
A Multi-Agent, Socratic, Cognitive-Preserving Tutoring System for Architectural Education
The Silent Crisis
Picture this: A design student faces a challenging architectural problem. They need to create a sustainable community center that harmonizes with its urban context while meeting complex programmatic requirements. In 2023, they would likely turn to ChatGPT, type their question, and receive a comprehensive answer within seconds. Problem solved? Not quite. Problem created.
Recent research from the University of Pennsylvania revealed a startling reality: 52% of students given unrestricted AI access exhibit cognitive offloading behaviors – essentially outsourcing their thinking to artificial intelligence. It’s the educational equivalent of using a calculator for 2+2, except the stakes are our collective cognitive future.
This isn’t just about cheating or academic integrity. We’re facing something far more profound: the systematic erosion of human thinking capabilities in the age of AI. When students habitually rely on AI for answers, they lose the ability to think independently, solve problems creatively, and develop the cognitive resilience necessary for navigating an uncertain future.
Enter Mentor: The AI That Makes You Think Harder
This crisis inspired the development of the Mentor system – a revolutionary multi-agent AI tutoring platform that flips the traditional AI assistance model on its head. Instead of providing answers, Mentor guides students to discover solutions themselves. Instead of making learning easier, it makes learning more thoughtful. Instead of replacing human cognition, it enhances it.
Developed as part of a Master’s thesis project at the Master of Advanced Computation in Architecture and Design (MaCAD) program, Mentor represents a fundamental paradigm shift in educational AI. The system achieved remarkable results: an 84.7% cognitive offloading prevention rate and 73.9% deep thinking engagement – compared to just 29.8% with ChatGPT.
But how does an AI system make students think more, not less?
Abstract
The widespread adoption of large language models and design automation tools in architectural education risks promoting cognitive offloading — the delegation of reasoning to external systems. We introduce MENTOR (Multi-agent Educational Guidance for Architecture), a domain-grounded, multi-agent tutoring system that operationalizes Socratic scaffolding, real-time cognitive state monitoring, and automated linkography to prevent offloading while promoting deep engagement and transferable design reasoning. MENTOR’s five specialized agents are orchestrated by LangGraph workflows and connected to a curated Retrieval-Augmented Generation (RAG) knowledge base. A controlled three-arm study (MENTOR vs Generic AI vs Control, N≈135) using a 65-minute Community Center design challenge produced large, robust effects: 84.7% cognitive offloading prevention (COP), 73.9% deep thinking engagement (DTE), 65% higher linkography link density, and strong anthropomorphism prevention (ADS ≈ 15.6%). We detail system architecture, the eleven pedagogical routing patterns, phase-detection and phase-protection math, fuzzy linkography, benchmarking pipeline, ML analyses and statistical models.
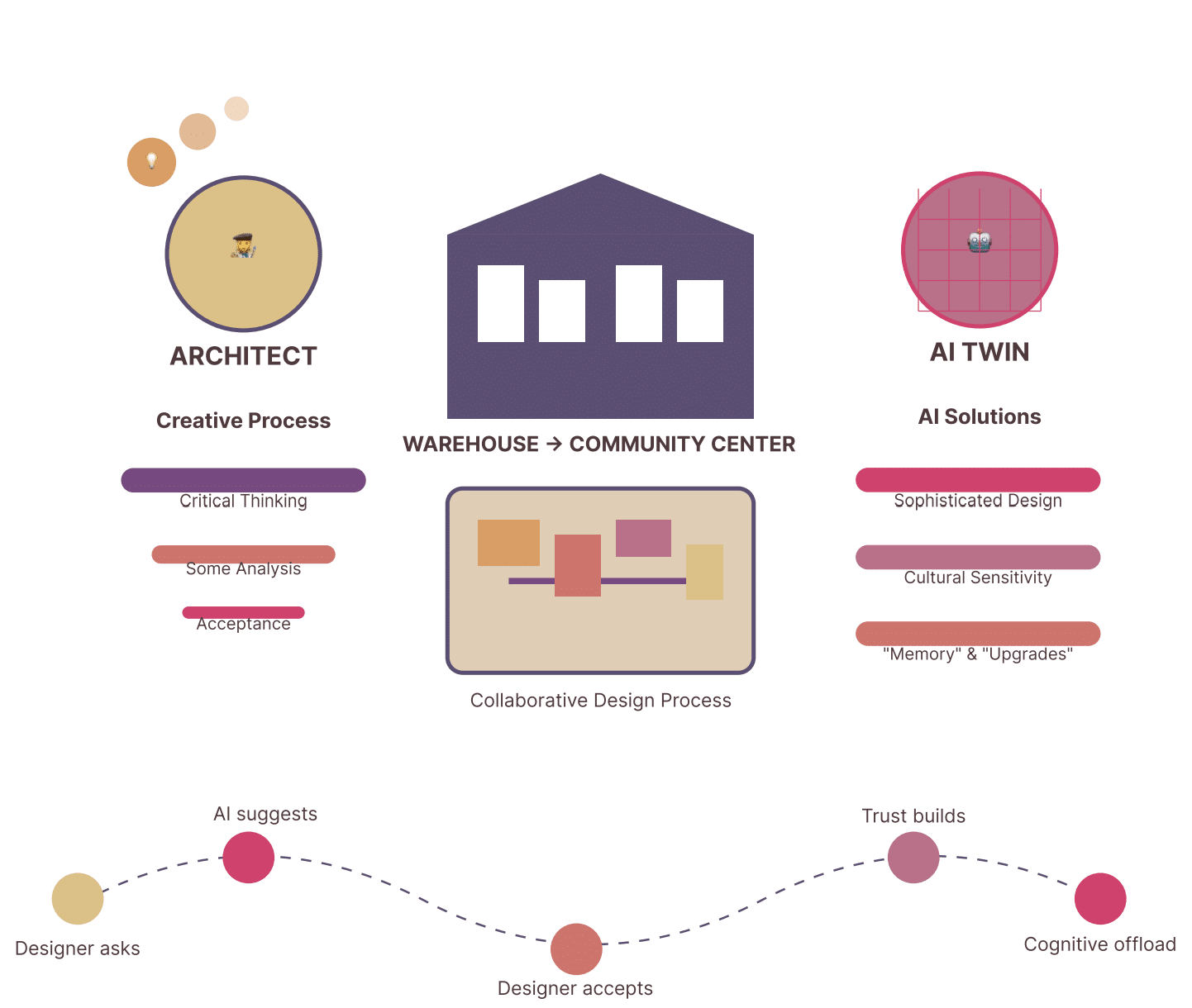
1. Introduction & Motivation
The last five years have seen a radical incorporation of AI tools into design education — generative models, code-driven parametrics and LLMs that answer technical and conceptual questions. While these tools accelerate production, evidence now indicates measurable cognitive shifts when students rely on AI as an answer provider. Neurological and behavioral studies point to reductions in creative-network activity and diminished independent reasoning when AI is used without pedagogical safeguards. This project asks: Can we design an AI that actively preserves and enhances thinking?
MENTOR answers affirmatively. Its architecture and pedagogy focus on process over product, privileging guided discovery, progressive challenge, and continuous measurement of cognitive state. The thesis formalizes eleven cognitive metrics, routes that operationalize theory into behavior, and an empirical pipeline that validates the claims with rigorous statistics and machine learning.
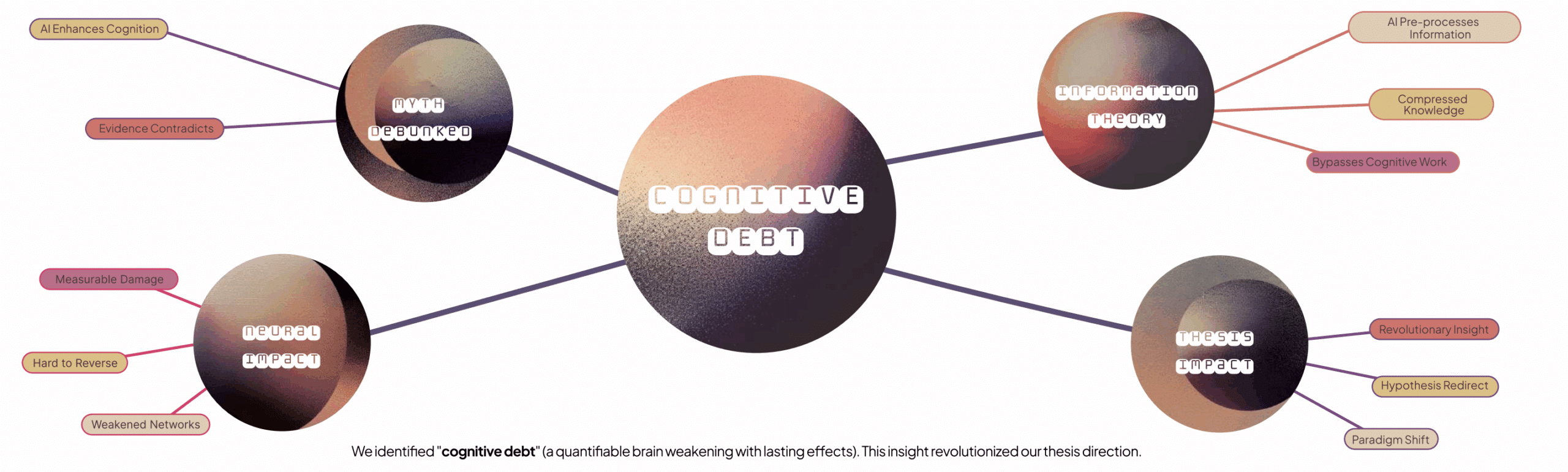
2. Theoretical foundations
MENTOR is grounded in four interlocking theoretical strands:
- Socratic pedagogy — using questions to stimulate reflection rather than supplying solutions; operationalized by the Socratic Tutor Agent.
- Vygotsky’s Zone of Proximal Development (ZPD) and scaffolding — adaptive support that fades with competence; implemented via phase detection and adaptive
- Cognitive Load Theory — dynamic management of intrinsic/extraneous load through question complexity modulation and progressive disclosure in the Domain Expert Agent.
- Linkography (Goldschmidt) — process-focused mapping of design moves and their interconnections; central to the Analysis Agent and to outcome assessment.
These theories were translated into concrete metrics (11 scientific metrics — COP, DTE, SE, KI, MA, CAI, ADS, NES, PBI, BRS, LP), routing rules, and algorithmic checks that let the system act as a cognitive scaffold rather than an oracle.
