
We embarked on a fascinating journey through the latest advancements in Image Synthesis and Language Models within the Architecture, Engineering, and Construction (AEC) industry. The course highlighted the transformative potential of generative AI, enabling architects, engineers, and designers to push the boundaries of traditional design processes, streamline workflows, and tackle complex challenges in groundbreaking ways.
Why do we need a LLM model for Building Codes?
It can dramatically improve the efficiency, accuracy, and accessibility of regulatory information in the construction and architecture sectors. Building codes are often intricate and vary significantly across regions, making it challenging for professionals to stay updated and ensure compliance. An LLM can quickly interpret and apply relevant codes, providing instant guidance and reducing the risk of errors.
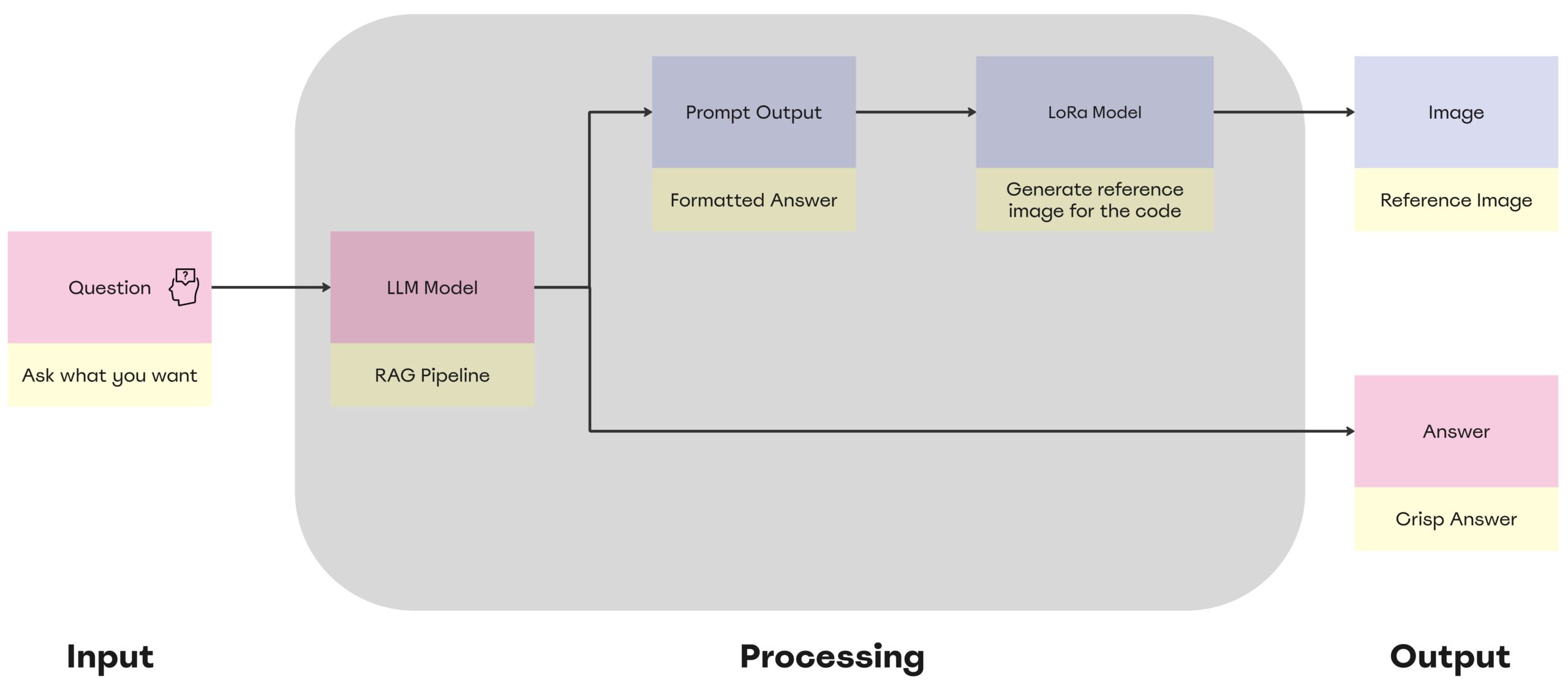
How does this model work?
Stage 01
Where we work with a RAG LLM to easily get the needed codes as we chat with the model, asking it specific technical questions and the model will answer according to the knowledge pool of building code information that we provided.
Stage 02
Where we get the option from our LLM to give us a prompt related to the question that we had and then input this prompt in our LoRA model that was trained on selected images that will provide the user with the visualization needed to clarify the idea.
