

Automating Architectural Visualization: A Journey Through Technical Pivots and AI Evolution

Introduction
In the rapidly evolving landscape of architectural visualization, the gap between conceptual design and compelling visual presentation remains a significant challenge. While architects and designers excel at creating innovative spaces, transforming these 3D models into cinematic walkthroughs typically requires specialized skills, expensive software, and countless hours of manual work. This project emerged from a simple question: What if we could democratize architectural visualization by automating the entire process through natural language commands?
Our vision was to create a pipeline where users could simply upload their 3D models and describe the camera movements they wanted in plain English – “orbit around the building slowly” or “dramatic reveal from ground to sky” – and receive professional-quality animations within minutes. This blog documents our technical journey, the challenges we encountered, and the pivotal moments that shaped our approach to automated architectural storytelling.
The Problem Space
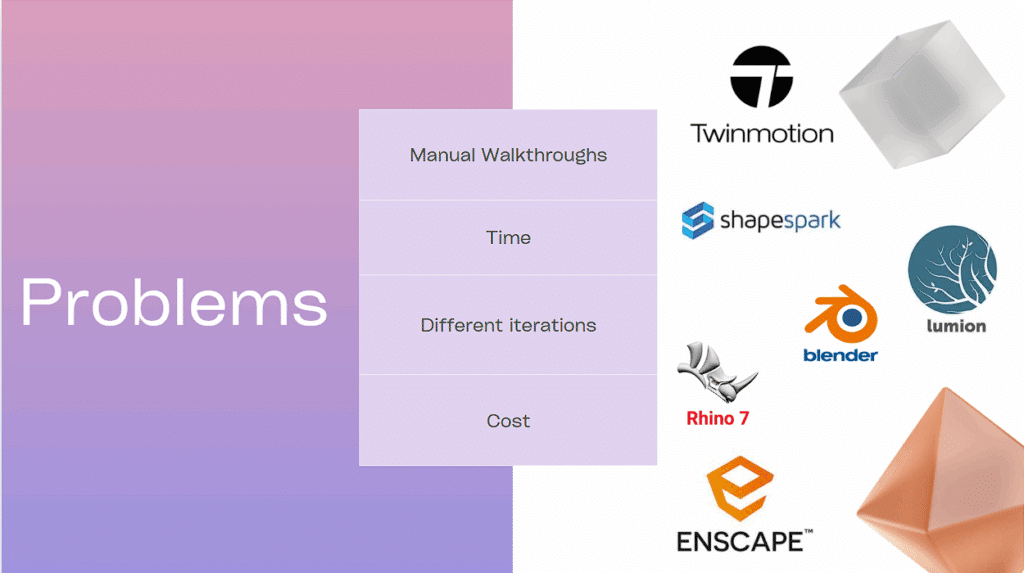
The current state of architectural visualization presents a tripartite challenge that affects professionals across the industry. First, there’s the time factor – creating even a simple walkthrough requires hours of keyframing, path adjustments, and render iterations. A typical 30-second architectural animation can consume 20-40 hours of skilled labor. Second, the iteration problem compounds this time investment. Clients rarely approve the first version, leading to endless cycles of “can we see it from another angle?” or “what if we approach from the east instead?” Each iteration isn’t just a minor adjustment – it’s often a complete rework of camera paths, lighting, and timing.
Finally, there’s the cost barrier. Professional visualization software like Lumion, Enscape, or Twinmotion comes with hefty license fees, while outsourcing to visualization studios can cost thousands per minute of animation. This creates a situation where compelling architectural storytelling becomes a luxury reserved for high-budget projects, leaving smaller firms and independent architects at a disadvantage.
Understanding Our Users

Through research and interviews, we identified five distinct user groups who would benefit from automated architectural visualization. Architecture students represented our most enthusiastic early adopters – they had creative visions but lacked both the budget for professional software and the time to master complex animation tools. Freelance architects formed our core user base, professionals who understood the value of visualization but couldn’t justify the overhead of maintaining expensive software licenses or hiring visualization specialists.