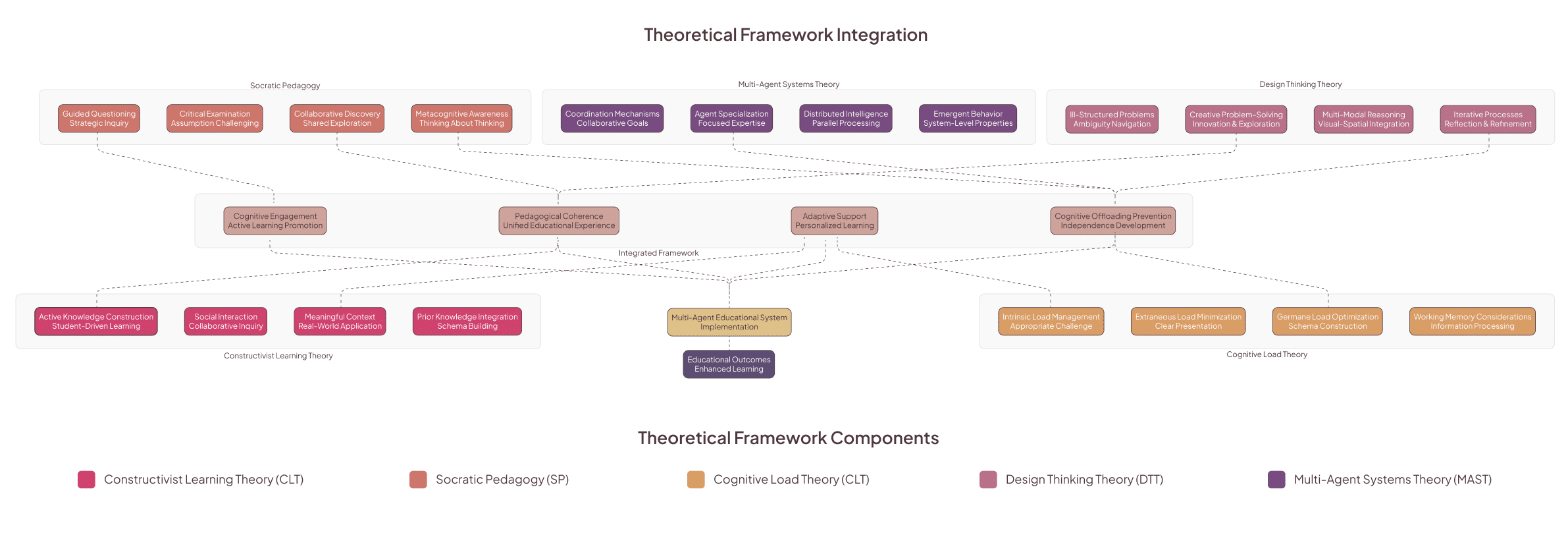
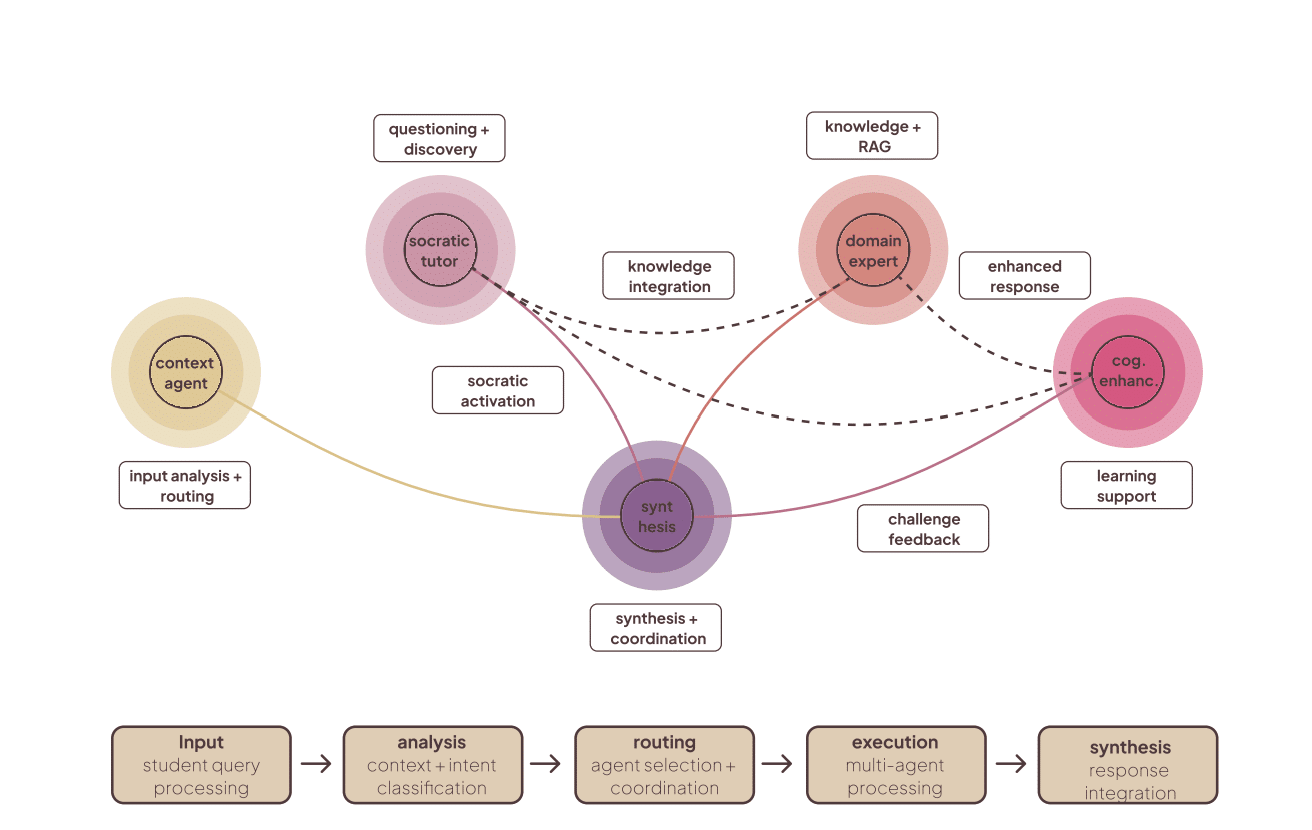
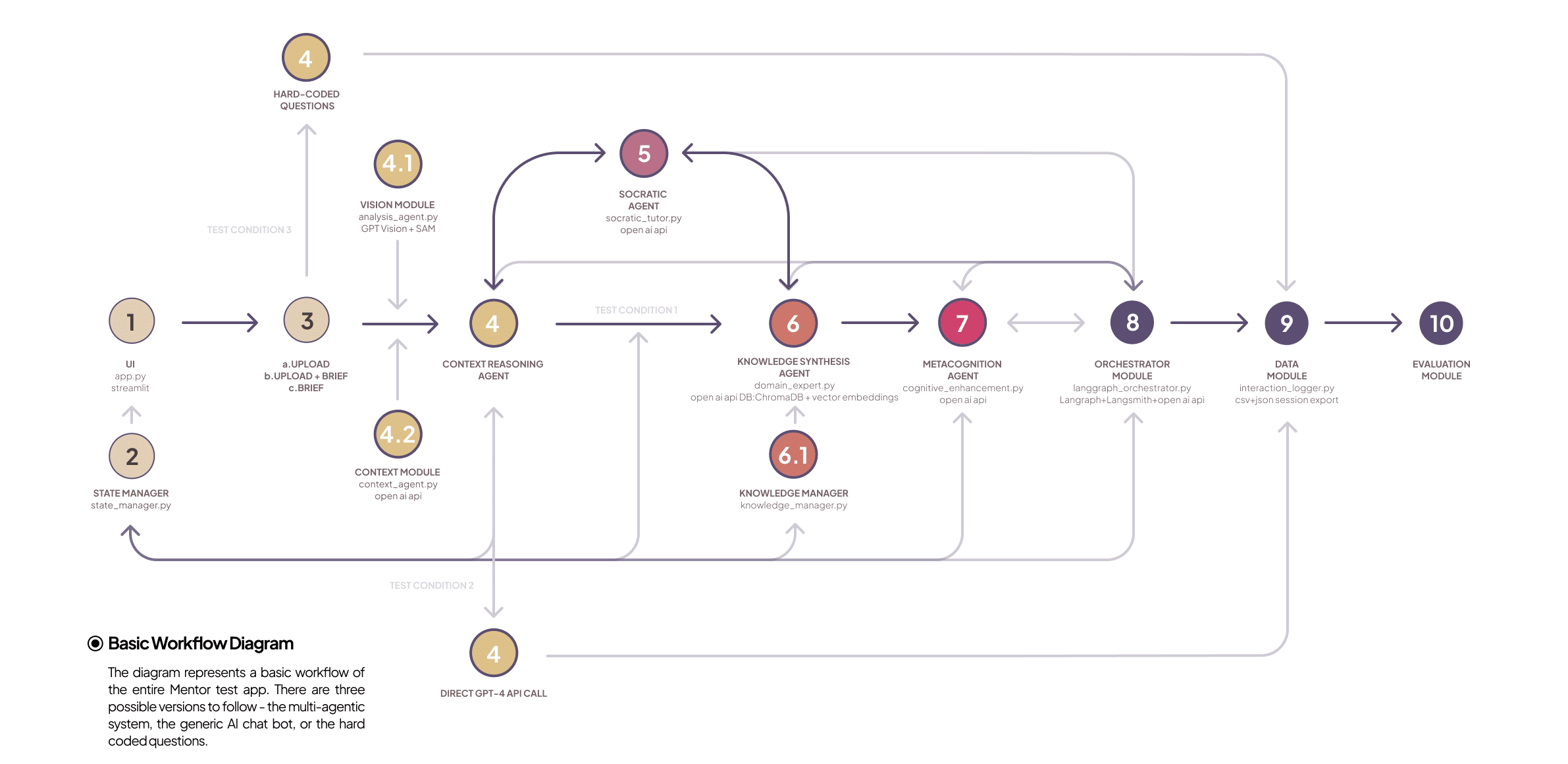
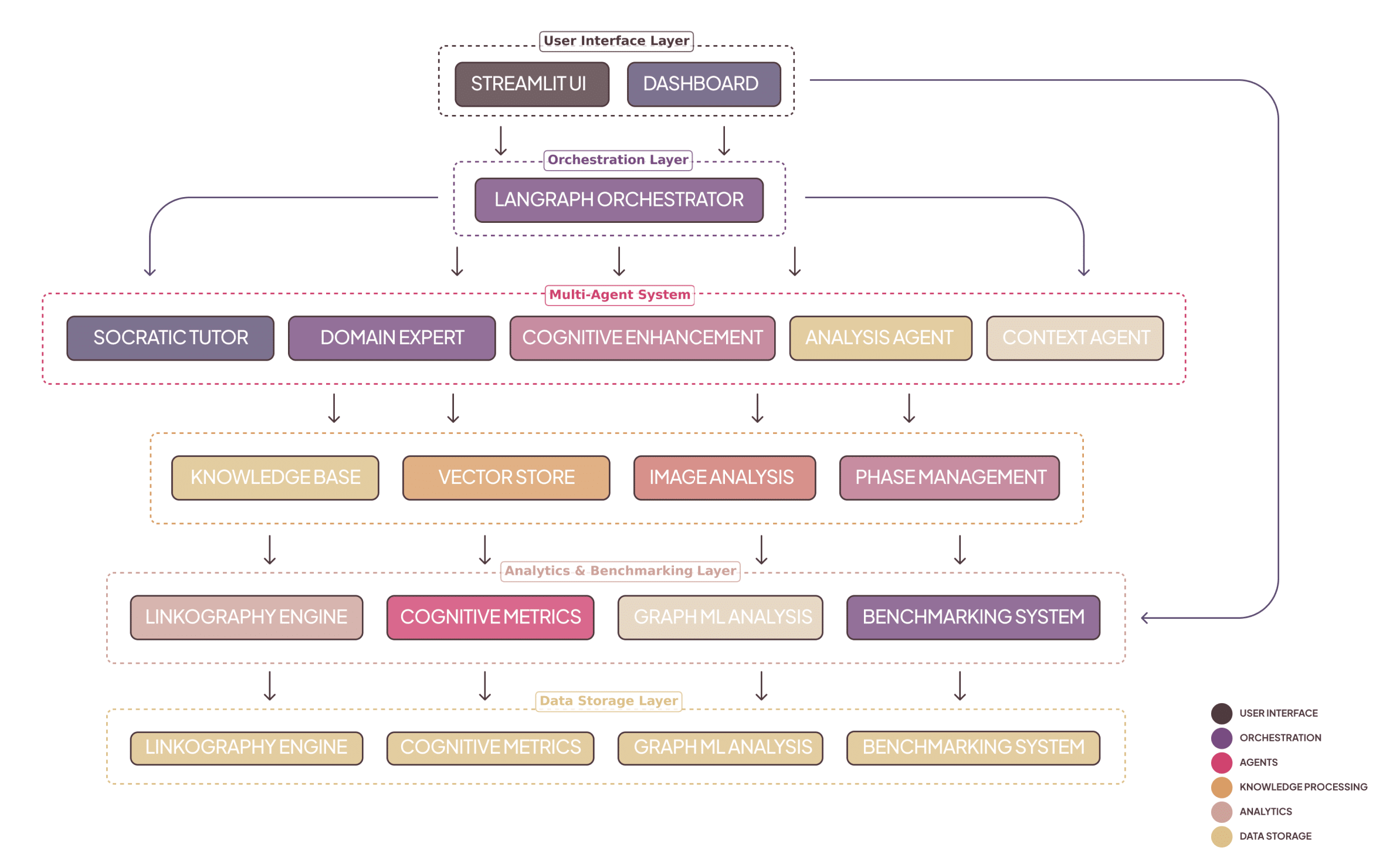
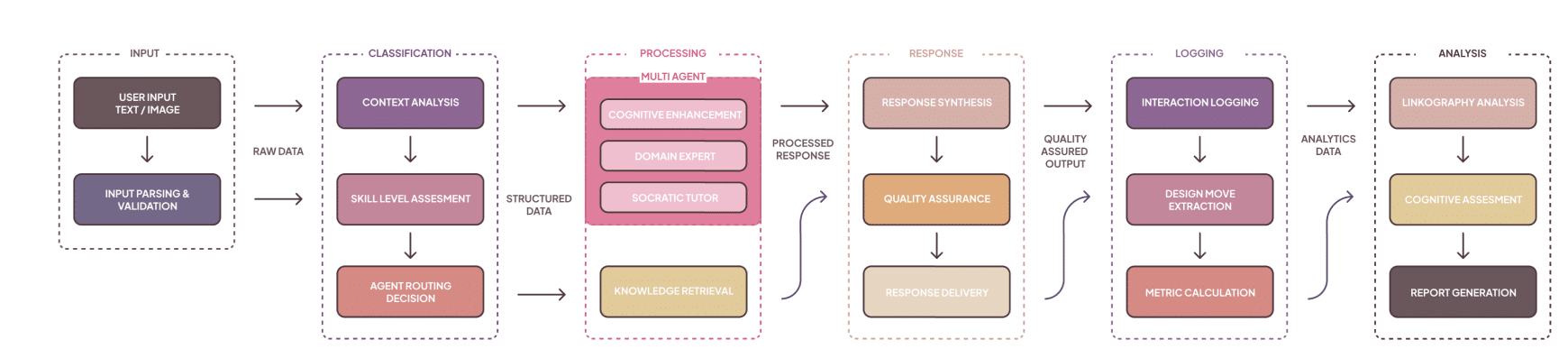
3. System overview and six-layer architecture
3.1 High-level layers
MENTOR employs a six-layer architecture that separates concerns (student UI, LangGraph orchestration + state, multi-agent set, supporting systems — knowledge/vision/phase, storage & analytics, external integrations like GPT-4V). This modularity enables focused agent specialization and robust state tracking.