Data Collection
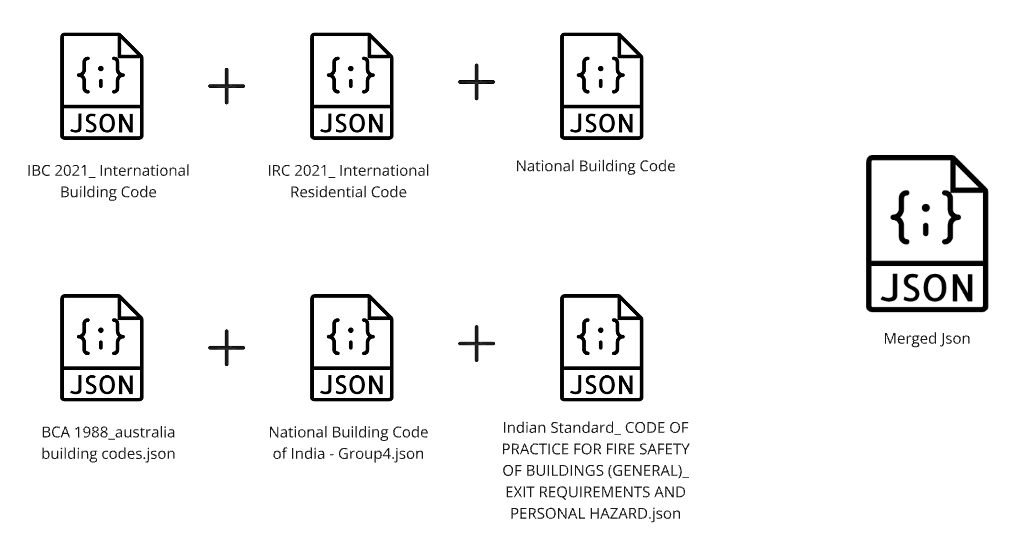
To start collecting the data for our project, we focused on 4 regions around the world, where we extracted the chapter that focuses more on Circulation and safety. We selected these regions based on their diverse architectural practices and regulations. This approach ensures a comprehensive understanding of the variations in vertical circulation design across different cultural and regulatory contexts.

PDF to .txt
To convert the data from the PDF format to the .txt format, we use Llama Prase where # symbol gets added before any bold letter, which helps create distinct chunks of information. Here’s a detailed explanation of how this conversion is done:

But with tabular data, we need to do further formatting as the data converted to a .txt file doesn’t make sense as a sentence. In the below image, you can see that the data is further formatted so each sentence in the .txt file makes sense

.txt to .json
Once we get the .txt file we start creating the chunks and their vectors based on the following strategies determined by the data in the file. This is done with the help of the embedding model “nomic-ai/nomic-embed-text-v1.5-GGUF” which converts .txt files to JSON files i.e. the vector format.
The following strategies are:
- We utilize ‘#’ as a reference point for creating these chunks.
- To accommodate datasets from different regions, we prepend each chunk with a reference “As per —- Standard” at the start indicating its origin.
- If in the .txt file new chunks start with the next paragraph then splitting into paragraphs becomes our strategy

Once we get all the JSON files we merge them so that we can use them as a base dataset for our RAG Pipeline
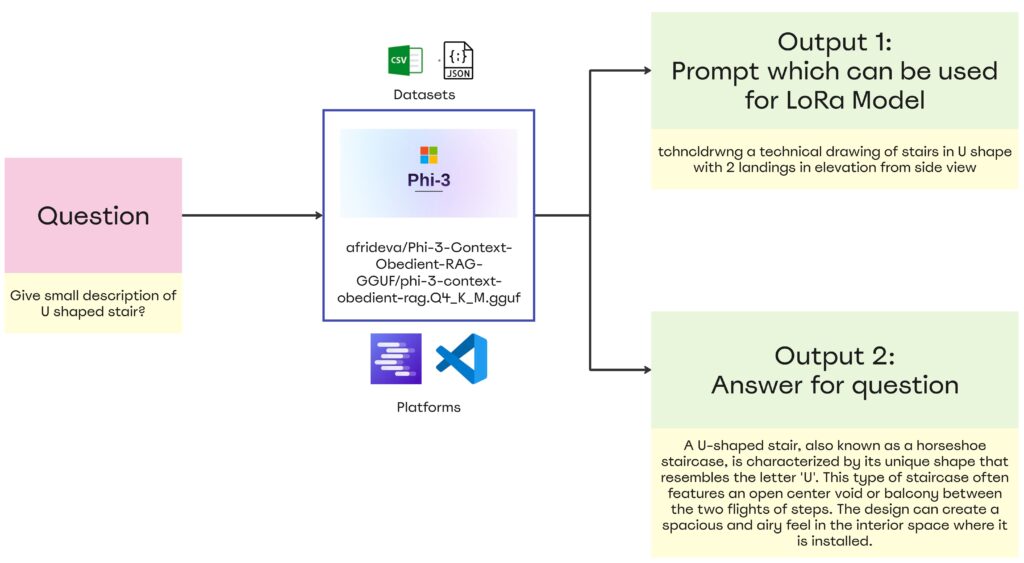
RAG Model
We connected with LM Studio and tried to analyze with different models where we noticed that the model selected Phi 3 worked best for our case