Small firms emerged as a crucial market segment. These practices, typically with 5-15 employees, occupied a challenging middle ground – too small to maintain dedicated visualization teams but too established to ignore client expectations for high-quality presentations. Product designers surprised us as an unexpected user group. They needed to showcase industrial designs, furniture, and consumer products with the same cinematic quality as architectural projects. Finally, movie makers and content creators saw potential in using architectural models as virtual sets, requiring camera movements that told stories rather than just showcased spaces.
The Initial Approach: Model to Raw Video
Our first iteration focused on the fundamental challenge: getting from a static 3D model to moving images. We built a pipeline that accepted FBX models through a web interface, processed them in Blender’s Python API, and generated basic camera movements. The system worked on a simple principle – parse the model’s bounding box, calculate appropriate camera distances, and execute predefined movement patterns.
The technical implementation involved creating a headless Blender instance that could receive commands via Python scripts. Users would upload their models, select from basic movement options (orbit, flythrough, pan), and receive a raw video output. While functional, these initial outputs were utilitarian at best – grey models against stark backgrounds, with mechanical camera movements that lacked the nuance of professional cinematography. But it proved our core concept: we could automate the technical process of animation generation.
Proof of Concept: Integrating AI Rendering
Recognizing the limitations of raw Blender outputs, we experimented with a novel approach: feeding our basic animations into Runway ML’s AI video generation models. This two-step process transformed our mechanical camera movements into visually compelling content. The AI would interpret our grayscale animations and add realistic lighting, materials, and atmospheric effects.
The results were remarkable. A simple box-like building model became a sun-drenched modernist structure with realistic shadows and material textures. Our proof of concept videos showed buildings that looked like they belonged in architectural portfolios, complete with dramatic skies and contextual environments. This hybrid approach – procedural camera work combined with AI enhancement – seemed to offer the best of both worlds: precise control over movement with automatic visual enhancement.
The Blender API Limitation
Our momentum hit a significant technical wall when we attempted to scale the system. To handle multiple users and reduce rendering times, we needed Blender to run in headless mode on cloud servers without GUI overhead. However, testing revealed a critical limitation: Blender’s EEVEE renderer, which we relied on for fast rendering, had incomplete support for headless operation on Windows systems.
The documentation was clear: “GPU memory management is done by the GPU driver. In theory, only the needed textures and meshes (now referred to as ‘resources’) for a single draw call (i.e., one object) needs to fit into GPU memory.” In practice, this meant our renders would either crash or produce the dreaded blue screen – a frame buffer that hadn’t properly initialized without a display context. This wasn’t just a bug to fix; it was a fundamental architectural limitation that required us to completely rethink our approach.