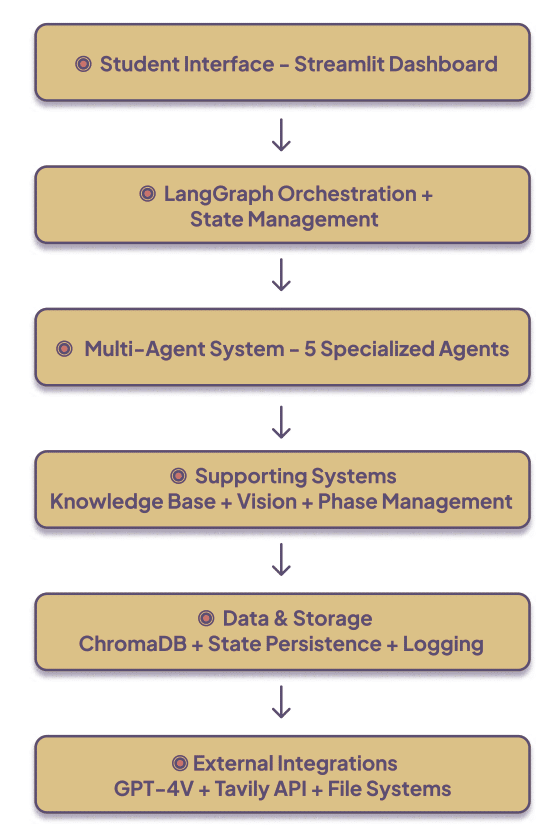
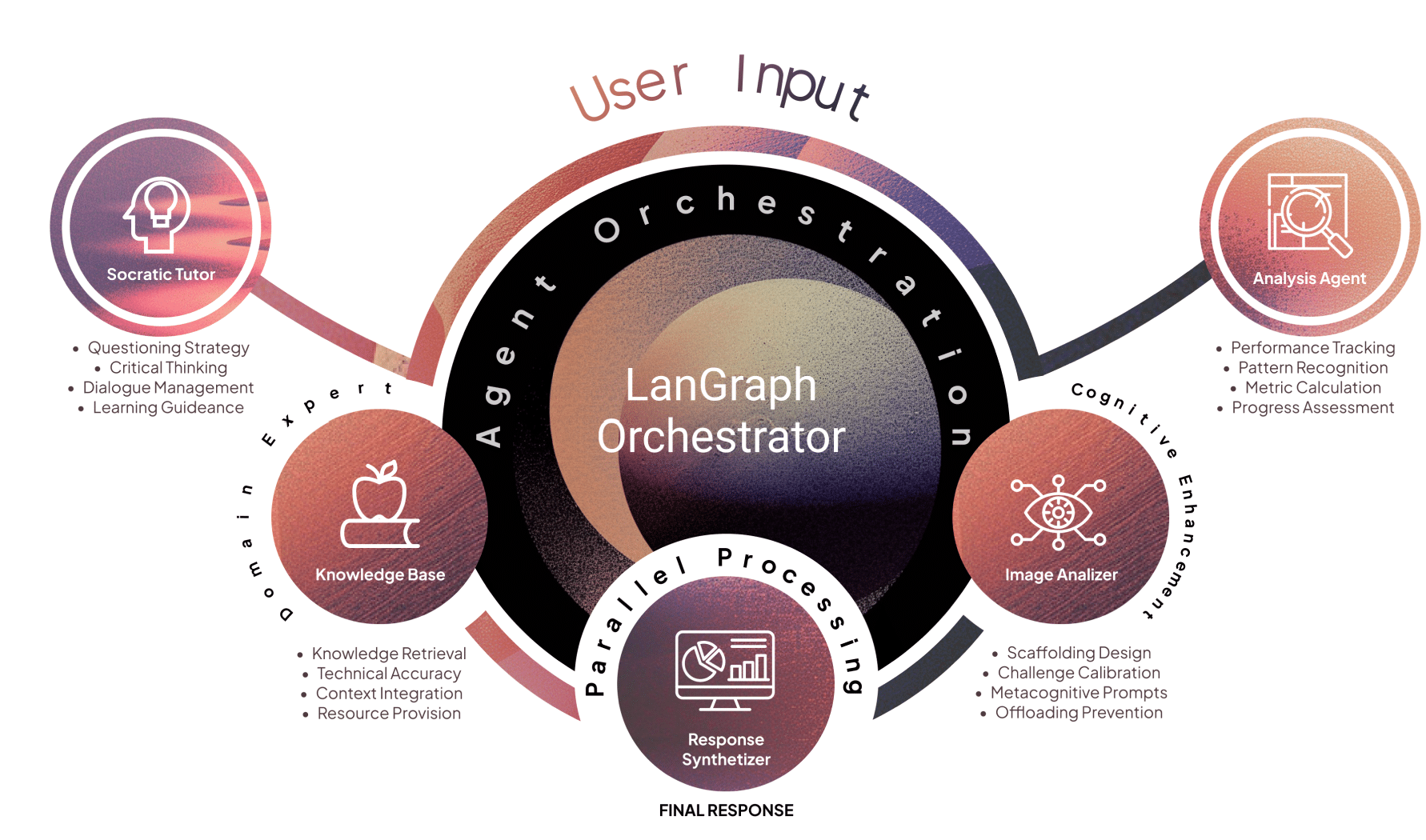
3.2 Agent set: five specialized agents
MENTOR’s pedagogy emerges from distributed specialization. Each agent embodies pedagogical values and computational responsibilities:
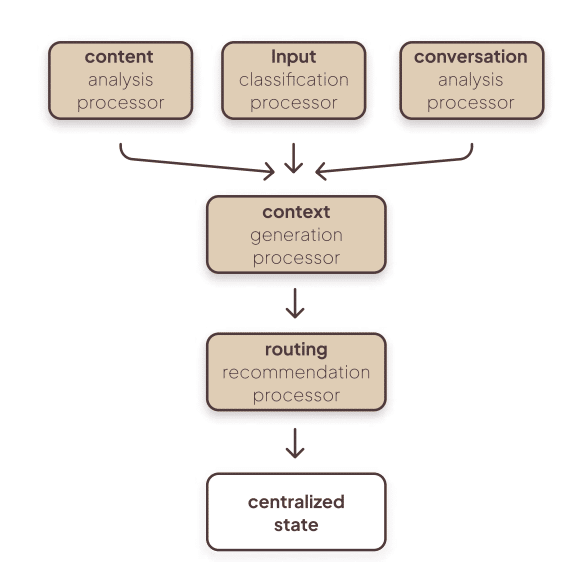
- Context Reasoning Agent — always first; classifies input, extracts intent, prepares context packages for downstream agents (input classification, conversation analysis, context generation).
