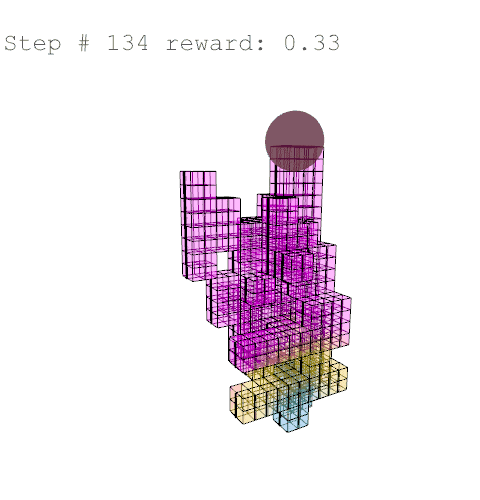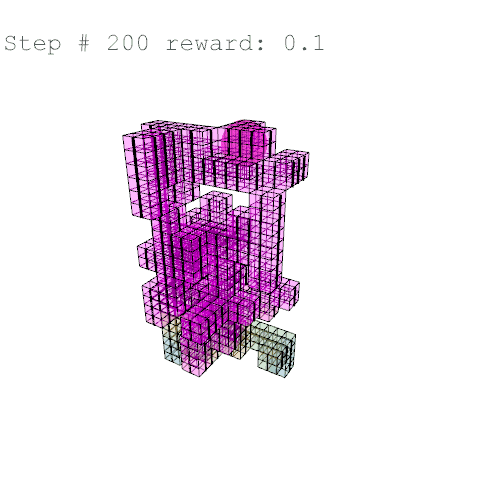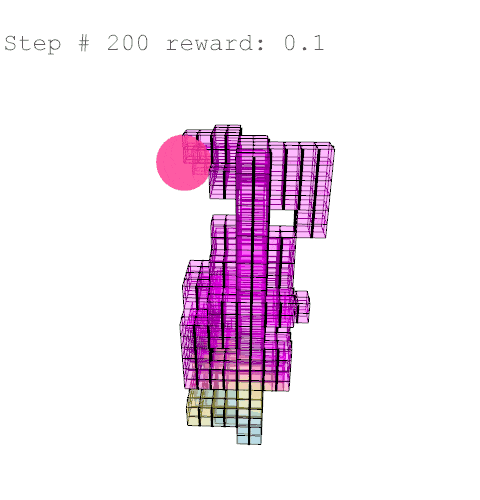
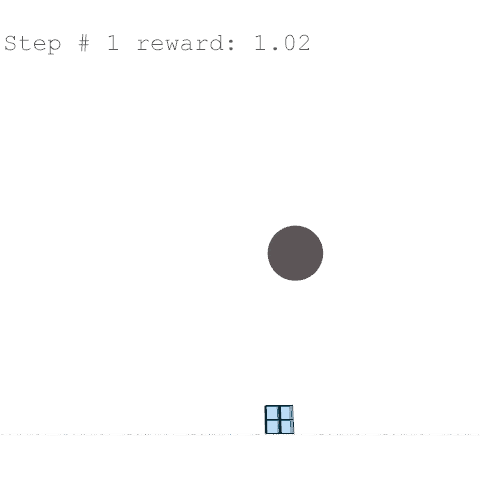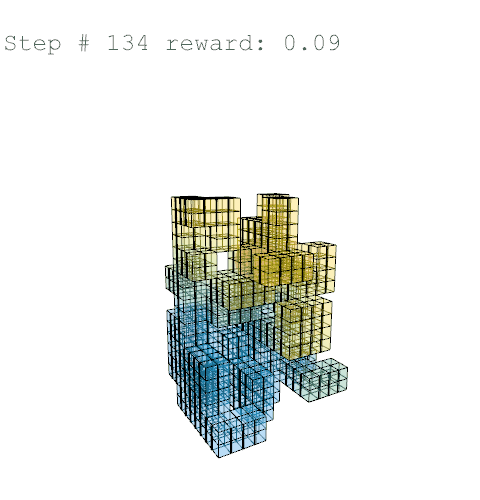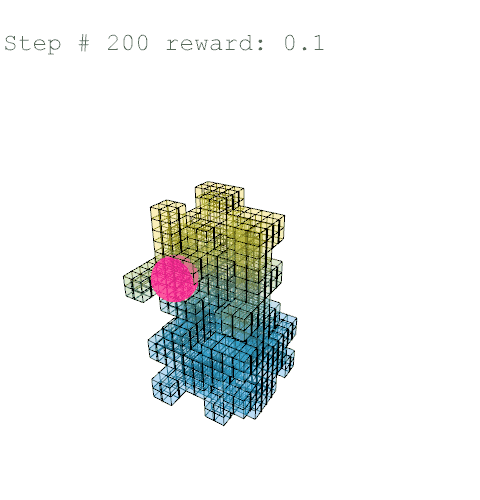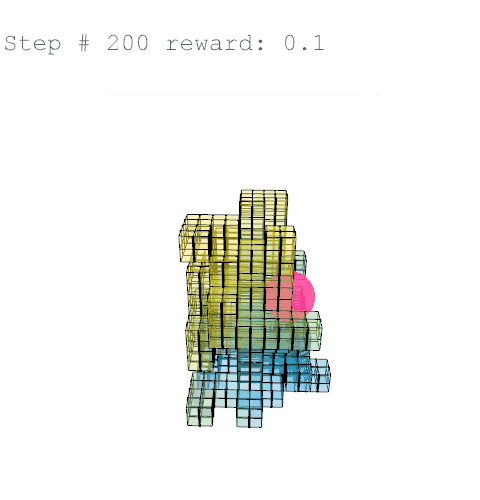

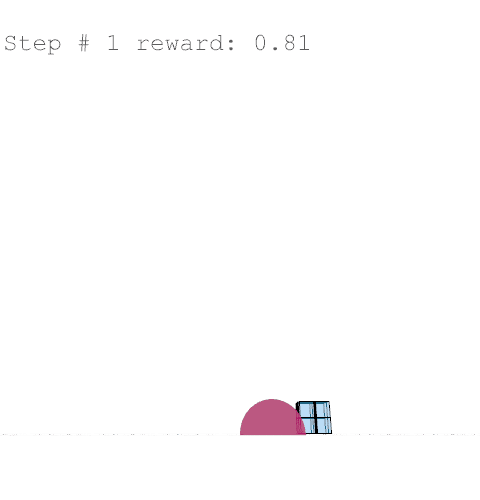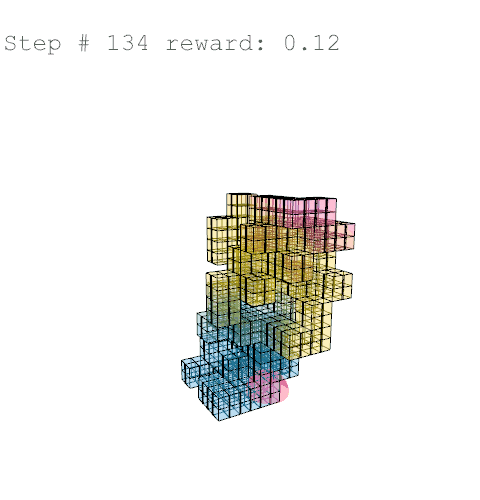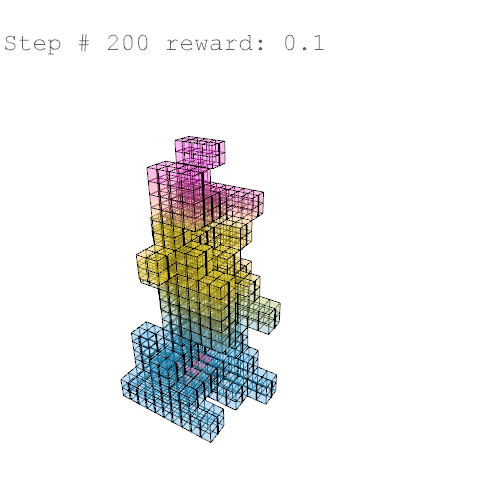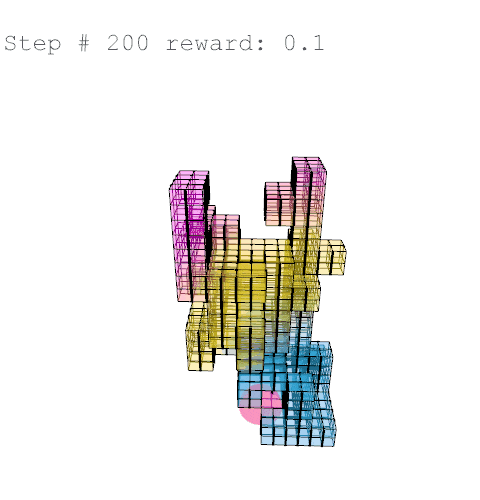
References //
Foster+Partners (2025) https://cyclops.fosterandpartners.com/ accessed 2025-09-09
Leach, Neil. (2009). “Digital Morphogenesis.” Architectural Design 79 (1 SPEC. ISS.): 32–37. https://doi.org/10.1002/ad.806
Neftci, Emre O., and Bruno B. Averbeck. (2019). “Reinforcement Learning in Artificial and Biological Systems.” Nature Machine Intelligence 1 (3): 133–43. https://doi.org/10.1038/s42256-019-0025-4
Patterson, Blake, Michael Ward Cis, Final Project, and Pei Wang. (2022). “Adaptive Procedural Generation in Minecraft.”
Preisinger, C. (2013), Linking Structure and Parametric Geometry. Architectural Design, 83: 110-113 DOI: https://doi.org/10.1002/ad.1564
Schwinn, T. (2021). A systematic approach for developing agent-based architectural design models of segmented shells : towards autonomously learned goal-oriented agent behaviors [Dissertation, Institute for Computational Design and Construction, University of Stuttgart]. https://doi.org/10.18419/OPUS-11633.