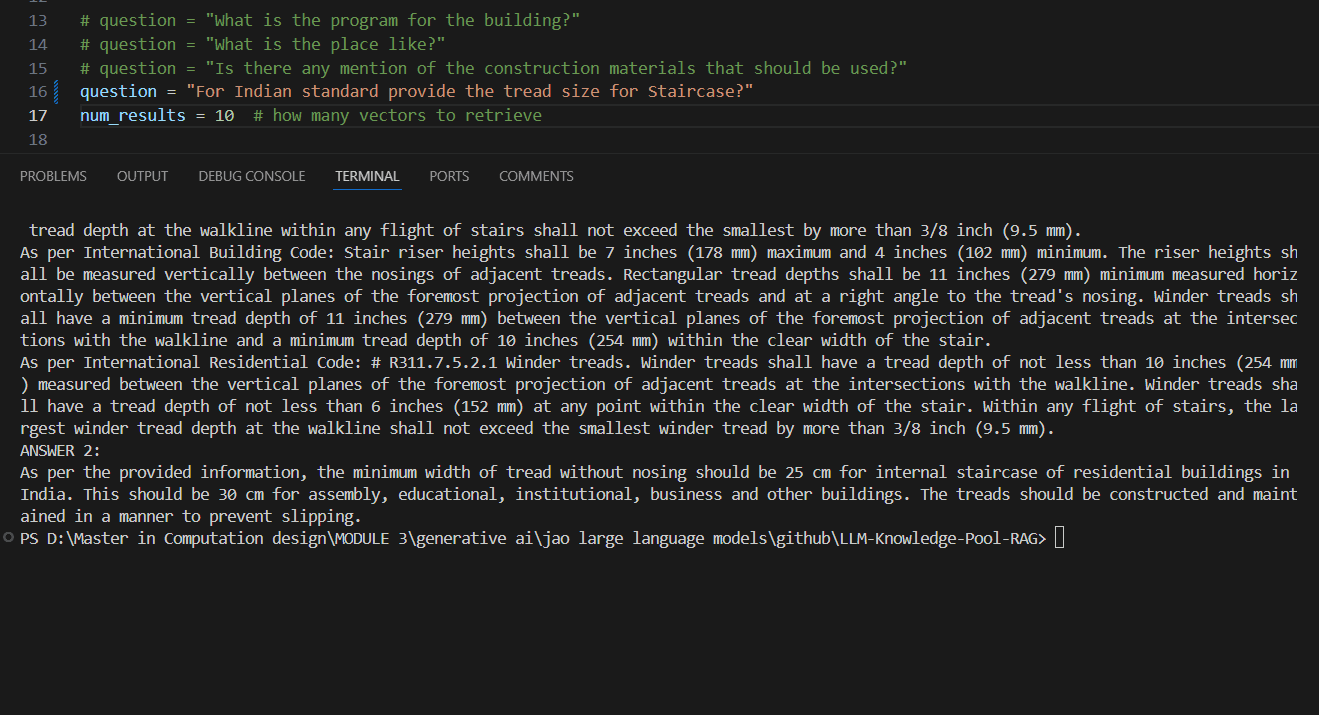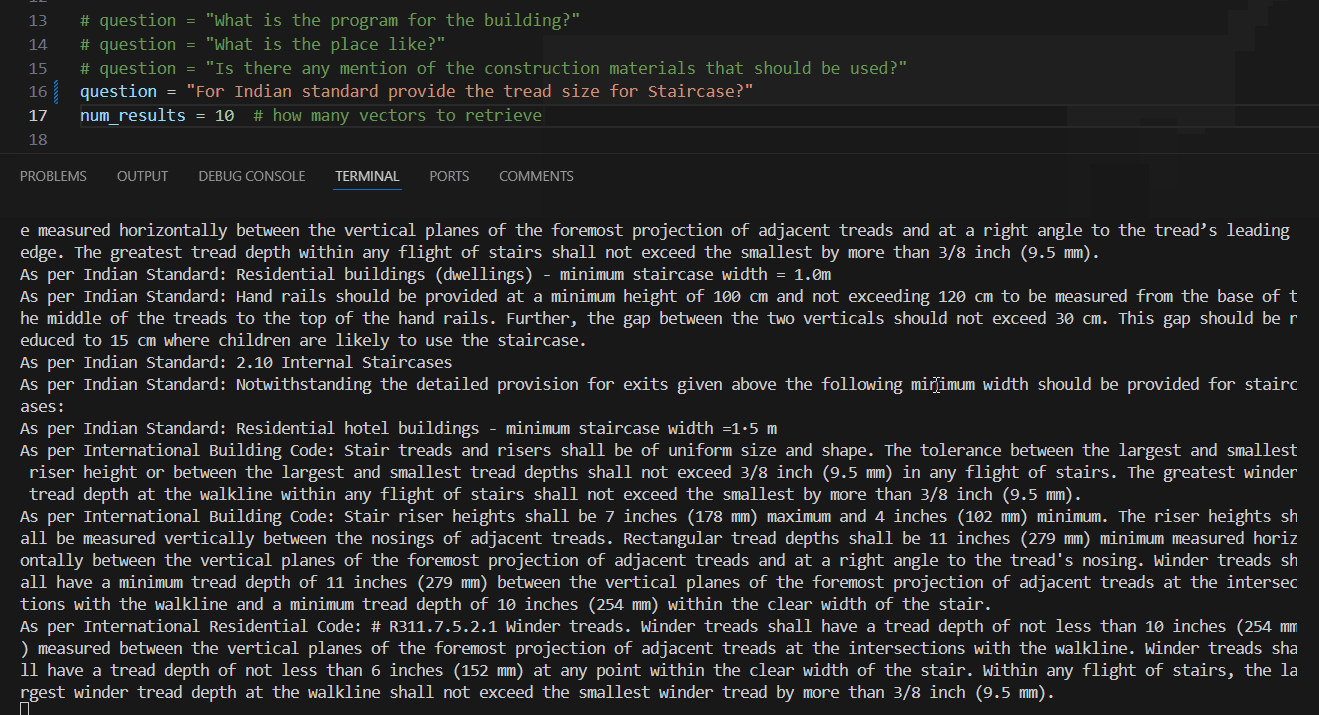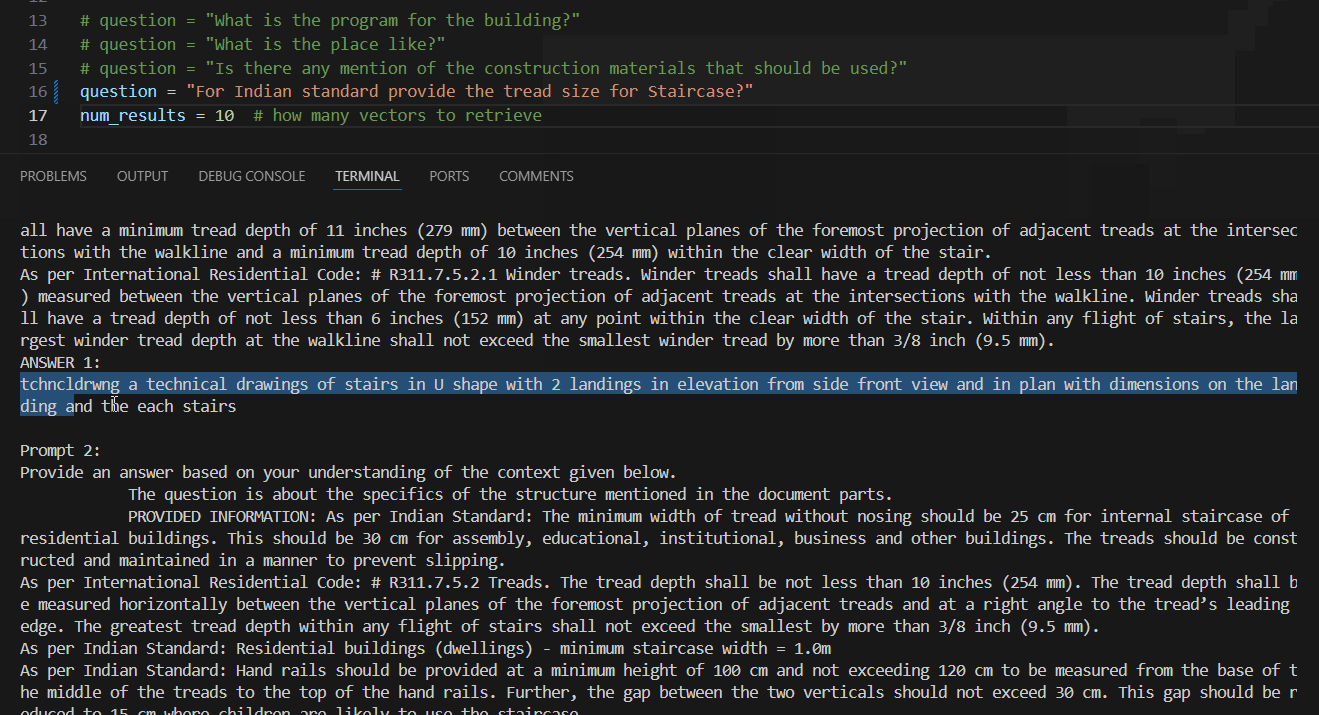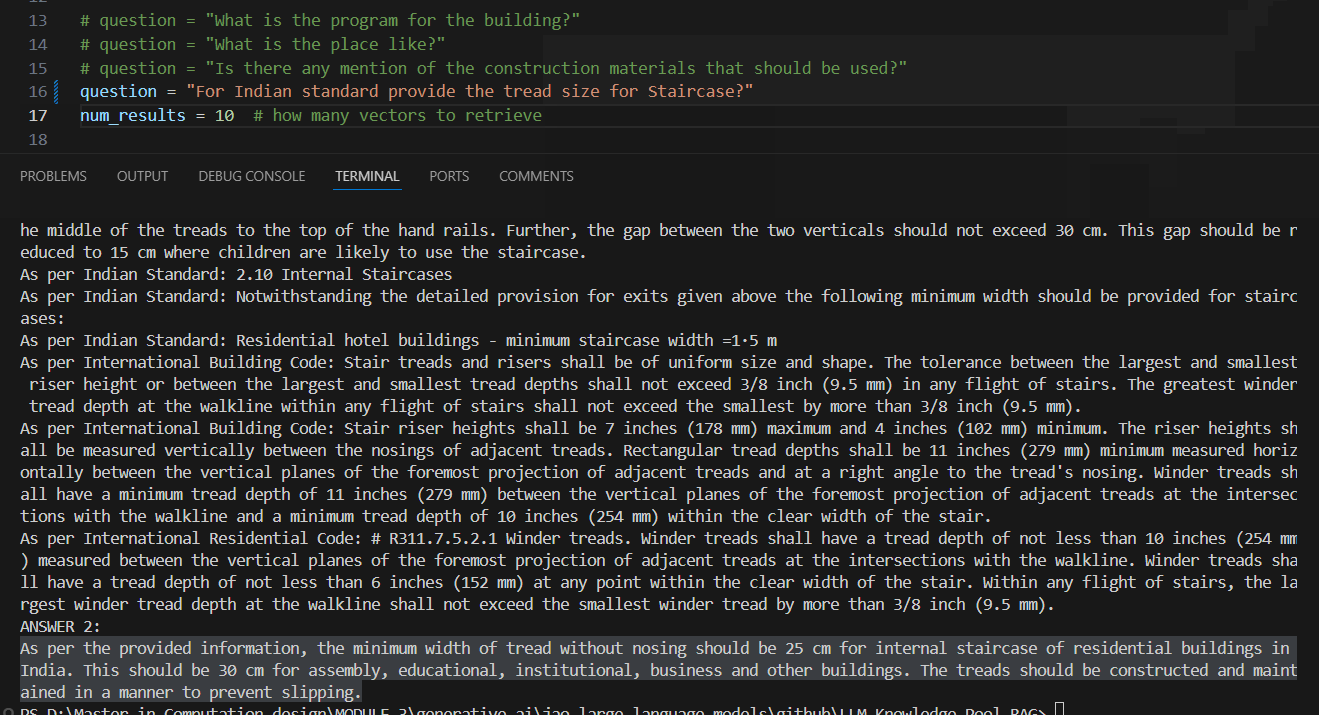
Once the RAG pipeline setup is complete, we initiate the process by posing questions. The model retrieves answers from our combined JSON file, which is configured to provide two types of outputs.
- Output 1 utilizes sentence structures from the CSV tailored for the LoRA prompt.
- Output 2 offers a more generalized response to the query, generated by the LLM model.
This setup ensures that whether we ask specific or broad questions, both outputs deliver precise answers. After completing its responses, the system exports the prompt answers into a CSV file for future use.