Figure 2. Context Agent Processor Pipeline
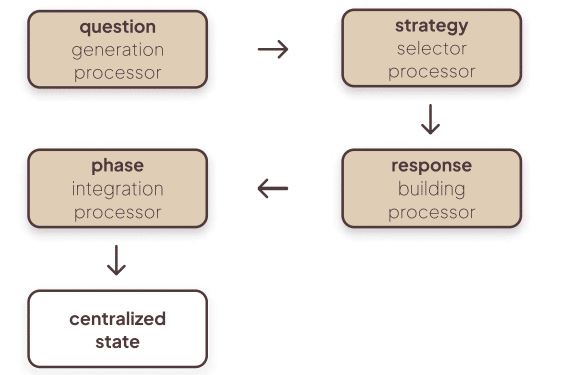
- Socratic Dialogue Agent — asks calibrated, phase-aware questions (why/what/what if), preserves productive struggle, generates question difficulty dynamically. The agent’s question constructor considers phase and student state.
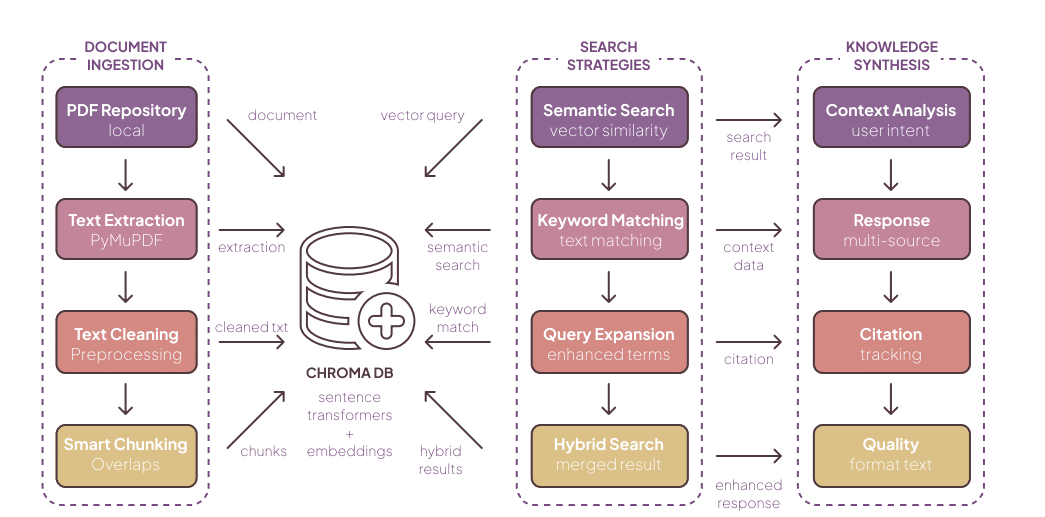
- Domain Expert Agent — RAG-enabled knowledge retrieval (ChromaDB vector store + hybrid semantic/keyword search), with pedagogical filtering and automatic citation generation. It provides targeted facts and scaffolded references (not direct answers).

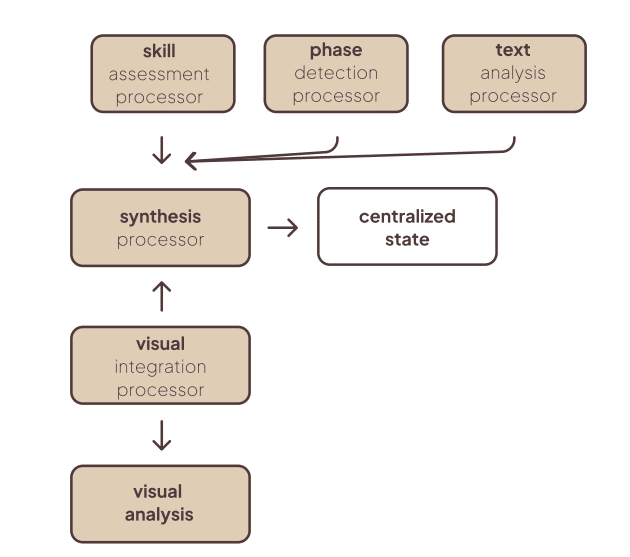
- Cognitive Enhancement Agent — novel cognitive safety/gating agent that monitors offloading markers and triggers interventions (challenge prompts, reframing, delaying direct answers). It maintains the centralized cognitive state and decides when to escalate to higher-priority cognitive protection routes.
- Analysis Agent — executes automated fuzzy linkography, process analytics, and meta-feedback. It identifies chunks, webs, sawtooth patterns, critical moves and triggers scaffolding when fragmentation appears.
3.3 Orchestration (LangGraph)
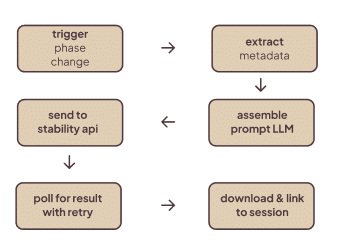
The orchestration layer is implemented with LangGraph (state-graph workflows). The Context Agent is always the entry node; routing decisions (via a route_decision_function) select single-agent or multi-agent coordination paths (sequential, parallel, adaptive coordination). The workflow defines transitions, conditional edges, and a synthesizer stage that merges agent outputs into a coherent educational response.
Representative pseudocode (paraphrased): the workflow sets an entry point to context_agent, uses a route_decision_function to choose routes like socratic_exploration or knowledge_delivery, and connects agent outputs to a synthesizer node for coherence checking and formatting.
4. Knowledge management & RAG implementation
MENTOR’s Domain Expert uses a hybrid Retrieval-Augmented Generation pipeline built on ChromaDB (persistent vector store), multi-strategy search (semantic + keyword + query expansion), smart chunking, and citation tracking. The ingestion pipeline runs PDF extraction, chunking, metadata enrichment, and embedding (sentence-transformer models), producing a curated architectural knowledge base updated periodically.
Key properties:
- Pedagogical filtering: content is reformatted for educational use; progressive disclosure reduces extraneous load.
- Citation integration: every retrieved snippet is returned with a citation in requested academic style (APA/MLA/Chicago).
- Quality merging: hybrid search results are deduplicated and scored based on authority, local context and pedagogical suitability.
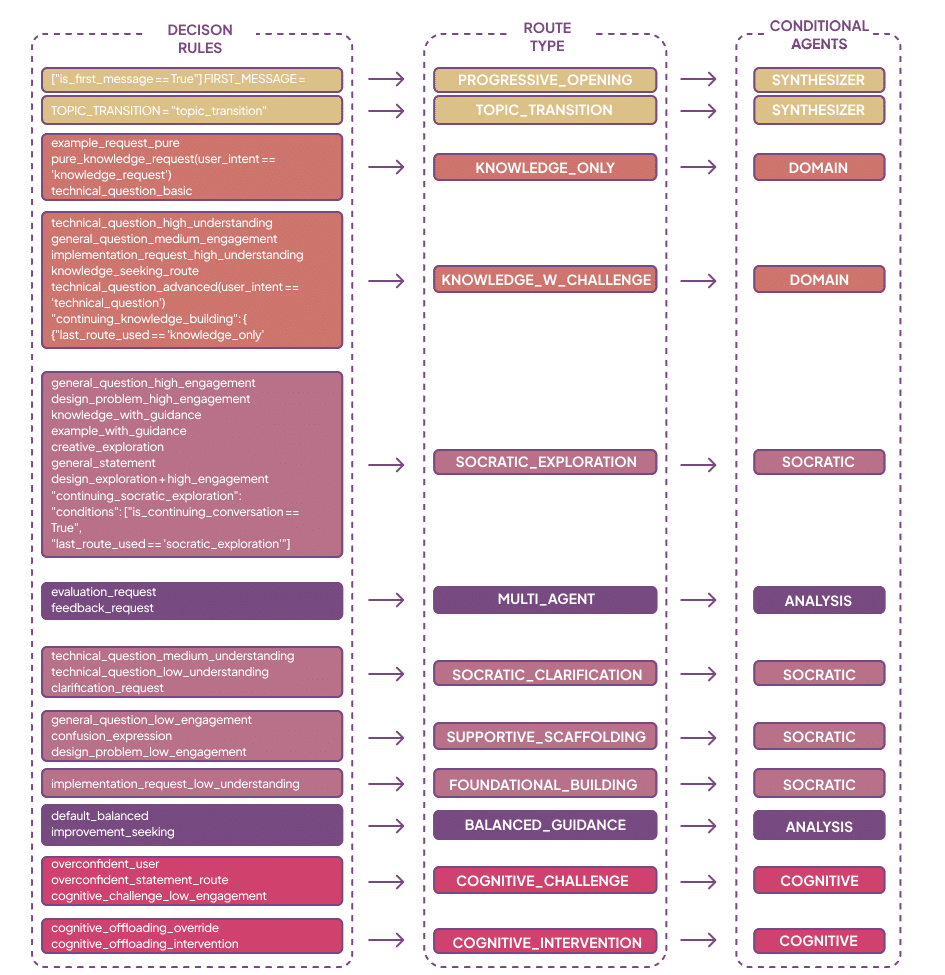
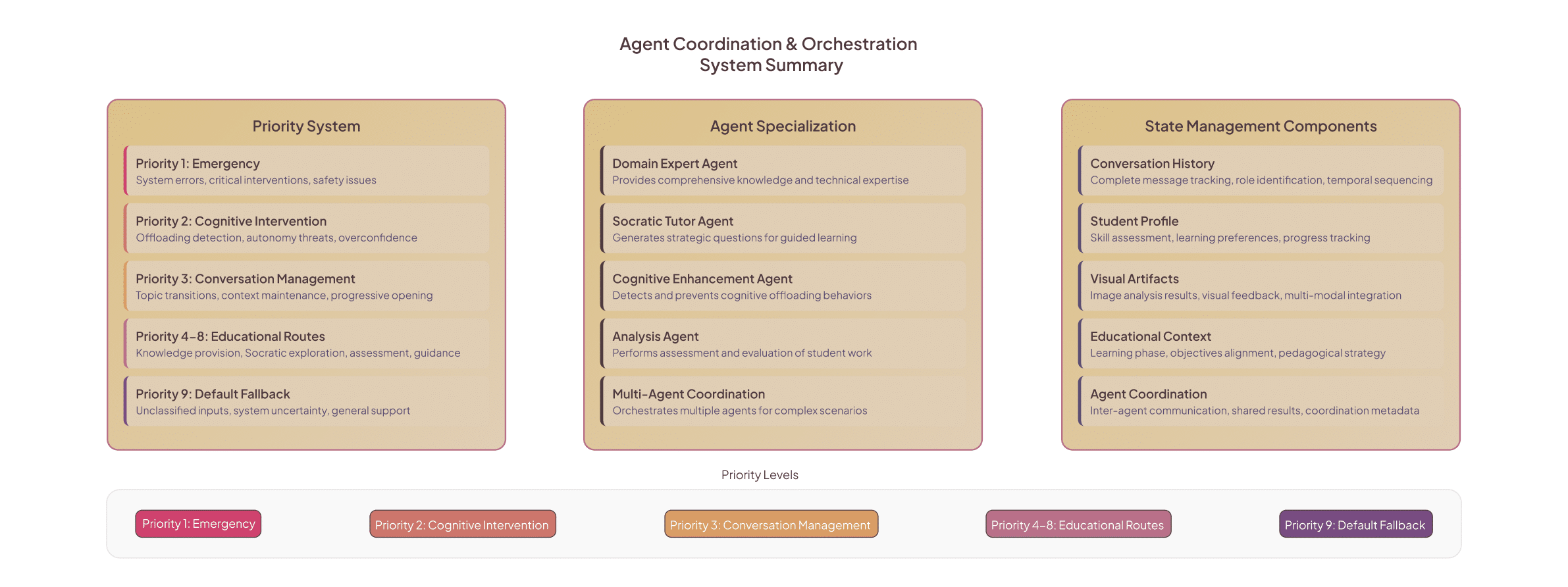
5. Routing, pedagogy and the eleven interaction routes
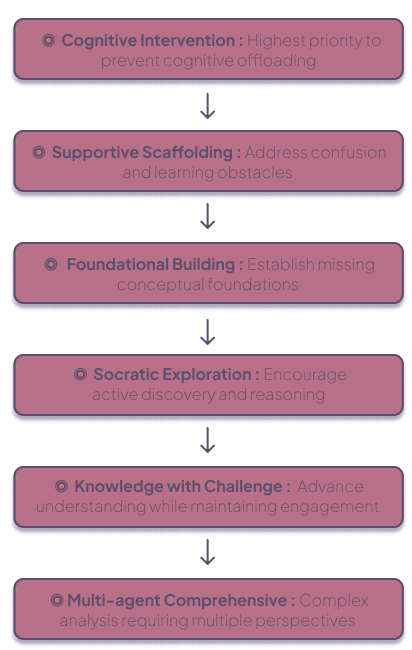
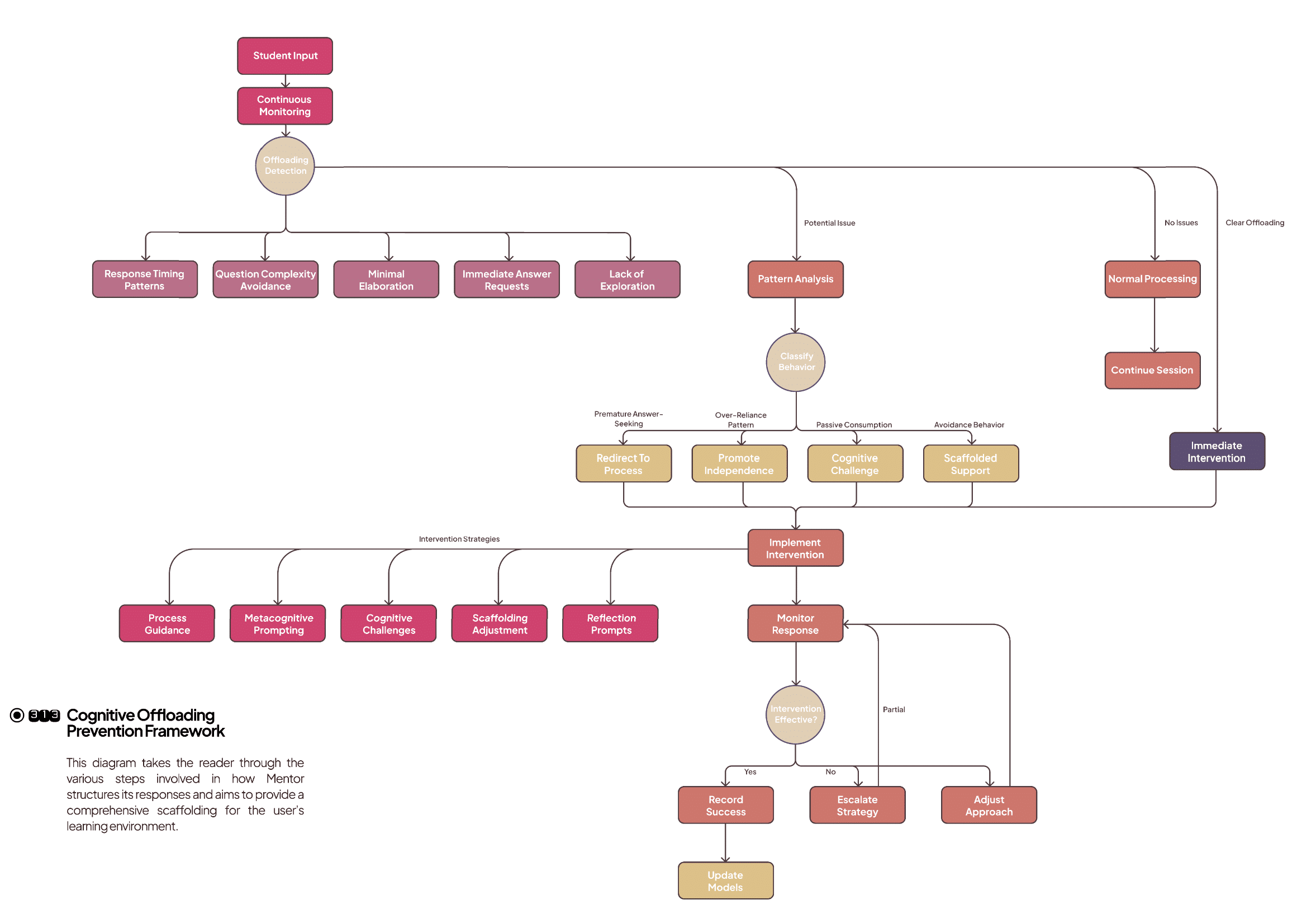
cognitive protection hierarchy: emergency → cognitive intervention → conversation management → educational routes → fallback. Routes of note:
- COGNITIVE_INTERVENTION (highest educational priority) — detect offloading attempts, reframe the prompt, activate Socratic questioning and minimal domain hints; used to preserve independence.