Silver, David, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, et al. (2017). “Mastering the Game of Go without Human Knowledge.” Nature 550 (7676): 354–59. https://doi.org/10.1038/nature24270
Snooks, Roland (2017). Behavioral formation: multi-agent algorithmic design strategies. RMIT University. Thesis. https://doi.org/10.25439/rmt.27591192
Turing, Alan M. (1952). “The Chemical Basis of Morphogenesis.” Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences 237 (1–2): 37–72. https://doi.org/10.1016/S0092-8240(05)80008-4
Wang, Dasong and Snooks, Roland (2021) “Intuitive Behavior – The Operation of Reinforcement Learning in Generative Design Processes.” Proceedings of the 26th Conference on Computer Aided Architectural Design Research in Asia (CAADRIA), https://doi.org/10.52842/conf.caadria.2021.1.101
Wang, Dasong (2023). Augmented agency: approaches for enhancing the capabilities of generative architectural design processes. RMIT University. Thesis. https://doi.org/10.25439/rmt.27598200 Yang, Xuyou, Ding Wen Bao, Xin Yan, and Yucheng Zhao. (2022). “OptiGAN: Topological Optimization in Design Form-Finding With Conditional GANs.” Proceedings of the 27th Conference on Computer Aided Architectural Design Research in Asia (CAADRIA) [Volume 1] 1 (May): 121–30. https://doi.org/10.52842/conf.caadria.2022.1.121