First Real Iteration: The Camera System
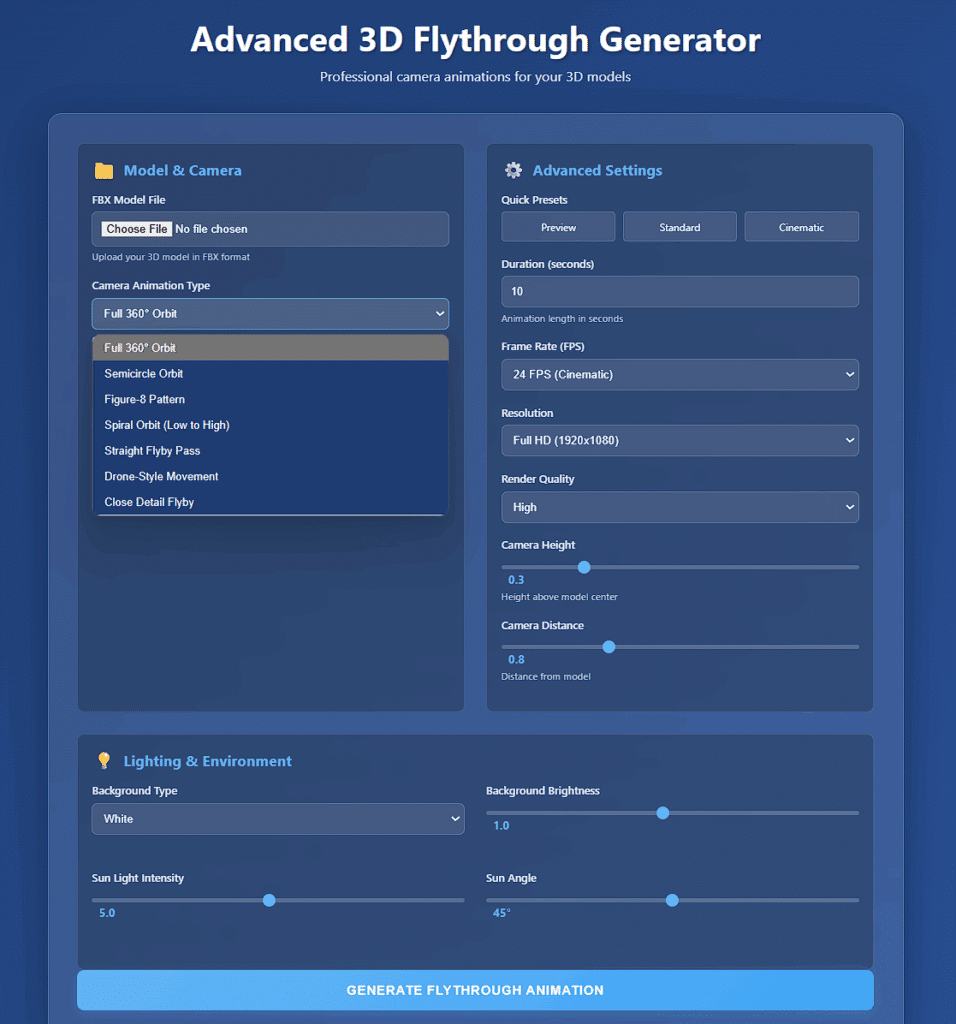
Pivoting from our rendering challenges, we refocused on what we could control: sophisticated camera movement generation. We developed a comprehensive camera system that offered eight distinct movement types: orbit, straight flyby, dolly zoom, close detail, semicircle, figure-8, spiral, and sunrise arc. Each movement type was mathematically defined to ensure smooth, professional-looking motion paths.
The interface evolved into a more sophisticated control panel. Users could select camera types from a dropdown menu showing options like “Full 360° Orbit,” “Semicircle Orbit,” or “Figure-8 Pattern.” We added granular controls for animation duration, frame rate, resolution, and render quality. The system also introduced camera physics – ease-in and ease-out calculations that made movements feel natural rather than mechanical. This iteration proved that even without AI enhancement, we could generate cinematography that matched professional standards.
The Prompt Engine Revolution
The next breakthrough came from reimagining the user interface entirely. Instead of forcing users to understand camera terminology and movement types, we built a natural language prompt engine. Users could now type commands like “orbit around the building” or “dramatic sunrise reveal” and our system would interpret these into appropriate camera movements and settings.
Building this required extensive pattern matching and keyword analysis. We collected 5,000 animation descriptions and manually tagged them with corresponding camera movements, speeds, and angles. Our regex patterns could identify intent from phrases like “fly through” (straight camera), “spin around” (orbit), or “zoom into details” (dolly + close-up). The system achieved 87% accuracy in matching user intent to appropriate camera movements, though compound requests like “orbit while zooming” remained challenging.
Advanced Generation: Eight Angles, Custom Backgrounds
Our most polished iteration delivered professional results in just 46 seconds. The system could generate eight different camera angles of any uploaded model, each with customizable backgrounds ranging from pure white to gradient skies. The grid output allowed users to quickly compare different perspectives and choose the most compelling views for their presentations.
This version represented the culmination of our technical learning. We had optimized render settings for speed without sacrificing quality, implemented intelligent camera positioning based on model dimensions, and created a one-click solution for generating multiple marketing-ready visualizations. Architecture students could create portfolio pieces, freelancers could impress clients, and small firms could compete with larger studios – all without learning complex software.
The Market Disruption
Just as we reached thr finals, the landscape shifted dramatically. Google announced Veo, their AI video generation model. Midjourney teased video capabilities. Runway ML released Gen-3 with architectural visualization examples. Suddenly, our carefully crafted pipeline faced competition from billion-dollar AI companies who could generate entire videos from text prompts alone.