- SOCRATIC_EXPLORATION — open-ended generative questioning to stimulate divergent thinking.
- KNOWLEDGE_WITH_CHALLENGE — deliver targeted domain knowledge but pair it with an explicit cognitive challenge (apply/critique).
- FOUNDATIONAL_BUILDING — remedial route to establish missing conceptual foundations.
- MULTI_AGENT_COMPREHENSIVE — used for complex synthesis requiring domain + analysis + cognitive enhancement.
Each route defines which agents activate and how the synthesizer composes outputs into an educationally coherent message; routes adjust question complexity and scaffolding intensity based on phase detection and cognitive metrics.
6. Phase detection, phase-protection and adaptive scaffolding
Design tasks are decomposed into three phases (ideation, visualization, materialization). MENTOR computes phase readiness and completion with weighted signals from conversation content, artifact progress, questions answered, average response quality and covered concepts. The system emphasizes question count (practice volume) but also values response quality and concept coverage in readiness scoring.
Phase completion formula (paraphrase):percent = 100 * (0.60 * question_ratio + 0.25 * quality_ratio + 0.15 * concept_ratio) where question_ratio = min(answered/target_questions,1), etc. This formula encourages active questioning while not ignoring response quality.
Phase 1: Ideation (Concept Development and Exploration)
The ideation phase focuses on developing conceptual thinking and creative exploration capabilities. During this phase, the system emphasizes:
Learning Objectives:
◐Program analysis and spatial reasoning development
◐Creative exploration and divergent thinking
◐Conceptual framework establishment
◐Design vocabulary building
Pedagogical Approach:
◐High reliance on Socratic Tutor Agent for open-ended exploration
◐Minimal technical constraints to encourage creativity
◐Emphasis on “why” questions over “how” questions
◐Encouragement of multiple solution exploration
Agent Coordination:
◐Socratic Tutor Agent: Primary (60% of responses)
◐Context Agent: Continuous monitoring (100% engagement)
◐Cognitive Enhancement Agent: Challenge generation (40% of responses)
◐Domain Expert Agent: Minimal knowledge provision (20% of responses)
Phase 2: Visualization (Spatial Representation and Design Development)
The visualization phase bridges conceptual thinking with spatial representation, requiring integration of creative and technical knowledge.
Learning Objectives:
◐Spatial relationship understanding and manipulation
◐Architectural representation skill development
◐Technical knowledge integration with design concepts
◐Visual communication capability building
Pedagogical Approach:
◐Balanced integration of questioning and knowledge provision
◐Multimodal interaction emphasis (text and visual analysis)
◐Progressive technical complexity introduction
◐Feasibility consideration integration
Agent Coordination:
◐Analysis Agent: Primary for visual interpretation (50% of responses)
◐Socratic Tutor Agent: Spatial reasoning questions (40% of responses)
◐Domain Expert Agent: Technical knowledge integration (35% of responses)
◐Cognitive Enhancement Agent: Challenge calibration (30% of responses)
Phase 3: Materialization (Technical Development and Implementation)
The materialization phase focuses on technical knowledge application and professional practice preparation.