LoRA model: Technical Drawing
To build our LoRA model, we started by web scraping images of technical drawings. We discovered that dimensions.com offers a comprehensive dataset of technical drawings for various architectural elements, including stairs, elevators, bedroom layouts, facades, and more. To collect these images, we created a script in google colab that enabled us to efficiently scrape images from the site. After gathering the images, we processed them to ensure they were all in .jpg format, ensuring consistency for our model.
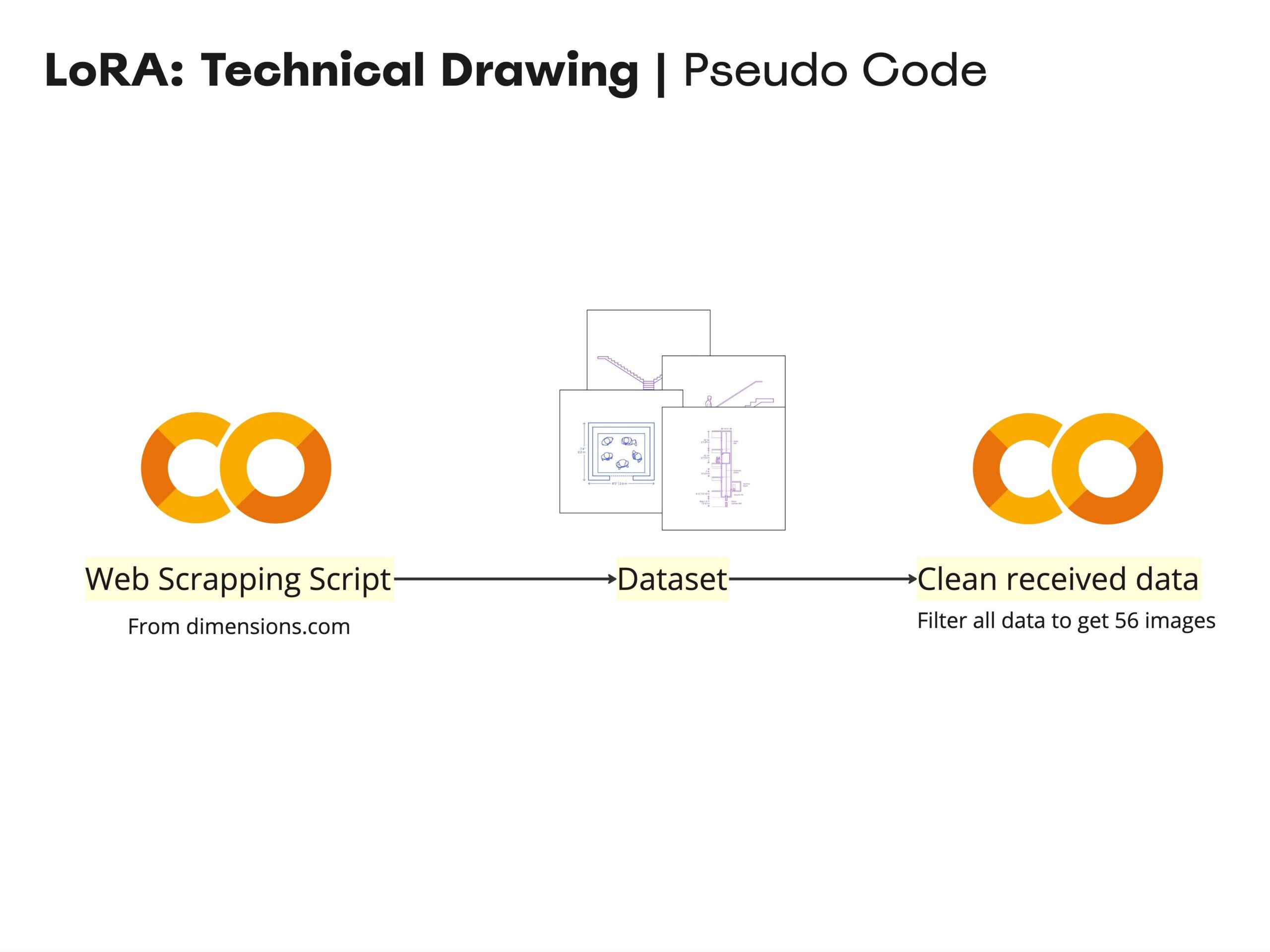
Once we had web scraped and cleaned the downloaded images, we began setting up the training elements for the LoRA model:
1. A dataset of technical images.
2. A .txt file containing a description prompt for each image.


Captions Anatomy
The anatomy for the captions is composed of tchncldrwng then a technical drawing of followed by the description of the image, and then for the ending we first trained a LoRA with over a white background but beceause the resutls wasnt good we changed it to isolated on a white background and we got better results.