This moment forced a critical reflection. While our technical approach was sound, the market was moving faster than we could develop. The major players weren’t just automating camera movements – they were generating entire photorealistic videos from scratch. Our advantage in precise camera control seemed less relevant when users could simply prompt “architectural flythrough of modern building at sunset” and receive Hollywood-quality results.
Pivot to Procedural Generation
Rather than compete directly with generative AI, we identified an underserved niche: procedural environment generation for architectural contexts. We began developing systems that could automatically create appropriate surroundings for architectural models – urban contexts with streets and buildings, natural landscapes with vegetation, or abstract geometric environments for conceptual presentations.
Our procedural generation system worked by analyzing the uploaded model’s characteristics (size, style, purpose) and generating complementary environments. A modernist house would receive a minimalist landscape with carefully placed trees. An office building would be situated in an urban context with surrounding structures and streets. This approach provided value that pure AI generation couldn’t match – contextually appropriate environments that respected architectural principles and spatial relationships. But the results were completely underwhelming for the first trials and needs a lot more work to gain accuracy.
Scope and Limitations
Our current system successfully delivers on several key promises. Users can control animations through natural language, choosing from eight sophisticated camera movement types. Five distinct environment presets provide appropriate contexts for different architectural styles. Real-time preview generation allows for rapid iteration, and exports support standard formats for integration into existing workflows. Most importantly, we’ve succeeded in our core mission: saving animator sanity by automating tedious technical tasks.
However, we’ve consciously limited our scope to maintain focus and quality. Character animation remains outside our domain – architectural visualization has different requirements than character performance. We don’t attempt photorealistic rendering comparable to dedicated ray-tracing engines. Time travel (scrubbing through animations in real-time) remains a future feature. And despite consuming vast quantities of coffee during development, we haven’t automated that process… yet.
Methodology
Our development methodology embraced rapid prototyping and constant user feedback. Each iteration began with user interviews to understand pain points, followed by technical experiments to validate solutions. We adopted a fail-fast approach, quickly testing ideas like the Runway ML integration before committing to full implementation.
The technical stack evolved through necessity. Python and Blender’s API provided the foundation for 3D manipulation. FastAPI handled web services for file uploads and job queuing. For the prompt engine, we combined regex pattern matching with statistical analysis of user inputs. The procedural generation system leveraged noise functions and rule-based placement algorithms to create believable environments. Throughout development, we prioritized speed and reliability over cutting-edge features – a 46-second generation time with 95% success rate was more valuable than 5-minute renders with frequent failures.
The Future
We envision a hybrid system where traditional 3D control meets intelligent generation. Users could upload rough massing models and receive fully detailed architectural visualizations. Natural language prompts would control not just camera movements but lighting moods, material selections, and environmental conditions.
Machine learning could analyze successful architectural videos to understand cinematographic conventions – learning that residential projects benefit from warm, welcoming movements while commercial projects require dynamic, energetic cameras. The system could suggest optimal viewing angles based on architectural style, automatically identify key design features to highlight, and even generate narrative structures for longer presentations.
Most ambitiously, we see potential for AI-assisted storytelling where the system doesn’t just move cameras but crafts emotional journeys through spaces. A prompt like “show how this hospital design promotes healing” would generate a sequence highlighting natural light, green spaces, and human-scale details – understanding the architectural intent and translating it into visual narrative.
Conclusion
This project began as an attempt to democratize architectural visualization and evolved into a deeper exploration of how AI and automation can enhance creative workflows. While market forces led us to pivot from our original vision, each iteration taught valuable lessons about the intersection of technology and design communication.
The journey from manual walkthroughs to AI-powered generation represents more than technical progress – it’s a fundamental shift in how architectural ideas can be shared and understood. As we continue developing procedural generation systems and exploring AI integration, our core mission remains unchanged: making professional architectural visualization accessible to everyone with a design to share.
The future of architectural visualization won’t be about choosing between human creativity and AI efficiency. Instead, it will emerge from the thoughtful combination of both – where technology handles the technical complexity and humans focus on the story they want to tell. Our project, in its various iterations, has been a small step toward that future.