Learning Objectives:
◐Technical system integration and coordination
◐Construction and material knowledge application
◐Performance requirement satisfaction
◐Professional practice skill development
Pedagogical Approach:
◐Higher reliance on Domain Expert Agent for technical knowledge
◐Challenge-based learning with real-world constraints
◐Integration of multiple building systems and requirements
◐Professional communication skill development
Agent Coordination:
◐Domain Expert Agent: Primary for technical guidance (55% of responses)
◐Analysis Agent: System integration analysis (45% of responses)
◐Socratic Tutor Agent: Integration and synthesis questions (35% of responses)
◐Cognitive Enhancement Agent: Professional challenge generation (25% of responses)
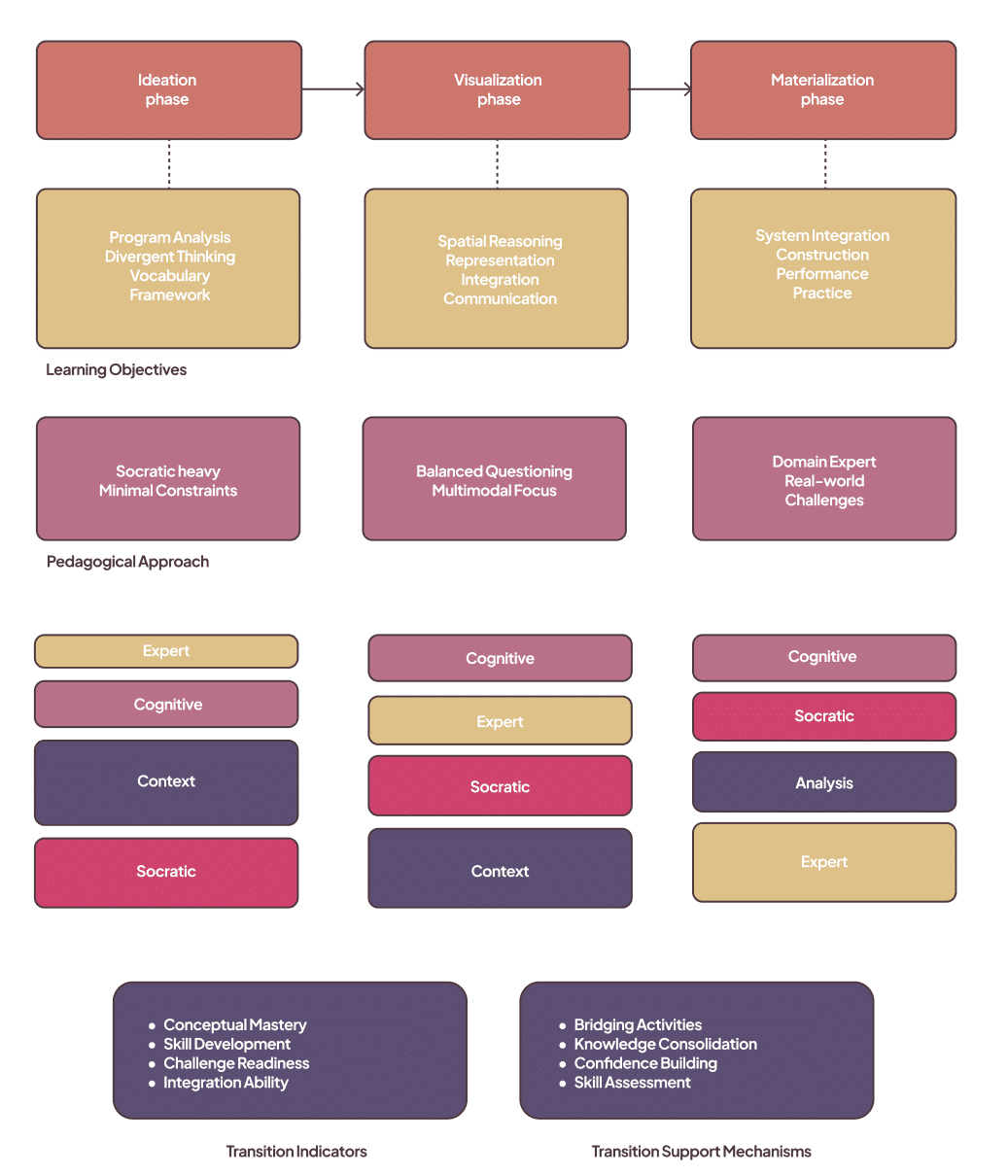
Phase protection: before allowing a user to move to a higher phase (e.g., from ideation to visualization), the system computes readiness_score across minimum interactions, average score thresholds, completion percentages and minimum concepts covered; only if readiness_score ≥ 0.6 does the system suggest advancing. This avoids premature phase jumps that would encourage shallow acceptance of AI suggestions.
Adaptive scaffolding behaviors: difficulty adjustment, intervention triggering when offloading is detected, and progress tracking with bridging activities at transitions (e.g., concept synthesis exercise).
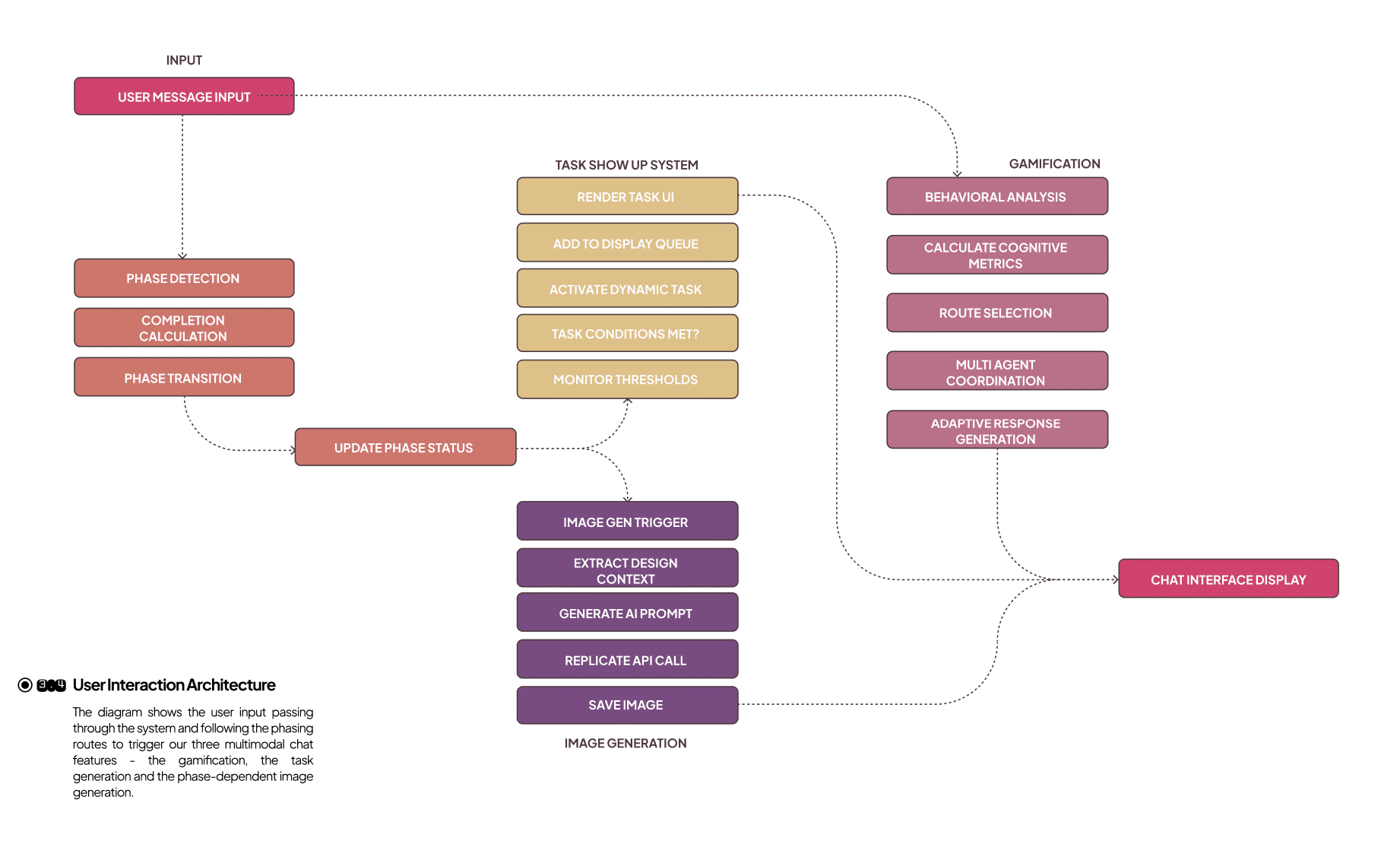
Task Generation: Presents contextual learning tasks to students at pedagogically meaningful moments. Tasks are short, targeted activities that scaffold the design process without solving the problem for the learner.
High-level requirements consist of the following:
◐Appear at configurable phase completion thresholds.
◐Respect prerequisites and resource constraints (e.g., sufficient conversation depth or an uploaded image).
◐Persist across refreshes and sessions until completed or expired.
◐Be traceable (trigger reasons and timestamps) for later analysis.
The activation workflow begins with threshold detection, where the system calculates the learner’s phase completion for a given session.
Once the threshold is met, the system performs condition verification, ensuring prerequisites such as prior tasks, required images, or a minimum number of messages are satisfied.
When these checks succeed, the system proceeds to task activation, instantiating an ActiveTask object and persisting it in the database.
Finally, the task is placed in the UI queue, rendering it directly in the learner’s interface and linking it to the triggering message for contextual relevance.