Based on this anatomy we created a caption for each image.

Model training
We then conducted multiple test runs to identify and resolve any potential issues. Finally, we trained the model for 8000 steps, carefully balancing and adjusting the number of images in our dataset. To improve the model’s performance, we added a variety of additional images and included a plain white image to encourage the model to generate images with a predominantly white background.
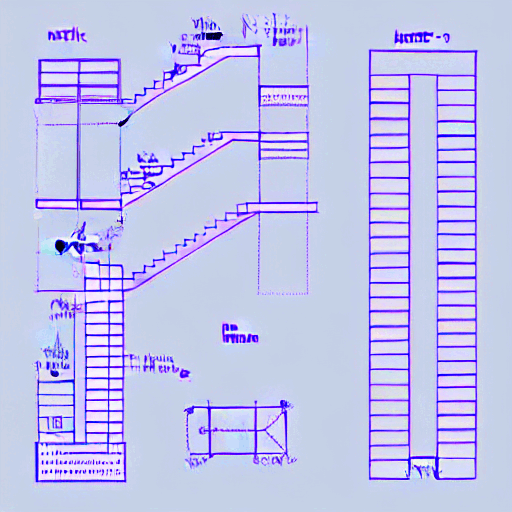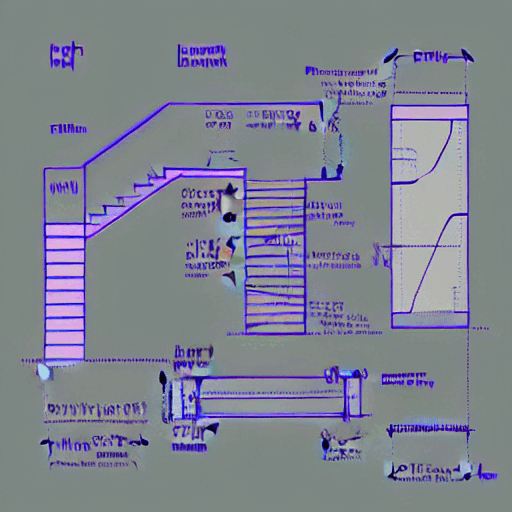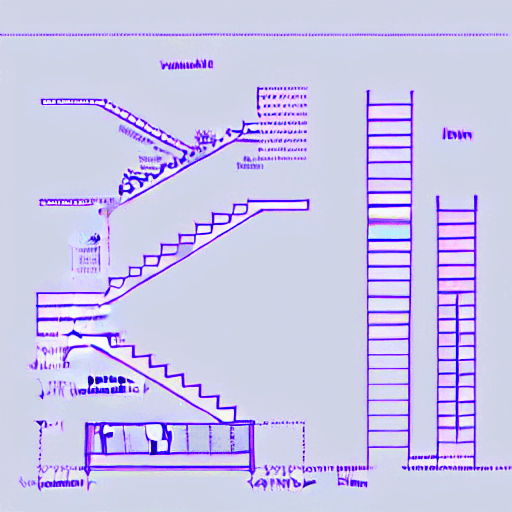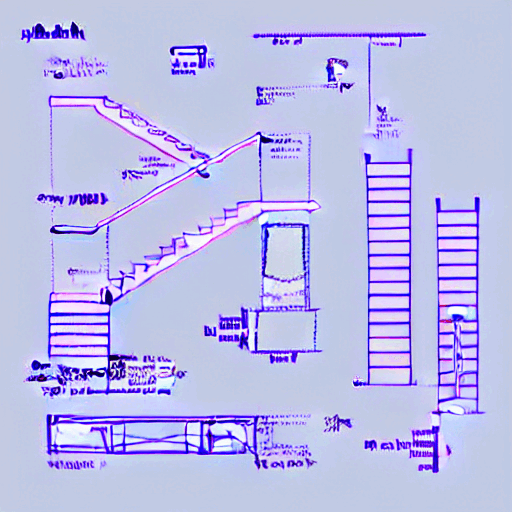
Steps: 10600
Dataset: 56 images
Validation_prompt
“tchncldrwng a technical drawing of an stair with a handrail and detailed dimensions over a white background“
Steps: 8000
Dataset: 57 images, 1 image is WHITE
Validation_prompt
“”tchncldrwng a technical drawing of a stairway of at least 36 inches (914 mm) wide above the handrail height and below the headroom height, stairways must have a headroom of at least 6 feet 8 inches (2032 mm), isolated on a white background.”
Once our LoRA was trained we conducted some tests with different seeds, strenghst and checkpoints.


Between the two checkpoints (6000 and 8000 steps), we observed that the 6000-step checkpoint produced more images with white backgrounds. Based on this observation, we decided to test our LoRA model again using the 6000-step checkpoint with three different prompts.

User Interface
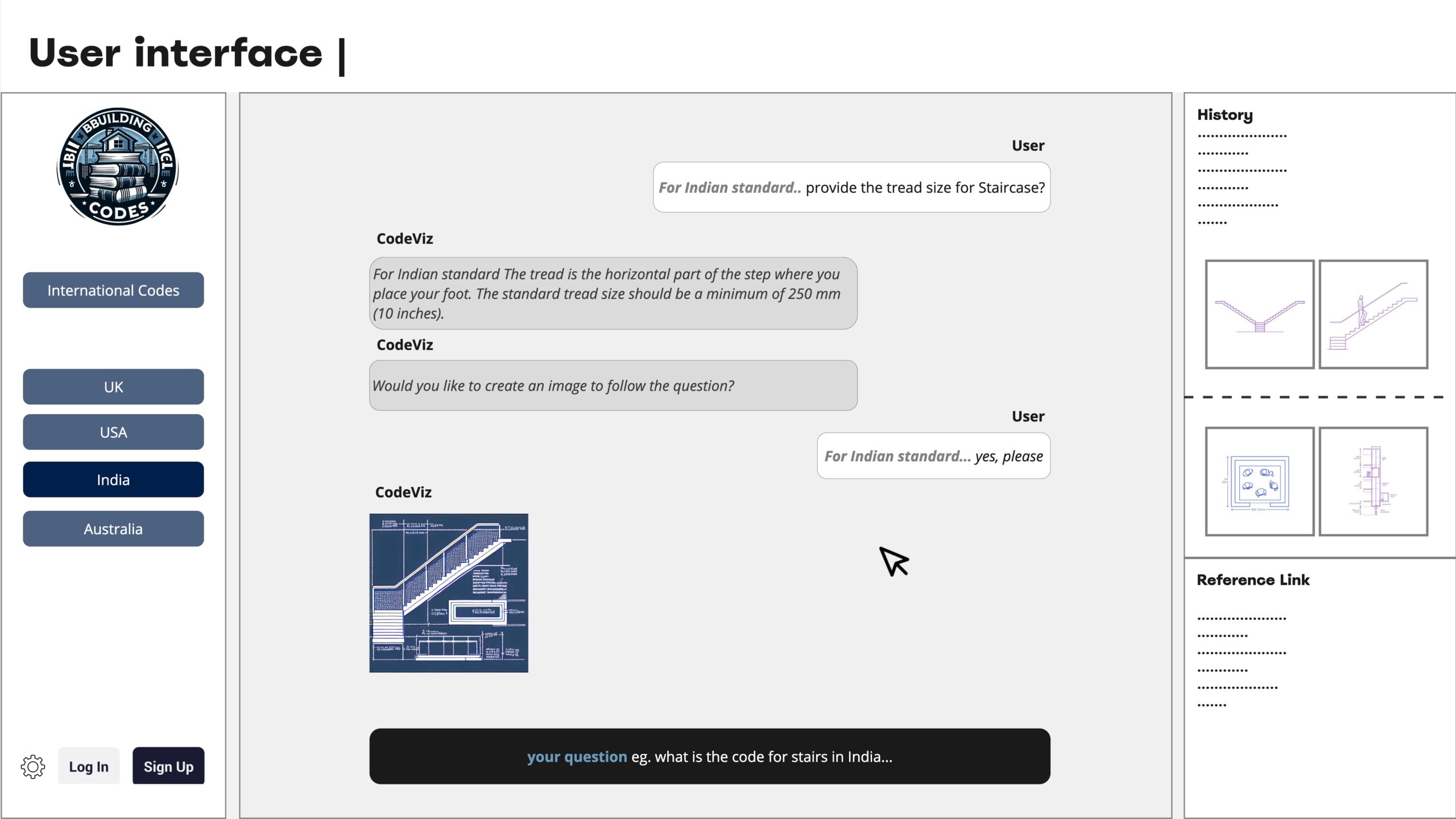
Finally, here is an overview of a possible UI after deployment. Users will be able to specify the location needed for the code and ask their questions. Additionally, they will have the option to visualize the generated images related to the provided answers.