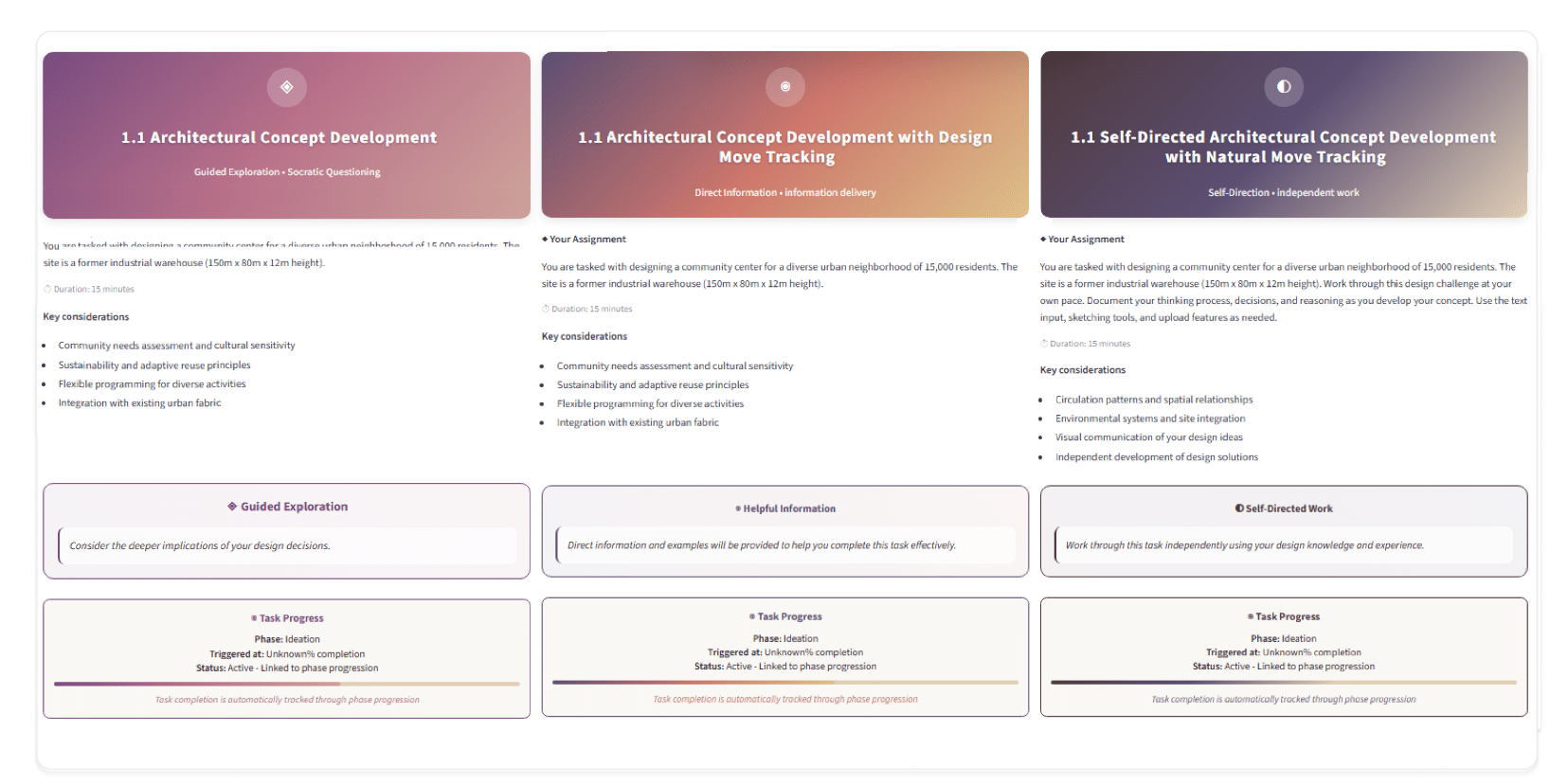
Image Generation: Each design phase incorporates distinct cognitive demands and learning objectives:
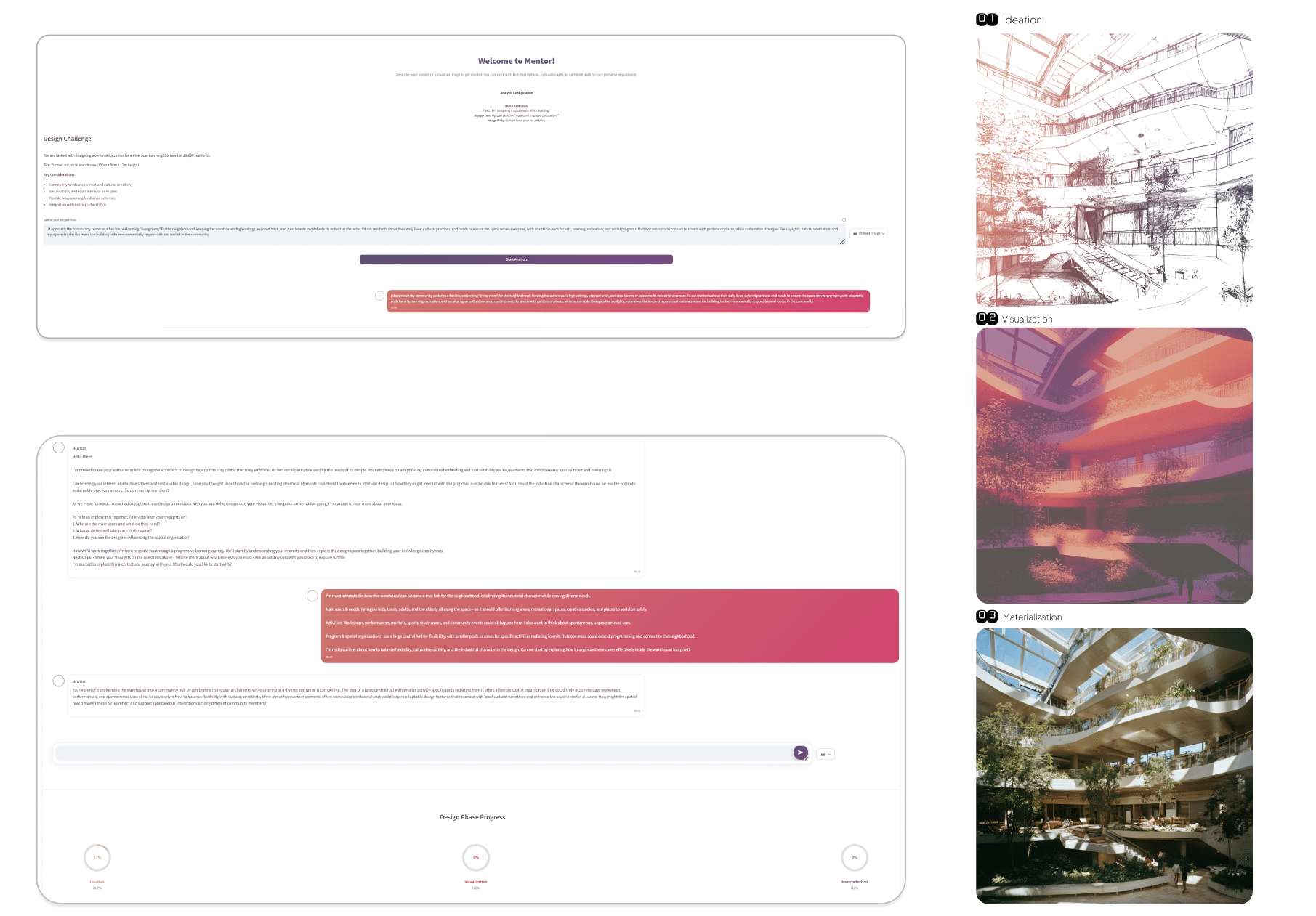
Ideation Phase:
◐ Focus: Conceptual thinking, problem definition and creative exploration
◐ Cognitive demands: Divergent thinking, exploration, concept generation
◐ Assessment criteria: Problem understanding, contextual awareness, precedent knowledge
Visualization Phase:
◐ Focus: Spatial organization, form development and design synthesis
◐ Cognitive demands: Spatial reasoning, integration skills, visual thinking
◐ Assessment criteria: Spatial relationships, form sensitivity, iteration comfort
Materialization Phase:
◐ Focus: Technical development, material selection and implementation
◐ Cognitive demands: Technical thinking, detail orientation, systematic approach
◐ Assessment criteria: Technical understanding, precision, implementation focus
These are then translated into relevant phase mappings & prompt templates:
◐Ideation — Rough Sketch
Template: “Very rough, sketchy architectural concept drawing of {{concept_keywords}}. Loose hand-drawn lines, pencil-on-paper texture, no dimensions, expressive marks.”
◐Visualization — Architectural Form
Template: “Finished architectural sketch of {{concept_keywords}} with color washes and marker rendering. Include plan hint, massing gesture and human scale.”
◐Materialization — Detailed Render
Template: “Photorealistic 3D architectural rendering of {{concept_keywords}}. Realistic materials, natural lighting, exterior context, camera angle 35mm.”
Gamification Process
◐Gamification System
The gamification process in this system is not designed around superficial rewards or external motivators, but rather as an instrumental mechanism for shaping pedagogical routing grounded in Self-Determination Theory.
Its central purpose is to quantify cognitive engagement in real time and adaptively guide learners through the educational pathway while maintaining their agency. In this context, gamification is a diagnostic and regulatory tool rather than a motivational overlay.

◐Adaptive Challenge Generation
The system implements dynamic challenge generation mechanisms that respond to individual student cognitive states and learning progression.
Challenges are designed to promote specific cognitive skills including creative thinking, critical analysis, spatial reasoning and design synthesis. The challenge generation system incorporates frequency control mechanisms to prevent gamification fatigue while maintaining optimal engagement levels.
Challenge types include:
◐perspective-shifting exercises
◐ constraint-based design problems
◐role-playing scenarios
◐ mystery-solving activities
Each challenge type targets specific cognitive capabilities while maintaining connection to architectural design contexts.
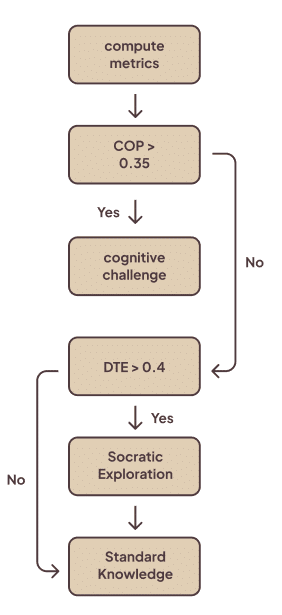
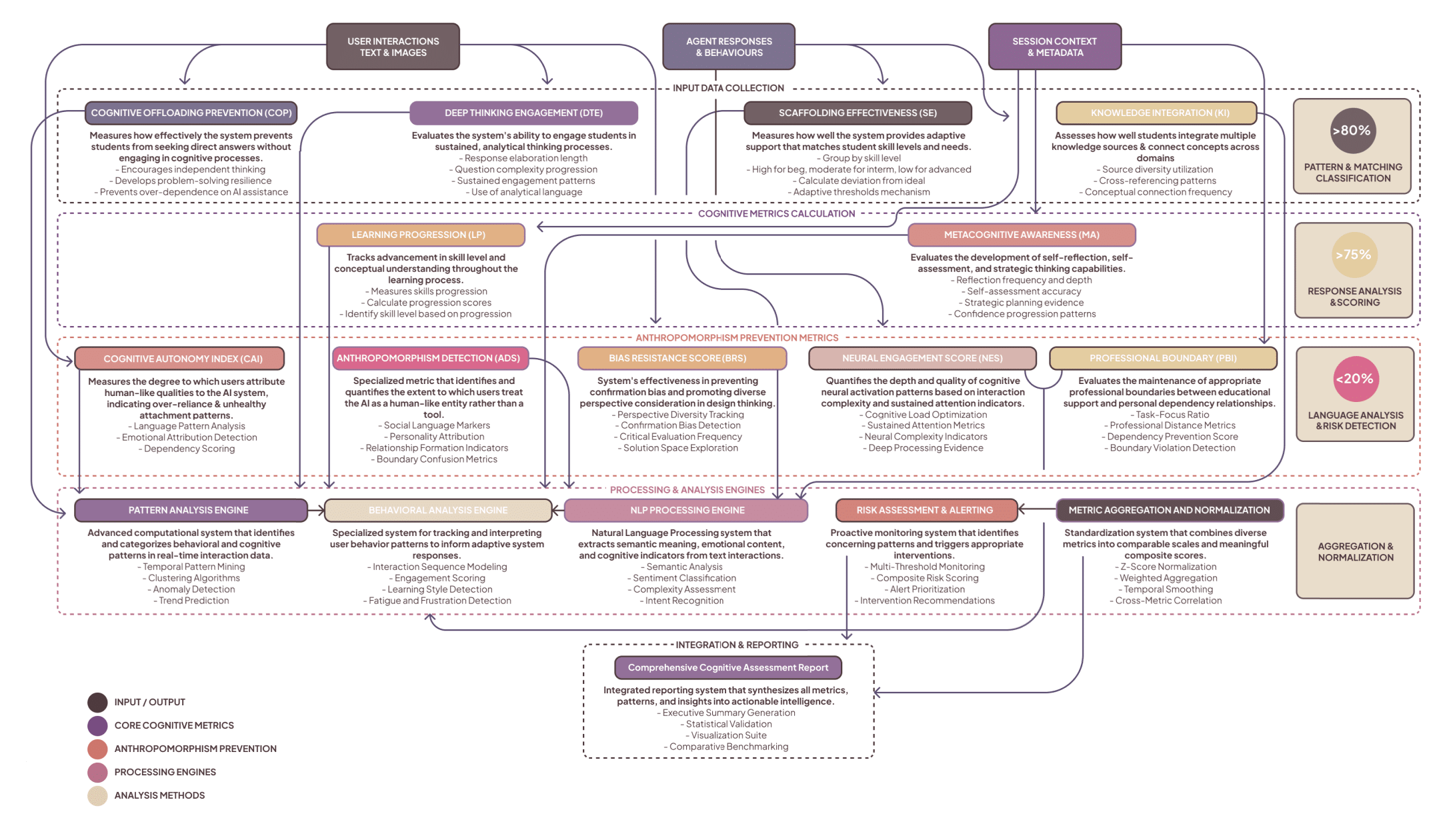
7. Real-time cognitive state monitoring and the eleven metrics
MENTOR calculates a Scientific Metrics Profile in real time. The core metrics (with research-validated targets) include:
- Cognitive Offloading Prevention (COP): target >70%. Measures how much the system prevents direct answer acceptance.

- Deep Thinking Engagement (DTE): target >60%. Measures reasoning chain length, alternatives considered.
- Scaffolding Effectiveness (SE): target >80%. Measures whether scaffolding improved independent performance.
- Knowledge Integration (KI), Learning Progression (LP), Metacognitive Awareness (MA), etc. Full list and operationalization are implemented across behavior, NLP features and artifact analysis.
The Cognitive State Assessment class aggregates indicators: understanding_level, engagement_depth, confidence_level, cognitive_load, metacognitive_awareness. These feed route selection and intervention triggers.
8. Automated fuzzy linkography (process analysis)
Arguably the most technically novel component for design assessment is the automated fuzzy linkography implementation:
- Encoding: Each design move (textual description / comment / sketch metadata) is embedded using sentence-transformer (384-dim vector all-MiniLM) to capture technical, spatial and aesthetic semantics.
- Similarity & temporal decay: pairwise cosine similarities are computed; a temporal decay factor multiplies semantic similarity to respect proximity in time (e.g., temporal_factor = max(0.1, 1.0 − time_diff / 300) with 5-minute decay). This produces a fuzzy link strength rather than a binary link.
- Thresholding & pattern detection: links with strength > threshold (default 0.35) are retained. From the link matrix, we detect link_density, critical_moves (highly connected hubs), chunks (dense local windows), webs (nodes ≥5 connections), sawtooth sequences and orphans (moves with no links).
Computational scale: average session has ~124.6 moves → ~7,754 potential connections → millions of vector ops; this is expensive but necessary to maintain high semantic fidelity for educational use (false positives/negatives in link detection would misdirect pedagogy).
9. Benchmarking, analytics & ML pipeline
MENTOR’s empirical analysis uses a 10-step benchmarking pipeline:
- Data loading and validation (CSV/session JSON).
- Interaction → InteractionGraph conversion.
- Cognitive metric calculation (real time).
- Fuzzy linkography & process pattern detection.
- GNN training (GraphSAGE/GAT variations) for pattern recognition.
- Proficiency clustering (K-means) and classification (Random Forest ensembles).
- Mixed-effects models for longitudinal phase analysis.
- MANOVA for omnibus testing across the eleven metrics, followed by ANOVAs with Bonferroni correction.
- Bayesian hierarchical models for probabilistic inference and Bayes factors.
- Dashboard generation & reporting (Streamlit).
Representative ML elements:
- Proficiency classifier: ensemble of RandomForest, GradientBoosting, VotingClassifier using composite scoring (cognitive_score0.4 + support0.3 + interaction0.2 + knowledge_integration0.1) to assign Expert/Advanced/Intermediate/Beginner classes.
- GNNs: Graph Neural Networks (SAGE/GCN/GAT) trained on interaction graphs to detect higher-order cognitive patterns; useful for early prediction of struggling students.
Statistical modeling: repeated measures mixed-effects (LME via lme4), pairwise contrasts via emmeans and Bayesian stan_lmer models with normal(0,2.5) priors for robustness checks. MANOVA is used as omnibus test for group differences across the eleven cognitive metrics; assumptions (normality, homogeneity, sphericity) were assessed and alternative non-parametric tests (Kruskal-Wallis + Mann-Whitney U) used where appropriate.
10. Experimental design (study protocol)
10.1 Research questions & hypotheses
The experiment targeted three RQs: COP effectiveness, differences in process quality across conditions, and subjective experience & preference predictability. Hypotheses predicted MENTOR would outperform Generic AI and Control on COP, DTE, linkography metrics and metacognitive gains.
10.2 Sample & assignment
Target sample N = 135 (minimum per group n≈32; target n=45 each to allow attrition); inclusion/exclusion criteria included at least one semester of design coursework, limited prior AI tutoring exposure, no professional experience >6 months. Participants were stratified by academic level, prior AI experience, spatial ability quartile and gender and assigned using a stratified rotation algorithm (paraphrased in the thesis).
10.3 Task & session protocol
65-minute standardized Community Center design challenge with phased progression (ideation → visualization → materialization), real-time logging, screen recording and optional think-aloud recordings (subset). Each participant used: (a) MENTOR multi-agent test app, (b) Generic AI assistant (chatbot), or (c) Control (no AI).
10.4 Measures & validation
Pre/post domain knowledge tests, spatial reasoning tasks, design quality rubric for artifacts, automated linkography, self-report questionnaires (satisfaction, cognitive load), inter-rater checks (κ>0.80) for manual coding and reliability analyses including ICC and Krippendorff’s alpha.
11. Results (detailed — empirical outcomes and statistics)
Below we summarize the principal quantitative and qualitative outcomes produced by the benchmarking analysis. All group differences reported were tested with MANOVA and follow-up ANOVAs (Bonferroni correction), supplemented with mixed effects and Bayesian checks for robustness. See the thesis figures and tables for full statistical tables; here we highlight the most consequential findings.
11.1 Cognitive Offloading Prevention (COP)
- MENTOR (multi-agent): COP = 84.7% (target >70).
- Generic AI: COP ≈ 42.3% (below baseline).
- Control: COP ≈ 60%.
Group differences were significant (MANOVA omnibus p << 0.001). Effect sizes were large (reported d in thesis range 2.34–4.12 for core metrics), and results were stable under Bayesian modeling.
11.2 Deep Thinking Engagement (DTE)
- MENTOR: 73.9% DTE (exceeded 60% target).
- Generic AI: 29.8% DTE.
- Control: ~45%.
Qualitative NLP analysis showed +126% abstract reasoning language and +81% technical vocabulary in MENTOR transcripts, indicating deeper conceptually-oriented processing.
11.3 Process quality via linkography
- Link density: MENTOR sessions had ~65% higher interconnectedness than baselines.
- Critical moves: +85% more in MENTOR group.
- Web formation: +114% more integrated reasoning patterns.
- Orphans: 44% fewer orphan moves.
These process effects align closely with DTE increases, demonstrating that cognitive depth translated into better design reasoning patterns.
11.4 Anthropomorphism & dependency
- Anthropomorphism Detection Score (ADS): ~15.6% for MENTOR (target <20).
- Cognitive Autonomy Index (CAI): 72.4% for MENTOR vs 38.9% for Generic AI.
This indicates the multi-agent design and explicit boundary maintenance prevented unhealthy AI humanization and dependency.
11.5 Learning gains, transfer & sustainability
- Knowledge test: statistically significant gains (p < 0.05) for MENTOR vs Generic AI; medium effect sizes for spatial reasoning (Cohen’s d ≈ 0.51).
- Skill transfer: near transfer maintenance 78.9%, far transfer 56.7% for MENTOR.
- Self-reported autonomy/confidence: 87.2% reported increased independent problem-solving confidence after MENTOR sessions.
11.6 Temporal & computational notes
- Average session had ~124.6 design moves leading to ~2.98M vector ops (pairwise comparisons and decay weighting), necessitating optimized implementations for real-time responsiveness. Thesis documents show computational budgets, O(N²) bounds and practical processing strategies.
Recommended figures in Results: Metric Distribution Analysis, Session Performance Analysis, Cumulative Learning Progress, Agent Performance by Metric (Figures 6.2.1, 6.2.2, 6.5.2, 6.6.2).
12. Mechanisms of effect (how MENTOR produced better outcomes)
The empirical superiority of MENTOR is explained by multiple interacting mechanisms:
- Prevention via Socratic gating: the system identifies direct answer seeking and reframes requests into explorations, maintaining cognitive effort (COGNITIVE_INTERVENTION route).
- Adaptive scaffolding: phase detection + phase protection prevented premature proceduralization and fostered appropriate challenge.
- Process feedback: linkography + analysis agent provided process-level feedback (not only product critique), enabling students to form integrative webs.
- Knowledge delivery with cognitive challenge: Domain Expert never simply hands solutions — it pairs facts with synthesis prompts to stimulate application.
- Distributed agency reduces anthropomorphism: multi-agent coordination prevents emotional overattachment to a single “partner”.
13. Limitations
- Duration & scope: the primary empirical test was acute (single 65-minute session per participant). Longitudinal studies across semesters are needed to determine lasting cognitive effects.
- Domain specificity: implementation is tailored to architectural design; cross-domain validation (engineering, urban planning) is required to assert generality.
- Computational cost: fuzzy linkography entails O(N²) operations with high dimensional embeddings. Scalability strategies and hardware acceleration (GPU batched similarity, approximate nearest neighbor) are necessary for large rollouts.
14. Practical recommendations & design principles
From MENTOR’s architecture and empirical results we extract practical design principles:
- Process-first design: prioritize process metrics (linkography, DTE) over immediate task completion metrics.
- Socratic over answer-provision: default to guided questioning; deliver knowledge only when paired with cognitive challenge.
- Phase-aware scaffolding: use explicit phase detection and readiness thresholds before advancing difficulty.
- Explicit boundary & capability communication: prevent anthropomorphism by stating agent roles and limits; distribute authority across agents.
- Hybrid search + citation: use RAG with academic citation to ground domain knowledge and maintain integrity.
15. Future work
Planned directions include: longitudinal cohort studies, integration of immersive VR for spatial reasoning tasks, efficient approximate linkography (ANN search + temporal locality heuristics), exploration of multi-modal GNNs for richer process prediction, and open-sourcing of the benchmarking pipeline to foster replication and meta-analysis.
16. Conclusion
MENTOR shows that AI can and should be designed to protect cognition. By embedding Socratic pedagogy, phase-aware scaffolding, a curated RAG knowledge base, multi-agent orchestration via LangGraph, and real-time fuzzy linkography, the system prevents cognitive offloading and fosters richer design reasoning — empirically and robustly. The technical and empirical contributions include a novel Cognitive Enhancement Agent, automated fuzzy linkography at scale, a validated routing hierarchy of eleven pedagogical routes, and a benchmarking stack that couples GNNs with classical inferential statistics. The results provide a practical blueprint for educational AI that augments human cognition rather than replacing it.
